Deep Residual Learning has emerged as a groundbreaking technique in the field of computer vision, specifically for image recognition tasks. This approach, introduced in the seminal paper “Deep Residual Learning For Image Recognition,” tackles a fundamental challenge in training very deep neural networks, paving the way for unprecedented accuracy in image classification, object detection, and beyond.
Understanding Deep Residual Learning
The core idea behind deep residual learning lies in the concept of “residual blocks.” Traditional deep neural networks learn direct mappings from input to output. However, as networks become deeper, they become increasingly difficult to train, often suffering from the vanishing gradient problem. This problem hinders learning because gradients become extremely small as they are backpropagated through many layers, effectively stopping the training process in the earlier layers.
Residual networks, or ResNets, circumvent this issue by learning residual mappings instead. Instead of trying to learn a complex mapping directly, each residual block learns a “residual” function with reference to the input of that block. This is achieved through “skip connections” or “identity shortcuts.”
A residual block essentially consists of a few convolutional layers followed by a skip connection that adds the input of the block to the output of the convolutional layers. Mathematically, if we denote the desired underlying mapping as H(x), a residual block does not directly learn H(x). Instead, it learns a residual function F(x) = H(x) – x. The original mapping is then recast as F(x) + x. The skip connection performs the identity mapping ‘x’, and the network learns the residual F(x).
This formulation is crucial because it suggests that it is easier to learn residual mappings than to learn the original, unreferenced mappings. In the case where identity mapping is optimal, it is easier to push the residuals to zero than to learn an identity mapping by a stack of nonlinear layers.
The Architecture of ResNet
The original ResNet paper introduced several deep network architectures, with depths ranging from 18 to 152 layers. These networks are built by stacking residual blocks. For instance, ResNet-50, ResNet-101, and ResNet-152, the models initially released by the authors, differ primarily in the number of residual blocks, leading to varying depths.
A typical ResNet architecture begins with a convolutional layer and a pooling layer, followed by a series of residual blocks grouped into stages. Within each stage, the residual blocks maintain the same output feature map size, and the number of filters is typically doubled for each subsequent stage. Finally, an average pooling layer and a fully connected layer with a softmax activation are used for classification.
The depth of ResNets, enabled by residual learning, is key to their success. Deeper networks can learn more complex and hierarchical features, leading to improved performance on complex tasks like image recognition.
Performance and Impact
ResNet models achieved state-of-the-art results on various challenging benchmarks, including ImageNet, COCO object detection, and COCO segmentation. Their breakthrough performance in the 2015 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) and COCO competitions marked a significant milestone in computer vision.
Here are the 1-crop validation error rates on ImageNet, demonstrating the effectiveness of ResNet compared to previous models like VGG-16:
| Model | Top-1 Error | Top-5 Error |
|---|---|---|
| VGG-16 | 28.5% | 9.9% |
| ResNet-50 | 24.7% | 7.8% |
| ResNet-101 | 23.6% | 7.1% |
| ResNet-152 | 23.0% | 6.7% |
These results clearly show the superior performance of ResNet architectures, especially as depth increases. The significantly lower error rates demonstrated ResNet’s ability to learn more effective representations from images.
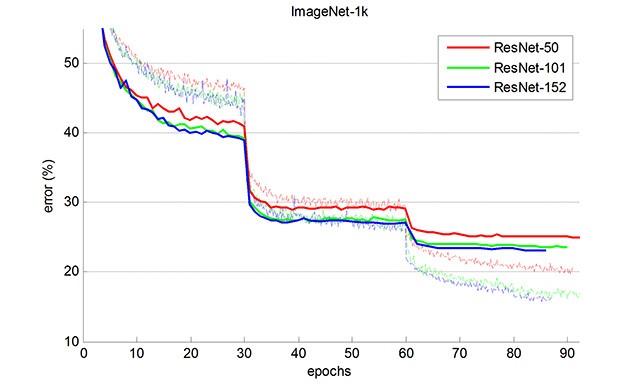
 Training curves
Training curvesImage showing training curves of ResNet models, illustrating the relationship between network depth and performance in image recognition.
Applications Beyond Image Classification
While initially demonstrated for image classification, the principles of deep residual learning have proven to be broadly applicable across various computer vision tasks. ResNet architectures or their variants are now widely used in:
- Object Detection: Frameworks like Faster R-CNN and Mask R-CNN commonly employ ResNet backbones to extract robust image features for object detection and instance segmentation.
- Semantic Segmentation: ResNets are integrated into semantic segmentation models to achieve pixel-level image understanding.
- Other Vision Tasks: The benefits of residual learning extend to other areas like image generation, video analysis, and even non-vision tasks where deep networks are applicable.
Conclusion
Deep residual learning has fundamentally changed the landscape of deep learning for image recognition. By addressing the challenges of training very deep networks, ResNet architectures have enabled the development of significantly more accurate and powerful computer vision systems. The simplicity and effectiveness of residual blocks have made ResNets a foundational architecture in the field, inspiring countless subsequent research and applications. The original models and the core concepts continue to be highly influential, serving as a cornerstone for modern deep learning practices in image recognition and beyond.
Citation
If you utilize ResNet models in your research, please cite the original paper:
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}