Deep learning has revolutionized scientific computing, becoming an indispensable tool across industries tackling intricate challenges. At the heart of this revolution are Deep Learning Models, sophisticated algorithms leveraging neural networks to perform specific tasks.
This guide delves into the essential artificial neural networks that power these models, exploring how deep learning algorithms emulate the human brain to solve complex problems.
Understanding Deep Learning Models
Deep learning models are built upon artificial neural networks to execute complex computations on vast datasets. As a subset of machine learning, deep learning mirrors the structure and functionality of the human brain, enabling machines to learn from examples. Its applications are widespread, impacting sectors like healthcare, e-commerce, entertainment, and advertising.
Elevate Your AI and Machine Learning Career
Embark on a transformative journey with our comprehensive Post Graduate Program. Learn More Now
Decoding Neural Networks: The Foundation of Deep Learning Models
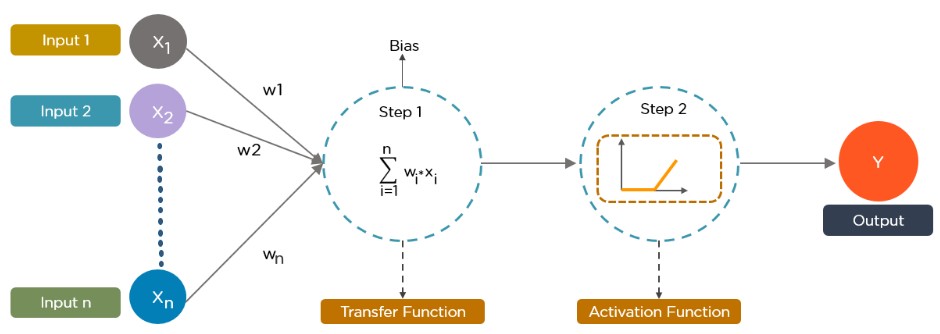
A neural network, the bedrock of deep learning models, is designed to mimic the human brain’s architecture. It comprises interconnected artificial neurons, or nodes, organized into three fundamental layers:
- Input Layer: The entry point for data.
- Hidden Layer(s): One or more layers where complex computations occur.
- Output Layer: Produces the final result or prediction.
In operation, each node receives data as inputs. These inputs are then multiplied by assigned weights, summed, and adjusted by a bias. Activation functions, which are nonlinear, determine if a neuron “fires,” passing information to the next layer. This intricate process allows neural networks to learn complex patterns and make informed decisions.
How Deep Learning Models and Algorithms Function
Deep learning models leverage self-learning representations, relying on Artificial Neural Networks (ANNs) to mirror human brain information processing. During training, these algorithms analyze unknown elements within input distributions to extract features, categorize objects, and identify valuable data patterns. This learning process occurs across multiple layers, enabling algorithms to construct sophisticated models.
Numerous algorithms power deep learning models, each with unique strengths and applications. While no single algorithm is universally superior, selecting the right one is crucial for task-specific optimization. A solid grasp of primary algorithms is essential for effectively leveraging deep learning’s potential.
Top 10 Deep Learning Models and Algorithms in Detail
1. Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) stand out as deep learning models adept at processing structured grid data, particularly images. Their success is evident in image classification, object detection, and facial recognition tasks, making them foundational in computer vision.
How CNN Models Work:
- Convolutional Layer: This initial layer employs filters (kernels) across the input image. Each filter slides over the image, performing convolutions to generate feature maps. This process is key to detecting features like edges, textures, and intricate patterns within images.
- Pooling Layer: Following convolution, pooling layers reduce the dimensionality of feature maps while preserving essential spatial information. Max pooling and average pooling are common techniques, simplifying the feature maps and making computation more efficient.
- Fully Connected Layer: After several convolutional and pooling stages, the processed features are flattened into a one-dimensional vector. This vector is then fed into one or more fully connected (dense) layers. The final fully connected layer serves as the output layer, responsible for making the ultimate classification or prediction based on learned features.
2. Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are specifically engineered to discern patterns within sequential data, such as time series data or natural language. They maintain a hidden state, acting as a memory, to retain information from preceding inputs in the sequence.
How RNN Models Work:
- Hidden State: At each step in processing a sequence, the RNN updates its hidden state. This update is based on both the current input and the hidden state from the previous step. This mechanism allows the network to remember and utilize past information to understand the context and dependencies in the sequence.
- Output Generation: For each time step, the hidden state is used to generate an output. This output could be a prediction, a classification, or any other form of sequence-related information.
- Training with Backpropagation Through Time (BPTT): RNNs are trained using a technique called Backpropagation Through Time (BPTT). BPTT extends the standard backpropagation algorithm to handle sequential data. It works by unfolding the RNN over time and then calculating gradients across all time steps to minimize prediction errors. This method enables the RNN to learn long-range dependencies within sequences.
3. Long Short-Term Memory Networks (LSTMs)
Long Short-Term Memory Networks (LSTMs) are specialized RNNs designed to overcome the challenge of learning long-term dependencies in sequential data. They mitigate the vanishing gradient problem inherent in traditional RNNs, making them highly effective for applications like speech recognition and time series forecasting where context over extended sequences is crucial.
How LSTM Models Work:
- Cell State: LSTMs introduce a cell state, a key component that acts as a memory track running through the entire sequence. The cell state’s primary function is to carry relevant information across many time steps, facilitating the learning of long-range dependencies.
- Gates – Input, Forget, Output: LSTMs incorporate three types of gates—input, forget, and output gates—that precisely control the flow of information into and out of the cell state.
- Input Gate: This gate determines which new information from the current input should be added to the cell state. It regulates the inflow of new data.
- Forget Gate: The forget gate decides what information should be discarded or removed from the cell state. It manages the memory by removing irrelevant or outdated information.
- Output Gate: The output gate controls what information from the cell state should be outputted at the current time step. It filters and selects the information that is relevant to the output.
Don’t miss your chance to become a top-earning professional in AI! 🎯🚀
4. Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are unique deep learning models designed to generate synthetic, realistic data by pitting two neural networks against each other in a competitive learning process. GANs have achieved remarkable success in creating highly realistic images, videos, and even audio, finding applications in art, entertainment, and data augmentation.
How GAN Models Work:
- Generator Network: The generator’s role is to create fake data instances from random noise. It attempts to produce synthetic data that is indistinguishable from real data, constantly learning to improve its output.
- Discriminator Network: The discriminator acts as a judge, evaluating the authenticity of data instances. It is trained to differentiate between real data from the dataset and fake data produced by the generator.
- Adversarial Training Process: The generator and discriminator networks are trained simultaneously in an adversarial, zero-sum game. The generator strives to fool the discriminator by generating increasingly realistic fake data, while the discriminator aims to become better at detecting counterfeit data. This competitive process drives both networks to improve, ultimately leading to the generator producing highly realistic synthetic data.
Secure Your Future in AI and ML
Advance your career with our intensive Post Graduate Program. Learn More Now
5. Transformer Networks
Transformer networks have become the cornerstone of modern Natural Language Processing (NLP) models. They process input data using a self-attention mechanism, which allows for parallelization and significantly enhances the handling of long-range dependencies in sequences. This architecture has revolutionized tasks like machine translation, text summarization, and question answering.
How Transformer Models Work:
- Self-Attention Mechanism: This is the core innovation of Transformers. Self-attention allows the model to weigh the importance of each part of the input sequence relative to all other parts. For example, in a sentence, it enables the model to understand the relationships between words, regardless of their position, by calculating an attention score for each word pair. This mechanism is crucial for capturing context and dependencies within sequences.
- Positional Encoding: Since self-attention is order-agnostic and doesn’t inherently capture the sequence order, positional encoding is used. This technique adds information about the position of words in the sequence directly into the input embeddings. Positional encodings ensure that the model is aware of the order of words, which is vital for understanding language.
- Encoder-Decoder Architecture: Transformers typically follow an encoder-decoder structure. The encoder processes the input sequence and converts it into a rich representation. The decoder then uses this representation to generate the output sequence, step by step. Both the encoder and decoder are composed of multiple layers of self-attention and feed-forward networks, allowing for deep and complex processing of language.
6. Autoencoders
Autoencoders are unsupervised learning models primarily used for tasks like data compression, noise reduction (denoising), and feature learning. They operate by learning to encode input data into a lower-dimensional, compressed representation (latent space) and then decode it back to reconstruct the original data.
How Autoencoder Models Work:
- Encoder: The encoder network takes the input data and maps it into a lower-dimensional latent space representation. This compressed representation captures the most salient features of the input data.
- Latent Space: This is the compressed, lower-dimensional representation of the input data learned by the encoder. It ideally contains the most important information needed to reconstruct the original input.
- Decoder: The decoder network takes the latent space representation as input and attempts to reconstruct the original input data from it.
- Training for Reconstruction: Autoencoders are trained by minimizing the reconstruction error—the difference between the original input data and the reconstructed output. By forcing the network to compress and then decompress the data, the autoencoder learns efficient representations of the input data.
7. Deep Belief Networks (DBNs)
Deep Belief Networks (DBNs) are generative deep learning models composed of multiple layers of stochastic, latent variables. They are particularly useful for unsupervised learning tasks, such as feature extraction and dimensionality reduction. DBNs can learn complex probabilistic relationships in data.
How DBN Models Work:
- Layer-by-Layer Training: DBNs are trained using a greedy, layer-by-layer approach. Each layer is trained independently as a Restricted Boltzmann Machine (RBM). An RBM is a generative stochastic neural network that learns to probabilistically reconstruct its inputs. This unsupervised pre-training helps initialize the network weights in a good region of the parameter space.
- Fine-Tuning with Backpropagation: After pre-training each layer as an RBM, the entire DBN can be fine-tuned for specific tasks using backpropagation. This supervised fine-tuning refines the learned features and adapts the network for tasks like classification or regression.
Become an AI Engineer in Just 11 Months
Launch your AI career with our top-tier AI Program. Explore Program
8. Deep Q-Networks (DQNs)
Deep Q-Networks (DQNs) represent a significant advancement in reinforcement learning, combining deep learning with Q-learning. DQNs are designed to handle complex environments with high-dimensional state spaces, making them suitable for tasks like playing video games and controlling robots, where traditional Q-learning struggles due to the vast state space.
How DQN Models Work:
- Q-Learning Foundation: DQN builds upon Q-learning, a model-free reinforcement learning algorithm. Q-learning traditionally uses a Q-table to store and update Q-values, which represent the expected reward for taking a particular action in a given state.
- Deep Neural Network for Q-Value Approximation: In DQNs, the Q-table is replaced by a deep neural network. This neural network approximates the Q-values for different actions given a state. The network takes the state as input and outputs the estimated Q-values for each possible action. This function approximation allows DQNs to handle continuous and high-dimensional state spaces, which are infeasible for traditional Q-tables.
- Experience Replay: To stabilize training and break correlations between consecutive experiences, DQNs use experience replay. This technique stores past experiences (state, action, reward, next state) in a replay buffer. During training, a batch of experiences is randomly sampled from this buffer to update the Q-network. Randomizing the experiences helps to reduce variance and improve learning stability.
- Target Network for Stability: DQNs employ a separate target network to further stabilize training. The target network is a copy of the Q-network but with delayed updates. Q-values used for calculating the training target are predicted by this target network. Periodically, the target network is updated with the weights of the online Q-network. This separation prevents oscillations and divergence that can occur when the target Q-values are updated too frequently.
9. Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are generative models that utilize variational inference to learn the underlying probability distribution of the training data. This enables VAEs to generate new data points that are similar to the training data. They are widely used for generative tasks and anomaly detection, offering a probabilistic approach to data generation and representation learning.
How VAE Models Work:
- Encoder for Probabilistic Latent Space: Unlike traditional autoencoders that map inputs to a fixed latent vector, VAE encoders map inputs to a probability distribution in the latent space. Typically, this distribution is assumed to be a Gaussian distribution. The encoder outputs the parameters of this distribution (mean and variance).
- Latent Space Sampling: To introduce variability and generative capability, VAEs sample from the latent space distribution learned by the encoder. By sampling from this distribution, the model can generate slightly different latent vectors for similar inputs, leading to diverse outputs.
- Decoder for Data Generation: The decoder network takes the sampled latent vector as input and generates data points in the original data space. It learns to map points in the latent space back to meaningful data samples.
- Combined Loss Function: VAE training combines two loss terms: reconstruction loss and a regularization term. The reconstruction loss ensures that the decoder can accurately reconstruct the input from the latent representation. The regularization term, typically Kullback-Leibler divergence, encourages the latent space distribution to be close to a prior distribution, often a standard normal distribution. This regularization is crucial for ensuring a well-structured and continuous latent space, which is essential for generating meaningful new data points.
10. Graph Neural Networks (GNNs)
Graph Neural Networks (GNNs) extend the principles of neural networks to data structured as graphs. Graphs are powerful data structures for representing relationships between entities, making GNNs highly applicable in domains like social network analysis, molecular structure analysis, and recommendation systems.
How GNN Models Work:
- Graph Representation: GNNs operate on graph data, where data is represented as nodes (entities) and edges (relationships between entities). Each node and edge can have associated features.
- Message Passing (Neighborhood Aggregation): The core operation in GNNs is message passing or neighborhood aggregation. In this process, each node aggregates information from its neighbors (nodes directly connected to it) to update its own representation. This aggregation is typically done through a neural network layer.
- Iterative Information Propagation: Message passing is often repeated for several iterations (layers). In each iteration, nodes gather information from increasingly distant neighbors, allowing information to propagate across the graph. This iterative process enables nodes to incorporate broader contextual information from the graph structure.
- Readout Function for Graph-Level Tasks: For tasks that require a graph-level prediction (e.g., graph classification or regression), a readout function is used. This function aggregates the representations of all nodes in the graph, typically at the end of several message-passing iterations, to produce a single graph-level representation. This representation is then used for making predictions about the entire graph.
Become the Leading AI Engineer!
Elevate your career with our cutting-edge AI Engineer Master Program. Know More
Conclusion: The Future of Deep Learning Models in 2024 and Beyond
As we progress through 2024, deep learning models continue to advance, pushing the boundaries of machine capabilities. From CNNs’ image recognition to Transformer Networks’ NLP prowess, these top 10 deep learning algorithms are at the forefront of technological innovation. Whether your focus is natural language processing, generative models, or reinforcement learning, these algorithms provide potent tools for tackling intricate problems across diverse fields.
To remain competitive in this rapidly evolving domain, continuous learning and skill enhancement are paramount. The Caltech Post Graduate Program in AI and Machine Learning offers an exceptional opportunity to deepen your knowledge and expertise. This comprehensive program provides in-depth knowledge and practical experience with the latest AI and machine learning technologies, guided by experts from a leading global institution. Explore these programs to accelerate your career in AI!
| Foundational Program 📚 | Recommended Program ✍️ | Trending Program 📈 |
|---|---|---|
| > Explore Now | > Explore Now | > Explore Now |

Frequently Asked Questions (FAQs) about Deep Learning Models
Q1. Which Deep Learning Algorithm is Considered the Most Versatile?
Multilayer Perceptrons (MLPs) are often cited as a highly versatile deep learning algorithm. As one of the earliest techniques, MLPs are still widely used across various applications, including social media platforms like Instagram and Meta for image loading in low-bandwidth conditions, data compression, and speed and image recognition tasks.
Q2. Can You Provide Examples of Deep Learning Algorithms?
The landscape of deep learning algorithms is rich and diverse, including Radial Basis Function Networks, Multilayer Perceptrons, Self-Organizing Maps, and Convolutional Neural Networks, among many others. These algorithms often draw inspiration from the functional architecture of neurons in the human brain.
Q3. Is a Convolutional Neural Network (CNN) Classified as a Deep Learning Algorithm?
Yes, CNNs are unequivocally deep learning algorithms. They are specifically designed to process image data, inspired by the animal visual cortex, interpreting images as grid-like patterns. CNNs excel at tasks like automated object detection and image segmentation, learning hierarchical spatial features from basic to complex patterns.
Q4. What are the Fundamental Layers in a Typical Deep Learning Model?
A standard three-layer neural network comprises an input layer, one or more hidden layers, and an output layer. Data enters through the input layer, undergoes processing and computation in the hidden layer(s), and the results are presented in the output layer. The hidden layers are responsible for performing the complex, ‘hidden’ computations that enable the network to learn intricate patterns.
Q5. How Does a Deep Learning Model Achieve Learning?
Deep learning models learn through a process of training on labeled datasets using neural network architectures with multiple layers. These models have demonstrated the capacity to surpass human-level performance in certain tasks. A key advantage is their ability to automatically learn features directly from raw data, eliminating the need for manual feature extraction.
Q6. What Are Recommended Deep Learning Algorithms for Beginners and Professionals Alike?
For both newcomers and experienced practitioners in deep learning, Convolutional Neural Networks (CNNs), Long Short-Term Memory Networks (LSTMs), and Recurrent Neural Networks (RNNs) are highly recommended. These algorithms are foundational and powerful, capable of addressing complex problems across a wide range of deep learning applications.
