Self Supervised Learning (SSL) is transforming the landscape of artificial intelligence, offering innovative solutions to overcome the limitations of traditional supervised learning methods. At learns.edu.vn, we believe understanding this technique is crucial for anyone interested in the future of AI. This comprehensive guide explores the mechanics, applications, and benefits of SSL, empowering you with the knowledge to navigate this exciting field and unlock your full learning potential with enhanced educational methodologies. Dive in to discover how SSL is revolutionizing machine learning and how you can leverage its power!
1. Understanding Self-Supervised Learning Algorithms
Self-Supervised Learning (SSL) is an advanced machine learning technique that tackles the challenges of relying too heavily on labeled data. Historically, creating intelligent systems with machine learning has hinged on the availability of high-quality labeled data. However, the expense of annotating data is a significant hurdle in training these systems.
AI researchers are focusing on building self-learning mechanisms using unstructured data. These systems aim to reduce the cost of developing general AI. Collecting and labeling all types of data is practically impossible, driving the need for SSL techniques.
Researchers are now developing self-supervised learning (SSL) techniques that can detect subtle patterns in data. This approach allows models to learn from the data itself, reducing the need for manual labeling.
Before we explore self-supervised learning, let’s review the foundational learning methods used in building intelligent systems. These methods provide a context for understanding the innovative approach of SSL and its potential impact on various fields.
1.1 Supervised Learning
Supervised learning trains neural networks on labeled data for specific tasks. It’s like a student learning from a teacher with many examples, such as object classification. The model learns to map inputs to outputs based on the provided labels. This method is effective when labeled data is abundant and accurate. However, obtaining and maintaining such data can be costly and time-consuming.
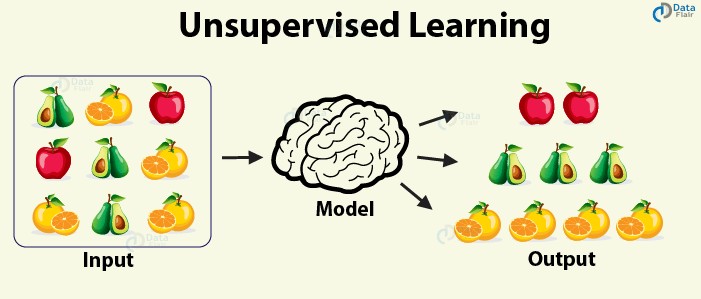
1.2 Unsupervised Learning
Unsupervised learning discovers implicit patterns in data without explicit training on labeled data. Unlike supervised learning, it doesn’t require annotations or feedback loops. Clustering is a common application. This approach is useful for exploring data and identifying hidden structures. However, it can be challenging to interpret the results and apply them to specific tasks.
1.3 Semi-Supervised Learning
Semi-supervised learning uses a combination of labeled and unlabeled data. Only a portion of the input data is labeled with the output. This method blends supervised and unsupervised learning. Semi-supervised learning is valuable when only a small amount of labeled data is available. The training process uses the labeled data and pseudo-labels the rest of the dataset. It’s like a student learning from a teacher with a few problems and then solving the rest on their own.
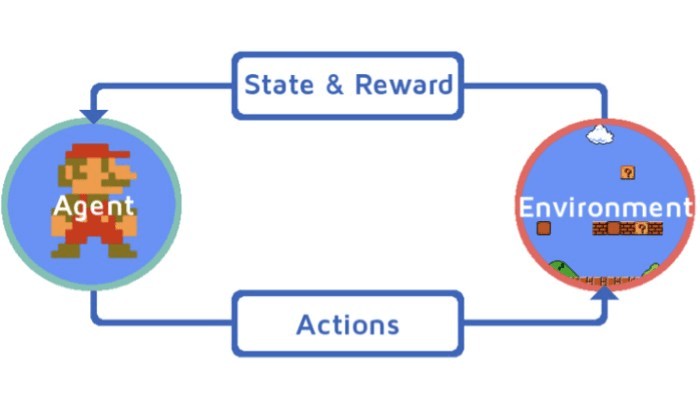
1.4 Reinforcement Learning
Reinforcement learning trains AI agents to learn environment behavior using reward feedback policies. Think of it as a child trying to win a game. The agent learns through trial and error, optimizing its actions to maximize rewards. This method is effective in dynamic environments where the agent must make decisions over time. However, it can be challenging to design the reward function and ensure the agent learns the desired behavior.
2. Delving into Self-Supervised Learning (SSL)
Self-supervised learning is a machine learning process where the model learns to predict one part of the input from another. It’s also known as predictive or pretext learning. This transforms an unsupervised problem into a supervised one by automatically generating labels. Setting the right learning objectives is crucial to leverage the vast amount of unlabeled data.
The self-supervised learning method identifies any hidden part of the input from any unhidden part. For example, in natural language processing, SSL can complete a sentence given a few words. Similarly, in video, it can predict future frames based on available data. Self-supervised learning uses the structure of the data to leverage supervisory signals across large datasets without relying on manual labels.
3. Key Differences Between Self-Supervised and Unsupervised Learning
People often confuse self-supervised and unsupervised learning, using the terms interchangeably. However, these techniques have distinct objectives. Both methods do not require labeled datasets, but self-supervised learning has many supervisory signals that act as feedback in the training process, unlike unsupervised learning, which lacks feedback loops.
Unsupervised learning focuses on the model, while self-supervised learning focuses on the data. Unsupervised learning excels at clustering and dimensionality reduction, while self-supervised learning is a pretext method for regression and classification tasks.
| Feature | Self-Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Labeling | Does not require labeled data | Does not require labeled data |
| Feedback Loop | Uses supervisory signals as feedback | No feedback loops |
| Focus | Data | Model |
| Applications | Regression, classification | Clustering, dimensionality reduction |




4. The Necessity of Self-Supervised Learning
Self Supervised Learning addresses persistent issues in other learning procedures:
- High Cost: Most learning methods require labeled data, which is expensive in terms of time and money.
- Lengthy Lifecycle: The data preparation lifecycle is lengthy, involving cleaning, filtering, annotating, reviewing, and restructuring.
- Generic AI: Self-supervised learning moves closer to embedding human cognition in machines.
Now, let’s explore the utility of self-supervised learning in different domains.
4.1 Cost Reduction with Unlabeled Data
Traditional machine learning models often demand vast quantities of labeled data, a process that can be incredibly costly. Labeling data requires human expertise, which can be time-intensive and expensive. Self-supervised learning eliminates this need, as it can learn directly from unlabeled data. This is particularly beneficial in fields where labeled data is scarce or difficult to obtain, such as medical imaging or rare language processing.
Example:
Imagine training a model to identify different types of skin diseases. Gathering and labeling a comprehensive dataset of skin images would require dermatologists to manually annotate each image, which is both time-consuming and expensive. With self-supervised learning, the model can learn from a large collection of unlabeled skin images by predicting one part of the image from another, reducing the need for costly manual annotation.
4.2 Efficient Data Preparation
The process of preparing data for machine learning models is often lengthy and complex. It involves cleaning, filtering, annotating, reviewing, and restructuring the data. Self-supervised learning simplifies this process by reducing the need for manual annotation. This not only saves time but also reduces the risk of human error.
Example:
Consider training a model to understand customer sentiment from social media posts. Traditional approaches would require manually labeling each post as positive, negative, or neutral. This process can be time-consuming and subjective. With self-supervised learning, the model can learn from unlabeled social media posts by predicting masked words or phrases, reducing the need for manual labeling and streamlining the data preparation process.
4.3 Enabling Generic AI
One of the ultimate goals of AI research is to create systems that can perform a wide range of tasks, much like humans. Self-supervised learning is a significant step toward this goal, as it allows models to learn general representations of the world from unlabeled data. These representations can then be fine-tuned for specific tasks, making the models more adaptable and versatile.
Example:
Imagine training a model to understand both images and text. Traditional approaches would require separate models for each modality. With self-supervised learning, a single model can learn from both unlabeled images and text by predicting masked regions or words. This unified representation allows the model to perform tasks that involve both modalities, such as image captioning or visual question answering.
5. Self-Supervised Learning Applications in Computer Vision
Computer vision learning methods have focused on perfecting model architecture, assuming high-quality data is available. However, obtaining good quality image data is difficult and expensive, leading to sub-optimal trained models.
Research has focused on developing self-supervised methods in computer vision across different applications. Training models with unlabeled data speeds up the overall training process and allows the model to learn underlying semantic features without label bias.
Training a self-supervised model involves two main stages:
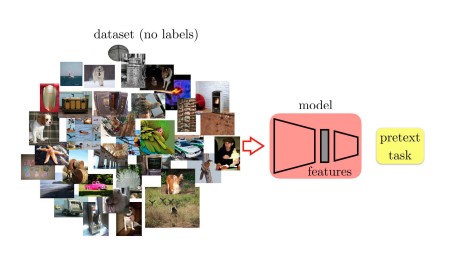
5.1 Pretext Task
The pretext task is used for pre-training. The aim of the pretext task (also known as a supervised task) is to guide the model to learn intermediate representations of data. This is useful for understanding the underlying structural meaning that benefits practical downstream tasks.
Generative models can be considered self-supervised models but with different objectives. For example, GANs generate realistic images for the discriminator, while self-supervised training identifies good features for various tasks.
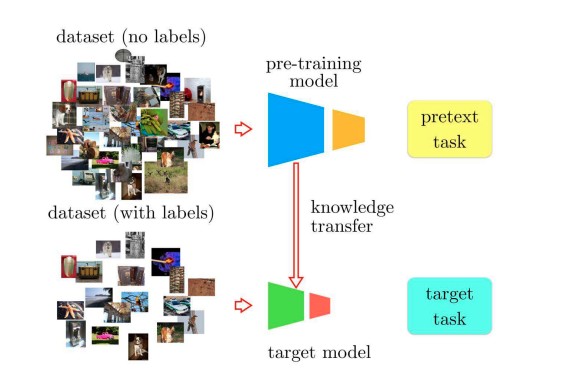
5.2 Downstream Tasks
The downstream task is the knowledge transfer process of the pretext model to a specific task. Downstream tasks receive less labeled data. These tasks, also known as target tasks in the visual domain, include object recognition, object classification, and object reidentification, and are fine-tuned on the pretext model.
Researchers have proposed many ideas for different image-based tasks to train using the SSL method.
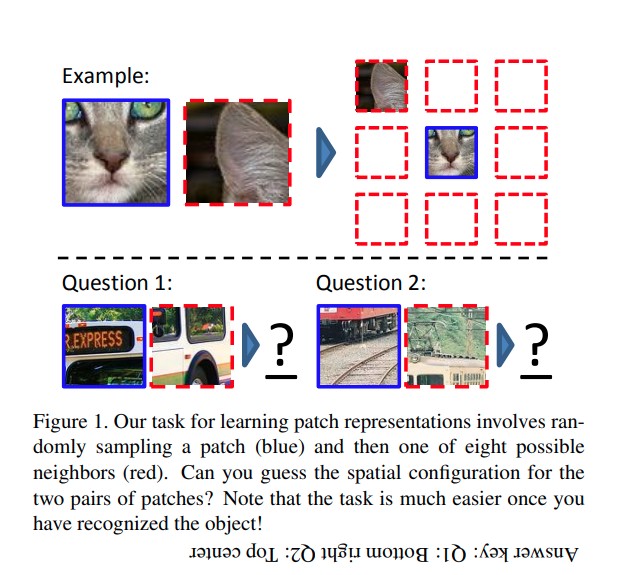
5.3 Patch Localization
Objective: Identify the relationship between different image patches using self-supervised learning.
Training Algorithm:
- Sample a random patch from the image.
- Nearest Neighbor: Place the first patch in the middle of a 3×3 grid and sample the second patch from its 8 neighboring locations.
- Introduce augmentations such as gaps between patches, chromatic aberration, downsampling, and upsampling to handle pixelation and color jitters. This prevents the model from overfitting low-level signals.
- Identify which of the 8 neighboring positions is the second patch, framing the task as a classification problem over 8 classes.
It is important to ensure the pretext task doesn’t learn trivial patterns compared to high-level latent features. Low-level cues like boundary textures between patches can be trivial features. However, some images have a trivial solution due to chromatic aberration. Convolutional neural networks can learn the relative location of the patches by detecting the difference between magenta (blue+red) and green. Nearest-neighbor experiments showed that few patches retrieved regions from the absolute same location because patches displayed similar aberration.
5.4 Context-Aware Pixel Prediction
Objective: Predict the pixel values of an unknown patch in the image based on the overall context of the image using encoder-decoders.
Training Algorithm:
- Train the pretext task using a vanilla encoder-decoder architecture.
- The encoder (Pathak, et al., 2016) produces a latent feature representation of the image using an input image with blacked-out regions.
- The decoder uses the latent feature representation from the encoder and estimates the missing image region using the reconstruction loss (MSE).
- The channel-wise fully-connected layer between encoder and decoder allows each unit in the decoder to reason about the entire image content.
5.4.1 Loss Function
The loss functions used in training were reconstruction and adversarial loss.
Reconstruction Loss
- Captures the salient features with respect to the context of the full image.
- Defined as the normalized masked distance of input image x.
- M: Binary mask corresponding to the removed image region with a value of 0 for input pixels and 1 when a pixel is not considered.
- F: The function resulting in an output of the encoder
Adversarial Loss
- Modeled to make the prediction look real and learn the latent space of the input data it is trained on.
- Only the generator G is conditioned against the input mask because the discriminator D is able to exploit the perpetual discontinuity in the patched regions and original context.
Joint Loss
- Developed using combining both reconstruction and adversarial losses.
- However, during experiments, the authors realized that inpainting works best with only adversarial loss.
Semantic inpainting is achieved using the SSL method through auxiliary supervision and learning of strong feature representations. Back in 2016, this paper was one of the early pioneers in using the SSL approach in training a competitive image model.
6. Self-Supervised Learning Applications in Natural Language Processing
SSL made huge strides in Natural Language Processing (NLP) before becoming mainstream in computer vision research. Language models were used almost everywhere, from document processing to text suggestion and sentence completion.
The learning capabilities of these models have evolved since the Word2Vec paper was published in 2013, revolutionizing the NLP space. Instead of predicting the next word, the model predicts the next word based on prior context, enabling meaningful representation through the distribution of word embeddings.
Today, one of the most popular SSL methods used in NLP is BERT. In the past decade, there has been amazing research and development in NLP. Let’s distill some of the important ones below.
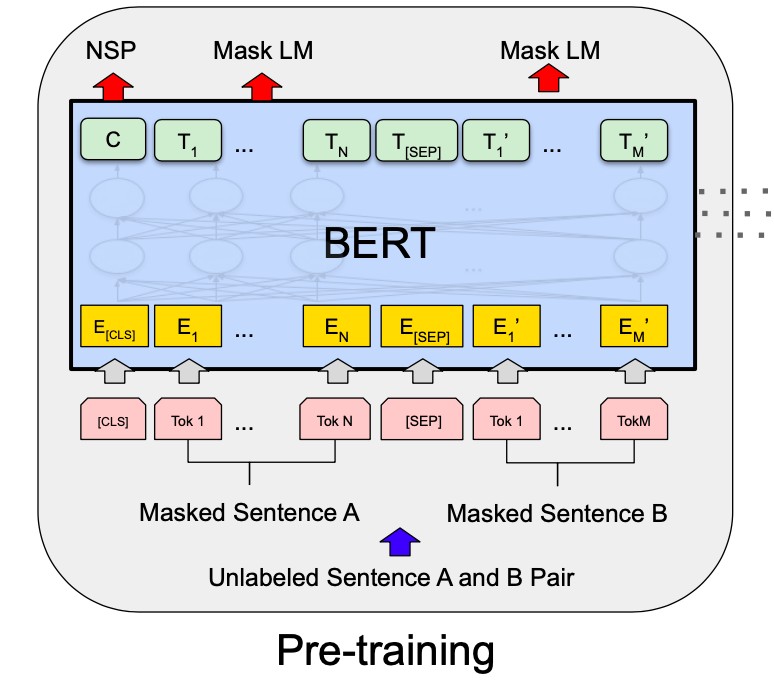
6.1 Next Sentence Prediction
In Next Sentence Prediction (NSP), we select two simultaneous sentences from a document and a random sentence from the same or a different document, say sentence A, sentence B, and sentence C. The model then determines the relative position of sentence A with respect to sentence B, outputting either IsNextSentence or IsNotNextSentence for all combinations.
Consider the following scenario:
- After completing the school hours, Mike went home.
- After almost 50 years, the manned mission to Moon is finally underway.
- Once home, Mike watched Netflix to relax.
A person would likely reorder the sentences to fit a logical understanding, such as sentence 1 followed by sentence 3. The main objective of the model is to predict sentences based on long-term contextual dependencies.
Bidirectional Encoder Representations from Transformers (BERT), published by Google AI, has become a gold standard for NLP tasks like Natural Language Inference (MNLI) and Question Answering (SQuAD). BERT captures the relationship between sentences, which is not possible through other language modeling techniques. Here’s how it works for Next Sentence Prediction.
- To enable BERT to handle various downstream tasks, the input representation can unambiguously represent a pair of sentences packed together in a single sequence. A “sequence” refers to the input token sequence to BERT.
- The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.
- The sentences are differentiated in two ways: separated with a special token ([SEP]) and by adding a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
- Input embedding is denoted as E, the final hidden vector of the special [CLS] token as C, and the final hidden vector for the ith input token as Ti. Vector C is used for Next Sentence Prediction (NSP).
This task can be understood from the following example:
You can utilize the BERT Model for this task by referring to Hugging Face documentation.
6.2 Auto-Regressive Language Modeling
While autoencoding models like BERT use self-supervised learning for tasks like sentence classification (next or not), another application of self-supervised approaches lies in text generation. Autoregressive models like GPT (Generative Pre-trained Transformer) are pre-trained on the classic language modeling task: predict the next word having read all the previous ones. These models correspond to the decoder part of the transformer, and a mask is used on top of the full sentence so that the attention heads can only see what was before in the text, not what’s after.
Let’s examine how these models work by looking at the training framework of GPT. The training procedure consists of two stages:
- Unsupervised Pre-training
The first stage is learning a high-capacity language model on a large corpus of text. Given an unsupervised corpus of tokens U = {u1, . . . , un}, we use a standard language modeling objective to maximize the following likelihood:
where k is the size of the context window, and the conditional probability P is modeled using a neural network with parameters Θ. These parameters are trained using stochastic gradient descent.
The model being trained here is a multi-layer transformer decoder for the language model, which is a variant of the transformer. This model applies a multi-headed self-attention operation over the input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:
where U = (u−k, . . . , u−1) is the context vector of tokens, n is the number of layers, We is the token embedding matrix, and Wp is the position embedding matrix. This constrained self-attention, where every token can attend to the context to its left, brings the self-supervised approach into the picture.
- Supervised Fine-tuning
In this step, we assume a labeled dataset C, where each instance consists of a sequence of input tokens, x1 , . . . , xm, along with a label y. The inputs are passed through our pre-trained model to obtain the final transformer block’s activation hml, which is then fed into an added linear output layer with parameters Wy to predict y:
This gives us the following objective to maximize:
Including language modeling as an auxiliary objective to the fine-tuning helped learning by improving generalization of the supervised model and accelerating convergence. Specifically, we optimize the following objective (with weight λ):
Overall, the only extra parameters we require during fine-tuning are Wy and embeddings for delimiter tokens.
(left) Transformer architecture and training objectives used in this work (right) Input transformations for fine-tuning on different tasks | Source
The left side of the image shows the Transformer architecture and training objectives, and the right side shows the Input transformations for fine-tuning on different tasks. We convert all structured inputs into token sequences to be processed by our pre-trained model, followed by a linear+softmax layer. Different processing is required for different tasks. For Textual Entailment, we concatenate the premise (p), the entailing text and hypothesis (h), the entailed text, token sequences, with a delimiter token ($) in between.
There have been many iterations of improvements over the original GPT model, and you can refer to this page to understand how you can use it for your own use cases.
7. Self-Supervised Learning Applications: Industrial Case Studies
We’ve discussed how popular models have been trained using self-supervised approaches and how you can train one yourself or use one from available libraries. Now, let’s examine how the industry is leveraging this technique to solve critical problems.
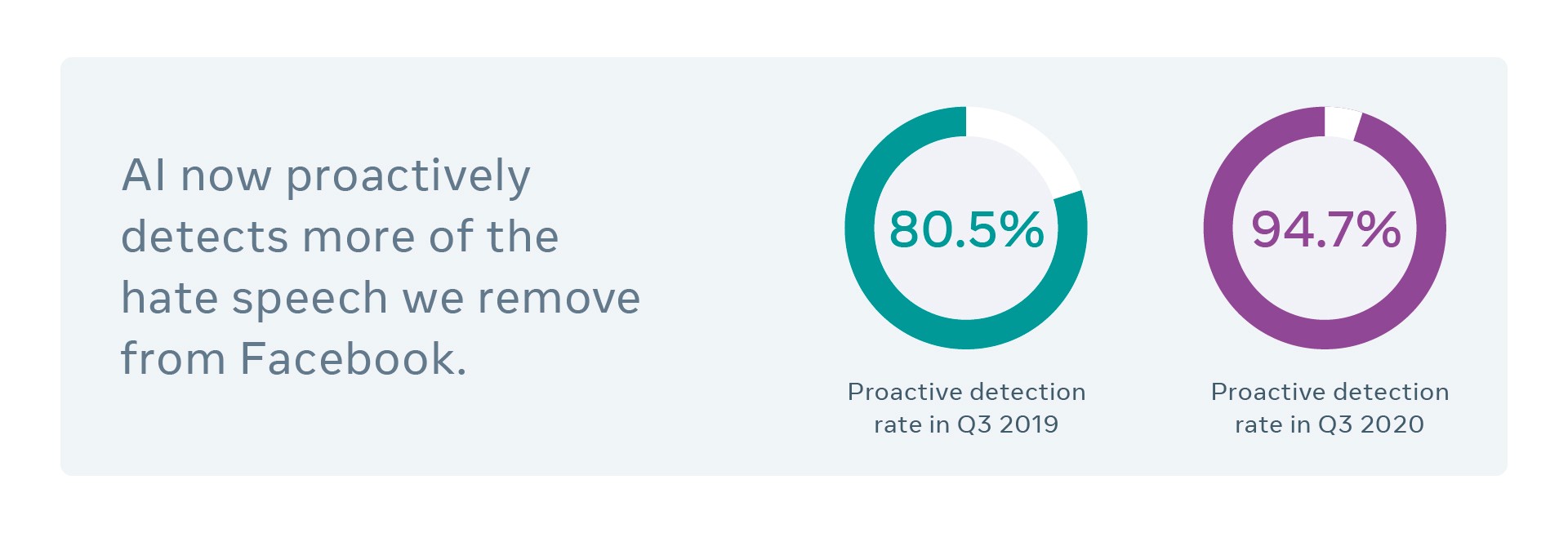
7.1 Hate-Speech Detection at Facebook
“We believe that self-supervised learning (SSL) is one of the most promising ways to build background knowledge and approximate a form of common sense in AI systems.”
AI Scientists, Facebook
Facebook is advancing self-supervised learning techniques across many domains through fundamental, open scientific research. They are also applying this work in production to improve the accuracy of content understanding systems, ensuring safety on their platforms.
One example is XLM, Facebook AI’s method of training language systems across multiple languages without relying on hand-labeled datasets to improve hate speech detection.
This application of self-supervised learning has made their models more robust and their platforms safer. Let’s briefly discuss what XLM is and how it has made such a difference.
7.1.1 XLM
The Model
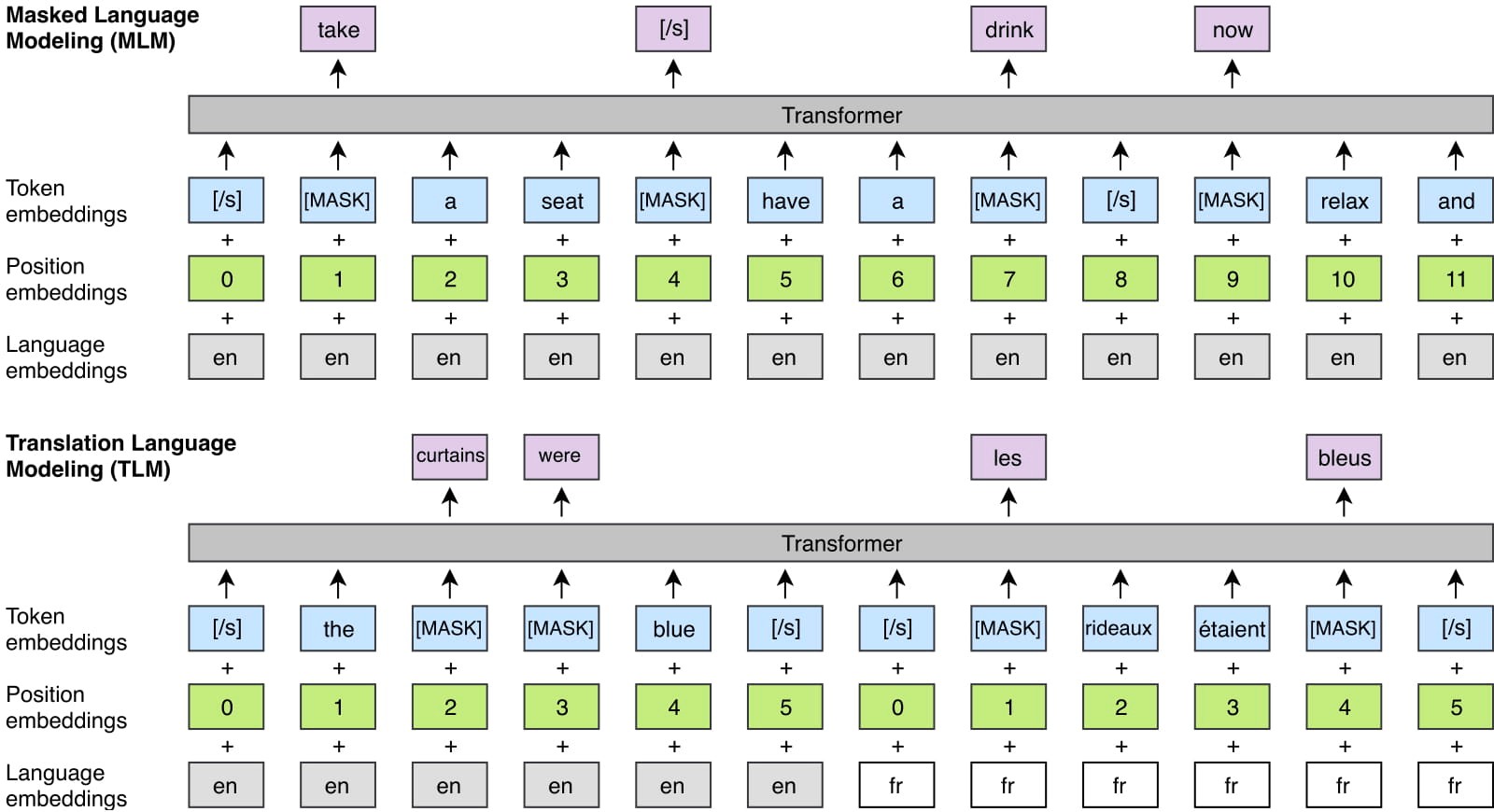
XLM is a Transformers-based architecture that is pre-trained using one of three language-modeling objectives:
- Casual Language Modeling (CLM): To model the probability of a word given the previous words in a sentence, i.e., P(wt |w1, . . . , wt−1, θ).
- Masked Language Modeling (MLM): The masked language modeling objective of BERT, i.e., masking randomly chosen tokens with [MASK] keyword and trying to predict them.
- Translation Language Modeling (TLM): A new addition and an extension of MLM, where instead of considering monolingual text streams, parallel sentences are concatenated. Words in both the source and target sentences are masked. To predict a word masked in an English sentence, the model can attend to surrounding English words or the French translation, encouraging the model to align the English and French representations. The model can also leverage the French context if the English one is not sufficient to infer the masked English words.
XLM is a cross-lingual language model whose pretraining can be done with either CLM, MLM, or MLM used in combination with TLM. Let’s examine the benefits that XLM brings.
Performance Analysis
- Cross-lingual Classification
XLM provides a better initialization of sentence encoders for zero-shot cross-lingual classification and achieved State-of-the-Art (SOTA) performance by obtaining 71.5% accuracy through the MLM method. Combining MLM and TLM improves the performance even further to 75.1%.
- Machine Translation Systems
It provides a better initialization of supervised and unsupervised neural machine translation systems. Pre-training with the MLM objective showed significant improvements in the case of unsupervised systems, while the same objective led to SOTA performance in supervised systems with a BLEU score of 38.5.
- Language Models for Low-Resource Languages
For low-resource languages, it is often beneficial to leverage data in similar but higher-resource languages, especially when they share a significant fraction of their vocabularies. XLM improved the Nepali language model (a low-resource language) by utilizing information from Hindi (a relatively popular one with considerable resources) as they share the same Devnagari script.
- Unsupervised Cross-lingual Word Embeddings
XLM outperformed previous works on cross-lingual word embeddings by reaching a SOTA level Pearson correlation score of 0.69 between source words and their translation.
With these advancements, XLM has made a significant difference in Natural Language Processing.
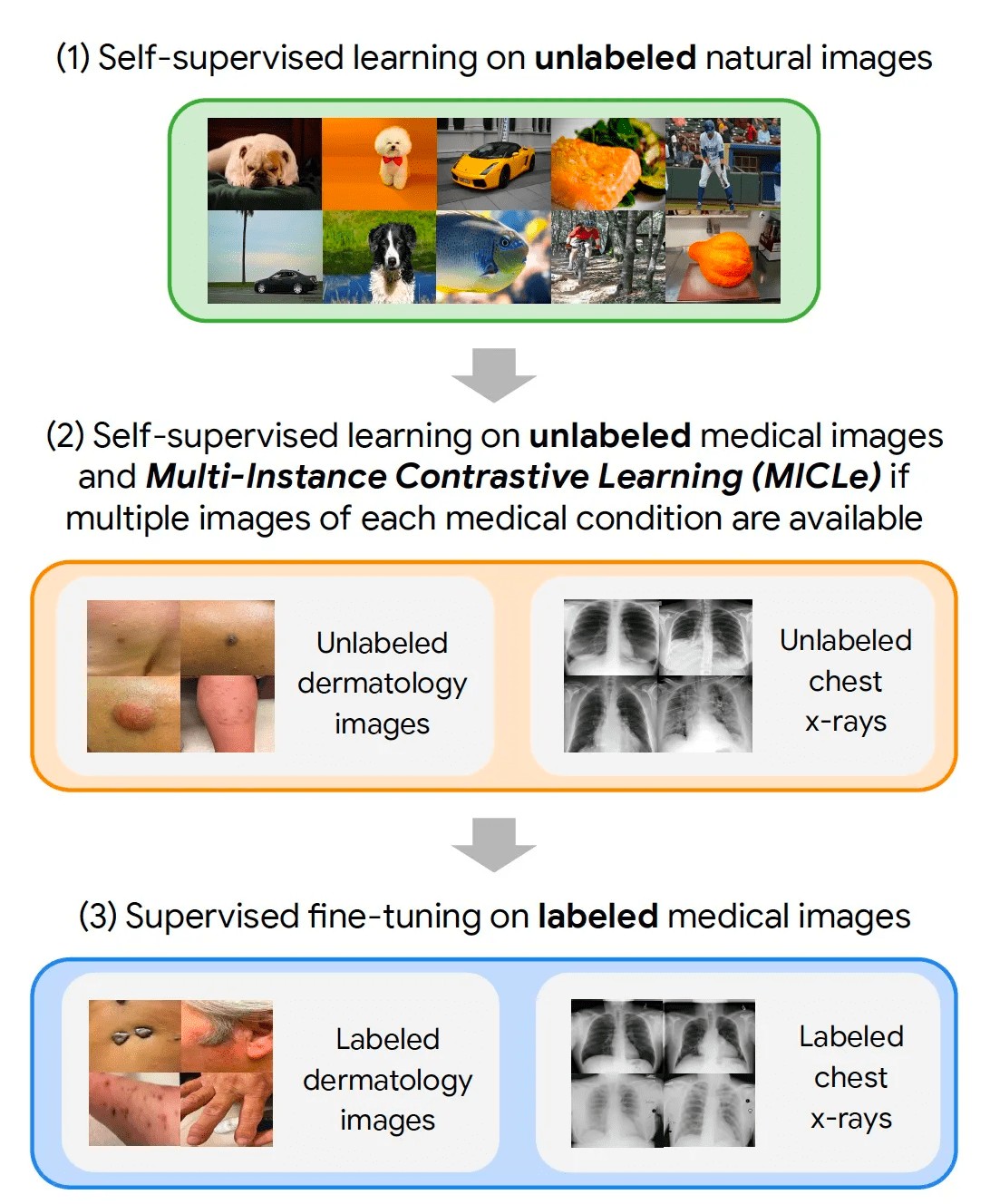
7.2 Google’s Medical Imaging Analysis Model
In the medical domain, training deep learning models has always been difficult due to limited labeled data and the time-consuming and expensive nature of annotating such data. To tackle this problem, Google’s Research Team introduced a novel Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case to construct more informative positive pairs for self-supervised learning.
Key points about the illustrated approach:
- Step 1 is carried out using SimCLR, another framework designed by Google for self-supervised representation learning on images.
- Steps 2 and 3 are task and dataset-specific.
Let’s break it down step by step.
7.2.1 Step 1: The SimCLR Framework
SimCLR stands for A Simple Framework for Contrastive Learning of Visual Representations, and it significantly advances the state of the art on self-supervised and semi-supervised learning, achieving a new record for image classification with a limited amount of class-labeled data.
- SimCLR first learns generic representations of images on an unlabeled dataset, and then it can be fine-tuned with a small amount of labeled images to achieve good performance for a given classification task (like medical imaging).
- The generic representations are learned by simultaneously maximizing agreement between differently transformed views of the same image and minimizing agreement between transformed views of different images, following a method called contrastive learning. Updating the parameters of a neural network using this contrastive objective causes representations of corresponding views to “attract” each other, while representations of non-corresponding views “repel” each other.
- To begin, SimCLR randomly draws examples from the original dataset, transforming each example twice using a combination of simple augmentations, creating two sets of corresponding views.
- It then computes the image representation using a CNN, based on ResNet architecture.
- Finally, SimCLR computes a non-linear projection of the image representation using a fully-connected network (i.e., MLP), which amplifies the invariant features and maximizes the ability of the network to identify different transformations of the same image.
The trained model not only identifies different transformations of the same image but also learns representations of similar concepts (e.g., chairs vs. dogs), which can later be associated with labels through fine-tuning.
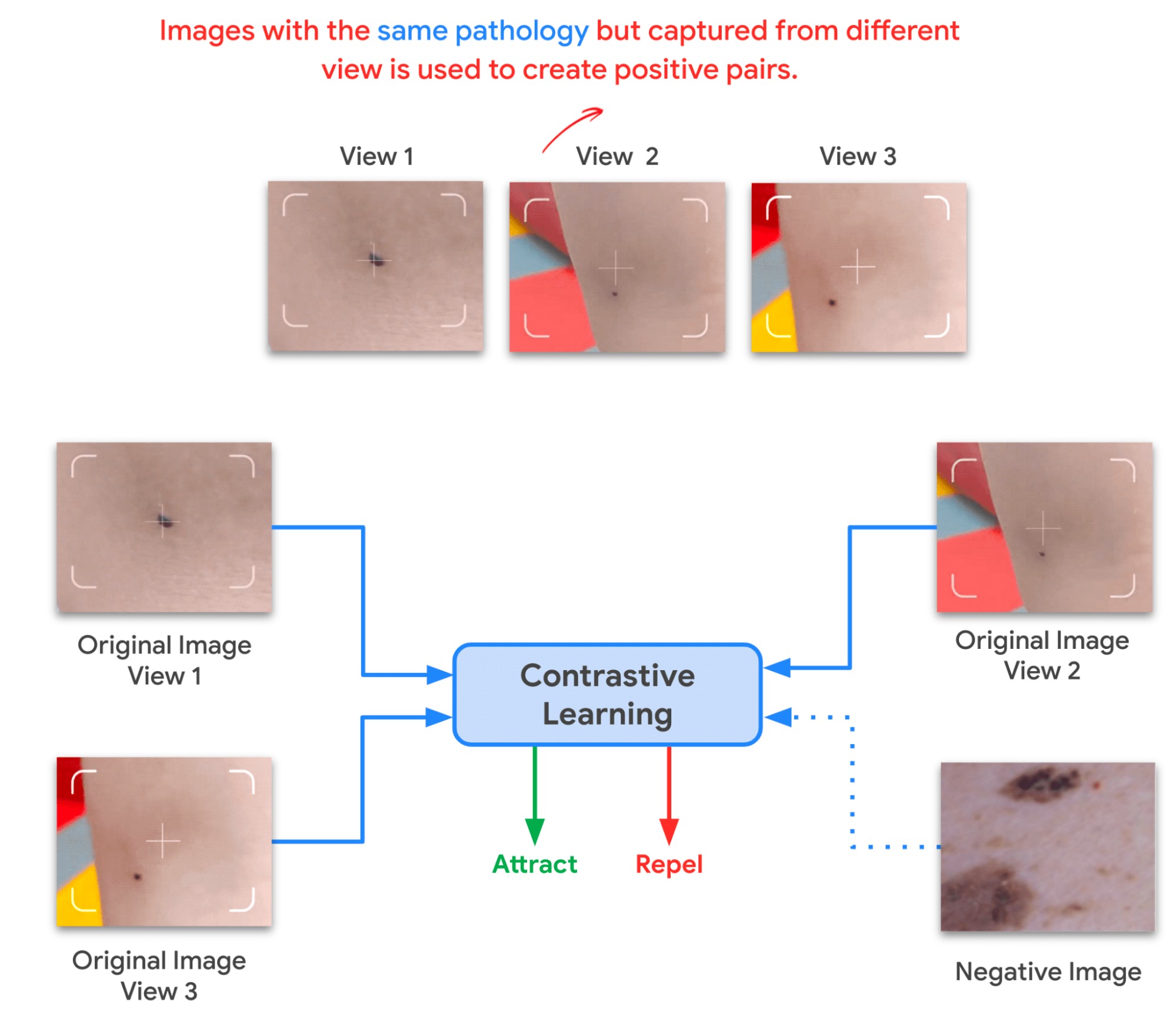
7.2.2 Step 2: MICLe
After the initial pre-training with SimCLR on unlabeled natural images is complete, the model is trained to capture the special characteristics of medical image datasets. This can be done with SimCLR, but this method constructs positive pairs only through augmentation and does not readily leverage patients’ metadata for positive pair construction. Hence, MICLe is used here.
- Given multiple images of a given patient case, MICLe constructs a positive pair for self-supervised contrastive learning by drawing two crops from two distinct images from the same patient case. Such images may be taken from different viewing angles and show different body parts with the same underlying pathology.
- This presents a great opportunity for self-supervised learning algorithms to learn representations that are robust to changes of viewpoint, imaging conditions, and other confounding factors.
7.2.3 Step 3: Fine-tuning
- The model is trained end-to-end during fine-tuning, using the weights of the pre-trained network as initialization for the downstream supervised task dataset.
- For data augmentation during fine-tuning, random color augmentation, cropping with resizing, blurring, rotation, and flipping were done for the images in both tasks (Dermatology and Chest X-Rays).
- For every combination of pretraining strategy and downstream fine-tuning task, an extensive hyperparameter search was performed.
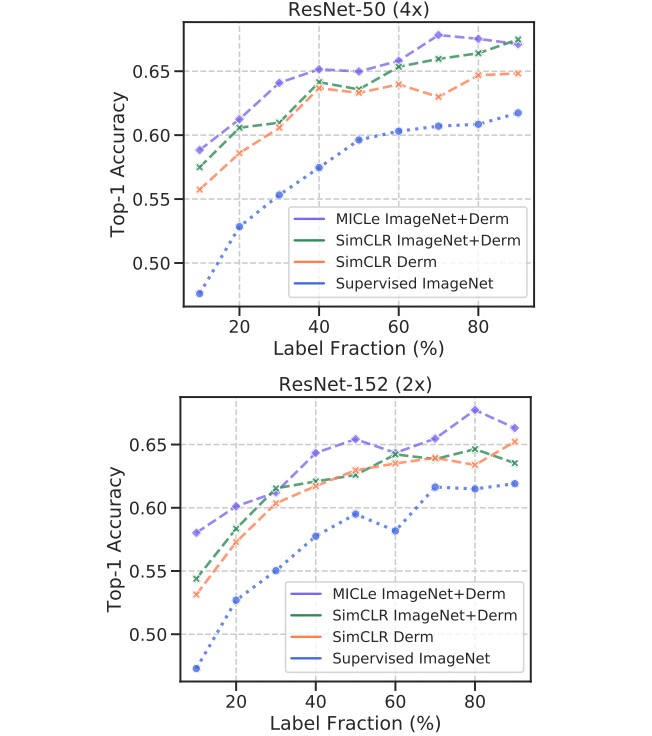
Performance Analysis
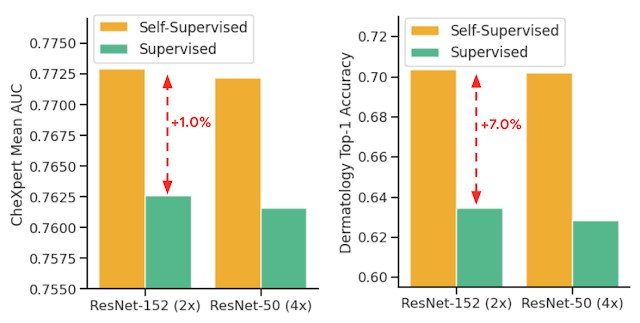
- Self-supervised learning utilizes unlabeled domain-specific medical images and significantly outperforms supervised ImageNet pre-training.
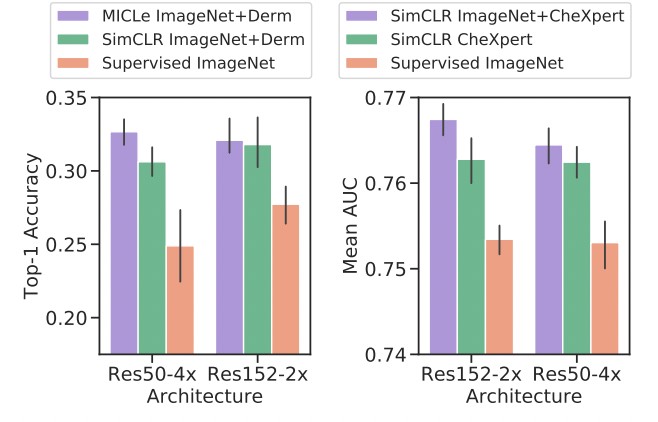
- Self-supervised pre-trained models can generalize better to distribution shifts, with MICLe pre-training leading to the most gains. This is a valuable finding, as generalization under distribution shift is of paramount importance to clinical applications.
- Pre-training using self-supervised models can compensate for low label efficiency for medical image classification, and across the sampled label fractions, self-supervised models consistently outperform the supervised baseline. In fact, MICLe is able to match baselines using only 20% of the training data for ResNet-50 (4x) and 30% of the training data for ResNet152 (2x).
8. Challenges in Self-Supervised Learning
Self-supervised learning is making strides in almost every sphere of the Machine Learning community, but it has drawbacks. It aims for a ‘one method solves all’ approach but is far from that. Key challenges in the SSL space include:
8.1 Accuracy
The premise of SSL is not using labeled data, but the downside is that you either need huge amounts of data to generate accurate pseudo labels or compromise on accuracy. Inaccurate labels generated will be counterproductive while training in the initial steps.
8.2 Computational Efficiency
Due to multiple training stages (generating pseudo labels and training on pseudo labels), the time taken to train a model is high compared to supervised learning. Current SSL approaches require a huge amount of data to achieve accuracy close to supervised learning counterparts.
8.3 Pretext Task
Choosing the right pretext task for your use case is very important. For instance, if you choose an autoencoder as your pretext task where the image is compressed and then regenerated, it will also try to mimic the noise of the original image. If your task is generating high-quality images, this pretext task will do more harm than good.
9. Key Takeaways
In this article, we explored self-supervised learning, its growing popularity, and its risks and challenges. We discussed popular models trained using this approach and examined how big tech companies leverage self-supervised learning to solve pressing issues.
To sum up what we have learned:
- Self-supervised learning is beneficial in use-cases where we deal with data-related challenges, ranging from low resources for dataset preparation to time-consuming annotation problems.
- It’s great for Downstream Tasks i.e., Transfer Learning. Models can be pre-trained in a self-supervised manner on unlabeled datasets, which can then be fine-tuned for specific use-cases.
- As a result, self-supervised learning is the go-to approach if you want to build a scalable ML model.
- However, be aware of the strings attached to using this approach.
While we have covered a lot in this article, it is not exhaustive. There is still much to learn about self-supervised learning. If you want to learn more about its present and potential use-cases, you can refer to the following material:
Happy Learning!
10. FAQs About Self-Supervised Learning
-
What is the main advantage of self-supervised learning?
- The main advantage is the ability to learn from unlabeled data, reducing the need for costly and time-consuming manual annotation.
-
How does self-supervised learning differ from supervised learning?
- Supervised learning requires labeled data, while self-supervised learning creates its own labels from the data itself.
-
What are some common applications of self-supervised learning?
- Common applications include computer vision tasks like image recognition and natural language processing tasks like text generation.
-
What is a pretext task in self-supervised learning?
- A pretext task is a task designed to help the model learn useful representations of the data, which can then be used for downstream tasks.
-
What is transfer learning and how does it relate to self-supervised learning?
- Transfer learning involves using knowledge gained from one task to improve performance on another. Self-supervised learning is often used as a pre-training step for transfer learning.
-
What are the challenges of self-supervised learning?
- Challenges include ensuring the generated pseudo-labels are accurate, the high computational cost of training, and choosing the right pretext task.
-
Can self-supervised learning be used in medical imaging?
- Yes, self-supervised learning is used in medical imaging to analyze and classify images, especially when labeled data is limited.
-
What is BERT and how does it use self-supervised learning?
- BERT (Bidirectional Encoder Representations from Transformers) is a popular NLP model that uses self-supervised learning techniques like masked language modeling and next sentence prediction.
-
How does self-supervised learning contribute to generic AI?
- Self-supervised learning allows models to learn general representations of
