Low-Rank Adaptation (LoRA) has emerged as a pivotal technique for efficiently customizing Large Language Models (LLMs). For those navigating the landscape of open-source LLMs, understanding LoRA is indispensable. This article delves into the crucial aspect of learning rates when finetuning Gemma 2, Google’s open-source LLM, using LoRA. We aim to provide actionable insights and address key questions to optimize your finetuning process and save valuable time.
This article synthesizes practical lessons derived from extensive experimentation with LoRA, building upon previous explorations using the Lit-GPT repository. We aim to guide you through selecting an optimal learning rate for Gemma 2 finetuning, enhancing model performance while maintaining computational efficiency.
Here are the core insights we will explore:
- Consistency in LoRA Finetuning: Understand the reliability of LoRA results across multiple runs despite inherent randomness in LLM training.
- QLoRA Trade-offs: Evaluate the memory savings of QLoRA against its impact on training runtime, and how this affects learning rate considerations.
- Optimizer Selection: Learn why the choice of optimizer is less critical than learning rate tuning for LoRA finetuning, and the subtle differences between SGD and AdamW.
- Memory Implications of Adam: Debunk the myth that Adam’s memory overhead significantly impacts peak memory usage in LLMs, and its relevance to learning rate adjustments.
- Multi-Epoch Training: Discover why iterating multiple times over static datasets might not be beneficial and can lead to performance degradation, influencing learning rate strategies over epochs.
- Comprehensive LoRA Application: Emphasize the importance of applying LoRA across all layers to maximize model performance and its interaction with learning rate effectiveness.
- Hyperparameter Tuning: Explore the crucial interplay between LoRA rank (r), alpha value, and learning rate in achieving optimal results for Gemma 2.
- Efficient Finetuning on Single GPU: Highlight the feasibility of finetuning 7 billion parameter models like Gemma 2 on a single GPU with sufficient RAM, and how learning rate optimization contributes to this efficiency.
Understanding LoRA for Gemma 2 Finetuning
Large Language Models, including Gemma 2, are substantial in size, making full parameter updates during training computationally expensive due to GPU memory constraints.
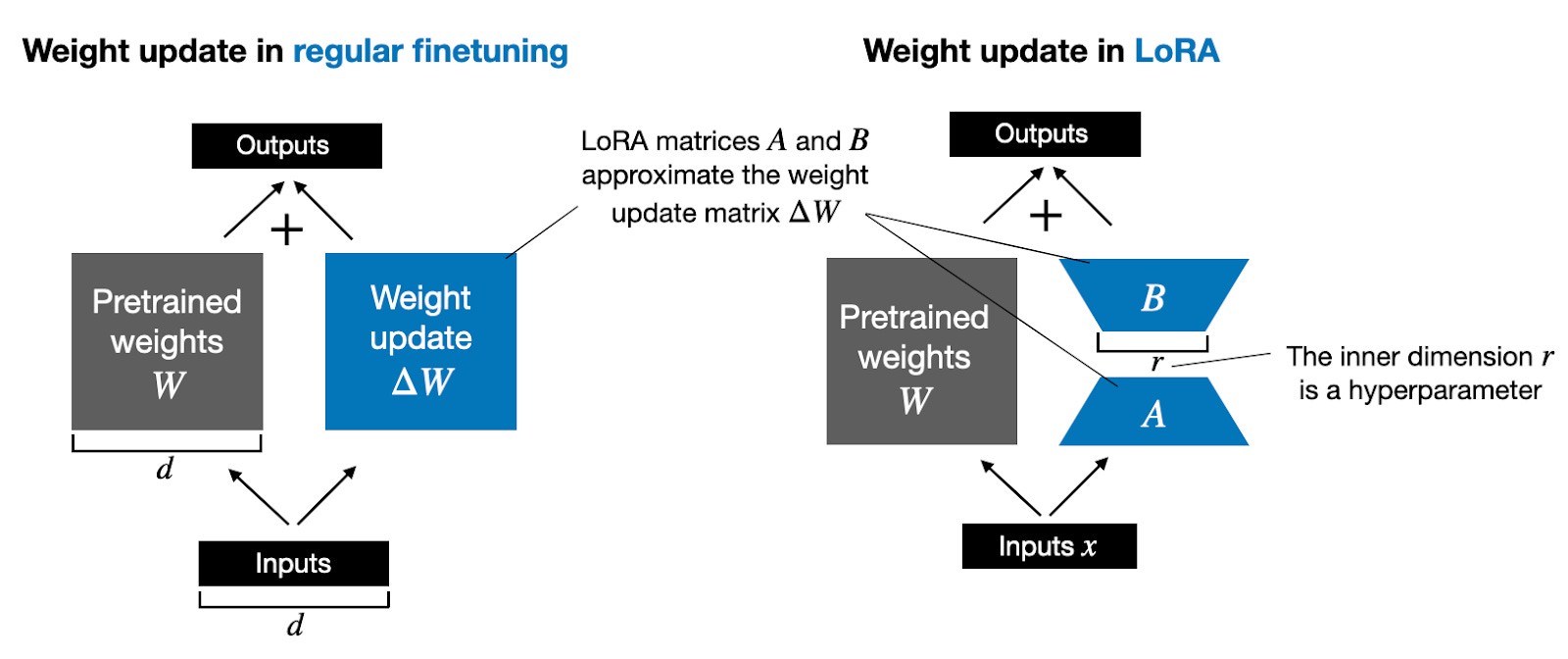
Imagine Gemma 2’s parameters represented as a weight matrix W. During traditional backpropagation, updating all weights involves calculating a ΔW matrix of the same size, which demands significant compute and memory resources.
LoRA, introduced by Hu et al., offers a solution by decomposing the weight updates, ΔW, into a lower-rank representation. Instead of directly computing ΔW, LoRA learns its decomposed form during training. This is where the efficiency gains originate.
The decomposition represents ΔW using two smaller matrices, A and B, such that ΔW = AB. This significantly reduces the number of trainable parameters. For instance, with a rank r, the number of parameters is drastically reduced compared to updating the full ΔW matrix.
This reduction is based on the hypothesis that while pre-trained LLMs require full-rank matrices to capture broad knowledge, finetuning for specific tasks needs only a fraction of these parameters to adapt effectively. LoRA leverages this by focusing on low-rank updates via AB.
1. Consistency of Learning Rate Effects in LoRA
Experiments reveal remarkable consistency in benchmark results across multiple LoRA finetuning runs for Gemma 2, even with the inherent randomness in GPU-based LLM training. This consistency is crucial when evaluating the impact of different learning rates.
Benchmark results showing consistent performance across multiple LoRA finetuning runs, highlighting the reliability for learning rate experiments.
This consistency allows for more reliable comparisons when testing various learning rates and hyperparameters for Gemma 2, ensuring that observed performance changes are genuinely due to the adjustments and not random fluctuations.
2. QLoRA and Learning Rate Considerations
QLoRA (Quantized LoRA) further optimizes memory usage by quantizing pre-trained weights to 4-bit precision during backpropagation and employing paged optimizers. This can save up to 33% of GPU memory, but it introduces a trade-off with a runtime increase of approximately 39% due to quantization and dequantization processes.
For Gemma 2 finetuning, QLoRA can be invaluable when GPU memory is limited. However, the added computational overhead might necessitate adjustments to the learning rate schedule. While QLoRA doesn’t fundamentally change the best learning rate, the slower training process might benefit from a slightly adjusted learning rate schedule or total training steps to achieve comparable performance to standard LoRA.
3. Learning Rate Schedulers for Gemma 2
Learning rate schedulers are vital for optimizing convergence and preventing overshooting during training. For Gemma 2 finetuning with LoRA, cosine annealing schedulers can be particularly effective.
Cosine annealing starts with a higher learning rate and gradually reduces it following a cosine curve. The half-cycle variant, completing only half of the cosine cycle, is often preferred in practice.
Visualization of a cosine annealing learning rate schedule, showing the learning rate’s smooth decrease over training iterations.
Experiments show that cosine annealing can noticeably improve SGD performance in LoRA finetuning. While its impact is less pronounced with Adam and AdamW optimizers, it can still contribute to more stable and efficient training for Gemma 2, especially when using SGD.
For Gemma 2, starting with a learning rate in the range of 1e-4 to 1e-5 and using a cosine annealing scheduler can be a robust starting point. The exact optimal initial learning rate might require fine-tuning based on the dataset and task.
4. AdamW vs. SGD and Learning Rate Selection
AdamW and Adam optimizers are widely used in deep learning despite their memory intensity. They maintain moving averages of gradients, requiring additional memory. SGD, conversely, doesn’t track these parameters.
For Gemma 2 LoRA finetuning, the memory savings from switching from AdamW to SGD might be minimal, especially with low LoRA ranks. This is because the trainable LoRA parameters are a small fraction of the total model parameters.
Comparison of GPU memory usage between AdamW and SGD optimizers in LoRA finetuning scenarios.
However, as the LoRA rank (r) increases, the difference in memory usage between AdamW and SGD becomes more noticeable. While the choice of optimizer is less critical than the learning rate itself, SGD can be a viable option, particularly at higher LoRA ranks or when memory optimization is paramount.
The learning rate should be tuned in conjunction with the optimizer. AdamW might tolerate slightly higher learning rates compared to SGD due to its adaptive nature. For Gemma 2, if using AdamW, a learning rate around 3e-5 to 1e-4 might be suitable, whereas with SGD, a slightly lower range of 1e-5 to 5e-5 could be more appropriate as a starting point.
5. Epochs and Learning Rate Adjustment
In traditional deep learning, multi-epoch training is common. However, for instruction finetuning Gemma 2 with datasets like Alpaca, multiple epochs might not be beneficial and can even degrade performance due to overfitting.
For Gemma 2, especially with instruction datasets, it’s advisable to start with a smaller number of epochs, potentially just one, and monitor validation performance closely. If overfitting is observed, reducing epochs or adjusting the learning rate schedule to decay more aggressively can be beneficial.
The learning rate schedule should be designed considering the number of epochs. With fewer epochs, a slower decay might be suitable, while with more epochs (if deemed necessary), a more rapid decay might be needed to prevent overfitting.
6. LoRA Layer Configuration and Learning Rate
Enabling LoRA for more layers beyond just Key and Value matrices, such as Query, projection layers, MLP layers, and the output layer, increases the number of trainable parameters and can improve model performance.
Diagram illustrating different configurations for enabling LoRA across various layers in a transformer model.
For Gemma 2, applying LoRA to all relevant layers is generally recommended to maximize performance. This increased model capacity might necessitate a slight adjustment in learning rate. A slightly smaller learning rate might be needed when LoRA is applied to more layers to maintain stability and prevent overfitting due to the increased number of trainable parameters.
7. Balancing LoRA Rank, Alpha, and Learning Rate
The LoRA rank (r) and alpha (α) hyperparameters significantly influence model performance. The scaling coefficient, calculated as alpha / r, determines the influence of LoRA weights. A common heuristic is setting alpha to twice the rank value (α = 2*r).
Performance variation with different combinations of LoRA rank (r) and alpha (α) values, highlighting the importance of hyperparameter tuning.
For Gemma 2, while α = 2r is a good starting point, experimenting with different ratios might yield better results. For instance, with higher ranks like r=256, a smaller alpha ratio (e.g., α = r or even α = 0.5r) might be optimal.
The learning rate is intertwined with these LoRA hyperparameters. Higher ranks (larger r) increase model capacity and might require smaller learning rates to prevent instability. Conversely, lower ranks might tolerate slightly higher learning rates. For Gemma 2, when experimenting with rank and alpha, adjust the learning rate accordingly to find the optimal combination.
8. Efficient Finetuning of Gemma 2 on a Single GPU
LoRA enables finetuning 7B parameter LLMs like Gemma 2 on a single GPU with sufficient RAM (14GB+). Using QLoRA with optimized settings can further reduce memory footprint.
For Gemma 2, efficient finetuning on a single GPU is achievable. Optimizing the learning rate is crucial for both performance and training stability within these memory constraints. A well-tuned learning rate ensures that the model learns effectively without diverging, especially when pushing the limits of GPU memory.
Conclusion: Optimizing Learning Rate for Gemma 2 Finetuning
Finding the Best Learning Rate For Finetuning Gemma 2 with LoRA is an iterative process that depends on various factors, including the dataset, LoRA configuration, optimizer, and training schedule.
Key Takeaways for Learning Rate Optimization with Gemma 2:
- Start with a range: Begin with learning rates between 1e-4 and 1e-5 for AdamW, and slightly lower for SGD (1e-5 to 5e-5).
- Use schedulers: Implement cosine annealing schedulers for smoother convergence.
- Tune with rank and alpha: Optimize learning rate in conjunction with LoRA rank (r) and alpha (α). Higher ranks may require lower learning rates.
- Monitor epochs: Start with fewer epochs to avoid overfitting and adjust learning rate decay accordingly.
- Experiment consistently: Leverage the consistency of LoRA results to reliably compare different learning rates.
By carefully tuning the learning rate and considering the interplay with other LoRA hyperparameters, you can effectively finetune Gemma 2 to achieve optimal performance on your specific tasks while leveraging the efficiency of LoRA.
To deepen your understanding of LLMs and finetuning techniques, consider exploring resources like “Build a Large Language Model (From Scratch)” for a comprehensive insight into the mechanics of LLMs.
