Abstract
Background: The development of robust and generalizable predictive models is essential in healthcare for accurate disease prediction and informed clinical decisions. Achieving this often necessitates leveraging diverse datasets to mitigate biases and ensure algorithmic fairness across various populations. However, a significant hurdle lies in collaboratively training models across multiple institutions without compromising patient privacy or introducing biases from individual sites.
Objective: This study delves into the critical issues of bias and fairness within machine learning applications in predictive healthcare. We introduce a novel software architecture that synergistically combines federated learning and blockchain technologies. This integration aims to enhance fairness in predictive models while upholding acceptable prediction accuracy and minimizing computational overhead.
Methods: We advanced existing federated learning frameworks by incorporating blockchain technology through an iterative design science research methodology. This involved two key design cycles: (1) employing federated learning for bias mitigation and (2) establishing a decentralized architecture using blockchain. Our innovative architecture integrates a bias-mitigation process within a blockchain-empowered federated learning framework. This allows multiple medical institutions to collaboratively train predictive models utilizing their privacy-protected data, thereby fostering fairness in healthcare decision-making.
Results: We successfully designed and implemented our proposed solution utilizing Aplos smart contracts, microservices, the Rahasak blockchain, and Apache Cassandra for distributed storage. Through extensive simulations involving 20,000 local model training iterations and 1,000 federated model training iterations across five simulated medical centers operating as peers on the Rahasak blockchain network, we demonstrated the efficacy of our solution. The enhanced fairness mechanism significantly improved the accuracy of predictive diagnoses.
Conclusions: Our research identifies the inherent technical challenges of prediction biases that plague existing predictive models in the healthcare sector. To address these challenges, we present an innovative design solution leveraging federated learning and blockchain. Coupled with a unique distributed architecture tailored for fairness-aware systems, our design effectively tackles privacy, security, prediction accuracy, and scalability concerns. Ultimately, this approach significantly advances fairness and equity within predictive healthcare applications.
Keywords: fairness, federated learning, bias, health care, blockchain, software, proof of concept, implementation, privacy
Introduction
Precision medicine relies heavily on the ability to accurately identify patients at high risk of life-threatening diseases. The convergence of Artificial Intelligence (AI) and digital health data, particularly Electronic Health Records (EHRs), holds immense potential to revolutionize precision medicine, enabling more precise diagnoses and predictions [1]. Prior research has convincingly demonstrated the power of machine learning (ML) applied to EHR data in improving the prediction accuracy of adverse health outcomes, such as cardiovascular disease [2], and in facilitating the early detection of COVID-19 symptoms [3]. However, the evolution of precision medicine has seen a proliferation of research projects conducted locally or utilizing localized EHR data. This approach introduces inherent biases stemming from underrepresented population samples and fragmented data silos. While solutions aimed at training global models using data from diverse local institutions have been proposed [4], their widespread adoption is hampered by critical challenges, including substantial costs associated with data transmission and storage, as well as significant security and privacy risks [5]. Furthermore, ambiguities surrounding data ownership and limitations on data sharing further impede progress in this crucial domain [6].
Federated learning (FL) emerges as a promising ML paradigm that addresses these challenges. In FL, multiple collaborating entities share only locally trained ML models, maintaining the privacy of their training data [7]. Studies have shown that FL-trained models can achieve performance levels comparable to those trained using centrally hosted datasets and outperform models trained using data from a single institution [8,9]. Consequently, the development and implementation of health AI technologies based on FL are not only essential but also highly sought after in the medical field [10]. The European Union Innovative Medicines Initiative’s privacy-preserving federated ML (FML) projects exemplify this growing trend. Nevertheless, the majority of existing FL systems rely on centralized coordinators, which introduces vulnerabilities to security attacks and privacy breaches due to the potential for a single point of failure.
Addressing these limitations is the core aim of this study. We seek to identify and mitigate bias in healthcare data, enhance the fairness of predictive models through federated learning, and fortify trust and fairness by integrating blockchain technology into FL. Our proposal is a blockchain-empowered, decentralized FL platform designed to improve the fairness of predictive models in healthcare while rigorously preserving patient privacy. We leverage a blockchain platform to build ML models using existing off-chain data storage. Our design is rooted in a two-cycle research methodology. By embedding fairness metrics within a blockchain consensus-driven federated setting, our design elevates the overall fairness of the global model and provides valuable feedback for updating local training models. We implemented and prototyped this design using Aplos smart contracts, microservices, Rahasak blockchain, and Apache Cassandra-based distributed storage. A pilot study [11] involving five simulated medical centers as peers within the Rahasak blockchain network demonstrated the effectiveness of our design in improving the accuracy of a predictive model through 20,000 local model training iterations and 1,000 federated model training iterations. Our evaluation results conclusively show that the proposed design delivers accurate predictions while ensuring fairness with acceptable overhead. This innovative design significantly contributes to healthcare equity and enhances the quality of care by enabling accurate and fair clinical decisions [12].
Methods
Ethical Considerations
This research did not involve the collection of any human-related information or surveys from individuals. The data utilized in this study was algorithmically generated specifically for system performance testing.
Overview of Algorithmic Fairness and FL
Fairness in machine learning is defined through two primary lenses: statistical notions of fairness and individual notions of fairness [13]. Statistical fairness definitions focus on ensuring parity across protected demographic groups based on statistical measures. Conversely, individual fairness definitions emphasize equal treatment for individuals with similar characteristics [13,14]. Recent literature increasingly views algorithmic fairness as a sociotechnical phenomenon [15], recognizing the reciprocal influence between technical and social structures. AI algorithms are inherently complex, and currently, there are no universal standards or guidelines to guarantee fairness in their design [16] or outcomes. Despite the potential for unfairness in AI algorithms, individuals may still be incentivized to utilize them if they can adjust their predictions accordingly [17]. Human oversight of algorithms and human behavior as algorithm inputs are critical factors in achieving algorithmic fairness. Furthermore, while significant progress has been made in developing methods for measuring and addressing algorithmic fairness [18], such as the IBM AI Fairness 360 toolkit [19], the majority of these efforts are concentrated on centralized ML settings, which are not directly transferable to the FL context. As FL inherently limits direct access to raw training datasets, devising methods to detect and mitigate bias without directly examining sensitive information remains a significant challenge.
Fairness is a paramount concern in healthcare. Equity in access to care and the quality of care received are major determinants of overall healthcare quality [20,21]. ML is increasingly being adopted in healthcare to address these equity concerns. However, research specifically focusing on algorithmic fairness within precision medicine remains limited. Existing work on fairness provides general approaches [22], but these may not fully resolve the unique fairness challenges in precision medicine. Precision medicine involves diverse data types that can introduce varied biases into ML models. Therefore, a critical need exists to measure, audit, and mitigate bias within FL specifically for precision medicine applications, while simultaneously safeguarding privacy throughout data collection, processing, and evaluation. Studies indicate that aggregating statistics can potentially lead to individual identification [23]. In FL, the inherent capabilities of sharing models and data among distributed agents can create data leakage risks through reverse engineering and model aggregation. Growing concerns surround the potential for data re-identification and use without patient consent or knowledge [24]. Prior research suggests a general “debiasing” method involving the removal of redundant encoding related to sensitive human attributes in prediction-focused ML applications [25]. However, this method, primarily tested in credit lending, may not be optimal for healthcare decision-making. Another approach, the human-centric, fairness-aware automated decision-making (ADM) framework [26], advocates for holistic human involvement in each ADM step. This approach, however, may be impractical in healthcare due to the complexity of medical decisions and stringent privacy requirements.
Blockchain and FL Integration in Healthcare
In a healthcare FL system, a central coordinator orchestrates the learning process and aggregates parameters from local ML models trained on participant datasets. This centralized coordinator design is vulnerable to security attacks and privacy breaches, presenting a single point of failure risk. Furthermore, malicious actors in FL can exploit the distributed model training process by injecting fake data, incorrect gradients, or manipulated model parameters. Beyond security, FL does not inherently address biases present in medical data itself. Healthcare data is susceptible to biases, such as over- or under-representation of population groups in training data and significant missing values. The distributed nature of FL complicates the identification of bias sources. Predictive algorithms trained on such biased data can amplify these biases, leading to skewed decisions that disproportionately affect certain patient populations, thus introducing unfairness in decision-making [27]. Such unfairness can exacerbate existing healthcare disparities and undermine health equity [28]. To address these privacy and security challenges, we propose integrating blockchain technology with FL. Blockchain offers transparent operations [29] and robust accountability within a decentralized architecture, while maintaining acceptable overhead and a balanced trade-off between algorithm performance and fairness.
Design Science Research Methodology
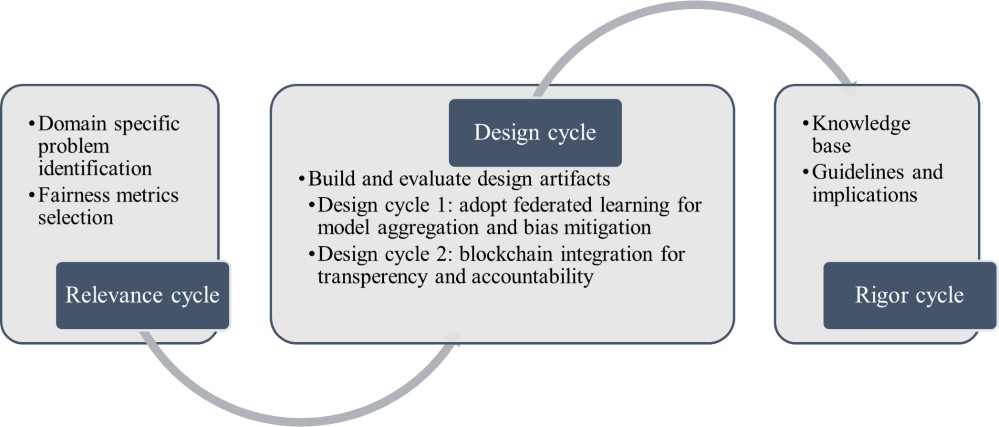
Our research adopts the 3-cycle view of design science research, outlining the tasks for each cycle in Figure 1 [30]. The “Relevance Cycle” section details the objectives of our fairness-aware FL platform and the design science activities bridging blockchain and FL to enhance fairness. The design cycle involves iterative building and evaluating of design artifacts, encompassing two design cycles in this study. The first cycle focused on adopting FL for fairness improvement in disease prediction. The second cycle integrated blockchain to further enhance the fairness of the FL process for disease prediction. The rigor cycle encompasses the resources, technology, and expertise utilized to establish the research project, connecting design activities with the knowledge base of healthcare fairness, FL, and blockchain from scientific foundations and practical implications. We discuss the relevance cycle and artifact building in this section, followed by implementation and evaluation of the two design cycles in subsequent sections.
Figure 1. Design science research methodology (adapted from the study by Hevner [30]).
Relevance Cycle
Problem Identification
This study focuses on understanding bias and fairness issues in ML processes applied to healthcare prediction. Following the design science research framework proposed by Hevner et al [32], our aim is to analyze bias and fairness metrics in healthcare and develop a software architecture integrating FL with blockchain to improve fairness while maintaining acceptable prediction accuracy and manageable overhead. This led to the identification of three primary objectives:
- Objective 1: To understand and detect bias in healthcare data used for building predictive models. We aimed to define objective fairness metrics enabling healthcare organizations to quantitatively assess fairness in algorithm design and identify biases and unfairness.
- Objective 2: To mitigate bias and enhance the fairness of predictive models using FL. We explored the application of various fairness metrics suitable for distributed learning processes and their impact on the overall learning outcomes of predictive models.
- Objective 3: To develop blockchain-assisted FL for enhanced fairness and trustworthiness. We integrated blockchain to bolster the resilience of the FL process by decentralizing data flow during model training. Furthermore, blockchain-based communication architecture ensures accountability and transparency in model aggregation, mitigating biases through smart contract execution and consensus among participating nodes. Blockchain-assisted FL also addresses data sharing concerns for healthcare organizations due to stringent privacy regulations.
Fairness Metrics
Considering the healthcare context and the objectives of predictive models in medical decision-making, we prioritized prediction performance fairness, directly related to biases. Bias, in this context, refers to disparities in both underlying data and prediction model outcomes. We define disparity, aligning with the Institute of Medicine’s definition [33], as “discrepancies in measures of interest unexplained by clinical need.” A model is considered fair if its prediction errors are consistent across privileged and unprivileged groups. Conversely, an algorithm is unfair if its decisions are skewed towards a specific population group without clinical justification [18,33]. Based on established fairness definitions [34], we employed two key metrics for fairness assessment: Equal Opportunity Difference (EOD) and Disparate Impact (DI). Textbox 1 clarifies the terminology used to define these fairness metrics.
Textbox 1. Definition of the terminology [35].
- Protected attribute: A protected attribute categorizes data samples into groups that should exhibit parity in outcomes. In this study, race and gender were investigated as protected attributes.
- Privileged group: A privileged group is defined as a population group whose protected attributes hold privileged values. For instance, White and male groups were considered privileged compared to Black and female groups.
- Label: The outcome label assigned to each individual; 1 indicates a diagnosis (case), and 0 represents a normal control.
- Favorable label: A favorable label corresponds to an outcome beneficial to the recipient. In this context, a positive disease prediction was the favorable label, enabling early identification and treatment of high-risk patients to reduce adverse outcomes.
Prior studies have effectively utilized EOD and DI as fairness metrics [27,36] for both individual and group fairness assessments. We selected EOD and DI as primary fairness metrics due to their prominence in bias assessment research [18,19,27] and their relevance to crucial concerns in clinical prediction models: true positive rates and positive prediction rates. We define EOD and DI as follows:
-
Equal Opportunity Difference (EOD): EOD quantifies the difference in true positive rates between privileged and unprivileged groups. Mathematically, EOD is defined as:
where Ŷ represents the predicted label, A denotes the protected attribute, a is the privileged value (e.g., White or male), a’ is the unprivileged value, and Y is the actual label. An EOD value of 0 signifies fairness, indicating equal true positive rates between groups. This implies that the probability of a specific predictive outcome should be consistent across both Black and White individuals, as well as male and female individuals.
-
Disparate Impact (DI): DI measures the ratio of predicted favorable label percentages between groups, defined as:
where Ŷ, A, a, and a’ retain the same meanings as in equation 1. A DI value of 1 indicates fairness, signifying that the predicted favorable outcome percentage is equal for both privileged and unprivileged groups. The underlying principle of DI is that all individuals should have equal opportunities to receive a favorable prediction, irrespective of race or gender.
In our design cycles, we incorporated both local and global fairness considerations to address algorithmic fairness. Local fairness refers to fairness measures within each local data training process. Each FL node monitors its local state, including fairness measurements, and dynamically adjusts the ratio of each feature based on these measurements. Both EOD and DI are calculated iteratively using feedback from the global training model. Global fairness ensures similar average weights based on proximity to a predefined fairness level [18]. The blockchain node monitors the global state, including fairness measurements, and dynamically adjusts group ratios. Global EOD and DI are shared with all participants, enabling local models to iteratively improve based on global state inputs. Both local and global fairness metrics are meticulously monitored and recorded on the blockchain to ensure accountability and transparency.
Design Cycle: Build and Evaluate
Design Cycle 1: Adopt FL for Bias Mitigation in Disease Prediction
Design cycle 1 focused on adopting FL for bias mitigation in disease prediction. Bias mitigation, or debiasing, aims to enhance fairness metrics by modifying training data distribution, learning algorithms, and predictions. In this cycle, we employed both local and global fairness to address algorithmic fairness. Local fairness measures were applied to each local data training process. Each FL node self-monitored its local state, incorporating fairness measurements, and dynamically adjusted feature ratios accordingly. Both EOD and DI fairness metrics were calculated interactively using feedback from the global training model. Global EOD and DI were shared among all participants, allowing local models to iteratively improve based on global state input. Both local and global fairness metrics were rigorously monitored and recorded. We implemented four modifications (M1 to M4) in the disease prediction algorithm, as depicted in Figure 2, to achieve bias mitigation.
Figure 2. Adopt federated learning for disease prediction.
In M1, we employed decentralized data processing to mitigate bias by retrieving local fairness measurements instead of directly sharing data among institutions. During model training, we adopted two debiasing methods: removing protected attributes from the feature set and resampling to balance group distributions in training data across protected attributes. Protected attributes and data imbalance are primary bias sources. As race and gender are protected attributes, we excluded them from model training comparisons. Prior research has shown that removing race or gender attributes can reduce bias through “fairness through unawareness” [27,37]. We compared models trained with and without protected attributes.
In M2, we aggregated ML model parameters at the global level using calculated training outcomes. ML model bias often arises from two imbalance scenarios: (1) imbalanced sample sizes within training data groups and (2) differing class distributions across groups. Resampling addresses bias from these imbalances. We applied two resampling methods adapted from Afrose et al [38]: (1) resampling by group size (oversampling the minority group to match the majority) and (2) resampling by proportion (resampling only positive samples in groups with lower positive class ratios to balance ratios between groups). Resampling by group size was used by Afrose et al [38] with sample enrichment to generate candidate models for optimization.
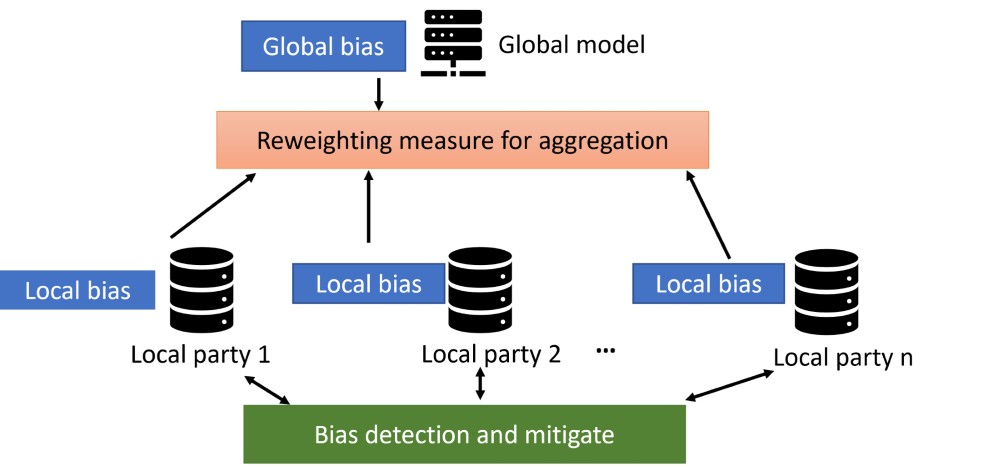
After global model aggregation in M2, M3 involves each participant sharing model outcomes at the global level, and M4 involves receiving feedback from the aggregated global model. Participants in M3 shared model data instead of original datasets, preserving individual privacy. In M4, participants received automated feedback from the global network and adjusted local model parameters. Figure 3 illustrates a hierarchical audit framework for detecting and addressing local and global bias within the FL architecture and the processes of M3 and M4. Local parties share local bias with the global model while reweighting measures for aggregation. The global model calculates global bias and provides feedback to local parties for model improvement and reweighting, iterated until a satisfactory threshold is reached.
Figure 3. A hierarchical framework to detect and address local and global bias under federated learning.
Design Cycle 2: Integrate Blockchain to Enhance Fairness and Trustworthiness
Design cycle 2 integrated blockchain to enhance FL process trustworthiness and fairness. We designed a blockchain-assisted FL platform to improve security and reliability. The challenge was designing the FL network on the blockchain and enhancing bias mitigation for fairness in local and global models. Blockchain tracks data flow and provides feedback to participating institutions for fairness feature parameter fine-tuning and data privacy. Updated modifications (M1 to M4) removed the central server, enabling real-time transparent weight adjustment, model outcome adjustment, and peer-to-peer fairness measurement feedback.
We propose three algorithms to instantiate the blockchain-enabled FL process. In M1, incremental learning continuously trains models by blockchain peers. Each peer uses debiasing in local models. Once a peer generates a model, it’s incrementally aggregated by other peers in M2. Each blockchain node stores shareable information in M3. The ledger provides system auditability. This design enhances feedback transparency in M4. A model card framework [39] is adopted for ML model use and ethics-informed evaluations, crucial for accountability and transparency, providing training model provenance. The model card object contains model information (participants, local model generators, aggregators), serving as a traceable record of model development and protection against adversarial ML attacks.
Results
System Implementation
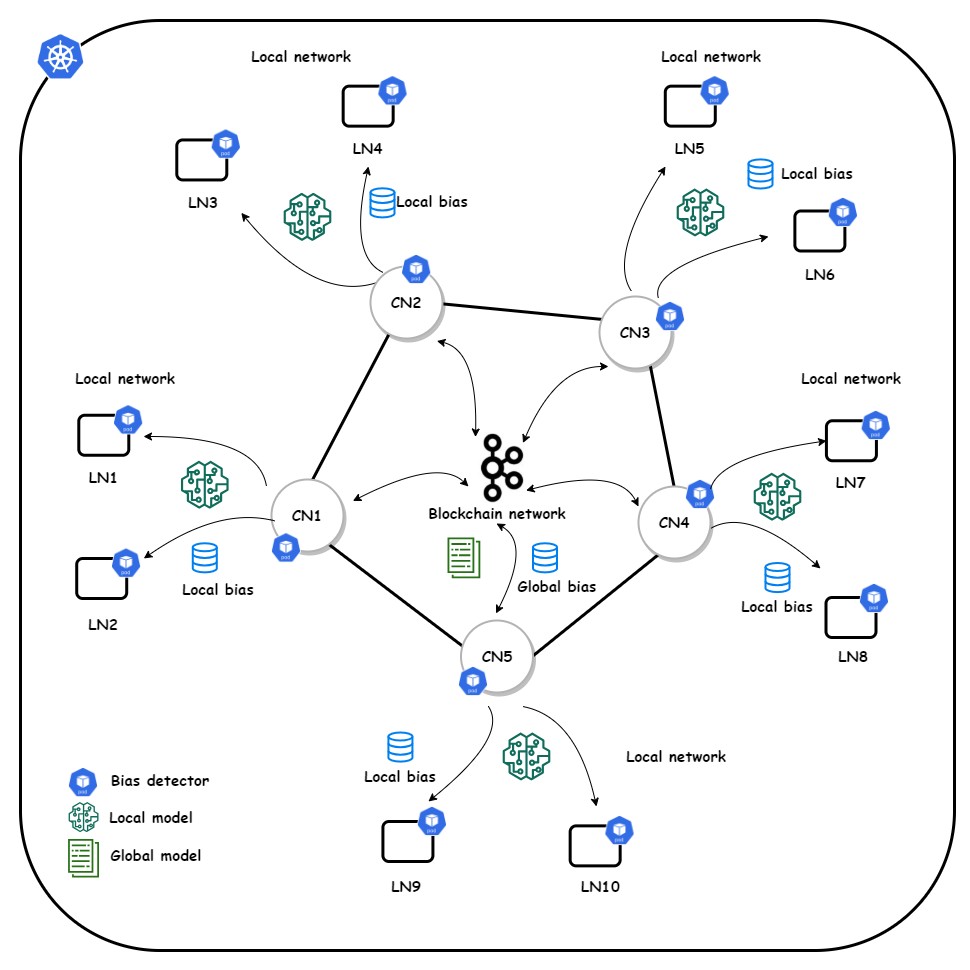
We implemented a blockchain-assisted FL platform incorporating an incremental learning process for continuous model training by blockchain peers (Figure 4). We utilized the Rahasak blockchain [40] with Aplos smart contracts [41] for a customized smart contract interface. Rahasak is a permissioned blockchain where institutions register identities via a membership management service. The platform uses a microservices architecture [42]. We implemented two node types: collaborative nodes (blockchain network nodes) and learning nodes (FL process nodes). Each collaborative node includes FML and storage microservices. The FML service handles FML functions using Pytorch and Pysyft libraries. The storage service manages off-chain data storage with Apache Cassandra [43] distributed storage. Algorithm 1 initializes the training pipeline for three institutions (A, B, C) with blockchain nodes (Textbox 2). Blockchain stores ML model data, while institutions use off-chain storage for local patient data. ML models are published to the blockchain ledger, with consensus via Apache Kafka [44].
Figure 4. System overview of the layered architecture with collaborative node (CN) and learning node (LN) network.
Textbox 2. Algorithm 1: training pipeline initialization.
- Input: Blockchain nodes information, machine learning model training parameters
- Output: Blockchain genesis block, updated training parameters
- Results
- The system initializes with 1 blockchain node chosen by the round robin scheduler with the node information and current training model parameters.
- The chosen blockchain node extracts information attributes from the training model parameters and executes the block creation process.
- The chosen blockchain node broadcasts the genesis block to other peers in the network and the system choose the next available blockchain node to continue the learning process.
- Return
- The results are returned.
We used the Lokka service to generate blocks, including the genesis block for incremental learning [45] and subsequent blocks with model parameters. Federated consensus with three Lokka services was implemented for new block generation. Blocks 1, 2, and 3 were sequentially generated by Lokka A, B, and C through federated consensus via Lokka services. An incremental learning flow defined the training process order (A to B to C). Peer A produces an initial model for incremental training by peers B and C. After Peer A publishes the genesis block with model parameters and incremental flow, other peers retrieve it and start retaining models based on local datasets.
In each incremental learning process, peer A generates a model based on genesis block parameters. Only the hash and URI of the built model are published as a transaction, not the original model. Peer B fetches the model URI and initiates local training with off-chain storage. This trained model is saved on peer B’s off-chain storage, and peer B publishes its hash and URI as a transaction. Peer C repeats the process. After institutions complete training, the Lokka service finalizes the model and generates a new block with finalized model parameters, including multiple transactions from each peer. This new block is broadcast for validation. Peers validate the learning process using block transactions. The finalized model, once fetched, can be shared via smart contracts for prediction.
System Evaluation Outcomes
Overview
As a platform use case, we explored FL and blockchain integration in healthcare. The blockchain network was deployed across five simulated hospitals, each with its own dataset. We used a bladder inflammation dataset to predict acute inflammations [46]. Logistic regression was used to build models for each peer. Platform evaluation focused on model accuracy, blockchain scalability, and model calculation overhead.
Descriptive Assessment of Fairness
We utilized decentralized data processing for bias mitigation by retrieving local fairness measurements instead of sharing data among institutions. During model training, we implemented debiasing by removing protected attributes and resampling to balance group distributions. Protected attributes and data imbalances were primary bias sources.
Training and Validation Loss for Local Model Accuracy
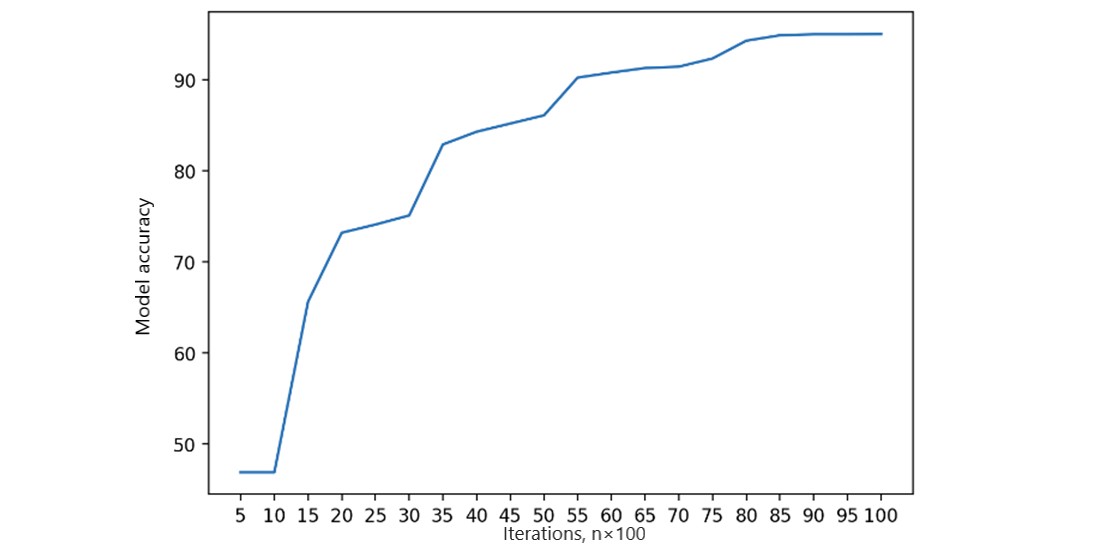
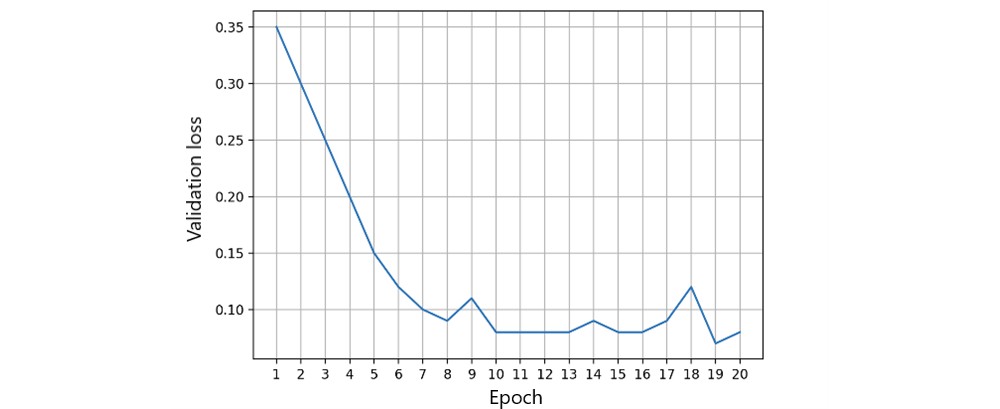
Local fairness metrics are calculated as the initial FL process step. Each FL node monitors its local state and fairness measurements, dynamically adjusting feature ratios. Local training involved 20,000 iterations to assess local model accuracy, training, and validation loss on a single peer [47]. We measured local model accuracy using the area under the receiver operating characteristic curve (Figure 5). Accuracy reached a steady threshold with increasing iterations, indicating model stability. Training and validation loss (Figures 6 and 7) in a single peer reached acceptable levels after 1,000 iterations.
Figure 5. Single peer local model accuracy.
Figure 6. Single peer training loss.
Figure 7. Single peer validation loss.
Federated Model Accuracy
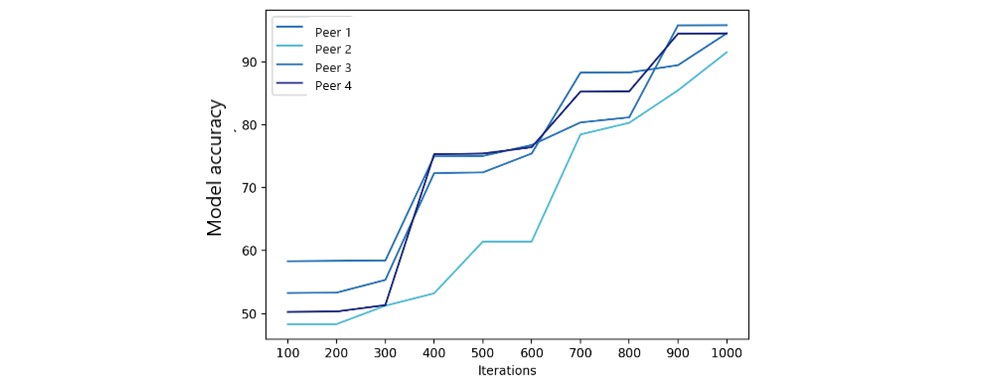
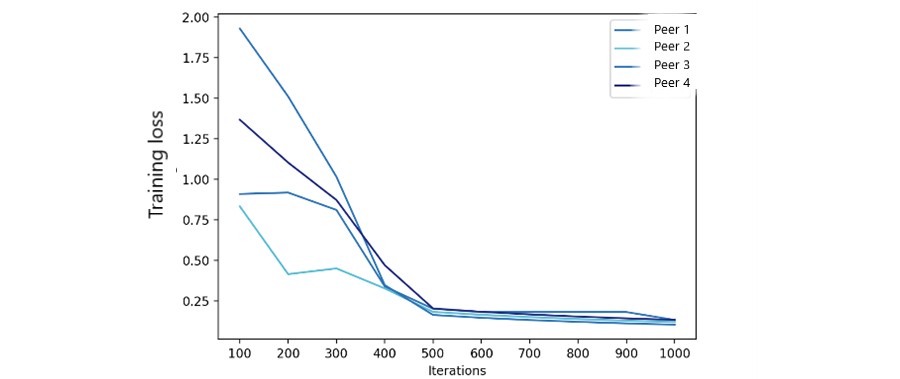
We used 1,000 iterations to measure FML model accuracy and training loss with varying peer numbers. Accuracy results (Figure 8) show federated model accuracy improves with more peers. Federated model training loss (Figure 9) also significantly improved after 500 iterations. The number of peers had a limited impact, as the primary FL modification focused on fairness metrics, not ML parameters.
Figure 8. Federated model accuracy.
Figure 9. Federated model training loss.
Performance of Blockchain Scalability
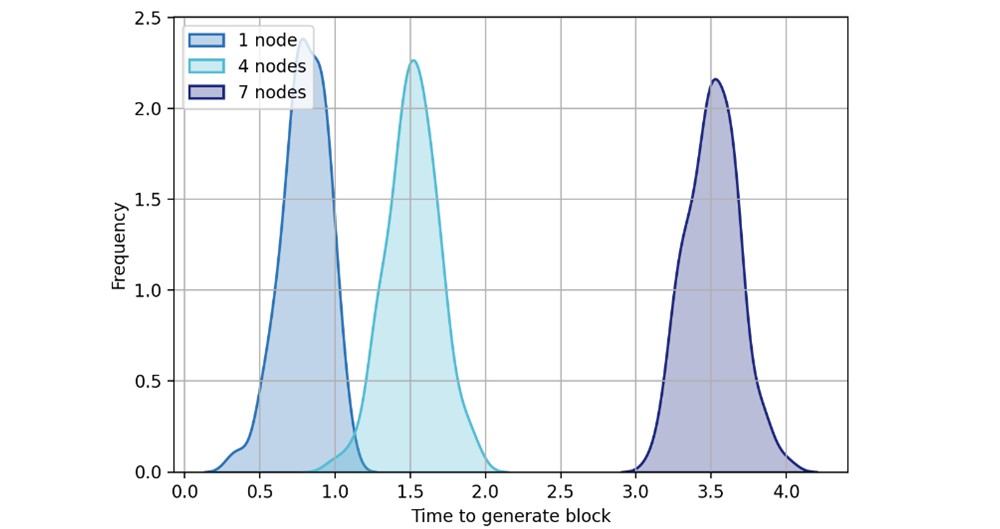
In local block generation and consensus, blocks are generated within a preset threshold. Average block generation time depends on consensus process steps: leader election, peer broadcast, block generation, and transaction validation. Multiple transactions per block enhance scalability. Consensus process simulation with 1, 4, and 7 nodes (Figure 10) showed increased block generation time with more peers due to new block calculation and verification. While more peers increase calculation and verification time, overall network performance improves.
Figure 10. New block generation time.
Local Model–Building Time and Search Time
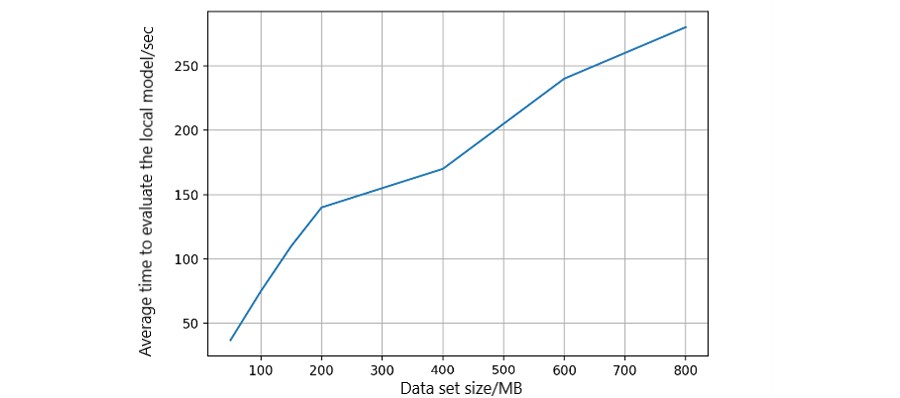
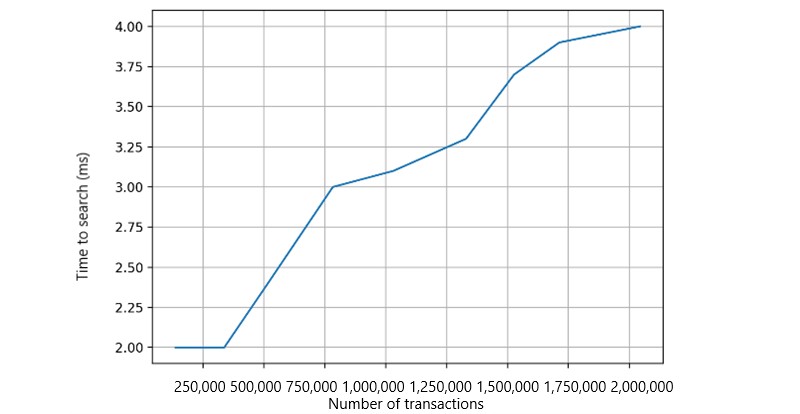
We measured average model-building time relative to dataset size using logistic regression models. Data sizes were adjusted in simulations (Figure 11). Local model-building time increased linearly, demonstrating platform scalability with varying data volumes. Health records are stored off-chain in Cassandra-based Elassandra storage, enabling transaction searches via elastic search-based APIs (Figure 12). Transaction search time increased with the number of records, but overall time cost remained in milliseconds, acceptable for ML models.
Figure 11. Model-building time in each peer.
Figure 12. Transaction search in each peer.
Discussion
Principal Findings
We successfully designed and implemented a bias-mitigation process within a blockchain-empowered FL framework. Our FL platform design effectively mitigates bias, enhancing fairness in distributed medical institutions without raw health data sharing. This incentivizes healthcare institution collaboration and alleviates data leakage and privacy concerns associated with centralized systems. Furthermore, blockchain integration into the FL framework provides an accountable and transparent bias mitigation process. The blockchain and FL synergy enables institutions to share FL models without a central coordinator, eliminating single points of failure. System implementation demonstrated the feasibility of our design for addressing fairness in decentralized environments. Performance evaluations indicate that blockchain integration overhead is acceptable, given the enhanced capabilities achieved.
Our work contributes significantly to research and practice in FL for disease prediction and clinical decision-making. In research, our study contributes by: (1) designing and implementing a blockchain-empowered FL framework to improve decision-making fairness in healthcare, combining FL’s distributed learning advantages with blockchain’s privacy and trustworthiness; (2) advancing algorithmic fairness research by implementing a bias-mitigation process for incremental fairness improvement in both global and local FL models using fairness metric feedback; and (3) showcasing design science research’s guidance in analytic research, particularly healthcare analytics, demonstrating design rigor for analytic artifacts in specific domains with user-centric system requirements.
Our work has practical implications for patients and providers concerned about healthcare fairness and disparity. For patients, our design addresses training data biases to prevent over- or under-representation of populations, easing fairness concerns in ML-aided clinical decisions. For providers, data privacy is protected for institutions with data-sharing restrictions, fostering collaboration to build accurate global models for improved fairness, precision, and quality in clinical decision-making.
For developers, our work provides the blockchain-empowered FL framework, prototype, and evaluation. Developers can build upon this foundation for full framework implementation, generating fair learning models for specific diagnoses and clinical decisions. They can also explore design extensions combining FL and blockchain advantages, considering trade-offs identified in our design. These trade-offs include: (1) prediction accuracy vs. fairness – fairness metrics and parameter adjustments inherently impact prediction accuracy; (2) prediction accuracy vs. computational cost – prediction performance depends on architecture design and blockchain node count; and (3) fairness and transparency vs. model trust and market adoption – enhancing model trust through fairness and transparency promotes innovative design adoption. Human trust should be central to algorithm development to foster understanding and promote ML model trust.
For physicians, the platform offers incentive design opportunities and can help mitigate human bias and structural inequalities affecting diagnosis and treatment [48]. Our blockchain-empowered FL platform promotes data sharing and collaboration fairness. Incentive models can be built based on participant contributions and topological relationships for reward distribution and value model development in revenue distribution [49]. This platform can integrate signature techniques like Boneh-Goh-Nissim cryptosystem and Shamir’s secret sharing [50] for fair incentives, data obliviousness security, and fault tolerance. IT components should have independent fiduciary responsibility to each hospital for data standardization, organization, and maintenance, while also enabling physician collaboration [51]. Incorporating a better understanding of the cultural and political significance of IT implementation, particularly algorithm design and new technology adoption, can improve care delivery quality and effectiveness [52].
Limitations
Blockchain and FL are emerging technologies in healthcare [53], lacking full development and regulatory frameworks [54]. Our prototype has technical limitations in healthcare: ML models may vary in formats and parameters across datasets, requiring standardized institutional collaboration mechanisms. Sharing ML models could lead to unintended intellectual information disclosure if system deployment is not carefully planned and negotiated between institutions [55]. Incentive mechanisms for institutional collaboration could be explored to address this. Full stakeholder participation [56] is crucial for promoting innovative architectural design adoption for algorithmic fairness. FL’s sequential nature may limit learning process efficiency, but disease prediction in hospitals doesn’t require real-time performance, and node counts are manageable, making learning process delays acceptable.
Comparison With Prior Work
FL is an innovative ML technology addressing healthcare challenges. Prior research provided benchmark data [57] for performance assessment and privacy-preserving guidance [58] for FML in medical research, including mobile health [59]. Prior work combined FL and blockchain to address unfairness, such as a weighted data sampler algorithm for fairness in COVID-19 X-ray detection [60], providing accountability but not privacy. Privacy challenges in FL are addressed by statistical inference combining datasets, using methods like statistical estimators, risk utility [61], and binary hypothesis testing [62], successful in radiation and partitioned datasets [63]. Models need to configure attributes for individual identification (name, address, phone number). Existing privacy-preserving applications use decentralized learning [64] but face identity leakage issues from data and model sharing. Data re-identification and unauthorized use are growing concerns [24]. “Debiasing” by removing sensitive attribute encoding [25] was tested in credit-lending and may not be ideal for healthcare decisions. Human-centric fairness-aware ADM [26] emphasizing human involvement is unrealistic in complex healthcare and privacy scenarios.
Our model enables configuration of attributes for individual identification. Our blockchain-enabled FL platform offers transparent operations and accountability in a decentralized architecture, balancing algorithmic fairness and performance with acceptable overhead.
Conclusions and Future Directions
Precision medicine aims for fast, reliable detection of severe, heterogeneous illnesses. However, heterogeneous data from healthcare providers can lead to unfair and inaccurate predictions. Bias needs mitigation throughout data cycles. Our blockchain-empowered FL framework with a novel architecture enables medical institutions to jointly train predictive models using privacy-protected data, achieving fairness in healthcare decisions. The framework operates in two stages: learning and sharing/coordination. Learning occurs locally at each institution. Sharing/coordination, initiated upon joining the collaborative network, focuses on bias reduction using fairness metrics.
This novel design helps understand and detect bias in healthcare data, mitigates bias, and improves fairness using FL. Blockchain-assisted FL enhances fairness and trustworthiness, improving architecture resilience through decentralized data flow. System evaluation shows accurate prediction and fairness with acceptable overhead, improving healthcare equity and clinical decision quality. Local hospitals benefit from peer learning without data sharing.
Future work can extend this framework with incentive mechanisms to promote healthcare institution participation and collaboration, evaluating contributions and distributing rewards. Embedding and evaluating different fairness metrics can further improve the framework. Testing with diverse medical datasets and integrating new learning methods like swarm learning with edge and fog computing for confidential ML without central coordinators are future directions.
Acknowledgments
The authors thank all reviewers and editors for their helpful suggestions. The authors also thank colleagues for valuable feedback during manuscript preparation. This work was supported by the Department of Defense Center of Excellence in AI and Machine Learning under contract number W911NF-20-2-0277 with the US Army Research Laboratory.
Data Availability
Data sets are available from the corresponding author upon reasonable request.
Authors’ Contributions
XL, JZ, YC, EB, and SS designed the study architecture. XL, YC, and EB drafted the manuscript. XL and EB implemented the architecture. JZ and SS reviewed the manuscript. All authors approved the final manuscript.
Conflicts of Interest
None declared.
References
[1] Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med 2019 Jan;25(1):44-56. [doi: 10.1038/s41591-018-0300-7] [PMID: 30617337]
[2] Weng SF, Reps J, Kai J, Garmo H, Narayanan V, Davies G, et al. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS One 2017;12(12):e0189790 [FREE Full text] [doi: 10.1371/journal.pone.0189790] [PMID: 29261882]
[3] Pourhomayoun M, Shakikhanian P, Varshney P, Bookbinder M, Jahani N, Ghassemi MM, et al. Early detection of COVID-19 symptoms from smart wearable devices data using machine learning algorithms. PLoS One 2022;17(1):e0260639 [FREE Full text] [doi: 10.1371/journal.pone.0260639] [PMID: 35021095]
[4] Xu Z, Tang Y, Zhang Y, Xue H, Fu B, Liu F, et al. Federated learning with differential privacy for healthcare. AMIA Jt Summits Transl Sci Proc 2021;2021:605-614 [FREE Full text] [PMID: 34258277]
[5] Rieke N, Hancox J, Li W, Milletari F, Roth HR, Glocker B, et al. Federated learning in medicine. Patterns (N Y) 2020 Dec 11;1(12):100119 [FREE Full text] [doi: 10.1016/j.patter.2020.100119] [PMID: 34471731]
[6] Vayena E, Blasimme A, Cohen IG. Machine learning in medicine: addressing ethical challenges. PLoS Med 2018 Oct;15(10):e1002689 [FREE Full text] [doi: 10.1371/journal.pmed.1002689] [PMID: 30304098]
[7] McMahan B, Moore E, Ramage D, Hampson S, Arcas BAY. Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. 2017 Presented at: 20th International Conference on Artificial Intelligence and Statistics; April 20-22, 2017; Fort Lauderdale, FL USA. [CrossRef]
[8] Brisimi TS, Chen R, Cha KH, Matuszewski BJ, Li W, Xiao C, et al. Federated learning of predictive models from electronic health records. Int J Med Inform 2018 Dec;112:59-67 [FREE Full text] [doi: 10.1016/j.ijmedinf.2018.01.007] [PMID: 29426561]
[9] Yang Q, Liu Y, Chen T, Tong Y. Federated machine learning: concept and applications. ACM Trans Intell Syst Technol 2019 Feb 28;10(2):1-19. [doi: 10.1145/3298981]
[10] Kaissis GA, Makowski MR, Rückert D, Braren R, Holzinger A, Mayer MA, et al. Secure, privacy-preserving and federated machine learning in medical imaging. Nat Mach Intell 2020 Jun;2(6):305-311 [FREE Full text] [doi: 10.1038/s42256-020-0189-1] [PMID: 32626989]
[11] Liang X, Zhao J, Shetty S. Blockchained federated learning for bias mitigation and privacy preservation in healthcare. In: Proceedings of the 2022 IEEE International Conference on Blockchain and Cryptocurrency (ICBC). 2022 May Presented at: 2022 IEEE International Conference on Blockchain and Cryptocurrency (ICBC); May 2-5, 2022; Rome, Italy. [CrossRef]
[12] Chen IY, Szolovits P, Ghassemi M. Can AI help reduce disparities in health care? AMA J Ethics 2019 Feb 01;21(2):E167-E179 [FREE Full text] [doi: 10.1001/amajethics.2019.167] [PMID: 30785488]
[13] Mehrabi N, Morstatter F, Saxena N, Lerman K, Galstyan A. A survey on fairness in machine learning. ACM Comput Surv 2021 Mar 29;54(6):1-35. [doi: 10.1145/3457607]
[14] Dwork C, Hardt M, Pitassi T, Reingold O, Zemel R. Fairness through awareness. In: Proceedings of the 3rd Innovations in Theoretical Computer Science Conference. 2012 Presented at: 3rd Innovations in Theoretical Computer Science Conference; January 8-10, 2012; Cambridge, MA USA. [CrossRef]
[15] Selbst EA, Powles J, Ali K, Binns R, Valera I, Redmiles EM. Fairness and abstraction in sociotechnical systems. In: Proceedings of the Conference on Fairness, Accountability, and Transparency. 2019 Presented at: Conference on Fairness, Accountability, and Transparency; January 29-31, 2019; Atlanta, GA USA. [CrossRef]
[16] Holstein K, Wortman Vaughan J, Daumé H, Dudík M, Wallach H. Improving fairness in machine learning systems: What do industry practitioners need? In: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems. 2019 Presented at: 2019 CHI Conference on Human Factors in Computing Systems; May 4-9, 2019; Glasgow, Scotland UK. [CrossRef]
[17] Kleinberg J, Ludwig J, Mullainathan S, Obermeyer Z. Prediction policy problems. Am Econ Rev 2015 May 01;105(5):491-495. [doi: 10.1257/aer.p20151023] [PMID: 27294048]
[18] Barocas S, Hardt M, Narayanan A. Fairness and machine learning: limitations and opportunities. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. 2016 Presented at: 30th International Conference on Neural Information Processing Systems; December 5-10, 2016; Barcelona, Spain.
[19] Bellamy RKE, Dey K, Hind M, Hoffman SC, Houde S, Jenna R, et al. AI fairness 360: an extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias. arXiv 2018 Presented at: 1st Workshop on AI Fairness; January 31, 2019; Atlanta, GA. [CrossRef]
[20] Braveman PA, Gottlieb LM. The social determinants of health: it’s time to consider the causes of the causes. Public Health Rep 2014 Jan;129 Suppl 2:19-31 [FREE Full text] [doi: 10.1177/0033354914129S206] [PMID: 24489278]
[21] Shi L, Starfield B. Primary care, income inequality, and self-rated health in the United States: a multilevel analysis. Int J Health Serv 2005;35(2):287-300. [doi: 10.2190/HS.35.2.c] [PMID: 15932149]
[22] Gianfrancesco MA, Tamang S, Yazdany J, Schmajuk G. Potential biases in machine learning algorithms using electronic health record data. JAMA Intern Med 2018 Dec 01;178(11):1543-1547 [FREE Full text] [doi: 10.1001/jamainternmed.2018.3776] [PMID: 30279883]
[23] Dankar FK, El Emam K, Carriere J, Neisa A. Evaluating the re-identification risk of real-world clinical data de-identification. BMC Med Inform Decis Mak 2018 Feb 21;18(1):18 [FREE Full text] [doi: 10.1186/s12911-018-0592-1] [PMID: 29463177]
[24] Tene O, Polonetsky JP. A theory of creepy: technology, privacy and shifting social norms. Yale J Law Technol 2013;16(1):59-123 [FREE Full text]
[25] Zemel RS, Wu Y, Swersky K, Pitassi T, Dwork C. Learning fair representations. In: Proceedings of the 30th International Conference on Machine Learning. 2013 Presented at: 30th International Conference on Machine Learning; June 16-21, 2013; Atlanta, Georgia, USA.
[26] Binns R, Veale M, Van Kleek M, Schraefel MC, Shadbolt N. It’s reducing a human being to a percentage’: perceptions of justice in algorithmic decision-making. In: Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. 2018 Presented at: 2018 CHI Conference on Human Factors in Computing Systems; April 21-26, 2018; Montreal, QC, Canada. [CrossRef]
[27] Mehrabi N, Morstatter F, Saxena N, Lerman K, Galstyan A. A survey on fairness in machine learning. ACM Comput Surv 2022 Feb 14;55(1):1-35. [doi: 10.1145/3489032]
[28] Hardt M, Price E, Srebro N. Equality of opportunity in supervised learning. In: Proceedings of the 29th Annual Conference on Neural Information Processing Systems. 2016 Presented at: 29th Annual Conference on Neural Information Processing Systems; December 5-10, 2016; Barcelona, Spain.
[29] Swan M. Blockchain thinking: the power of crypto-economics and decentralized technologies. IEEE Access 2015;3:2814-2825. [doi: 10.1109/ACCESS.2015.2505656]
[30] Hevner AR. A three cycle view of design science research. Inf Syst Manag 2007 Oct;24(4):22-42. [doi: 10.1080/10580530701503143]
[31] March ST, Smith GF. Design and natural science research on decision support systems. Decis Support Syst 1995 Dec;15(4):251-266. [doi: 10.1016/0167-9236(94)00041-2]
[32] Hevner AR, March ST, Park J, Ram S. Design science in information systems research. MIS Q 2004 Mar;28(1):75-105. [doi: 10.2307/25148625]
[33] Smedley BD, Butler AS, Bristow LR. Unequal treatment: confronting racial and ethnic disparities in health care. Washington, DC: National Academies Press; 2003.
[34] Chouldechova A, Roth A. The frontiers of fairness in machine learning. ACM SIGACT News 2020 Mar 23;51(1):4-35. [doi: 10.1145/3375651.3375653]
[35] IBM Cloud Education. Fairness metrics. URL: https://www.ibm.com/cloud/learn/fairness-metrics [Accessed 2023-10-26]
[36] Holstein K, Adebayo J, Hullman J, Wortman Vaughan J, Weber G, Kıcıman E, et al. Improving fairness with causal embeddings. In: Proceedings of the Conference on Fairness, Accountability, and Transparency. 2019 Presented at: Conference on Fairness, Accountability, and Transparency; January 29-31, 2019; Atlanta, GA USA. [CrossRef]
[37] Pedreshi D, Ruggieri S, Turini F. Discrimination-aware data mining. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2008 Presented at: 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; August 24-27, 2008; Las Vegas Nevada USA. [CrossRef]
[38] Afrose S, Guha T, Gomes CP, Seltzer M. Fairness-aware model ensembling in a federated setting. arXiv 2019 Presented at: AAAI/ACM Conference on AI, Ethics, and Society; February 7-8, 2020; New York, NY. [CrossRef]
[39] Mitchell M, Wu S, Zaldivar-Kleiman L, Barnes P, Vasserman L, Hutchinson B, et al. Model cards for model reporting. In: Proceedings of the Conference on Fairness, Accountability, and Transparency. 2019 Presented at: Conference on Fairness, Accountability, and Transparency; January 29-31, 2019; Atlanta, GA USA. [CrossRef]
[40] Rahasak. URL: https://github.com/rahasak [Accessed 2023-10-26]
[41] Aplos. URL: https://github.com/rahasak/aplos [Accessed 2023-10-26]
[42] Newman M. Building microservices. Sebastopol, CA: O’Reilly Media; 2015.
[43] Lakshman A, Malik P. Cassandra: a decentralized structured storage system. ACM SIGOPS Oper Syst Rev 2009 Apr;43(2):35-40. [doi: 10.1145/1531793.1531805]
[44] Kreps J, Narkhede N, Rao J. Kafka: a distributed messaging system for log processing. In: Proceedings of the 6th International Workshop on Data Engineering on Cloud. 2011 Presented at: 6th International Workshop on Data Engineering on Cloud; March 8-9, 2011; Hong Kong, China. [CrossRef]
[45] Lokka. URL: https://github.com/rahasak/lokka [Accessed 2023-10-26]
[46] UCI Machine Learning Repository. Bladder inflammation data set. URL: https://archive.ics.uci.edu/ml/datasets/bladder+inflammation [Accessed 2023-10-26]
[47] Goodfellow I, Bengio Y, Courville A. Deep learning. Cambridge, MA: MIT Press; 2016.
[48] Obermeyer Z, Powers B, Vogeli C, Mullainathan S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 2019 Oct 25;366(6464):447-453 [FREE Full text] [doi: 10.1126/science.aax2342] [PMID: 31649192]
[49] Hawlitschek A, Notheisen B, Teubner T. Understanding the determinants of users’ continuance intention in blockchain-based systems: evidence from cryptocurrency wallets. Electron Mark 2021 Mar 18;31(1):111-133. [doi: 10.1007/s12525-020-00237-x]
[50] Kshetri N, Voas J. Blockchain-enabled e-governance. Computer 2018 Sep;51(9):87-91. [doi: 10.1109/MC.2018.2640190]
[51] Dixon BE, Stahl JE, Chiang MF. Trust and governance for clinical data sharing: lessons from a pilot project. J Am Med Inform Assoc 2015 Mar;22(2):280-286 [FREE Full text] [doi: 10.1136/amiajnl-2014-002913] [PMID: 25359773]
[52] Yaghobian S, Mazandarani F, Wrightson P, Seddon J. The politics of implementation: an interpretive case study of electronic health records in two NHS hospitals. BMC Health Serv Res 2017 Dec 21;17(1):842 [FREE Full text] [doi: 10.1186/s12913-017-2787-6] [PMID: 29262913]
[53] Benchoufi M, Ravaud P. Blockchain technology for improving clinical research quality. Trials 2017 Jul 06;18(1):243 [FREE Full text] [doi: 10.1186/s13063-017-2035-z] [PMID: 28683849]
[54] Meskó B, Drobni Z, Bényei E, Gábor P, Marsche B. Digital health is a cultural transformation of traditional healthcare. mHealth 2017 Sep;3:38 [FREE Full text] [doi: 10.21037/mhealth.2017.08.07] [PMID: 29354615]
[55] Jansen P, Prgomet M, van Lieshout J, Rosemann M, Bail P, Hujala A, et al. Towards a collaborative governance approach for cross-organizational integrated care enabled by information and communication technology. Health Policy 2017 Sep;121(9):953-962. [doi: 10.1016/j.healthpol.2017.06.011] [PMID: 28754229]
[56] Ohannessian R, Duong TA, Odone A, Ben Hamadi L, Nguyen CT, Jehan F. Stakeholders’ perceptions of blockchain technology for health data sharing: qualitative study. J Med Internet Res 2021 Jan 29;23(1):e25748 [FREE Full text] [doi: 10.2196/25748] [PMID: 33459693]
[57] Lee J, Kim J, Kim T, Lee S, Shin SY. McFL: Towards medical data confederation via federated learning. arXiv 2020 Presented at: 33rd Conference on Neural Information Processing Systems; December 6-12, 2019; Vancouver, BC Canada.
[58] Geyer RC, Klein T, Nabi M, Rey HG. On the convergence of federated averaging on non-iid data. In: Proceedings of the 32nd Annual Conference on Neural Information Processing Systems. 2017 Presented at: 32nd Annual Conference on Neural Information Processing Systems; December 4-9, 2017; Long Beach, CA USA.
[59] Khan R, Bhat S, Tran N, Nguyen Q, Nepal S, Rana R, et al. Federated learning for mobile health. ACM Trans Intell Syst Technol 2021 Jul 29;12(4):1-20. [doi: 10.1145/3464370]
[60] Shahin M, Ding M, Leckie C, Karunasekera S. Blockchain based fair federated learning for COVID-19 X-ray detection. In: Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN). 2021 Jul Presented at: 2021 International Joint Conference on Neural Networks (IJCNN); July 18-22, 2021; Shenzhen, China. [CrossRef]
[61] Ullman J. Privacy via calibrated noise addition. J Privacy Confidentiality 2017;7(3):1-33 [FREE Full text] [doi: 10.29012/jpc.v7i3.405]
[62] Dwork C, Lei J, Pitassi T, Reingold O. Generalization in adaptive data analysis and holdout reuse. In: Proceedings of the 47th Annual ACM Symposium on Theory of Computing. 2015 Presented at: 47th Annual ACM Symposium on Theory of Computing; June 14-17, 2015; Portland, OR USA. [CrossRef]
[63] Abayomi A, Gel YR, Knox JE, Kowalczyk A, Ross G, Wang PW. Fast, reliable and privacy-preserving statistical inference for radiation surveillance networks. Stat Med 2017 Jul 30;36(17):2628-2647. [doi: 10.1002/sim.7302] [PMID: 28485757]
[64] Gori P, Muscariello M, Bertini M, Catarci T, Najjar A, Pournajaf S, et al. Decentralized learning for healthcare informatics. IEEE Access 2020;8:132975-132992. [doi: 10.1109/ACCESS.2020.3010291]
Abbreviations
| ADM: automated decision-making |
|---|
| AI: artificial intelligence |
| DI: disparate impact |
| EHR: electronic health record |
| EOD: equal opportunity difference |
| FL: federated learning |
| FML: federated machine learning |
| ML: machine learning |


Edited by T Leung, G Eysenbach; submitted 15.02.23; peer-reviewed by D Chrimes, N Mungoli, C Zhu; comments to author 16.06.23; revised version received 06.07.23; accepted 21.08.23; published 30.10.23.
[Copyright ©Xueping Liang, Juan Zhao, Yan Chen, Eranga Bandara, Sachin Shetty. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 30.10.2023.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research, is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.
