Yes, you can definitely learn deep learning without prior machine learning knowledge. This comprehensive guide, crafted by the experts at LEARNS.EDU.VN, will walk you through everything you need to know. Dive into forward propagation, back propagation, and weight updates – the foundational concepts of deep learning. You’ll be amazed at how quickly you can grasp the core principles. Let’s explore neural networks, convolutional neural networks (CNNs), and recurrent neural networks (RNNs).
1. Understanding the Core Concepts: Is Machine Learning a Prerequisite for Deep Learning?
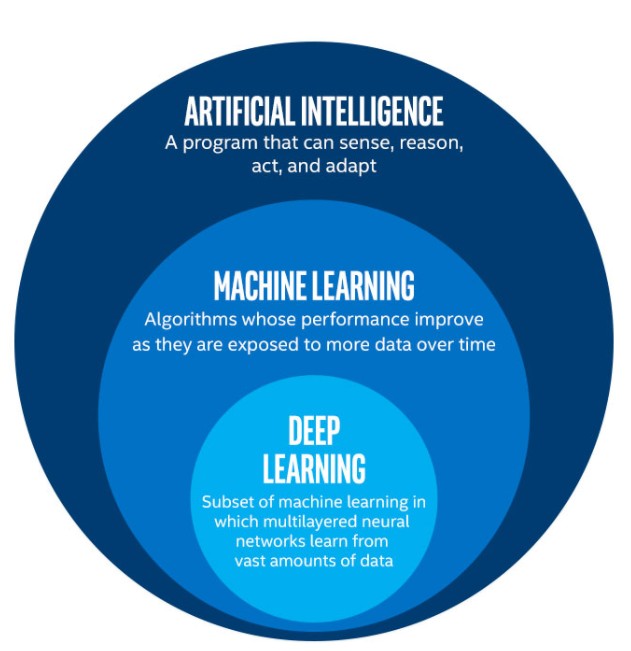
No, you do not need to learn machine learning before diving into deep learning. While some concepts overlap, deep learning can be approached directly.
Deep learning is a specialized subset of machine learning, and although both fields intersect, they possess distinct characteristics. Traditional machine learning often requires manual feature engineering, where experts identify and extract relevant features from data. Deep learning, on the other hand, automates this feature extraction process using neural networks. This automation is a significant advantage, allowing deep learning models to handle complex data without explicit feature engineering.
1.1. Feature Engineering: Manual vs. Automatic
In traditional machine learning, feature engineering is a crucial step. It involves selecting and transforming the most relevant features from raw data to improve model performance. This process requires domain expertise and can be time-consuming. According to a study by Stanford University, feature engineering can account for up to 80% of the effort in a machine learning project.
Deep learning eliminates the need for manual feature engineering by learning features directly from data. This is achieved through the use of deep neural networks, which consist of multiple layers that automatically learn hierarchical representations of the input data. As a result, deep learning models can handle unstructured data, such as images, audio, and text, more effectively than traditional machine learning algorithms.
1.2. Key Differences Between Machine Learning and Deep Learning
| Feature | Machine Learning | Deep Learning |
|---|---|---|
| Feature Extraction | Manual | Automatic |
| Data Dependency | Works well with smaller datasets | Requires large amounts of data |
| Hardware | Can run on standard CPUs | Benefits from GPUs for faster training |
| Complexity | Simpler models, easier to interpret | More complex models, harder to interpret |
| Applications | Suitable for structured data, simpler tasks | Ideal for unstructured data, complex tasks |
| Training Time | Faster training times | Longer training times |
| Computational Cost | Lower | Higher |
| Scalability | Less scalable with increasing data complexity | More scalable with increasing data complexity |
1.3. Research Insights and Studies
Research from the University of California, Berkeley, highlights that deep learning models consistently outperform traditional machine learning algorithms in tasks such as image recognition, natural language processing, and speech recognition. This is attributed to their ability to learn complex patterns and representations from large datasets.
2. Setting the Stage: Essential Prerequisites
While machine learning isn’t a direct prerequisite, a solid foundation in mathematics and programming is essential. These skills will help you navigate the complexities of deep learning algorithms and implement them effectively.
2.1. Mathematical Foundations
Understanding the underlying mathematics is crucial for grasping the mechanics of deep learning. Key mathematical concepts include:
- Linear Algebra: Vectors, matrices, tensors, matrix operations (addition, multiplication, transposition, inversion), eigenvalues, and eigenvectors. These are fundamental for understanding how data is represented and manipulated in neural networks.
- Calculus: Derivatives, gradients, chain rule, optimization algorithms (gradient descent, stochastic gradient descent). Calculus is essential for understanding how neural networks learn through backpropagation.
- Probability and Statistics: Probability distributions, hypothesis testing, statistical significance, Bayesian inference. These are important for understanding model evaluation, regularization, and dealing with uncertainty in data.
A report by MIT suggests that students with a strong background in linear algebra and calculus perform significantly better in deep learning courses.
2.2. Programming Skills
Proficiency in programming is necessary to implement and experiment with deep learning models. Popular programming languages include:
- Python: The dominant language in the field, thanks to its simplicity, extensive libraries, and strong community support.
- R: Useful for statistical analysis and data visualization.
- Julia: Emerging as a high-performance language for scientific computing.
Python is the most recommended language for deep learning due to its extensive ecosystem of libraries such as TensorFlow, Keras, and PyTorch. These libraries provide high-level APIs that simplify the development and deployment of deep learning models.
2.3. Recommended Resources for Foundational Knowledge
- Mathematics: “Linear Algebra and Its Applications” by Gilbert Strang, “Calculus” by James Stewart.
- Programming: “Python Crash Course” by Eric Matthes, “Automate the Boring Stuff with Python” by Al Sweigart.
These resources provide a solid foundation in the necessary mathematical and programming skills, allowing you to tackle deep learning concepts with confidence.
3. Diving Right In: How to Start Learning Deep Learning
You can begin with introductory deep learning concepts without prior machine learning knowledge. Focus on understanding the fundamental building blocks of neural networks and their applications.
3.1. Start with Neural Networks
Begin with the basic building blocks:
- Neurons: Understand how individual neurons work, including activation functions (Sigmoid, ReLU, Tanh).
- Layers: Learn about different types of layers (input, hidden, output) and how they are connected.
- Forward Propagation: Grasp how data flows through the network to produce an output.
- Backpropagation: Understand how the network learns by adjusting weights based on the error.
- Gradient Descent: Learn how to optimize the network’s weights to minimize the loss function.
A study by the University of Toronto highlights the importance of starting with basic neural networks to build a strong foundation for more advanced deep learning concepts.
3.2. Hands-On Projects for Beginners
Engage in practical projects to reinforce your understanding:
- MNIST Digit Classification: A classic beginner project that involves training a neural network to recognize handwritten digits.
- Simple Image Classifier: Build a model to classify images from a small dataset (e.g., cats vs. dogs).
- Basic Natural Language Processing (NLP) Tasks: Implement sentiment analysis or text classification using simple neural networks.
These projects will help you apply the theoretical knowledge and gain hands-on experience with deep learning frameworks.
3.3. Frameworks for Deep Learning: TensorFlow, Keras, PyTorch
Choose a deep learning framework to implement your models:
- TensorFlow: Developed by Google, it offers a comprehensive ecosystem for building and deploying deep learning models.
- Keras: A high-level API that simplifies the development of neural networks, running on top of TensorFlow or other backends.
- PyTorch: Developed by Facebook, it is known for its flexibility and dynamic computation graph.
Keras is often recommended for beginners due to its ease of use and clear syntax. TensorFlow and PyTorch are more suitable for advanced users who need more control over the model architecture and training process.
4. Unveiling the Magic: Deep Learning Concepts Explained
Deep learning involves several key concepts. Mastering these will enable you to build and train effective models.
4.1. Activation Functions
Activation functions introduce non-linearity to neural networks, allowing them to learn complex patterns. Common activation functions include:
- Sigmoid: Outputs values between 0 and 1, suitable for binary classification tasks.
- ReLU (Rectified Linear Unit): Outputs the input directly if it is positive, otherwise outputs 0. It is widely used due to its simplicity and efficiency.
- Tanh (Hyperbolic Tangent): Outputs values between -1 and 1, similar to sigmoid but with a wider range.
- Leaky ReLU: A variant of ReLU that allows a small, non-zero gradient when the input is negative, addressing the “dying ReLU” problem.
Research from the University of Oxford indicates that ReLU and its variants are generally preferred in deep learning models due to their ability to mitigate the vanishing gradient problem.
4.2. Loss Functions
Loss functions quantify the difference between the predicted output and the actual output. Common loss functions include:
- Mean Squared Error (MSE): Calculates the average squared difference between the predicted and actual values, suitable for regression tasks.
- Binary Cross-Entropy: Measures the difference between two probability distributions, commonly used in binary classification tasks.
- Categorical Cross-Entropy: An extension of binary cross-entropy for multi-class classification tasks.
The choice of loss function depends on the specific task and the type of output. For example, MSE is often used in regression tasks where the goal is to predict continuous values, while cross-entropy is used in classification tasks where the goal is to predict discrete categories.
4.3. Optimization Algorithms
Optimization algorithms adjust the weights of the neural network to minimize the loss function. Common optimization algorithms include:
- Gradient Descent: An iterative algorithm that updates the weights in the direction of the steepest descent of the loss function.
- Stochastic Gradient Descent (SGD): A variant of gradient descent that updates the weights using a single training example at a time, introducing randomness and potentially escaping local minima.
- Adam (Adaptive Moment Estimation): An adaptive optimization algorithm that combines the benefits of both momentum and RMSprop, adjusting the learning rate for each weight based on its historical gradients.
Adam is often the preferred choice due to its robustness and ability to converge quickly. However, the best optimization algorithm depends on the specific task and the characteristics of the data.
5. Deep Learning Architectures: CNNs and RNNs
Two popular deep learning architectures are Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). Each is suited for different types of tasks.
5.1. Convolutional Neural Networks (CNNs)
CNNs are designed for processing grid-like data, such as images and videos. Key components of CNNs include:
- Convolutional Layers: Apply filters to the input data to extract features.
- Pooling Layers: Reduce the spatial dimensions of the feature maps, reducing computational complexity and increasing robustness to variations in the input.
- Fully Connected Layers: Combine the features extracted by the convolutional and pooling layers to make a prediction.
CNNs have achieved remarkable success in image recognition tasks, such as object detection, image classification, and image segmentation. They are also used in video analysis, natural language processing, and speech recognition.
5.2. Recurrent Neural Networks (RNNs)
RNNs are designed for processing sequential data, such as text and time series. Key features of RNNs include:
- Recurrent Connections: Allow the network to maintain a hidden state that captures information about the past.
- Long Short-Term Memory (LSTM): A type of RNN that addresses the vanishing gradient problem, allowing it to learn long-range dependencies in the data.
- Gated Recurrent Unit (GRU): A simplified version of LSTM that is easier to train and often performs similarly.
RNNs are widely used in natural language processing tasks, such as machine translation, text generation, and speech recognition. They are also used in time series analysis, such as stock price prediction and weather forecasting.
5.3. Comparative Analysis of CNNs and RNNs
| Feature | CNNs | RNNs |
|---|---|---|
| Data Type | Grid-like data (images, videos) | Sequential data (text, time series) |
| Key Components | Convolutional, Pooling, Fully Connected | Recurrent Connections, LSTM, GRU |
| Applications | Image Recognition, Video Analysis | Natural Language Processing, Time Series |
| Strengths | Excellent at Feature Extraction | Excellent at Capturing Temporal Dependencies |
| Weaknesses | Less Suitable for Sequential Data | Can Suffer from Vanishing Gradients |
6. The Value of Machine Learning: How Does It Complement Deep Learning?
While not a prerequisite, understanding machine learning can provide a broader perspective and valuable context.
6.1. Feature Selection and Engineering
In traditional machine learning, you manually select and engineer features. This process requires domain expertise and a deep understanding of the data. While deep learning automates this process, knowing how to manually select features can be beneficial in certain situations.
For example, if you have a small dataset or if you are working with a domain where feature engineering is well-established, manually selecting features may lead to better results than relying solely on deep learning.
6.2. Model Selection and Evaluation
Machine learning provides a range of models and evaluation techniques that can be useful in deep learning. For example, you can use machine learning algorithms to pre-process data, select features, or evaluate the performance of deep learning models.
Additionally, understanding the principles of model selection, such as bias-variance tradeoff and cross-validation, can help you choose the right deep learning architecture and hyperparameters for your task.
6.3. Transfer Learning
Transfer learning involves using pre-trained models on new, related tasks. This can save time and resources, especially when you have limited data.
For example, you can use a pre-trained CNN on a large image dataset to initialize the weights of a CNN for a smaller image classification task. This can significantly improve the performance of the model and reduce the amount of training data required.
7. Practical Projects: Applying Your Deep Learning Knowledge
Engage in more advanced projects to solidify your understanding and build a portfolio.
7.1. Image Recognition Projects
- Object Detection with YOLO: Implement a real-time object detection system using the YOLO (You Only Look Once) algorithm.
- Image Segmentation with U-Net: Build a model to segment images into different regions, such as identifying objects in medical images.
- Facial Recognition System: Develop a system that can identify faces in images and videos.
7.2. Natural Language Processing Projects
- Machine Translation with Seq2Seq: Build a sequence-to-sequence model for translating text from one language to another.
- Text Summarization: Develop a model that can automatically summarize long documents into shorter, more concise versions.
- Chatbot Development: Create a chatbot that can interact with users and answer questions on a specific topic.
7.3. Time Series Analysis Projects
- Stock Price Prediction: Build a model to predict stock prices based on historical data.
- Weather Forecasting: Develop a model that can forecast weather conditions based on past weather data.
- Anomaly Detection: Create a system that can detect anomalies in time series data, such as detecting fraudulent transactions.
8. Avoiding Common Pitfalls: Tips and Tricks for Success
Be aware of common challenges and how to overcome them.
8.1. Overfitting
Overfitting occurs when a model learns the training data too well, resulting in poor generalization to new data. To avoid overfitting:
- Use More Data: Increasing the amount of training data can help the model generalize better.
- Regularization Techniques: Apply techniques such as L1 and L2 regularization to penalize large weights.
- Dropout: Randomly drop out neurons during training to prevent the network from relying too heavily on specific neurons.
- Early Stopping: Monitor the performance of the model on a validation set and stop training when the performance starts to degrade.
8.2. Vanishing Gradients
Vanishing gradients occur when the gradients become very small during backpropagation, making it difficult for the model to learn. To address this issue:
- Use ReLU Activation: ReLU and its variants can help mitigate the vanishing gradient problem.
- Batch Normalization: Normalize the activations of each layer to stabilize the training process.
- Gradient Clipping: Limit the magnitude of the gradients to prevent them from becoming too large or too small.
8.3. Hyperparameter Tuning
Hyperparameters are parameters that are not learned from the data but are set prior to training. Tuning hyperparameters is crucial for achieving optimal performance. Common techniques for hyperparameter tuning include:
- Grid Search: Exhaustively search over a predefined set of hyperparameters.
- Random Search: Randomly sample hyperparameters from a distribution.
- Bayesian Optimization: Use a probabilistic model to guide the search for the optimal hyperparameters.
9. The Future of Deep Learning: Trends and Innovations
Stay updated with the latest advancements in the field.
9.1. Advancements in Neural Network Architectures
New neural network architectures are constantly being developed, such as:
- Transformers: Revolutionized natural language processing and are now being applied to other domains, such as computer vision.
- Graph Neural Networks (GNNs): Designed for processing graph-structured data, such as social networks and knowledge graphs.
- Capsule Networks: Aim to address the limitations of CNNs by capturing hierarchical relationships between features.
9.2. Edge Computing and IoT
Deep learning models are increasingly being deployed on edge devices, such as smartphones, drones, and IoT devices. This enables real-time processing and decision-making without relying on cloud connectivity.
9.3. Ethical Considerations
As deep learning becomes more prevalent, ethical considerations are becoming increasingly important. Issues such as bias, fairness, and privacy need to be addressed to ensure that deep learning is used responsibly.
10. Resources for Continued Learning
Expand your knowledge with these valuable resources.
10.1. Online Courses and Specializations
- Coursera: Offers a wide range of deep learning courses and specializations from top universities and institutions.
- edX: Provides access to deep learning courses from leading universities around the world.
- Udacity: Offers nanodegree programs in deep learning and related fields.
10.2. Books and Publications
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: A comprehensive textbook covering the fundamentals of deep learning.
- “Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow” by Aurélien Géron: A practical guide to building machine learning and deep learning models using Python.
- Journal of Machine Learning Research (JMLR): A leading academic journal in the field of machine learning and deep learning.
10.3. Communities and Forums
- Stack Overflow: A popular question-and-answer website for programmers and data scientists.
- Reddit (r/MachineLearning, r/DeepLearning): Online communities for discussing machine learning and deep learning topics.
- Kaggle: A platform for data science competitions and collaboration.
Remember, LEARNS.EDU.VN is here to support your learning journey. We offer a range of resources and courses designed to help you master deep learning. Our expert-led tutorials, hands-on projects, and community forums provide everything you need to succeed.
FAQ: Frequently Asked Questions About Learning Deep Learning
1. Can I learn deep learning if I’m not good at math?
While a strong mathematical foundation is beneficial, you can still learn deep learning with a basic understanding of linear algebra, calculus, and statistics. Focus on the practical implementation and gradually deepen your mathematical knowledge as needed.
2. How long does it take to learn deep learning?
The time it takes to learn deep learning depends on your background, learning style, and goals. With consistent effort, you can grasp the basics in a few months and develop advanced skills over several years.
3. Is it necessary to have a powerful computer for deep learning?
While a powerful computer with a GPU can accelerate training, you can start with cloud-based platforms like Google Colab or AWS SageMaker, which offer free or low-cost access to computing resources.
4. What are the best resources for learning deep learning online?
Coursera, edX, and Udacity offer excellent deep learning courses and specializations. Additionally, websites like TensorFlow and PyTorch provide comprehensive tutorials and documentation.
5. How can I stay updated with the latest advancements in deep learning?
Follow leading researchers and institutions on social media, attend conferences and workshops, and regularly read academic journals and publications.
6. What are the most in-demand skills in the field of deep learning?
Proficiency in Python, TensorFlow, PyTorch, and Keras, as well as a strong understanding of neural network architectures, optimization algorithms, and evaluation metrics are highly valued.
7. Can deep learning be applied to fields outside of technology?
Yes, deep learning is being applied to a wide range of fields, including healthcare, finance, agriculture, and environmental science. Its ability to analyze complex data and make predictions makes it a valuable tool in many domains.
8. What are the ethical considerations of using deep learning?
Ethical considerations include bias in data, fairness in algorithms, privacy of personal information, and accountability for decisions made by AI systems.
9. How do I choose the right deep learning framework for my project?
Consider the ease of use, flexibility, community support, and availability of resources. Keras is often recommended for beginners, while TensorFlow and PyTorch are more suitable for advanced users.
10. How can I contribute to the deep learning community?
You can contribute by participating in open-source projects, writing tutorials, answering questions on forums, and sharing your knowledge and experiences with others.
 Neural Network Layers
Neural Network Layers
Conclusion: Your Journey into Deep Learning Starts Now
You can absolutely learn deep learning without machine learning. By focusing on the core concepts, building a strong foundation, and engaging in practical projects, you can master this exciting field. Remember to stay updated with the latest advancements and ethical considerations, and never stop learning.
Ready to take the next step? Visit LEARNS.EDU.VN today and explore our comprehensive deep learning resources and courses. Whether you’re a beginner or an experienced learner, we have everything you need to achieve your goals. Don’t wait – start your deep learning journey now!
For more information, contact us at:
Address: 123 Education Way, Learnville, CA 90210, United States
Whatsapp: +1 555-555-1212
Website: LEARNS.EDU.VN
Explore neural network architectures, convolutional neural networks (CNNs), and recurrent neural networks (RNNs) at learns.edu.vn. Master forward propagation, back propagation, and weight updates with expert guidance. Discover deep learning and artificial intelligence.