In-context Learning, an innovative method in natural language processing, allows language models to perform new tasks without explicit retraining. This article from LEARNS.EDU.VN delves into the mechanics, applications, and potential of this transformative learning approach, offering insights into how it’s reshaping AI and education. Discover how to leverage contextual understanding, zero-shot learning, and few-shot learning to improve learning outcomes.
1. What Is In-Context Learning (ICL) And Why Is It Important?
In-context learning (ICL) is a method where task demonstrations are naturally integrated into prompts, enabling pre-trained Large Language Models (LLMs) to tackle new tasks without fine-tuning. This approach marks a significant shift from traditional machine learning, which often requires extensive retraining for each new task. ICL’s importance lies in its ability to leverage existing knowledge within LLMs to solve problems more efficiently, thereby reducing computational overhead and accelerating the deployment of AI solutions.
Unlike supervised learning, ICL doesn’t update model parameters but relies on pre-trained language models to make predictions, identifying patterns within the provided latent space. In-context learning, sometimes referred to as few-shot learning or few-shot prompting, offers a transient knowledge accumulation, ensuring model parameter stability post-inference. Its effectiveness stems from utilizing extensive pre-training data and the expansive model scale of LLMs, allowing the understanding and execution of novel tasks without a complete training process.
1.1 Why Should In-Context Learning (ICL) Be Considered?
In-Context Learning (ICL) should be considered because it provides an intuitive way to interact with large language models (LLMs), simplifying the integration of human expertise by modifying sample cases and templates. This mirrors human cognitive reasoning, making it a more natural approach to problem-solving.
ICL provides competitive performance across various NLP benchmarks, even when compared with models trained on a more extensive labeled dataset. According to a study by Stanford AI Lab, ICL’s ability to exploit pre-training data and expansive model scale makes it a superior alternative to traditional machine learning methods. Furthermore, the computational overhead for task-specific model adaptation is significantly less, paving the way for deploying language models as a service, facilitating their application in real-world scenarios.
2. How Does In-Context Learning Work In Large Language Models?
In-context learning operates on the principle of learning by analogy, allowing models to generalize from minimal examples. In this approach, a task description or set of examples is presented as a prompt to the model, formulated in natural language. This prompt acts as a semantic prior, guiding the model’s chain of thought and subsequent output.
Unlike traditional machine learning methods like linear regression, in-context learning works on pre-trained models and does not involve parameter updates. Research indicates that the model’s ability to perform in-context learning improves with an increasing number of model parameters. During pre-training, models acquire a broad range of semantic prior knowledge from training data, which aids in task-specific learning representations. This pre-training data serves as the foundation upon which in-context learning builds, enabling the model to perform complex tasks with minimal additional input.
2.1 Bayesian Inference Framework
The Bayesian Inference Framework explains that in-context learning is an emergent behavior where the model performs tasks by conditioning on input-output examples without optimizing any parameters. The model uses the prompt to “locate” latent concepts acquired during pre-training, differing from traditional machine learning algorithms that rely on backpropagation for parameter updates. This framework provides a mathematical foundation for understanding how the model sharpens the posterior distribution over concepts based on the prompt, effectively “learning” the concept.
It emphasizes the role of latent concept variables containing various document-level statistics. These latent concepts create long-term coherence in the text and are crucial for the emergence of in-context learning. The model learns to infer these latent concepts during pre-training, which later aids in in-context learning. This aligns with the idea that pre-training data is the foundation for in-context learning, allowing the model to perform complex tasks with minimal additional input.
2.2 Approaches for In-Context Learning
In-context learning offers flexibility regarding the number of examples required for task adaptation, with three primary approaches: few-shot learning, one-shot learning, and zero-shot learning. Each method leverages the model’s pre-training and existing model scale to adapt to new tasks.
| Approach | Description | Use Case |
|---|---|---|
| Few-Shot Learning | Utilizes multiple input-output pairs as examples for the model to understand and generalize. | Complex tasks where several examples help the model understand nuances. |
| One-Shot Learning | Provides the model with a single input-output example to understand the task. | Domain-specific tasks with scarce data but clear input-output relationships. |
| Zero-Shot Learning | Relies solely on the task description and pre-existing training data to infer requirements. | Testing the model’s innate abilities to generalize to new tasks without explicit examples. |


The choice between these approaches often depends on the availability of labeled data, the complexity of the task, and the computational resources at hand.
2.3 Strategies to Exploit In-Context Learning: Prompt Engineering
Prompt engineering is crucial for exploiting in-context learning (ICL) in large language models (LLMs), involving the careful crafting of prompts to provide clear instructions and context to the model. This technique enhances performance on a given task by incorporating multiple demonstration examples across different tasks and ensuring well-defined input-output correspondence.
Few-shot learning is often combined with prompt engineering to provide a more robust framework, enabling the model to better understand the task description and generate more accurate output by incorporating a few examples within the prompt. While prompt engineering has shown promise, it faces challenges, with small modifications to the prompt potentially causing large variations in the model’s output. Future research is needed to make this process more robust and adaptable to various tasks.
2.4 Variants of In-Context Learning in Large Language Models
There are various approaches of In-Context Learning, namely, Regular ICL, Flipped-Label ICL, and Semantically-Unrelated Label ICL (SUL-ICL). Each approach tests the model’s reliance on semantic priors and its ability to learn new mappings from scratch.
| Variant | Description | Learning Emphasis |
|---|---|---|
| Regular ICL | Utilizes semantic prior knowledge to predict labels based on the format of in-context examples. | Leverages pre-trained understanding of concepts. |
| Flipped-Label ICL | Reverses the labels of in-context examples, forcing the model to override its semantic priors. | Challenges adherence to input-label mappings; tests the override of pre-trained knowledge. |
| SUL-ICL | Replaces labels with semantically unrelated terms, directing the model to learn input-label mappings from scratch. | Focuses on adapting to new task descriptions without relying on pre-trained semantics. |
While instruction tuning enhances the model’s capacity for learning input-label mappings, it also strengthens its reliance on semantic priors, making it an important tool for optimizing ICL performance.
2.5 Chain-of-Thought Prompting
Chain-of-thought (COT) Prompting enhances the reasoning capabilities of LLMs by incorporating intermediate reasoning steps into the prompt, particularly effective when combined with few-shot prompting for complex reasoning tasks.
Zero-shot COT Prompting extends this by adding the phrase “Let’s think step by step” to the original prompt, useful in scenarios with limited examples. This approach is closely related to In-Context Learning (ICL), as both techniques aim to leverage LLMs’ pre-training data and model parameters for task-specific learning, with ICL focusing on few-shot learning and prompt engineering, while COT Prompting emphasizes the chain of thought, prompting complex reasoning.
3. What Are The Real-Life Applications Of In-Context Learning?
In-context learning (ICL) is a transformative approach that enables large language models (LLMs) to adapt to new tasks without explicit retraining. The real-world applications of ICL are vast and span various sectors, showcasing the versatility and potential of this learning paradigm.
| Application | Description | Impact |
|---|---|---|
| Sentiment Analysis | LLMs can determine sentiment accurately with just a few example sentences, revolutionizing customer feedback and market research. | Enhances analysis speed and accuracy, providing actionable insights for businesses. |
| Customized Task Learning | LLMs learn to perform tasks by being shown a few examples, reducing time and resources required for new task adaptation. | Facilitates rapid adaptation to changing industry requirements and enhances operational agility. |
| Language Translation | The model translates new sentences by providing a few input-output pairs in different languages, bridging communication gaps. | Improves communication in global businesses, enabling seamless interaction across different languages. |
| Code Generation | The model generates code for new, similar problems by feeding it with a few examples of a coding problem and its solution. | Expedites software development, reducing manual coding efforts and increasing efficiency. |
| Medical Diagnostics | The model diagnoses new cases by showing a few examples of medical symptoms and their corresponding diagnoses. | Aids medical professionals in making informed decisions and providing timely care, improving healthcare outcomes. |
4. What Are The Challenges, Limitations, And Current Research Areas in ICL?
In-context learning (ICL) allows models to adapt and learn from new input-output pairs without explicit retraining, but it also presents several challenges and limitations:
Model Parameters and Scale: ICL efficiency is closely tied to the model’s scale, with smaller models exhibiting different proficiency levels than larger ones.
Training Data Dependency: The effectiveness of ICL relies on the quality and diversity of training data, where inadequate or biased data can lead to suboptimal performance.
Domain Specificity: While LLMs can generalize across various tasks, limitations may arise when dealing with highly specialized domains, requiring domain-specific data for optimal results.
Model Fine-Tuning: Even with ICL, model fine-tuning may be necessary to cater to specific tasks or correct undesirable emergent abilities.
The ICL research landscape is rapidly evolving, probing into the underlying mechanisms, training data, prompts, and architectural nuances that give rise to ICL. This research aims to address these limitations and enhance the applicability of ICL across various domains.
4.1 Research Papers
The research landscape in ICL is evolving rapidly. Here are summaries of three important research papers on in-context learning (ICL) from 2023:
4.1.1 Learning to Retrieve In-Context Examples for Large Language Models
This paper introduces a unique framework to iteratively train dense retrievers that can pinpoint high-quality in-context examples for LLMs. The method first establishes a reward model based on LLM feedback to assess candidate example quality, followed by employing knowledge distillation to cultivate a bi-encoder-based dense retriever. Experimental outcomes across 30 tasks reveal that this framework considerably bolsters in-context learning performance and exhibits adaptability to tasks not seen during training.
4.1.2 Structured Prompting: Scaling In-Context Learning to 1,000 Examples
This paper introduces structured prompting, a method that transcends these length limitations and scales in-context learning to thousands of examples. The approach encodes demonstration examples with tailored position embeddings, which are then collectively attended by the test example using a rescaled attention mechanism. Experimental results across various tasks indicate that this method enhances performance and diminishes evaluation variance compared to conventional in-context learning.
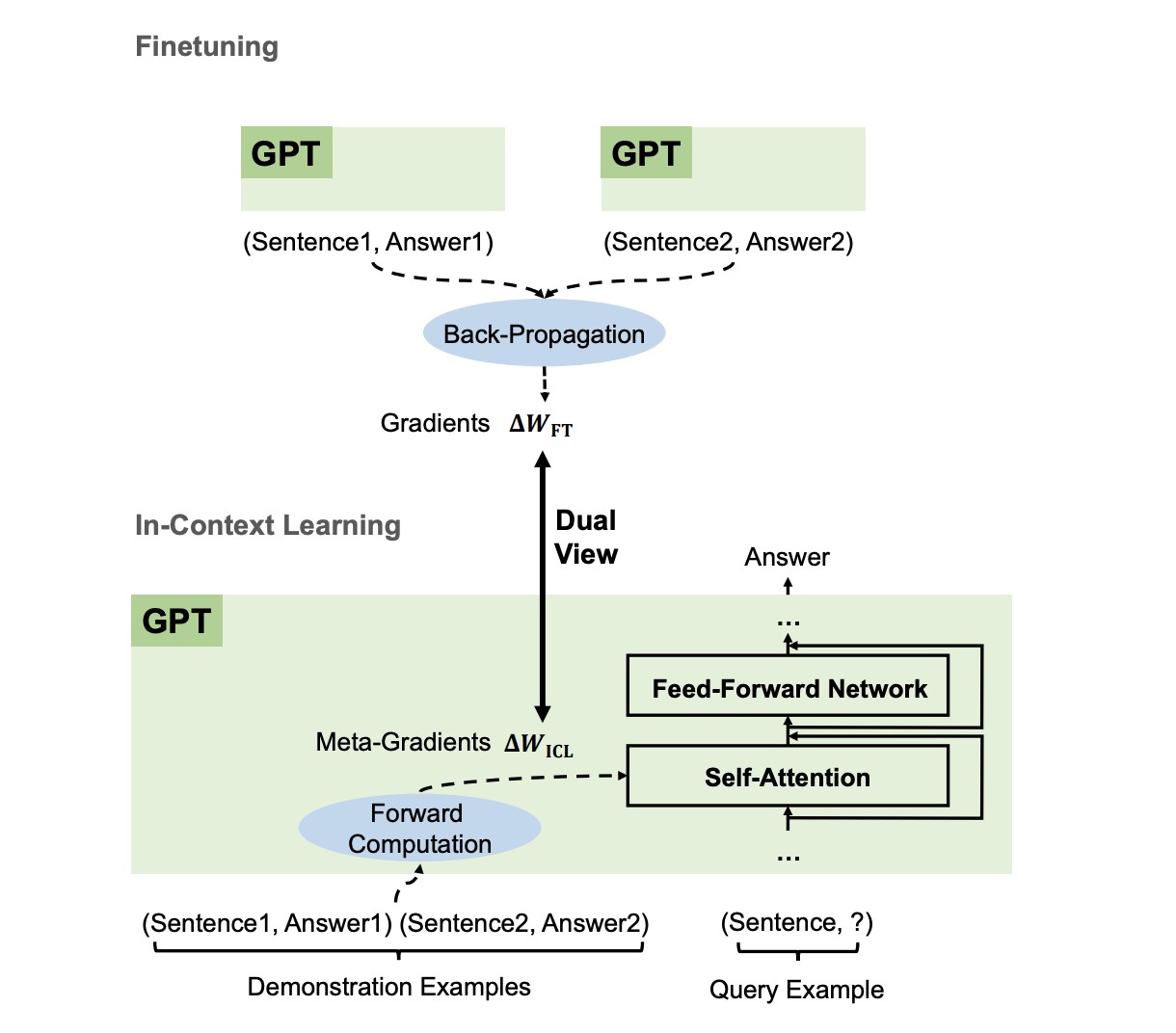
4.1.3 Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers
This paper delves into the underlying mechanism of this phenomenon, proposing that language models act as meta-optimizers and that ICL can be viewed as implicit fine-tuning. The research identifies a dual relationship between Transformer attention and gradient descent, suggesting that GPT generates meta-gradients based on demonstration examples to construct an ICL model. Experimental findings indicate that ICL’s behavior mirrors explicit fine-tuning in various aspects.
5. Key Takeaways On In-Context Learning
In summary, In-Context Learning (ICL) emerges as a transformative technique in the realm of large language models (LLMs). It enables LLMs to adapt to new tasks without explicit retraining or fine-tuning, leveraging natural language prompts for instruction. The efficacy of ICL is intricately linked to factors such as the model’s scale, the quality of training data, and the specificity of the domain. As a pivotal strategy, prompt engineering plays a crucial role in harnessing the capabilities of ICL.
FAQ: In-Context Learning
5.1 What is In-Context Learning (ICL)?
In-context learning (ICL) is a technique that allows large language models (LLMs) to perform new tasks without updating the model’s parameters. The model learns from the context provided in the input prompt, which includes task demonstrations in natural language.
5.2 How does In-Context Learning differ from traditional machine learning?
Unlike traditional machine learning, which requires a training phase involving backpropagation to modify model parameters, ICL operates without updating these parameters. It executes predictions using pre-trained language models, identifying patterns within the provided context.
5.3 What are the main approaches to In-Context Learning?
The main approaches are few-shot learning, where the model is given multiple examples; one-shot learning, with a single example; and zero-shot learning, where no examples are provided, and the model relies solely on its pre-existing knowledge.
5.4 Why is Prompt Engineering important in In-Context Learning?
Prompt engineering is crucial because it involves crafting effective prompts that guide the model’s chain of thought, enhancing its performance on a given task. A well-engineered prompt provides clear instructions and context to the model.
5.5 What are some real-world applications of In-Context Learning?
Real-world applications include sentiment analysis, customized task learning, language translation, code generation, and medical diagnostics. ICL enables LLMs to adapt quickly to various tasks, making it versatile across different sectors.
5.6 What are the limitations of In-Context Learning?
Limitations include dependency on the scale of the model, the quality and diversity of training data, and potential challenges when dealing with highly specialized domains. Model fine-tuning may still be necessary in certain scenarios.
5.7 How does Chain-of-Thought Prompting enhance In-Context Learning?
Chain-of-thought (COT) prompting enhances the reasoning capabilities of LLMs by incorporating intermediate reasoning steps into the prompt. This technique is particularly effective when combined with few-shot prompting for complex reasoning tasks.
5.8 What role does pre-training play in In-Context Learning?
Pre-training is foundational for ICL. During pre-training, models acquire a broad range of semantic prior knowledge from the training data, which later aids in task-specific learning representations. This pre-training data allows the model to perform complex tasks with minimal additional input.
5.9 Can In-Context Learning address biases in training data?
ICL can be limited by biases present in the training data. While it can adapt to new tasks, it may also perpetuate biases learned during pre-training. Addressing biases requires careful curation of training data and ongoing evaluation of model outputs.
5.10 Where can I learn more about In-Context Learning and related techniques?
You can explore comprehensive guides and resources at LEARNS.EDU.VN, including articles on prompt engineering, large language models, and machine learning techniques. Additionally, explore research papers and publications from leading AI labs to deepen your understanding.
Want to unlock your full learning potential? Explore LEARNS.EDU.VN today for more insightful articles, comprehensive guides, and expert resources designed to help you master new skills and excel in your studies. Whether you’re a student, a professional, or simply a curious mind, LEARNS.EDU.VN offers the tools and knowledge you need to succeed. Visit us at 123 Education Way, Learnville, CA 90210, United States, or reach out via WhatsApp at +1 555-555-1212. Start your learning journey with learns.edu.vn today.