Classification In Machine Learning is a fundamental concept that teaches computers to categorize data into distinct groups. Imagine teaching a machine to sort fruits: apples go in one basket, bananas in another, and oranges in a third. This is essentially what classification does, but with data instead of fruit. It’s a type of supervised learning where the algorithm learns from labeled examples to predict the category of new, unseen data.
For instance, a classification model could be trained on a dataset of emails, each labeled as either “spam” or “not spam.” By analyzing features like email content, sender information, and subject lines, the model learns to distinguish between spam and legitimate emails. Once trained, it can automatically classify new incoming emails as spam or not spam, helping to keep your inbox clean and secure.
In the context of machine learning, classification is visualized as drawing boundaries in a feature space. Consider the image above, which illustrates a simplified example of classifying images as either dogs or cats based on features like color, texture, shape, and size.
- Each colored dot represents an image, with the color indicating the model’s prediction (e.g., blue for cat, red for dog).
- The shaded areas depict the decision boundary. This boundary is what the classification model uses to decide whether a new image, based on its features, belongs to the “dog” or “cat” category. Images falling on one side of the boundary are classified as dogs, and those on the other side as cats.
Types of Classification in Machine Learning
Classification problems in machine learning are diverse and can be categorized based on the number of classes and how data points are assigned to these classes. Understanding these types is crucial for selecting the right approach for your specific problem. The primary types of classification are:
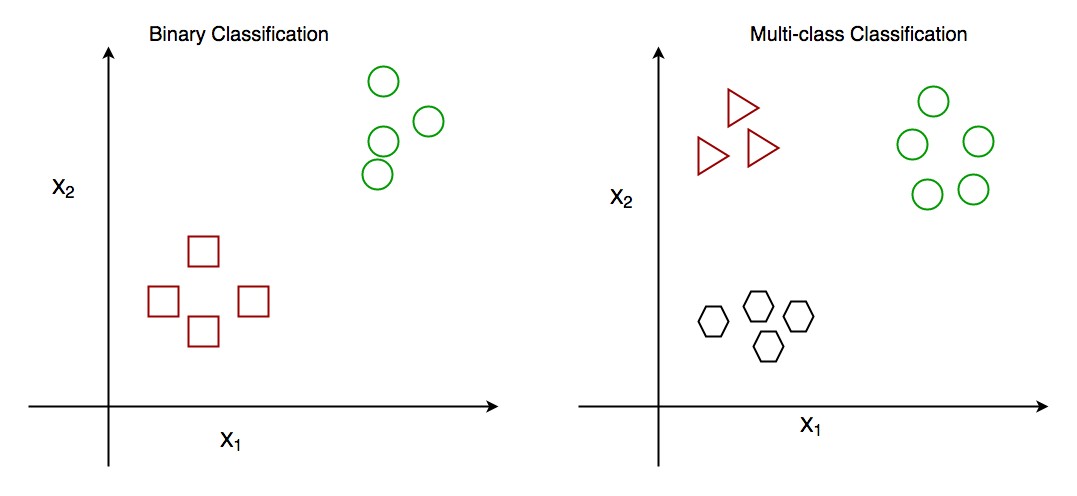
1. Binary Classification
Binary classification is the most straightforward form of classification, dealing with problems that have only two possible classes. It’s a yes-or-no, true-or-false scenario. Think of it as deciding between two exclusive options.
A classic example is spam email detection. Every incoming email is classified into one of two categories: “spam” or “not spam” (often called “ham”). The model analyzes various features of the email—such as keywords, sender reputation, and email structure—to make this binary decision. Other examples include:
- Medical diagnosis (disease detection): Determining if a patient has a specific disease (positive) or not (negative) based on medical tests.
- Credit risk assessment: Predicting whether a loan applicant will default (high risk) or not (low risk).
- Sentiment analysis (positive/negative): Classifying customer reviews as either positive or negative.
2. Multiclass Classification
Multiclass classification steps beyond binary choices and involves categorizing data into more than two classes. In this type of classification, each data point is assigned to one and only one category from a set of multiple possibilities.
Imagine an image recognition system designed to classify images of animals. Instead of just “cat” or “dog,” the system might need to distinguish between “cat,” “dog,” “bird,” and “fish.” The model examines features within the image—like shape, color patterns, and textures—and selects the most probable animal category from the predefined list.
Other real-world examples include:
- Handwritten digit recognition: Classifying handwritten digits (0-9) into ten distinct classes.
- Object recognition in images: Identifying various objects in a scene, such as “car,” “pedestrian,” “bicycle,” “truck,” etc.
- News article categorization: Sorting news articles into topics like “sports,” “politics,” “technology,” “entertainment,” etc.
3. Multi-Label Classification
Multi-label classification is a more complex scenario where each data point can belong to multiple classes simultaneously. This differs significantly from multiclass classification, where each item is assigned to only one category.
Consider a movie genre classification system. A single movie can be labeled with multiple genres, such as “action,” “comedy,” and “romance.” The system analyzes movie features—plot, actors, keywords, themes—and assigns all relevant genre labels to that movie.
Examples of multi-label classification applications include:
- Document tagging: Assigning multiple topics or keywords to a document.
- Music genre classification: Labeling songs with genres like “rock,” “pop,” “electronic,” and “alternative.”
- Image annotation: Identifying multiple objects or elements present in an image (e.g., “sky,” “tree,” “person,” “car”).
While multi-label classification is important in specific applications, for those new to classification, focusing on binary and multiclass classification provides a strong foundational understanding.
How Classification Works in Machine Learning: A Step-by-Step Guide
The process of classification in machine learning revolves around training a model to learn from labeled data and then using that learned knowledge to predict the categories of new, unlabeled data. Here’s a breakdown of the key steps involved:
-
Data Collection: The first step is gathering a labeled dataset. This dataset consists of examples where each data point is already assigned to its correct class. For example, in spam detection, you would collect a set of emails and manually label each one as “spam” or “not spam.”
-
Feature Extraction: Next, you need to identify and extract relevant features from the data that can help distinguish between different classes. Features are measurable characteristics of the data. For emails, features could include the frequency of certain words, the sender’s domain, the presence of links, etc. For images, features might be color histograms, texture patterns, or shapes.
-
Model Training: This is where the machine learning algorithm comes into play. You feed the labeled dataset and the extracted features to a classification algorithm. The algorithm learns the relationship between the features and the labels. It essentially tries to find patterns and rules that can accurately map features to their corresponding classes. Various algorithms can be used for classification, such as Logistic Regression, Support Vector Machines (SVM), Decision Trees, and Neural Networks.
-
Model Evaluation: After training, it’s crucial to evaluate the model’s performance. This involves testing the model on a separate dataset that it hasn’t seen during training, known as a test set. Evaluation metrics, such as accuracy, precision, recall, and F1-score, are used to measure how well the model generalizes to new, unseen data.
-
Prediction: Once you are satisfied with the model’s performance after evaluation, it can be deployed to predict the class labels for new, unlabeled data. You input the features of the new data into the trained model, and it outputs its predicted class. For example, with a trained spam detection model, you can feed in a new email, and the model will predict whether it’s spam or not.
-
Iterative Refinement: Machine learning model development is often an iterative process. If the initial evaluation results are not satisfactory, you may need to go back and adjust various aspects, such as:
- Feature Engineering: Refining or adding new features.
- Algorithm Selection: Trying a different classification algorithm.
- Hyperparameter Tuning: Adjusting the settings of the chosen algorithm.
- Data Augmentation: Increasing the size or diversity of the training data.
This iterative process of training, evaluating, and refining continues until you achieve a model that meets your desired performance criteria. In essence, machine learning classification is about using existing labeled data to teach a model how to accurately categorize new, unlabeled data based on learned patterns.
Real-World Examples of Machine Learning Classification
Classification algorithms are not just theoretical concepts; they are the workhorses behind many applications we use daily. Here are some prominent real-world examples:
-
Email Spam Filtering: As discussed earlier, classification is the backbone of spam filters, protecting users from unwanted and potentially harmful emails.
-
Credit Risk Assessment: Banks and financial institutions use classification models to assess the creditworthiness of loan applicants. By analyzing factors like credit score, income, and past financial behavior, these models predict the likelihood of loan default, enabling informed lending decisions and risk management.
-
Medical Diagnosis: Classification plays a vital role in healthcare, assisting in the diagnosis of diseases. Models can analyze medical data—such as symptoms, test results, and patient history—to classify whether a patient has a specific condition, like cancer or diabetes. This aids doctors in making faster and more accurate diagnoses, leading to improved patient care.
-
Image Classification: From facial recognition on smartphones to autonomous driving systems that identify pedestrians and traffic signs, image classification is ubiquitous. It’s also crucial in medical imaging for detecting anomalies like tumors.
-
Sentiment Analysis: Businesses leverage sentiment analysis to understand customer opinions from text data like reviews and social media posts. Classification models categorize text as positive, negative, or neutral, providing valuable insights for product improvement, marketing strategies, and customer service.
-
Fraud Detection: In the financial and e-commerce sectors, classification algorithms are essential for detecting fraudulent activities. By analyzing transaction patterns and identifying anomalies, these models help prevent credit card fraud, identity theft, and other financial crimes.
-
Recommendation Systems: Platforms like Netflix and Amazon use classification to power their recommendation engines. By analyzing user behavior and preferences, these systems classify items (movies, products) as “relevant” or “not relevant” to a specific user, personalizing user experience and boosting sales.
Classification Modeling in Machine Learning: Key Characteristics
Building effective classification models involves understanding their fundamental characteristics. Classification modeling utilizes machine learning algorithms to categorize data into predefined classes or labels. These models are adaptable to both binary and multiclass classification problems. Key characteristics include:
-
Class Separation: The core principle of classification is to distinguish between distinct classes. The goal is to train a model that can effectively separate data points into their correct predefined classes based on their features.
-
Decision Boundaries: Classification models achieve separation by establishing decision boundaries in the feature space. These boundaries can be linear (straight lines or hyperplanes) or non-linear (curves or complex shapes), depending on the complexity of the data and the chosen algorithm.
-
Sensitivity to Data Quality: Classification models are highly sensitive to the quality and quantity of the training data. High-quality, well-labeled, and representative data leads to better model performance. Conversely, noisy, biased, or insufficient data can result in inaccurate predictions and poor generalization.
-
Handling Imbalanced Data: A common challenge in classification is imbalanced datasets, where one class is significantly underrepresented compared to others. This can bias the model towards the majority class. Special techniques, such as resampling (oversampling minority class, undersampling majority class) or assigning class weights, are used to mitigate the impact of class imbalance.
-
Interpretability: The interpretability of a classification model refers to how easily humans can understand the model’s decision-making process. Some algorithms, like Decision Trees and Logistic Regression, are more interpretable, allowing users to understand why a model made a specific prediction. Others, like complex Neural Networks, are often considered “black boxes” with lower interpretability.
Popular Classification Algorithms
Implementing classification models requires understanding and utilizing various classification algorithms. While Logistic Regression is a foundational algorithm, many other powerful classifiers are available. Classification algorithms can be broadly categorized into:
Linear Classifiers: These algorithms create linear decision boundaries. They are generally simpler, computationally efficient, and work well when classes are linearly separable or approximately so. Examples include:
- Logistic Regression: A fundamental algorithm for binary and multiclass classification, estimating the probability of a data point belonging to a particular class.
- Support Vector Machines (SVM) (Linear Kernel): Effective in high-dimensional spaces, aiming to find the optimal linear hyperplane that maximizes the margin between classes.
- Perceptron: An early algorithm that forms the basis for neural networks, learning a linear decision boundary.
Non-linear Classifiers: These algorithms create non-linear decision boundaries, enabling them to model more complex relationships between features and classes. They are essential when data is not linearly separable. Examples include:
- Decision Trees: Tree-like structures that make decisions based on feature values, capable of capturing non-linear relationships and interactions.
- Random Forests: Ensemble methods that combine multiple decision trees to improve accuracy and robustness.
- Gradient Boosting Machines (GBM): Another ensemble technique that sequentially builds trees, correcting errors from previous trees, resulting in high accuracy.
- K-Nearest Neighbors (k-NN): A non-parametric algorithm that classifies data points based on the majority class among their k-nearest neighbors.
- Naive Bayes: Based on Bayes’ theorem, assuming feature independence, often used in text classification.
- Neural Networks (Multilayer Perceptron, Deep Learning Models): Highly flexible and powerful models capable of learning complex non-linear patterns, particularly effective with large datasets and complex problems.
- Support Vector Machines (SVM) (Non-linear Kernels e.g., RBF, Polynomial): Extending SVM to non-linear boundaries using kernel functions.
Frequently Asked Questions (FAQs) about Classification in Machine Learning
What is a classification rule in machine learning?
A classification rule is a guideline or condition learned by a machine learning model that dictates how to assign a class label to a given input based on its features. It’s the decision-making logic of the classifier.
What are the main types of classification algorithms?
Major types include linear classifiers (like Logistic Regression and Linear SVM) and non-linear classifiers (like Decision Trees, Random Forests, Neural Networks, and k-NN). The choice depends on the data’s complexity and separability.
What is meant by learning classification?
Learning classification refers to the process where a machine learning algorithm acquires the ability to assign correct class labels to input data. It involves learning patterns and relationships from labeled training data to generalize and classify new, unseen data accurately within a supervised learning framework.
What is the key difference between classification and regression methods?
- Classification: Focuses on sorting data into discrete categories or classes. The output is a categorical label (e.g., spam/not spam, cat/dog).
- Regression: Focuses on predicting continuous numerical values. The output is a numerical value (e.g., house price, temperature).
Next Article What is Image Classification?
