Adversarial Machine Learning represents a critical frontier in artificial intelligence, a vital area to comprehend in today’s digital landscape. This field, explored extensively at LEARNS.EDU.VN, delves into techniques that attempt to deceive machine learning models through cleverly crafted, deceptive data. Discover how to safeguard your AI systems by exploring strategies against adversarial attacks, ensuring robust and reliable AI implementations. Unlock essential strategies for defense, model security, and anomaly detection.
1. Understanding the Core of Adversarial Machine Learning
Adversarial machine learning is an innovative field focused on understanding and mitigating vulnerabilities in machine learning models. This branch of AI studies how to deceive models using deceptive inputs, emphasizing the importance of both generating and detecting adversarial examples. These examples are specifically designed to mislead classifiers, causing them to make incorrect predictions. The core objective is to fortify machine learning systems against malicious attacks, ensuring their reliability and security in various applications. Think of it as cybersecurity for AI, ensuring the integrity and safety of automated systems.
1.1. Defining Adversarial Examples
An adversarial example is essentially a “trick input” designed to fool a machine learning model. It’s a carefully crafted input that causes the model to make mistakes in its predictions, even though it appears valid to a human observer. These examples are designed to exploit vulnerabilities in the model’s decision-making process. Consider it a mirage for AI, appearing genuine but leading the system astray. These attacks highlight the importance of robust model evaluation and validation techniques.
1.2. White-Box vs. Black-Box Attacks: Understanding the Difference
Adversarial attacks come in different flavors, depending on how much information the attacker has about the target model:
- White-Box Attacks: In a white-box attack scenario, the attacker possesses complete knowledge of the target model, including its architecture, parameters, and training data. This allows them to craft highly targeted attacks, exploiting specific weaknesses in the model. Think of it as having the blueprints to the enemy’s fortress, making it easier to find and exploit vulnerabilities.
- Black-Box Attacks: In contrast, a black-box attack occurs when the attacker has limited or no information about the target model. They can only observe the model’s inputs and outputs, without knowing its internal workings. This makes it more challenging to craft effective attacks, as the attacker must rely on trial and error or transferability from other models. Think of it as trying to crack a safe without knowing the combination, requiring ingenuity and persistence.
2. The Growing Threat of Adversarial Attacks in Machine Learning
As machine learning becomes increasingly integral to organizational operations, the need to protect these systems from adversarial attacks is escalating rapidly. This rise positions Adversarial Machine Learning as a critical field within the software industry, focusing on safeguarding the integrity and reliability of machine learning implementations. Consider that a compromised AI system can lead to severe consequences, emphasizing the importance of robust security measures. This situation underscores the importance of proactive security measures in safeguarding sensitive AI systems.
2.1. Industry Leaders Taking Action
Leading tech giants such as Google, Microsoft, and IBM are now investing heavily in securing machine learning systems. Recent years have seen companies with significant investments in machine learning—including Google, Amazon, Microsoft, and Tesla—experiencing adversarial attacks. These incidents highlight the pervasive threat and underscore the need for robust security measures across all levels of machine learning deployment. Proactive steps are essential to mitigate risks and safeguard the integrity of AI systems.
2.2. Government Regulations and Security Standards
Governments worldwide are beginning to implement security standards for machine learning systems, with the European Union leading the way by releasing a comprehensive checklist for assessing the trustworthiness of AI systems, known as the Assessment List for Trustworthy Artificial Intelligence (ALTAI). These initiatives signal a growing recognition of the importance of AI security and the need for standardized approaches to ensure responsible and secure AI development. Compliance with these standards is crucial for organizations deploying AI systems.
2.3. Expert Insights on Data Manipulation Risks
Gartner, a leading industry market research firm, advises that application leaders must anticipate and prepare to mitigate potential risks of data corruption, model theft, and adversarial samples. This guidance emphasizes the importance of proactive security measures to safeguard machine learning systems from malicious attacks and ensure the integrity of AI implementations. A forward-thinking approach to security is essential in maintaining the reliability of AI systems.
3. How Adversarial AI Attacks Work: A Deep Dive
Adversarial attacks target vulnerabilities in machine learning systems, with many effective against both deep learning and traditional models like Support Vector Machines (SVMs) and linear regression. These attacks aim to degrade the performance of classifiers, essentially “fooling” the algorithms by exploiting their decision-making processes. Understanding these methods is crucial for developing robust defense strategies.
3.1. Classifying Adversarial Attacks
Adversarial attacks can be broadly classified into three main categories, each targeting different aspects of the machine learning process:
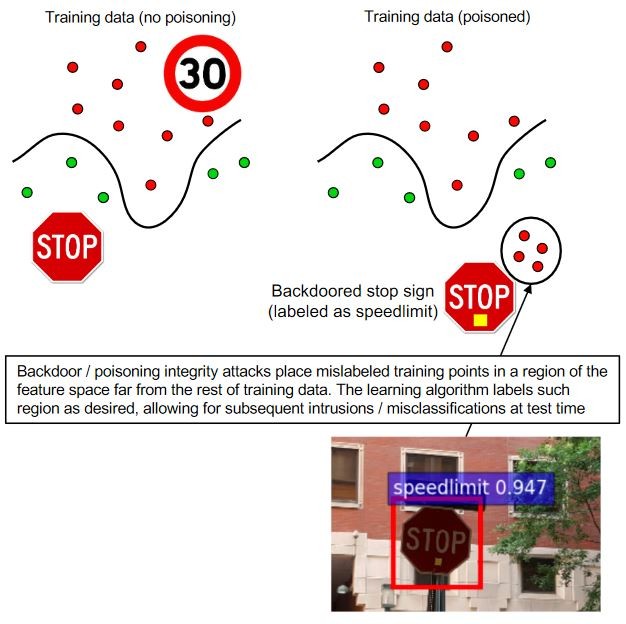
- Poisoning Attacks: Poisoning attacks involve manipulating the training data or its labels to cause the model to underperform during deployment. This is essentially an adversarial contamination of the data used to train the model, leading to biased or inaccurate results. Think of it as injecting misinformation into a student’s textbook, causing them to learn the wrong things.
- Evasion Attacks: Evasion attacks focus on manipulating the data during deployment to deceive previously trained classifiers. These attacks are often used in intrusion and malware scenarios, where attackers attempt to evade detection by obfuscating the content of malicious software or spam emails. The aim is to make the malicious input appear legitimate, allowing it to bypass security measures.
- Model Extraction Attacks: Model extraction involves an attacker probing a black-box machine learning system to reconstruct the model or extract the data it was trained on. This can be particularly damaging when the training data or the model itself is sensitive and confidential, such as in the case of a stock market prediction model.
4. Illustrative Examples of Adversarial Machine Learning in Action
To illustrate the power and subtlety of adversarial machine learning, let’s look at some real-world examples:
- Image Recognition: A classic example involves modifying an image in a way that is imperceptible to the human eye, but causes a machine learning model to misclassify it. For example, adding a small amount of noise to an image of a panda can cause the model to identify it as a gibbon.
- Spam Detection: Adversarial techniques can be used to craft spam emails that bypass spam filters. By carefully manipulating the content and structure of the email, attackers can make it appear legitimate and avoid detection.
- Self-Driving Cars: Imagine an adversarial attack that causes a self-driving car to misinterpret a stop sign as a speed limit sign. This could have catastrophic consequences, leading to accidents and injuries.
- Medical Diagnosis: Adversarial examples could be used to manipulate medical images, such as X-rays or MRIs, to mislead diagnostic algorithms. This could lead to incorrect diagnoses and inappropriate treatment.
These examples highlight the potential risks of adversarial machine learning and the importance of developing robust defenses.
5. Detailed Overview of Popular Adversarial AI Attack Methods
Here’s an expanded look at some commonly used adversarial attack methods:
| Attack Method | Description | Advantages | Disadvantages |
|---|---|---|---|
| Limited-memory BFGS (L-BFGS) | Optimizes perturbations to minimize added noise in images. | Effective at creating adversarial examples. | Computationally intensive and time-consuming. |
| Fast Gradient Sign Method (FGSM) | Efficiently generates adversarial examples by minimizing maximum added perturbation to any pixel. | Comparatively quick computation times. | Perturbations added to every feature. |
| Jacobian-based Saliency Map Attack (JSMA) | Selectively modifies features by adding perturbations according to saliency value to cause misclassification. | Perturbs very few features. | More computationally intensive than FGSM. |
| DeepFool Attack | Minimizes Euclidean distance between perturbed and original samples using decision boundary estimations. | Effective, with fewer perturbations and high misclassification rates. | More computationally intensive than FGSM and JSMA; suboptimal examples. |
| Carlini & Wagner Attack (C&W) | Efficiently generates adversarial examples, defeating defenses through optimization problems without box constraints. | Very effective; capable of defeating some defenses. | More computationally intensive than FGSM, JSMA, and DeepFool. |
| Generative Adversarial Networks (GANs) | Networks compete to generate adversarial attacks, with one acting as a generator and the other as a discriminator. | Generates samples different from those used in training. | Training is computationally intensive and can be unstable. |
| Zeroth-order Optimization Attack (ZOO) | Estimates classifier gradients without direct access, suitable for black-box attacks, using methods like Adam or Newton’s. | Similar performance to C&W; requires no classifier information. | Requires many queries to the target classifier. |

5.1. Limited-memory BFGS (L-BFGS)
The Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) method is a sophisticated non-linear gradient-based numerical optimization algorithm. It aims to minimize the number of perturbations added to images, making it a popular choice for generating adversarial examples.
- Advantages: Highly effective at generating adversarial examples.
- Disadvantages: Computationally intensive, as it is an optimized method with box constraints. The method can be time-consuming and impractical for real-time applications.
5.2. Fast Gradient Sign Method (FGSM)
The Fast Gradient Sign Method (FGSM) is a simple and fast gradient-based approach used to generate adversarial examples. It minimizes the maximum amount of perturbation added to any pixel of the image to cause misclassification.
- Advantages: Offers comparatively efficient computing times, making it suitable for quick experimentation.
- Disadvantages: Perturbations are added to every feature, which can make the adversarial example more detectable.
5.3. Jacobian-based Saliency Map Attack (JSMA)
Unlike FGSM, the Jacobian-based Saliency Map Attack (JSMA) uses feature selection to minimize the number of features modified while causing misclassification. Flat perturbations are added to features iteratively according to their saliency value, decreasing in order.
- Advantages: Perturbs very few features, making the adversarial example more subtle.
- Disadvantages: More computationally intensive than FGSM due to the need to calculate saliency maps.
5.4. DeepFool Attack
DeepFool is an untargeted adversarial sample generation technique that aims to minimize the Euclidean distance between perturbed samples and original samples. It estimates decision boundaries between classes and adds perturbations iteratively.
- Advantages: Effective at producing adversarial examples with fewer perturbations and higher misclassification rates.
- Disadvantages: More computationally intensive than FGSM and JSMA. Also, adversarial examples are likely not optimal.
5.5. Carlini & Wagner Attack (C&W)
The Carlini & Wagner Attack (C&W) is a technique based on the L-BFGS attack (optimization problem) but without box constraints and with different objective functions. This makes the method more efficient at generating adversarial examples. It has been shown to defeat state-of-the-art defenses, such as defensive distillation and adversarial training.
- Advantages: Very effective at producing adversarial examples. Also, it can defeat some adversarial defenses.
- Disadvantages: More computationally intensive than FGSM, JSMA, and DeepFool.
5.6. Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GANs) have been used to generate adversarial attacks, where two neural networks compete with each other. One acts as a generator, and the other behaves as the discriminator. The two networks play a zero-sum game, where the generator tries to produce samples that the discriminator will misclassify. Meanwhile, the discriminator tries to distinguish real samples from ones created by the generator.
- Advantages: Generation of samples different from the ones used in training, potentially uncovering new vulnerabilities.
- Disadvantages: Training a Generate Adversarial Network is very computationally intensive and can be highly unstable.
5.7. Zeroth-Order Optimization Attack (ZOO)
The Zeroth-order Optimization Attack (ZOO) technique allows the estimation of the gradient of the classifiers without access to the classifier, making it ideal for black-box attacks. The method estimates gradient and Hessian by querying the target model with modified individual features and uses Adam or Newton’s method to optimize perturbations.
- Advantages: Similar performance to the C&W attack. No training of substitute models or information on the classifier is required.
- Disadvantages: Requires a large number of queries to the target classifier, which can be time-consuming and expensive.
6. Defense Strategies: Strengthening Machine Learning Models
Now, let’s shift our focus to the other side of the coin: defense strategies. How can we make machine learning models more resilient to adversarial attacks?
6.1. Adversarial Training
Adversarial training is a technique that involves training a model on both clean and adversarial examples. This helps the model learn to recognize and resist adversarial perturbations. Think of it as vaccinating the model against adversarial attacks. By exposing the model to these threats during training, it becomes better equipped to handle them in the real world.
6.2. Defensive Distillation
Defensive distillation is a technique that involves training a new model on the soft predictions of a pre-trained model. This can help to smooth the decision boundaries of the model, making it less susceptible to adversarial attacks. The distilled model learns to generalize better and is less likely to be fooled by small perturbations.
6.3. Input Preprocessing
Input preprocessing techniques involve modifying the input data before feeding it to the model. This can include techniques like:
- Image Denoising: Removing noise from images can help to reduce the impact of adversarial perturbations.
- Image Compression: Compressing images can help to remove high-frequency components that are often targeted by adversarial attacks.
- Feature Squeezing: Reducing the number of features in the input data can make it harder for attackers to craft effective adversarial examples.
6.4. Anomaly Detection
Anomaly detection techniques can be used to identify adversarial examples by detecting inputs that deviate significantly from the training data. These techniques can be used as a first line of defense against adversarial attacks. If an input is flagged as an anomaly, it can be further scrutinized or rejected altogether.
7. The Future of Adversarial Machine Learning
Machine learning introduces a new attack surface, escalating security risks through potential data manipulation and exploitation. Organizations adopting machine learning must anticipate potential risks, establishing robust defenses against data corruption, model theft, and adversarial samples.
7.1. Key Developments to Watch
- Advanced Defense Mechanisms: Expect to see more sophisticated defense mechanisms emerge, combining multiple techniques to provide comprehensive protection against adversarial attacks.
- Explainable AI (XAI): XAI techniques can help to understand how machine learning models make decisions, making it easier to identify and mitigate vulnerabilities.
- Adversarial Robustness Certification: Formal methods for certifying the robustness of machine learning models against adversarial attacks will become increasingly important.
- Collaboration and Standardization: Collaboration between researchers, industry practitioners, and policymakers will be essential to develop standards and best practices for adversarial machine learning.
7.2. LEARNS.EDU.VN: Your Partner in AI Security
At LEARNS.EDU.VN, we are committed to providing you with the knowledge and resources you need to navigate the complex world of adversarial machine learning. Our comprehensive educational resources cover:
- In-depth articles and tutorials on adversarial attacks and defenses
- Practical guides on implementing security measures for machine learning systems
- Expert insights from leading researchers and practitioners in the field
- A supportive community where you can connect with other learners and share your knowledge
Visit LEARNS.EDU.VN today to explore our extensive collection of articles and courses on adversarial machine learning. Strengthen your knowledge base and equip yourself with the necessary tools to excel in this dynamic field. Our platform offers detailed guidance, practical strategies, and expert support to help you master adversarial machine learning.
8. Actionable Steps: Securing Your Machine Learning Systems
Here’s a step-by-step guide to get you started:
- Assess Your Risk: Identify the potential threats to your machine learning systems. Consider the sensitivity of your data, the criticality of your applications, and the potential impact of an adversarial attack.
- Implement Basic Defenses: Start with simple but effective defenses, such as input preprocessing and adversarial training.
- Monitor Your Systems: Continuously monitor your machine learning systems for signs of adversarial activity.
- Stay Up-to-Date: The field of adversarial machine learning is constantly evolving, so it’s important to stay up-to-date on the latest threats and defenses.
- Consult with Experts: If you need help, don’t hesitate to consult with experts in adversarial machine learning.
9. Frequently Asked Questions (FAQ) about Adversarial Machine Learning
- What is adversarial machine learning?
Adversarial machine learning involves techniques that attempt to fool machine learning models using deceptive input, focusing on generating and detecting adversarial examples. - What are adversarial examples?
Adversarial examples are inputs to machine learning models that are purposely designed to cause the model to make mistakes in its predictions, resembling valid inputs to humans. - What is the difference between white-box and black-box attacks?
A white-box attack is when the attacker has complete access to the model’s architecture and parameters, whereas a black-box attack is when the attacker has no access and can only observe the model’s outputs. - Why is adversarial machine learning important?
It’s important to protect machine learning systems from manipulation and exploitation, ensuring the reliability and security of AI implementations. - What are some common adversarial attack methods?
Common methods include L-BFGS, FGSM, JSMA, DeepFool, C&W, GANs, and ZOO, each with unique advantages and disadvantages in generating deceptive inputs. - How can machine learning models be defended against adversarial attacks?
Defenses include adversarial training, defensive distillation, input preprocessing, and anomaly detection, which enhance the model’s resilience. - What is adversarial training?
Adversarial training involves training a model on both clean and adversarial examples to help it learn to recognize and resist adversarial perturbations. - What are Generative Adversarial Networks (GANs) used for in adversarial machine learning?
GANs are used to generate adversarial attacks by having two neural networks compete, one generating attacks and the other distinguishing real from fake samples. - How does the Zeroth-Order Optimization (ZOO) attack work?
The ZOO technique estimates classifier gradients without direct access, making it suitable for black-box attacks by querying the target model with modified features. - Where can I learn more about adversarial machine learning and AI security?
Visit LEARNS.EDU.VN for in-depth articles, tutorials, practical guides, and expert insights on securing machine learning systems.
10. Conclusion: Embracing a Secure AI Future
Adversarial machine learning is a rapidly evolving field with significant implications for the security and reliability of AI systems. By understanding the threats and implementing appropriate defenses, we can harness the power of machine learning while mitigating the risks.
Remember, security is not a one-time fix but an ongoing process. Stay informed, stay vigilant, and work together to build a secure AI future.
Unlock a wealth of knowledge and skills by exploring LEARNS.EDU.VN. Whether you’re aiming to master a new discipline, deepen your comprehension of a concept, or refine your learning methodologies, LEARNS.EDU.VN is your ultimate ally. Elevate your educational journey with resources crafted by seasoned educators.
For further information, visit us at 123 Education Way, Learnville, CA 90210, United States. Contact us via Whatsapp at +1 555-555-1212 or explore our website at learns.edu.vn.
