Deep learning’s ever-increasing computational demands make your GPU choice a cornerstone of your experience. Selecting the right GPU can be daunting. What specifications truly matter? Is it GPU RAM, CUDA cores, Tensor Cores, or cache? How do you make a cost-effective decision, especially when considering the RTX 4070 Ti?
This article will guide you through the crucial aspects of GPU selection for deep learning, with a focus on the RTX 4070 Ti’s performance and value proposition. Whether you’re seeking a high-level overview or a deep dive into GPU architecture, this guide is for you.
(1) Quick Insights: For those primarily interested in performance metrics and value, jump directly to the performance charts, cost-effectiveness analysis, and RTX 4070 Ti recommendations. These sections provide core insights into GPU performance and the RTX 4070 Ti’s position in the market.
(2) Targeted Answers: If you have specific questions or misconceptions about GPUs, the Q&A section addresses common queries and clarifies frequent misunderstandings.
(3) In-Depth Understanding: For a comprehensive understanding of GPU functionality, including caches and Tensor Cores, read from start to finish. Feel free to navigate sections based on your existing knowledge.
Contents
hide
Overview
How GPUs Work: CPUs vs GPUs for Deep Learning
Key GPU Specifications for Deep Learning Speed
Tensor Cores: The Deep Learning Accelerators
Matrix Multiplication Without Tensor Cores
Matrix Multiplication With Tensor Cores
Advanced Matrix Multiplication: Asynchronous Copies & TMA
Memory Bandwidth: Feeding the Beast
Cache Hierarchy: L2, Shared Memory, L1, Registers
Estimating Ada and Hopper Architecture Performance
Practical Performance Benchmarks for RTX 4070 Ti and Beyond
Potential Biases in Performance Estimates
RTX 40 Series Advantages and Considerations
Sparse Network Training Capabilities
Low-Precision Computation: BF16 and TF32
Cooling and Fan Design Considerations
3-Slot Design and Power Demands
Power Limiting for Efficiency and Cooling
RTX 4090 Power Connector Concerns and Solutions
FP8 Support in RTX 40 Series: A Game Changer?
Raw GPU Performance Rankings
Deep Learning Performance per Dollar: RTX 4070 Ti Value
GPU Recommendations: Is RTX 4070 Ti Right for You?
Future GPU Trends: Is Waiting for Next-Gen Worth It?
Q&A: Common Questions and Misconceptions
PCIe 4.0 vs PCIe 5.0: Is It Necessary?
PCIe Lanes: 8x or 16x?
Fitting Multiple 3-Slot GPUs
Cooling Multi-GPU Setups
Mixing Different GPU Types
NVLink: Is It Beneficial?
Budget-Friendly GPU Options
GPU Carbon Footprint and Sustainability
Parallelizing Across Multiple Machines
Sparse Matrix Multiplication Limitations
CPU Recommendations for Multi-GPU Systems
Computer Case Design and Cooling
AMD GPUs vs NVIDIA: Catching Up?
Cloud GPUs vs Dedicated Desktops/Servers
Version History
Acknowledgments
Related Resources
Related Blog Posts
Overview
This guide is structured to progressively build your understanding of GPUs for deep learning. We begin by explaining the fundamental differences between CPUs and GPUs and what makes GPUs excel in deep learning tasks. We then delve into crucial GPU specifications—Tensor Cores, memory bandwidth, and cache hierarchy—and their direct impact on deep learning performance. Special attention is given to the NVIDIA RTX 40 series, including the RTX 4070 Ti, highlighting their unique features and performance characteristics.
Following the technical explanations, we present GPU recommendations tailored to various deep learning scenarios, emphasizing cost-effectiveness and performance. A comprehensive Q&A section addresses common questions and misconceptions, covering topics ranging from cooling solutions to cloud GPU alternatives. Finally, we explore the future of GPU technology and offer insights into whether upgrading now or waiting for future generations is the optimal choice. This article aims to equip you with the knowledge needed to make informed decisions when choosing a GPU for your deep learning projects, with a particular focus on understanding the deep learning GPU benchmarks and the value proposition of cards like the RTX 4070 Ti.
How GPUs Work: CPUs vs GPUs for Deep Learning
For frequent GPU users, understanding their operational principles is invaluable. This knowledge clarifies when GPUs shine and when they might falter, enabling you to appreciate the necessity of GPUs for deep learning and anticipate future hardware advancements. If you’re primarily interested in performance figures and recommendations for GPU purchasing, feel free to skip this section. For a concise explanation of GPU superiority over CPUs in deep learning, refer to this Quora answer by Tim Dettmers.
Read Tim Dettmers’ answer to Why are GPUs well-suited to deep learning? on Quora
This high-level explanation effectively illustrates why GPUs are better suited for deep learning than CPUs. Delving into the specifics allows us to discern what differentiates high-performing GPUs.
Key GPU Specifications for Deep Learning Speed
This section aims to provide an intuitive understanding of deep learning performance factors, empowering you to evaluate future GPUs independently. We’ll rank components by importance: Tensor Cores are paramount, followed by memory bandwidth, cache hierarchy, and lastly, FLOPS.
Tensor Cores: The Deep Learning Accelerators
Tensor Cores are specialized units designed for highly efficient matrix multiplication, the most computationally intensive operation in deep neural networks. Their efficiency is so significant that GPUs lacking Tensor Cores are generally not recommended for deep learning.
Understanding their operation underscores their importance. Consider a simplified 32×32 matrix multiplication (A*B=C) to illustrate computational patterns with and without Tensor Cores. This example, while simplified, captures the essence. A CUDA programmer would use this as a starting point, optimizing it through techniques like double buffering, register optimization, and instruction-level parallelism, which are beyond this article’s scope.
Grasping the concept of cycles is crucial. A 1 GHz processor executes 10^9 cycles per second, each cycle representing a computational opportunity. However, operations often span multiple cycles, creating a queue where subsequent operations await completion. This delay is termed latency.
Here are approximate latency timings for Ampere GPUs, noting that these can vary across GPU generations and these figures are specific to Ampere GPUs, which have comparatively slower caches:
- Global memory access (up to 80GB): ~380 cycles
- L2 cache: ~200 cycles
- L1 cache/Shared memory access (up to 128kb per SM): ~34 cycles
- Fused multiply-add (FFMA): 4 cycles
- Tensor Core matrix multiply: 1 cycle
Operations are processed in warps of 32 threads, operating synchronously. Memory operations are optimized for warps, e.g., global memory loads occur in 32*4 byte chunks (32 floats, one per thread). A streaming multiprocessor (SM), the GPU equivalent of a CPU core, can house up to 32 warps (1024 threads). SM resources are shared among active warps, sometimes favoring fewer warps to allocate more resources per warp.
For our 32×32 matrix multiply example, we assume 8 SMs (≈10% of RTX 3090) and 8 warps per SM.
To illustrate cycle latencies and resource interplay, we’ll examine matrix multiplication examples with and without Tensor Cores. These examples are simplified and real-world matrix multiplication utilizes larger shared memory tiles and slightly different patterns.
Matrix Multiplication Without Tensor Cores
For a 32×32 matrix multiplication (AB=C), we load frequently accessed data into shared memory due to its lower latency (34 cycles vs 200 cycles for L2 cache and 380 for global memory). Shared memory blocks are termed tiles. Loading two 32×32 float tiles into shared memory can be parallelized using 232 warps. With 8 SMs and 8 warps each, parallelization reduces the global to shared memory load to a single sequential operation, taking 200 cycles.
For multiplication, we load 32-number vectors from shared memory A and B, perform fused multiply-accumulate (FFMA), and store results in registers C. Each SM performs 8 dot products (32×32) to compute 8 C outputs. The technical reason for 8 (formerly 4 in older algorithms) is detailed in Scott Gray’s blog post on matrix multiplication. The cycle cost is:
200 cycles (global memory) + 8*34 cycles (shared memory) + 8*4 cycles (FFMA) = 504 cycles
Now, let’s examine the cost with Tensor Cores.
Matrix Multiplication With Tensor Cores
Tensor Cores perform 4×4 matrix multiplications in a single cycle. Data must first be in the Tensor Core. Similar to the previous example, we read from global memory (200 cycles) and store in shared memory. A 32×32 matrix multiply requires 8×8=64 Tensor Core operations. An SM has 8 Tensor Cores, so 8 SMs provide the necessary 64. Data transfer from shared memory to Tensor Cores takes one memory transfer (34 cycles), followed by 64 parallel Tensor Core operations (1 cycle). The total cost is:
200 cycles (global memory) + 34 cycles (shared memory) + 1 cycle (Tensor Core) = 235 cycles.
Tensor Cores significantly reduce matrix multiplication cost from 504 to 235 cycles. In this simplified case, Tensor Cores reduce both shared memory access and FFMA operation costs.
This example is simplified. In reality, threads compute memory addresses during global-to-shared memory transfers. Newer architectures like Hopper (H100) introduce the Tensor Memory Accelerator (TMA) to handle index calculations in hardware, freeing threads for computation.
Advanced Matrix Multiplication: Asynchronous Copies & TMA
RTX 30 Ampere and RTX 40 Ada GPUs support asynchronous transfers between global and shared memory. Hopper H100 further enhances this with the Tensor Memory Accelerator (TMA), combining asynchronous copies and index calculation for reads and writes. TMA allows threads to focus on matrix multiplication rather than index computation.
The TMA fetches data from global to shared memory (200 cycles). Upon arrival, it asynchronously fetches the next data block from global memory. Concurrently, threads load data from shared memory and perform matrix multiplication via Tensor Cores. Once finished, threads wait for TMA to complete the next transfer, and the cycle repeats.
Asynchronous operation means the second global memory read overlaps with thread processing, reducing its effective time. The second read takes approximately 165 cycles (200 – 34 – 1).
Since reads are repetitive, only the initial memory access is slow. Subsequent accesses are partially overlapped with TMA, reducing average time by 35 cycles.
165 cycles (async copy wait) + 34 cycles (shared memory) + 1 cycle (Tensor Core) = 200 cycles.
This further accelerates matrix multiplication by about 15%.
These examples highlight the importance of memory bandwidth for Tensor-Core GPUs. Global memory latency is the primary bottleneck in Tensor Core matrix multiplication. Reducing global memory latency would further accelerate GPUs. This can be achieved by increasing memory clock frequency (more cycles/second, but increased heat/energy) or widening the data bus (more elements transferred simultaneously).
Memory Bandwidth: Feeding the Beast
Tensor Cores are incredibly fast, often idling while awaiting data from global memory. During large-scale training like GPT-3, Tensor Core utilization is around 45-65%, meaning even with massive networks, Tensor Cores are idle roughly half the time.
Therefore, memory bandwidth is a crucial performance indicator for GPUs with Tensor Cores. For instance, the A100 GPU boasts 1,555 GB/s memory bandwidth versus the V100’s 900 GB/s. A basic speedup estimate for A100 over V100 is 1555/900 = 1.73x. When considering deep learning GPU benchmarks, memory bandwidth becomes a critical factor, especially when comparing cards like the RTX 4070 Ti against competitors.
Cache Hierarchy: L2, Shared Memory, L1, Registers
Since memory transfers to Tensor Cores are performance-limiting, we seek GPU attributes that expedite these transfers. L2 cache, shared memory, L1 cache, and register usage are all interconnected. A memory hierarchy, progressing from slow global memory to faster L2, shared memory, L1, and registers, facilitates quicker transfers. Faster memory is invariably smaller.
L2 and L1 caches are conceptually similar, but L2’s larger size implies longer average access times. Imagine L1 and L2 caches as warehouses; retrieving an item takes longer in a larger warehouse (L2). Large cache = slower, small cache = faster.
Matrix multiplication leverages this hierarchy by breaking down large operations into smaller, faster chunks (tiles). Tiles are processed in fast, local shared memory close to the streaming multiprocessor (SM). Tensor Cores further refine this: tiles are loaded into Tensor Core registers, the fastest memory tier. L2 cache tiles are 3-5x faster than global GPU memory (GPU RAM), shared memory is ~7-10x faster, and Tensor Core registers are ~200x faster.
Larger tiles enable greater memory reuse, as detailed in my TPU vs GPU blog post. TPUs can be viewed as possessing exceptionally large tiles per Tensor Core, leading to more efficient memory reuse per global memory transfer, slightly outperforming GPUs in matrix multiplication efficiency.
Tile size depends on per-SM memory and total L2 cache. Shared memory sizes across architectures are:
- Volta (Titan V): 128kb shared memory / 6 MB L2
- Turing (RTX 20 series): 96 kb shared memory / 5.5 MB L2
- Ampere (RTX 30 series): 128 kb shared memory / 6 MB L2
- Ada (RTX 40 series, including RTX 4070 Ti): 128 kb shared memory / 72 MB L2
Ada’s significantly larger L2 cache allows for larger tiles, minimizing global memory access. For BERT-large training, input and weight matrices can fit within Ada’s L2 cache, reducing global memory loads to once per matrix multiplication, leading to 1.5-2.0x speedups. Speedups for larger models are lower during training, but specific model sizes benefit greatly. Inference with batch sizes over 8 also benefits from larger L2 caches, making cards like the RTX 4070 Ti, with its Ada architecture, particularly compelling for both training and inference workloads when considering deep learning GPU benchmarks.
Estimating Ada and Hopper Architecture Performance
This section details the technical basis for performance estimations for Ampere GPUs. Skip this section if you’re uninterested in these technical details.
Practical Performance Benchmarks for RTX 4070 Ti and Beyond
If we have a performance estimate for one GPU within an architecture (Hopper, Ada, Ampere, Turing, Volta), we can extrapolate to other GPUs in the same series. NVIDIA has benchmarked A100 vs V100 vs H100 across computer vision and NLP tasks (NVIDIA Deep Learning Performance). However, direct comparisons are complicated by varying batch sizes and GPU counts, favoring H100 results for marketing purposes. Larger batch sizes are arguably fair for H100/A100 due to their larger memory, but unbiased architecture comparisons require consistent batch sizes.
To obtain unbiased estimates, we adjust datacenter GPU results by: (1) accounting for batch size differences and (2) accounting for 1 vs 8 GPU performance. NVIDIA data provides estimates for both biases.
Doubling batch size increases CNN throughput (images/s) by ~13.6%. Transformer benchmarks on RTX Titan yielded similar 13.5% increase. This appears to be a robust estimate.
Parallelizing across GPUs incurs performance loss due to networking overhead. A100 8x GPU systems have better networking (NVLink 3.0) than V100 8x systems (NVLink 2.0), another confounding factor. NVIDIA data indicates 8x A100 systems have 5% less overhead than 8x V100 for CNNs. For transformers, the overhead difference is 7%.
Using these figures, we can estimate speedups for specific deep learning architectures from NVIDIA data. Tesla A100 speedups over Tesla V100 are:
- SE-ResNeXt101: 1.43x
- Masked-R-CNN: 1.47x
- Transformer (12-layer, Machine Translation, WMT14 en-de): 1.70x
These figures are slightly lower than theoretical estimates for computer vision, possibly due to smaller tensor dimensions, overhead from matrix multiplication preparation operations (img2col, FFT), or operations that don’t saturate the GPU (e.g., smaller final layers). Algorithm-specific artifacts (grouped convolutions) may also contribute.
Practical transformer estimates closely align with theoretical values, likely due to simpler algorithms for large matrices. These practical estimates are used for GPU cost-efficiency calculations, including analyses relevant to the RTX 4070 Ti and its position in deep learning GPU benchmarks.
Potential Biases in Performance Estimates
The above estimates are for H100, A100, and V100 GPUs. NVIDIA has previously introduced unannounced performance degradations in “gaming” RTX GPUs, including: (1) reduced Tensor Core utilization, (2) gaming-focused fan cooling, and (3) disabled peer-to-peer GPU transfers. Similar degradations in RTX 40 series compared to Hopper H100 are possible.
One degradation was found in Ampere GPUs: Tensor Core performance reduction making RTX 30 series less suitable than Quadro cards for deep learning. This practice, also present in RTX 20 series, was extended to the RTX 3090, the Titan-equivalent card, unlike the RTX Titan.
Currently, no degradations are known for Ada GPUs, including the RTX 4070 Ti, but updates will be provided on Twitter. Understanding these potential biases is crucial when interpreting deep learning GPU benchmarks for cards like the RTX 4070 Ti.
RTX 40 Series Advantages and Considerations
The NVIDIA Ada RTX 40 series, including the RTX 4070 Ti, offers advancements over the RTX 30 series, such as FP8 Tensor Cores. Features like new data types enhance ease-of-use, providing performance boosts similar to Turing but with less programming effort.
RTX 40 series shares power and temperature considerations with RTX 30. RTX 4090 melting power connector issues are preventable with correct cable installation.
Sparse Network Training Capabilities
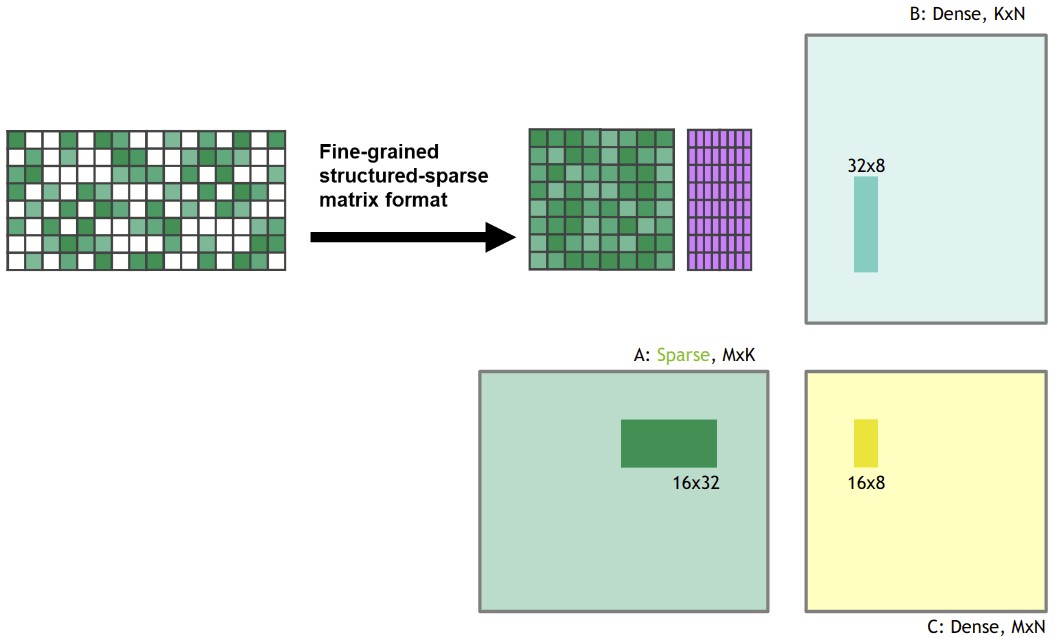
Ampere architecture enables fine-grained structured sparse matrix multiplication at dense speeds. It works by dividing weight matrices into 4-element pieces. If two elements are zero, as illustrated in Figure 1, Ampere’s sparse matrix Tensor Core feature compresses the sparse matrix into a dense, half-size representation (Figure 2). This compressed tile is then fed into the Tensor Core, performing a matrix multiplication of double the usual size, effectively yielding a 2x speedup due to halved bandwidth requirements from shared memory.
Figure 1: Structure supported by the sparse matrix multiplication feature in Ampere GPUs. The figure is taken from Jeff Pool’s GTC 2020 presentation on Accelerating Sparsity in the NVIDIA Ampere Architecture by courtesy of NVIDIA, illustrating the structure of sparse matrices that Ampere GPUs can efficiently process.
Figure 2: The sparse matrix is compressed to a dense representation before matrix multiplication. This process, as depicted, allows for efficient computation on sparse data. The figure is from Jeff Pool’s GTC 2020 presentation on Accelerating Sparsity in the NVIDIA Ampere Architecture courtesy of NVIDIA, highlighting the compression technique used to enhance sparse matrix operations.
This feature enhances sparse training algorithms, potentially yielding up to 2x speedups. While still experimental, sparse training capabilities in GPUs like the RTX 4070 Ti represent a forward-looking advantage.
Figure 3: Sparse training algorithm stages.
Figure 3: The sparse training algorithm consists of three stages: (1) Determine layer importance. (2) Remove smallest weights. (3) Grow new weights based on layer importance. More details are available in the sparse training blog post. This illustrates the process of identifying and pruning less important weights in neural networks to improve efficiency.
Low-Precision Computation: BF16 and TF32
New data types improve stability in low-precision backpropagation.
Figure 4: Low-precision 8-bit data types.
Figure 4: Low-precision deep learning 8-bit datatypes developed to enhance training. The dynamic tree datatype uses a dynamic bit to start a binary bisection tree quantizing the range [0, 0.9], with preceding bits for the exponent, enabling high precision for both large and small numbers. This specialized datatype is designed for stable and efficient low-precision deep learning computations.
FP16 training suffers from gradient explosion due to its limited range ([-65,504, 65,504]). Loss scaling is used to mitigate this. BrainFloat16 (BF16) format, with more exponent bits, matches FP32’s range ([-3*10^38, 3*10^38]). BF16 trades precision for range, but gradient precision is less critical for learning. BF16 eliminates the need for loss scaling, potentially enhancing training stability.
TensorFloat-32 (TF32) offers near-FP32 stability with FP16-like speedups. Switching from FP32 to TF32 and FP16 to BF16 requires minimal code changes.
These new data types simplify low-precision training, offering ease of use improvements rather than raw speedups compared to carefully optimized FP16 training with techniques like loss scaling. However, for users seeking straightforward low-precision workflows, cards like the RTX 4070 Ti with robust BF16 and TF32 support are highly advantageous, contributing to their strong deep learning GPU benchmarks.
Cooling and Fan Design Considerations
RTX 30 series’ fan design is effective, but non-founders edition GPUs may have cooling issues. GPUs exceeding 80°C throttle performance. Stacking GPUs can exacerbate overheating. PCIe extenders can create spacing for better cooling.
PCIe extenders effectively improve GPU cooling. This setup, while not aesthetically pleasing, maintains excellent GPU temperatures. It also addresses space constraints in desktop cases for multi-GPU setups, potentially enabling 4x RTX 4090 configurations even within standard cases.
Figure 5: 4x GPUs with PCIe extenders for cooling.
Figure 5: A 4x GPU setup utilizing PCIe extenders for enhanced cooling. Despite its somewhat messy appearance, this configuration is highly effective in maintaining low temperatures, especially when using GPUs like RTX 2080 Ti Founders Edition, which can be prone to overheating. This setup has been successfully used for 4 years, demonstrating its reliability in demanding deep learning environments.
3-Slot Design and Power Demands
RTX 3090 and RTX 4090 are 3-slot GPUs, hindering 4x setups with standard NVIDIA fan designs. Their >350W TDP makes 2-slot multi-GPU cooling challenging. RTX 3080 is slightly better at 320W TDP, but 4x RTX 3080 cooling remains difficult.
Powering 4x 350W (RTX 3090) or 4x 450W (RTX 4090) systems is also challenging. 1600W PSUs are available, but leaving only 200W for CPU/motherboard can be tight. However, CPUs are typically lightly loaded in deep learning. A 1600W PSU may suffice for 4x RTX 3080, but >1700W is recommended for 4x RTX 3090. Cryptomining PSUs are a high-wattage option. PSU form factor and outlet compatibility (especially in the US) should be considered.
Power Limiting for Efficiency and Cooling
GPU power limits can be set programmatically (e.g., RTX 3090 to 300W from 350W). In 4x GPU systems, this 200W saving can enable 4x RTX 3090 setups with 1600W PSUs and improve cooling. Power limiting addresses both power and cooling issues in 4x RTX 3080/3090 configurations. Effective blower GPUs (or standard designs with power limits) are still needed for 4x setups, but power limiting resolves PSU concerns.
Figure 6: Power limit effect on RTX 2080 Ti cooling.
Figure 6: Reducing the power limit of an RTX 2080 Ti results in a slight cooling effect. A 50-60W reduction in power limit leads to lower temperatures and quieter fan operation, as observed using nvidia-smi. This demonstrates the potential for power limiting to manage GPU thermals effectively.
Power limiting does reduce performance, but the question is by how much. Benchmarks on a 4x RTX 2080 Ti system (Figure 5) under varying power limits, using BERT Large inference (GPU-intensive), show minimal slowdown. Power limiting by 50W (sufficient for 4x RTX 3090) reduces performance by only ~7% (Figure 7). This suggests power limiting is a viable strategy for balancing performance, power consumption, and cooling in multi-GPU setups, potentially making even high-TDP cards like the RTX 4070 Ti more manageable in dense configurations.
Figure 7: RTX 2080 Ti slowdown with power limits.
Figure 7: Measured slowdown for different power limits on an RTX 2080 Ti. Measurements are based on mean processing times for 500 mini-batches of BERT Large during inference (excluding the softmax layer). The graph illustrates that even significant power reductions result in relatively minor performance losses, highlighting the efficiency of power limiting as a thermal and power management technique.
RTX 4090 Power Connector Concerns and Solutions
RTX 4090 power cable melting issues were initially misattributed to cable bending, but user error (incorrect cable insertion) was the primary cause, affecting only 0.1% of users. This video details correct cable installation.
RTX 4090 cards are safe with proper installation:
- Ensure clean contacts on cables and GPUs.
- Insert power connector until a *click* is heard (crucial).
- Test for secure fit by gently wiggling the cable; it should not move.
- Visually inspect for gaps between cable and socket.
These instructions are equally relevant for ensuring the reliable operation of other RTX 40 series cards, including the RTX 4070 Ti.
FP8 Support in RTX 40 Series: A Game Changer?
8-bit Float (FP8) support in RTX 40 series and H100 GPUs is a significant advantage. FP8 doubles data loading speed, doubles cache capacity for matrix elements, and in the RTX 4090, enables 0.66 PFLOPS of compute – surpassing the world’s fastest supercomputer in 2007. 4x RTX 4090 FP8 compute rivals 2010’s fastest supercomputer (deep learning emerged around 2009). This FP8 capability is a key differentiator for the RTX 40 series in deep learning GPU benchmarks.
The challenge with 8-bit precision is transformer instability, potentially causing crashes or nonsensical output. My paper on LLM instability and blog post address this.
The key takeaway: 8-bit precision introduces instability, but maintaining high precision in a few dimensions resolves this.
Main results from 8-bit matrix multiplication research for LLMs.
Main results from my work on 8-bit matrix multiplication for Large Language Models (LLMs). The chart compares the performance of a baseline 8-bit method against LLM.int8(), a method developed to maintain 16-bit baseline performance even with Int8 matrix multiplication. This highlights the advancements in maintaining accuracy while leveraging the efficiency of lower precision computation.
While RTX 30/A100/Ampere GPUs supported Int8, RTX 40’s FP8 is a major upgrade. FP8 is more stable than Int8 and easier to use in layer norm or non-linear functions. This simplifies FP8 training and inference, likely making it commonplace soon.
For more on Float vs Integer data types, see my paper on k-bit inference scaling laws. Float data types, bit-for-bit, preserve more information than Integer types, improving LLM zero-shot accuracy.
4-bit Inference scaling laws for Pythia LLMs across data types.
4-bit Inference scaling laws for Pythia Large Language Models across different data types. The graph demonstrates that bit-for-bit, 4-bit float data types achieve better zeroshot accuracy compared to Int4 data types in LLMs. This underscores the efficiency and accuracy benefits of float-based low-precision computation for large language models.
Raw GPU Performance Rankings
The chart below ranks raw relative GPU performance, highlighting the performance gap between H100 GPUs and older cards in 8-bit compute.
Raw relative transformer performance of GPUs.
Shown is raw relative transformer performance of GPUs, including the RTX 4070 Ti. For 8-bit inference, an RTX 4090 achieves approximately 0.33x the performance of an H100 SMX. This chart illustrates the substantial performance differences between various GPUs, particularly in 8-bit inference tasks, and positions the RTX 4070 Ti within this performance landscape.
8-bit compute was not modeled for older GPUs due to the enhanced effectiveness of 8-bit inference and training on Ada/Hopper GPUs (FP8, TMA). TMA reduces overhead in 8-bit matrix multiplication by automating read/write index computation. Ada/Hopper FP8 support makes 8-bit training more efficient.
8-bit training numbers were not modeled due to unknown L1/L2 cache latencies on Hopper/Ada. Rumored cache speeds suggest 8-bit training on Hopper/Ada could be 3-4x faster than 16-bit training.
FP8 Tensor Cores have limitations, like lack of transposed matrix multiplication support. Backpropagation may require weight transposing or storing both transposed and non-transposed weights, potentially reducing speedups. My Int8 training experiments in LLM.int8() using dual weight sets showed significant speedup reductions. Algorithm/software optimizations may mitigate this.
For models under 13B parameters, Int8 inference on older GPUs is comparable to 16-bit. Int8 on older GPUs is only relevant for 175B+ parameter models. Appendix D of my LLM.int8() paper benchmarks Int8 performance on older GPUs for further detail.
Deep Learning Performance per Dollar: RTX 4070 Ti Value
The chart below shows performance per US dollar for GPUs, sorted by 8-bit inference performance.
To use the chart for GPU selection:
- Determine required GPU memory (12GB+ for image generation, 24GB+ for transformers).
- Consider 8-bit (experimental but future standard) or 16-bit performance needs.
- Find the most cost-effective GPU with sufficient memory for your chosen metric (8-bit or 16-bit).
Performance per dollar of GPUs for deep learning tasks.
Shown is relative performance per US Dollar of GPUs, including the RTX 4070 Ti, normalized by desktop computer cost and average Amazon/eBay prices. 5-year electricity cost (0.175 USD/kWh, 15% GPU utilization) is included. The RTX 4070 Ti demonstrates exceptional 8-bit and 16-bit inference performance per dollar, outperforming many higher-priced GPUs like the RTX 3090 in cost-effectiveness. This chart is crucial for understanding the value proposition of different GPUs in deep learning applications, especially when budget is a key consideration.
The RTX 4070 Ti is highly cost-effective for both 8-bit and 16-bit inference. RTX 3080 remains cost-effective for 16-bit training. While cost-effective, these may lack memory for some use cases. They are excellent entry-level cards. Smaller GPUs are suitable for Kaggle competitions where smaller models are often sufficient and methodological approach outweighs model size.
A6000 Ada GPUs and H100 SXM are excellent for academic/startup servers due to cost-effectiveness, high memory, and strong performance. L40 GPUs are also worth considering if competitively priced. A recommended cluster mix is 66-80% A6000 GPUs and 20-33% H100 SXM GPUs.
GPU Recommendations: Is RTX 4070 Ti Right for You?
The recommendation flowchart below (interactive app: Nan Xiao GPU Recommender) assists in GPU selection in ~80% of cases. For budget constraints, consult the performance/dollar charts to find the most cost-effective GPU with sufficient memory. Estimate memory needs by testing your workload on vast.ai or Lambda Cloud. Cloud GPUs are suitable for sporadic use or when large datasets don’t require local processing. However, dedicated GPUs are more economical for sustained, high-usage scenarios. See the “Cloud vs Dedicated GPU” section for cost analysis. The RTX 4070 Ti, given its performance and price point, is a strong contender for many deep learning tasks, and the flowchart can help determine if it aligns with your specific needs.
GPU recommendation chart for Ada/Hopper GPUs.
GPU recommendation chart for Ada/Hopper GPUs, including the RTX 4070 Ti. This flowchart guides users through a series of questions to determine the most suitable GPU for their deep learning needs. While effective in many scenarios, users are advised to consult cost/performance charts for budget-sensitive decisions. [interactive app]
Future GPU Trends: Is Waiting for Next-Gen Worth It?
To decide whether to upgrade now or wait, consider future GPU improvements.
Past performance gains from transistor size reduction are diminishing. SRAM scaling no longer improves speed, and may even regress. Logic scaling (Tensor Cores) doesn’t necessarily accelerate GPUs as memory access to Tensor Cores (SRAM, GPU RAM speed/size) is the bottleneck. GPU RAM speed increases with HBM3+, but HBM is too costly for consumer GPUs. Raw GPU speed increases primarily rely on higher power and cooling, as seen in RTX 30/40 series, but this approach is nearing its limit.
Chiplets, like those used by AMD CPUs, are a promising direction. AMD surpassed Intel with CPU chiplets – small chips fused with high-speed on-chip networks. Think of them as closely coupled GPUs, almost a single large GPU. Chiplets are cheaper to manufacture but harder to integrate. AMD’s next-gen GPUs will be chiplet-based, while NVIDIA has no public chiplet plans. This could give AMD a cost/performance advantage in the next generation.
Specialized logic, like asynchronous copy hardware (RTX 30/40, A100) and Tensor Memory Accelerator (TMA), is a major performance driver. These units reduce overhead in global-to-shared memory transfers, enabling more computation per thread, especially beneficial for 8-bit compute. Low-bit precision is another near-term performance path. 8-bit inference and training adoption is imminent, followed by 4-bit inference. 4-bit training is in research, with potential for high-performance FP4 LLMs in 1-2 years. 2-bit training is currently improbable, but easier than further transistor scaling. Hardware progress depends on software/algorithms leveraging specialized features.
Algorithm + hardware improvements are likely until ~2032, after which GPU performance gains may plateau (similar to smartphones). Post-2032, networking algorithms and mass hardware may dominate. Consumer GPUs’ future relevance is uncertain. A hypothetical RTX 9090 might be needed for future demanding applications, but cloud APIs might offer cheaper alternatives.
Investing in 8-bit capable GPUs, like the RTX 4070 Ti, is a solid long-term investment for the next ~9 years. 4-bit and 2-bit improvements may be incremental, and features like Sort Cores depend on sparse matrix multiplication adoption. Future advancements in 2-3 years, appearing in GPUs in ~4 years, are anticipated, but matrix multiplication reliance is limiting. This extends the lifespan of GPU investments.
Q&A: Common Questions and Misconceptions
PCIe 4.0 vs PCIe 5.0: Is It Necessary?
Generally, no. PCIe 5.0/4.0 is beneficial for GPU clusters or 8x GPU machines, improving parallelization and slightly accelerating data transfer. Data transfer is rarely a bottleneck. Data storage is a bottleneck in computer vision data pipelines, not PCIe CPU-to-GPU transfer. PCIe 5.0/4.0 benefits are minimal for most users, perhaps 1-7% better parallelization in 4-GPU setups.
PCIe Lanes: 8x or 16x?
Similar to PCIe 4.0, generally not crucial. PCIe lanes aid parallelization and fast data transfer, seldom bottlenecks. 4x lanes are adequate, especially for 2 GPUs. For 4 GPUs, 8x lanes per GPU are preferable, but 4x lanes may only incur ~5-10% performance loss in 4-GPU parallelization.
Fitting Multiple 3-Slot GPUs
Use 2-slot variants or PCIe extenders for spacing. Consider cooling and PSU requirements alongside space. PCIe extenders address both space and cooling, provided sufficient case space and extender length.
Cooling Multi-GPU Setups
See “Fitting Multiple 3-Slot GPUs” and “Cooling and Fan Design Considerations.”
Mixing Different GPU Types
Yes, but inefficient parallelization. Performance is limited to the slowest GPU speed (data/fully sharded parallelism). Different GPUs function, but parallelization is inefficient due to synchronization wait times for slower GPUs.
NVLink: Is It Beneficial?
Generally, no. NVLink, a high-speed GPU interconnect, is useful for >128 GPU clusters. It offers minimal benefit over PCIe for smaller setups.
Budget-Friendly GPU Options
Consider used GPUs. Use a cheap GPU for prototyping, then cloud services like vast.ai or Lambda Cloud for full experiments. Cost-effective for infrequent large model training/inference, with more time spent prototyping on smaller models. Cloud GPUs are less suitable for months-long, daily high-usage scenarios. See “Cloud vs Dedicated GPU” section for cost analysis. Even within budget constraints, exploring deep learning GPU benchmarks for cards like the RTX 4070 Ti‘s lower-priced variants can reveal excellent value.
GPU Carbon Footprint and Sustainability
Use a carbon calculator to estimate GPU carbon footprint. GPUs generate significantly more carbon than flights. Prioritize green energy sources. If unavailable, buy carbon offsets. Portfolio diversification minimizes offset scam risks. UN-verified methane-burning projects in China demonstrate reliable offset generation.
Parallelizing Across Multiple Machines
Use +50Gbits/s network cards for inter-machine parallelization speedups. EDR Infiniband (≥50 GBit/s) is recommended. Two EDR cards with cables cost ~$500 on eBay. 10 Gbit/s Ethernet may suffice in specific cases (certain CNNs, Microsoft DeepSpeed).
Sparse Matrix Multiplication Limitations
Ampere’s sparse matrix feature requires structured sparsity (2 zeros per 4 elements). Arbitrary sparse matrix multiplication is not fully supported. Algorithm adjustments to compress 4 values into 2-value representations are possible, but precise arbitrary sparsity is limited.
CPU Recommendations for Multi-GPU Systems
AMD CPUs are generally preferred for deep learning over Intel, unless CPU-heavy Kaggle competitions (linear algebra on CPU) are the focus. Even for Kaggle, AMD CPUs are competitive. Threadrippers are excellent for 4x GPU builds. For 8x GPU systems, vendor-recommended CPUs prioritize reliability over peak performance or cost-effectiveness.
Computer Case Design and Cooling
Case design minimally impacts cooling (1-3°C improvement). GPU spacing is crucial (10-30°C improvement). With GPU spacing, case design is irrelevant. Without spacing, blower fans, water cooling, or PCIe extenders are necessary; case design and fans are secondary.
AMD GPUs vs NVIDIA: Catching Up?
Not in the next 1-2 years. Three challenges: Tensor Cores, software, community. AMD GPUs have strong silicon (FP16, memory bandwidth) but lack Tensor Cores, hindering deep learning performance. Packed low-precision math is insufficient. Tensor Core equivalents are essential for competitiveness. Rumored data center cards with Tensor Core equivalents have not materialized. Even with such hardware, high cost would give NVIDIA an advantage.
AMD’s ROCm software and PyTorch support have significantly improved, largely solving the software challenge. However, community and ecosystem lag. NVIDIA benefits from a large community, extensive online resources, and readily available experts. This creates trust and ease of use. AMD’s community is weaker, similar to Julia vs Python in scientific computing – Julia is arguably superior but Python’s strong community dominates.
AMD likely won’t catch up until Tensor Core equivalents are introduced (1/2-1 year?) and a robust ROCm community develops (2+ years?). AMD may gain market share in specific niches (cryptocurrency, datacenters), but NVIDIA will likely maintain deep learning monopoly for the foreseeable future.
Cloud GPUs vs Dedicated Desktops/Servers
Rule of thumb: dedicated GPUs are cheaper for >1 year of deep learning use. Cloud instances are preferable for shorter durations or if scalability is paramount and cloud computing expertise exists.
Break-even point depends on service and usage. Example: AWS V100 spot instance vs RTX 3090 desktop. RTX 3090 desktop costs $2,200 + $71/year electricity (15% utilization, 0.12 USD/kWh). AWS on-demand V100 instance: $2.14/hour.
Desktop annual electricity cost (15% utilization): (350W GPU + 100W CPU) 0.15 24 hours 365 days $0.12/kWh = ~$71.
Break-even point (desktop vs cloud, 15% utilization): ~300 days.
$2.14/hour 0.15 utilization 24 hours/day * 300 days = $2,311 (cloud cost) vs $2,200 (desktop cost) + ~$71 electricity.
If deep learning use exceeds ~300 days, desktop is cheaper. Perform similar calculations for your cloud service.
Typical utilization rates:
- PhD student personal desktop: <15%
- PhD student slurm GPU cluster: >35%
- Company-wide slurm research cluster: >60%
Personal machine utilization is often overestimated (typically 5-10%). Slurm GPU clusters are recommended for research groups and companies over individual desktops.
Version History
- 2023-01-30: Improved font, recommendation chart, 5-year electricity cost perf/USD chart, Async copy/TMA update, FP8 training update, general improvements.
- 2023-01-16: Added Hopper/Ada GPUs, GPU recommendation chart, TMA/L2 cache info.
- 2020-09-20: Power limiting for 4x RTX 3090, older GPUs in charts, sparse matrix multiplication figures.
- 2020-09-07: NVIDIA Ampere series GPUs, GPU details.
- 2019-04-03: RTX Titan, GTX 1660 Ti, TPU section update, startup hardware discussion.
- 2018-11-26: RTX overheating issues.
- 2018-11-05: RTX 2070, updated recommendations, performance data charts, TPU section update.
- 2018-08-21: RTX 2080/2080 Ti, performance analysis rework.
- 2017-04-09: Cost-efficiency analysis, Titan Xp recommendation update.
- 2017-03-19: Blog post cleanup, GTX 1080 Ti addition.
- 2016-07-23: Titan X Pascal, GTX 1060 addition, recommendation updates.
- 2016-06-25: Multi-GPU section rework, removed simple neural network memory section, expanded convolutional memory section, truncated AWS section, Xeon Phi opinion, GTX 1000 series updates.
- 2015-08-20: AWS GPU instances section, GTX 980 Ti comparison.
- 2015-04-22: GTX 580 no longer recommended, performance relationships added.
- 2015-03-16: GPU recommendation updates: GTX 970, GTX 580.
- 2015-02-23: GPU recommendations, memory calculations updated.
- 2014-09-28: CNN memory requirement emphasis added.
Acknowledgments
Thanks to Suhail for H100 price correction, Gjorgji Kjosev for font issues, Anonymous for TMA unit correction, Scott Gray for FP8 transposed matrix multiplication info, and reddit/HackerNews users for improvements.
Past acknowledgments: Mat Kelcey (GTX 970 debugging/testing), Sander Dieleman (CNN memory advice), Hannes Bretschneider (GTX 580 software dependencies), Oliver Griesel (AWS notebook solutions), Brad Nemire (RTX Titan benchmarking), Agrin Hilmkil, Ari Holtzman, Gabriel Ilharco, Nam Pho (previous version feedback).
Related Resources
Related Blog Posts
- TPUs vs GPUs for Transformers/BERT
- Sparse Networks from Scratch
- Deep Learning Hardware Guide
- LLM-INT8 and Emergent Features
