Transfer learning represents a paradigm shift in machine learning, leveraging pre-existing knowledge to accelerate and enhance learning in new, related tasks. How Does Transfer Learning Work? This article from LEARNS.EDU.VN explains the mechanics, advantages, and applications of this powerful technique. Dive in to understand how you can use transfer learning to build better models faster, even with limited data, and explore how it streamlines machine learning deployment and fosters innovation.
1. Understanding the Core of Transfer Learning
Transfer learning, a prominent technique in machine learning, enables the reuse of a pre-trained model on a new problem. In essence, a machine leverages the knowledge acquired from a previous task to enhance generalization in another. This is particularly beneficial when dealing with limited data, a common scenario in real-world applications. Transfer learning accelerates model training, improves performance, and conserves computational resources by focusing on transferring knowledge and applying it effectively, making it a key technique for various data science challenges.
1.1. What is Transfer Learning in Machine Learning?
In transfer learning, the expertise of an already trained machine learning model is applied to a different yet interconnected problem. For instance, if you trained a classifier to predict whether an image contains a backpack, you could employ the knowledge that the model gained during its training to recognize other objects like sunglasses.
With transfer learning, we basically try to exploit what has been learned in one task to improve generalization in another. We transfer the weights that a network has learned at “task A” to a new “task B.” This approach is especially valuable in fields like image recognition and natural language processing, where models often require extensive training data and computational power.
The general idea is to use the knowledge a model has learned from a task with a lot of available labeled training data in a new task that doesn’t have much data. Instead of starting the learning process from scratch, we start with patterns learned from solving a related task.
Transfer learning is mostly used in computer vision and natural language processing tasks like sentiment analysis due to the huge amount of computational power required.
Transfer learning isn’t really a machine learning technique, but can be seen as a “design methodology” within the field. It is also not exclusive to machine learning. Nevertheless, it has become quite popular in combination with neural networks that require huge amounts of data and computational power.
 Transfer Learning Explained
Transfer Learning Explained
1.2. Key Components of Transfer Learning
To effectively implement transfer learning, it’s essential to understand its fundamental components. These include the source task, the target task, and the transfer method itself. The source task is the task on which the model is initially trained, providing the pre-existing knowledge. The target task is the new problem to which the pre-trained model is applied. The transfer method involves selecting which parts of the pre-trained model to reuse and how to adapt them to the target task. This adaptation may involve fine-tuning specific layers or using the pre-trained model as a feature extractor. By carefully managing these components, practitioners can optimize the performance of transfer learning and achieve superior results with less data and computational effort.
1.3. Distinguishing Transfer Learning from Traditional Machine Learning
Traditional machine learning models are typically trained from scratch on a specific dataset, without leveraging any pre-existing knowledge. This approach requires substantial amounts of data and computational resources, particularly for complex tasks. Transfer learning, in contrast, leverages knowledge gained from training on a source task to improve performance on a target task. This enables models to achieve higher accuracy and faster convergence, especially when the target task has limited data. This approach is especially beneficial in scenarios where data is scarce or computationally expensive to acquire.
2. Delving into How Transfer Learning Works
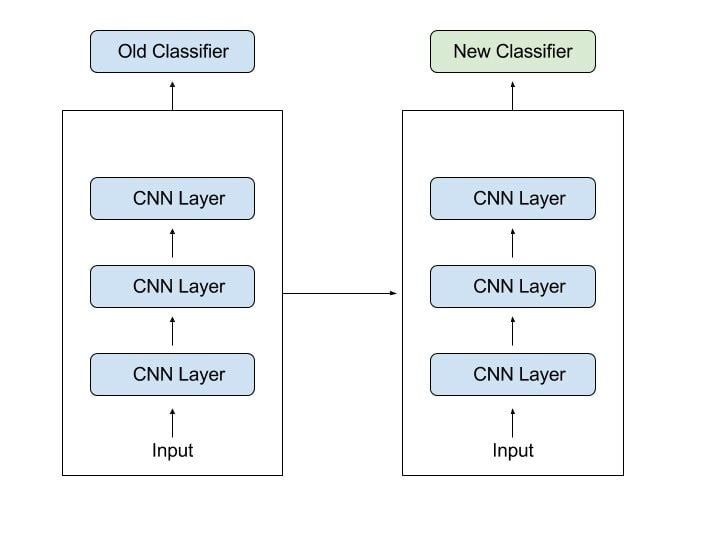
Transfer learning functions by leveraging pre-trained models, typically developed on large datasets, and adapting them to new, related tasks. This process often involves freezing the early layers of the pre-trained model, which have learned generic features, and retraining the later layers to recognize task-specific features. This approach saves time and resources, especially when dealing with limited data. The key lies in selectively transferring and fine-tuning the knowledge embedded in the pre-trained model to suit the specific requirements of the new task.
2.1. The Mechanics of Knowledge Transfer
In computer vision, for example, neural networks usually try to detect edges in the earlier layers, shapes in the middle layer and some task-specific features in the later layers. In transfer learning, the early and middle layers are used and we only retrain the latter layers. It helps leverage the labeled data of the task it was initially trained on.
This process of retraining models is known as fine-tuning. In the case of transfer learning, though, we need to isolate specific layers for retraining. There are then two types of layers to keep in mind when applying transfer learning:
- Frozen layers: Layers that are left alone during retraining and keep their knowledge from a previous task for the model to build on.
- Modifiable layers: Layers that are retrained during fine-tuning, so a model can adjust its knowledge to a new, related task.
Let’s go back to the example of a model trained for recognizing a backpack in an image, which will be used to identify sunglasses. In the earlier layers, the model has learned to recognize objects, so we will only retrain the latter layers to help it learn what separates sunglasses from other objects.
2.2. Fine-Tuning Pre-Trained Models
Fine-tuning is a critical step in transfer learning, involving the adjustment of a pre-trained model’s parameters to better suit a new task. This process typically involves unfreezing some of the pre-trained layers and retraining them on the target dataset. The extent of fine-tuning depends on the similarity between the source and target tasks. If the tasks are very similar, a smaller learning rate is often used to avoid disrupting the pre-trained weights. Conversely, if the tasks are more dissimilar, a larger learning rate may be appropriate to allow the model to adapt more significantly. Effective fine-tuning can significantly improve the model’s performance on the new task.
2.3. Feature Extraction with Pre-Trained Models
Feature extraction is a transfer learning technique where a pre-trained model is used as a feature extractor for a new task. In this approach, the pre-trained model’s layers are frozen, and the outputs of one or more layers are used as features for a new model. This is particularly useful when the target task has limited data or when the pre-trained model has learned robust, generalizable features. The extracted features can then be fed into a traditional machine learning model, such as a support vector machine or a random forest, to perform the target task. This method leverages the pre-trained model’s knowledge without requiring extensive retraining.
3. Exploring the Benefits of Transfer Learning
Transfer learning provides several advantages, making it a valuable tool in machine learning. Key benefits include reduced training time, improved model performance, and the ability to work with limited data. By leveraging pre-trained models, practitioners can achieve faster convergence and higher accuracy, especially in scenarios where data is scarce or computationally expensive. This approach fosters innovation and enables the development of advanced models more efficiently.
3.1. Accelerating Model Training
One of the primary advantages of transfer learning is its ability to accelerate model training. By starting with a pre-trained model, the initial layers of which have already learned valuable features from a large dataset, the training process can be significantly shortened. Instead of training a model from scratch, which can take days or even weeks, practitioners can fine-tune the pre-trained model on a smaller, task-specific dataset. This not only saves time but also reduces the computational resources required for training, making it an efficient approach for developing machine learning models.
3.2. Enhancing Model Performance
Transfer learning often leads to enhanced model performance, particularly when the target task has limited data. The pre-trained model brings with it a wealth of knowledge learned from a large dataset, which can help the model generalize better on the new task. This is especially beneficial when the target dataset is small or lacks diversity. By leveraging the pre-existing knowledge, the model can achieve higher accuracy and robustness compared to training from scratch. This makes transfer learning a valuable technique for improving the overall quality of machine learning models.
3.3. Working with Limited Data
Transfer learning is particularly useful when dealing with limited data, a common challenge in many real-world applications. By leveraging pre-trained models trained on large datasets, practitioners can achieve high accuracy even with small target datasets. The pre-trained model provides a strong foundation of knowledge, allowing the model to generalize effectively and avoid overfitting. This makes transfer learning an indispensable tool for scenarios where collecting large amounts of data is impractical or expensive.
4. When to Employ Transfer Learning
Determining when to use transfer learning depends on several factors, including the availability of training data, the existence of pre-trained models, and the similarity between tasks. Transfer learning is most effective when there is a lack of training data, a pre-trained network exists for a similar task, and the input data is the same or can be preprocessed to match the input requirements of the pre-trained model. These guidelines help ensure that transfer learning is applied appropriately and yields the desired improvements in model performance.
4.1. Scenarios with Insufficient Training Data
As is always the case in machine learning, it is hard to form rules that are generally applicable, but here are some guidelines on when transfer learning might be used:
- Lack of training data: There isn’t enough labeled training data to train your network from scratch.
- Existing network: There already exists a network that is pre-trained on a similar task, which is usually trained on massive amounts of data.
- Same input: When task 1 and task 2 have the same input.
If the original model was trained using an open-source library like TensorFlow, you can simply restore it and retrain some layers for your task. Keep in mind, however, that transfer learning only works if the features learned from the first task are general, meaning they can be useful for another related task as well. Also, the input of the model needs to have the same size as it was initially trained with. If you don’t have that, add a pre-processing step to resize your input to the needed size.
4.2. Leveraging Existing Pre-Trained Networks
The availability of pre-trained networks is a crucial factor in determining when to use transfer learning. If there exists a pre-trained model that has been trained on a similar task, it can be leveraged to accelerate and improve the training process. Pre-trained models often contain valuable knowledge and features learned from large datasets, which can be transferred to the new task. By using a pre-trained model as a starting point, practitioners can avoid training a model from scratch, saving time and resources. This approach is particularly beneficial when the target task has limited data or when the pre-trained model has achieved high accuracy on a related task.
4.3. Ensuring Input Compatibility
Ensuring input compatibility is essential when applying transfer learning. The input data for the target task should be compatible with the pre-trained model’s input requirements. This may involve preprocessing the input data to match the size, format, and distribution of the data used to train the pre-trained model. If the input data is incompatible, the pre-trained model may not perform well on the new task. Therefore, it is crucial to carefully assess and preprocess the input data to ensure compatibility with the pre-trained model.
5. Different Approaches to Transfer Learning
Transfer learning encompasses various approaches, each with its own advantages and use cases. These include training a model to reuse it, using a pre-trained model directly, and feature extraction. By understanding these different approaches, practitioners can choose the most appropriate method for their specific task and dataset. This flexibility allows for the efficient adaptation of pre-existing knowledge to new problems, maximizing the benefits of transfer learning.
5.1. Training a Model for Reuse
Imagine you want to solve task A but don’t have enough data to train a deep neural network. One way around this is to find a related task B with an abundance of data. Train the deep neural network on task B and use the model as a starting point for solving task A. Whether you’ll need to use the whole model or only a few layers depends heavily on the problem you’re trying to solve.
If you have the same input in both tasks, possibly reusing the model and making predictions for your new input is an option. Alternatively, changing and retraining different task-specific layers and the output layer is a method to explore.
5.2. Direct Use of Pre-Trained Models
The second approach is to use an already pre-trained model. There are a lot of these models out there, so make sure to do a little research. How many layers to reuse and how many to retrain depends on the problem.
Keras, for example, provides numerous pre-trained models that can be used for transfer learning, prediction, feature extraction and fine-tuning. You can find these models, and also some brief tutorials on how to use them, here. There are also many research institutions that release trained models.
This type of transfer learning is most commonly used throughout deep learning.
5.3. Feature Extraction Techniques
Another approach is to use deep learning to discover the best representation of your problem, which means finding the most important features. This approach is also known as representation learning, and can often result in a much better performance than can be obtained with hand-designed representation.
In machine learning, features are usually manually hand-crafted by researchers and domain experts. Fortunately, deep learning can extract features automatically. Of course, you still have to decide which features you put into your network. That said, neural networks have the ability to learn which features are really important and which ones aren’t. A representation learning algorithm can discover a good combination of features within a very short timeframe, even for complex tasks which would otherwise require a lot of human effort.
The learned representation can then be used for other problems as well. Simply use the first layers to spot the right representation of features, but don’t use the output of the network because it is too task-specific. Instead, feed data into your network and use one of the intermediate layers as the output layer. This layer can then be interpreted as a representation of the raw data.
This approach is mostly used in computer vision because it can reduce the size of your dataset, which decreases computation time and makes it more suitable for traditional algorithms as well.
6. Popular Pre-Trained Models in Use
Several pre-trained models have gained popularity due to their effectiveness and versatility. These include models like Inception-v3, ResNet, and AlexNet. Inception-v3, trained for the ImageNet Large Visual Recognition Challenge, is adept at classifying images into 1,000 classes. ResNet is known for its deep architecture and ability to mitigate the vanishing gradient problem, while AlexNet is a pioneering model in deep learning. These models offer a strong foundation for transfer learning, providing valuable features that can be adapted to various tasks.
6.1. Inception-v3 Model
There are some pre-trained machine learning models out there that are quite popular. One of them is the Inception-v3 model, which was trained for the ImageNet “Large Visual Recognition Challenge.” In this challenge, participants had to classify images into 1,000 classes like “zebra,” “Dalmatian” and “dishwasher.”
Here’s a very good tutorial from TensorFlow on how to retrain image classifiers.
6.2. Microsoft’s Pre-Trained Models
Microsoft also offers some pre-trained models, available for both R and Python development, through the MicrosoftML R package and the microsoftml Python package.
6.3. ResNet and AlexNet
Other quite popular models are ResNet and AlexNet. ResNet, with its deep residual learning framework, overcomes the vanishing gradient problem, enabling the training of very deep networks. AlexNet, a convolutional neural network, gained prominence for its performance in the ImageNet competition, demonstrating the power of deep learning for image recognition tasks. Both models are widely used in transfer learning due to their robust feature extraction capabilities.
7. Practical Applications of Transfer Learning Across Industries
Transfer learning has found widespread application across various industries, revolutionizing tasks in computer vision, natural language processing, and healthcare. In computer vision, it is used for image classification, object detection, and image segmentation. In natural language processing, it enhances sentiment analysis, text classification, and machine translation. In healthcare, transfer learning aids in medical image analysis, drug discovery, and patient diagnosis. These applications demonstrate the versatility and impact of transfer learning in solving complex problems and improving efficiency across diverse domains.
7.1. Computer Vision Enhancements
Transfer learning significantly enhances computer vision tasks by leveraging pre-trained models like VGGNet, ResNet, and Inception. These models, trained on large datasets like ImageNet, provide robust feature extraction capabilities. Fine-tuning these models on specific datasets allows for high accuracy in image classification, object detection, and image segmentation. For example, in autonomous driving, transfer learning is used to recognize traffic signs, pedestrians, and other vehicles, improving safety and reliability. This approach reduces the need for extensive training data and computational resources, making computer vision applications more accessible and efficient.
7.2. Natural Language Processing Improvements
Transfer learning has revolutionized natural language processing (NLP) by enabling models to leverage pre-trained embeddings and architectures. Models like BERT, GPT, and RoBERTa, trained on massive text corpora, provide a strong foundation for various NLP tasks. Fine-tuning these models on specific datasets allows for improved performance in sentiment analysis, text classification, named entity recognition, and machine translation. For example, in customer service, transfer learning is used to analyze customer feedback, identify issues, and provide automated responses, enhancing customer satisfaction and efficiency.
7.3. Advances in Healthcare with Transfer Learning
Transfer learning is making significant advances in healthcare by improving medical image analysis, drug discovery, and patient diagnosis. Pre-trained models can be fine-tuned on medical images to detect diseases like cancer, Alzheimer’s, and pneumonia with high accuracy. In drug discovery, transfer learning helps predict the efficacy and toxicity of new drugs, accelerating the development process. For patient diagnosis, transfer learning can analyze patient data to identify patterns and predict potential health issues, enabling early intervention and personalized treatment. These applications demonstrate the potential of transfer learning to transform healthcare and improve patient outcomes.
8. Navigating Challenges in Transfer Learning
Despite its benefits, transfer learning poses several challenges that practitioners must address. These include negative transfer, domain adaptation, and catastrophic forgetting. Negative transfer occurs when the knowledge learned from the source task negatively impacts performance on the target task. Domain adaptation involves adjusting the pre-trained model to account for differences between the source and target domains. Catastrophic forgetting refers to the loss of knowledge from the source task when fine-tuning on the target task. By understanding these challenges and implementing appropriate mitigation strategies, practitioners can maximize the effectiveness of transfer learning.
8.1. Overcoming Negative Transfer
Negative transfer occurs when the knowledge learned from the source task negatively impacts the performance of the target task. This can happen when the source and target tasks are too dissimilar, causing the pre-trained model to introduce irrelevant or misleading features. To mitigate negative transfer, it is crucial to carefully select source tasks that are closely related to the target task. Additionally, techniques like fine-tuning only specific layers or using regularization methods can help prevent the model from overfitting to irrelevant features. Monitoring the model’s performance during training and adjusting the transfer learning strategy accordingly is also essential.
8.2. Adapting to Different Domains
Domain adaptation is a critical challenge in transfer learning, particularly when the source and target datasets have different distributions. This difference can lead to reduced performance on the target task. Techniques like domain adversarial training and maximum mean discrepancy (MMD) are used to align the feature distributions of the source and target domains. Additionally, fine-tuning the pre-trained model on a small subset of the target data can help it adapt to the new domain. Careful selection of the pre-trained model and thorough evaluation on the target domain are essential for successful domain adaptation.
8.3. Preventing Catastrophic Forgetting
Catastrophic forgetting, also known as catastrophic interference, is a phenomenon where a neural network abruptly forgets previously learned information upon learning new information. This can be a significant challenge in transfer learning when fine-tuning a pre-trained model on a new task. To mitigate catastrophic forgetting, techniques like regularization, knowledge distillation, and replay buffers are used. Regularization methods, such as L1 and L2 regularization, help prevent the model from overfitting to the new data. Knowledge distillation involves transferring knowledge from the pre-trained model to the fine-tuned model, preserving the original knowledge. Replay buffers store a subset of the original training data, which is periodically replayed during fine-tuning to prevent the model from forgetting.
9. The Future of Transfer Learning: Trends and Innovations
The future of transfer learning is marked by several exciting trends and innovations, including meta-learning, self-supervised learning, and continual learning. Meta-learning aims to develop models that can quickly adapt to new tasks with minimal training. Self-supervised learning leverages unlabeled data to pre-train models, reducing the need for labeled datasets. Continual learning focuses on enabling models to learn continuously from new data without forgetting previous knowledge. These advancements promise to further enhance the efficiency, adaptability, and robustness of transfer learning.
9.1. Meta-Learning for Rapid Adaptation
Meta-learning, also known as “learning to learn,” is an emerging trend in transfer learning that focuses on developing models that can quickly adapt to new tasks with minimal training data. Meta-learning algorithms learn from a distribution of tasks, enabling them to generalize to new, unseen tasks more effectively. Techniques like model-agnostic meta-learning (MAML) and reptile are used to train models that can be fine-tuned with just a few examples. Meta-learning promises to significantly improve the efficiency and adaptability of transfer learning, making it easier to apply pre-trained models to a wide range of new tasks.
9.2. Self-Supervised Learning Approaches
Self-supervised learning is a powerful approach that leverages unlabeled data to pre-train models, reducing the need for large labeled datasets. In self-supervised learning, the model learns to predict certain aspects of the input data, such as missing parts of an image or masked words in a sentence. This pre-training step allows the model to learn useful representations that can then be fine-tuned on downstream tasks with limited labeled data. Techniques like contrastive learning and generative pre-training are used in self-supervised learning. This approach is particularly beneficial in domains where labeled data is scarce or expensive to obtain.
9.3. Continual Learning for Sustained Performance
Continual learning, also known as lifelong learning, focuses on enabling models to learn continuously from new data without forgetting previously learned knowledge. This is a significant challenge in machine learning, as models often suffer from catastrophic forgetting when trained on new tasks. Continual learning techniques like regularization, replay buffers, and knowledge distillation are used to mitigate catastrophic forgetting and preserve the model’s ability to perform well on past tasks. Continual learning is essential for applications where models need to adapt to changing environments and learn from a continuous stream of data.
10. Getting Started with Transfer Learning Today
Ready to dive into transfer learning? LEARNS.EDU.VN provides numerous resources to help you get started. Visit our website at LEARNS.EDU.VN to explore detailed tutorials, case studies, and pre-trained models. Whether you’re a student, researcher, or industry professional, you’ll find valuable information and tools to enhance your machine learning skills. Join our community today and start transforming your projects with the power of transfer learning! Contact us at 123 Education Way, Learnville, CA 90210, United States or reach out via Whatsapp at +1 555-555-1212.
10.1. Utilizing LEARNS.EDU.VN Resources
LEARNS.EDU.VN provides a wealth of resources to help you get started with transfer learning. Our website offers detailed tutorials, case studies, and pre-trained models that you can use for your projects. Whether you’re a student, researcher, or industry professional, you’ll find valuable information and tools to enhance your machine learning skills. Explore our resources today and start transforming your projects with the power of transfer learning.
10.2. Practical Exercises and Projects
To gain hands-on experience with transfer learning, consider working on practical exercises and projects. Start by selecting a pre-trained model from a library like TensorFlow or PyTorch and fine-tuning it on a dataset of your choice. Experiment with different layers and learning rates to see how they affect the model’s performance. Work through case studies to understand how transfer learning is applied in real-world scenarios. By engaging in practical exercises and projects, you’ll develop a deeper understanding of transfer learning and its applications.
10.3. Connecting with the Transfer Learning Community
Connecting with the transfer learning community is a great way to learn from others, share your knowledge, and stay up-to-date with the latest trends and innovations. Join online forums, attend conferences, and participate in open-source projects to connect with fellow practitioners. Share your experiences, ask questions, and contribute to the community. By connecting with others, you’ll expand your network and gain valuable insights into the world of transfer learning.
Frequently Asked Questions
What is transfer learning?
Transfer learning is a machine learning technique where a model trained on one task is reused for another related task. This way, a model can build on its previous knowledge to master new tasks, and you can continue training a model despite having limited data.
What is the primary goal of transfer learning?
The primary goal of transfer learning is to leverage the knowledge gained from training on a source task to improve the performance of a model on a different but related target task, especially when the target task has limited data.
How does transfer learning differ from traditional machine learning?
Traditional machine learning models are trained from scratch on a specific dataset, without leveraging any pre-existing knowledge. Transfer learning, in contrast, leverages knowledge gained from training on a source task to improve performance on a target task.
What are the key benefits of using transfer learning?
The key benefits of using transfer learning include reduced training time, improved model performance, and the ability to work with limited data.
Can you explain the concept of fine-tuning in transfer learning?
Fine-tuning is a process where a pre-trained model’s parameters are adjusted to better suit a new task. This typically involves unfreezing some of the pre-trained layers and retraining them on the target dataset.
What is feature extraction in the context of transfer learning?
Feature extraction is a technique where a pre-trained model is used as a feature extractor for a new task. The pre-trained model’s layers are frozen, and the outputs of one or more layers are used as features for a new model.
How do I choose the right pre-trained model for my task?
Choosing the right pre-trained model involves considering the similarity between the source and target tasks, the size and type of your dataset, and the available computational resources.
What are some common challenges in transfer learning?
Common challenges in transfer learning include negative transfer, domain adaptation, and catastrophic forgetting.
What are some popular pre-trained models used in transfer learning?
Popular pre-trained models include Inception-v3, ResNet, AlexNet, BERT, and GPT.
Where can I find resources to learn more about transfer learning?
You can find resources on websites like learns.edu.vn, which offers tutorials, case studies, and pre-trained models. Additionally, online forums, conferences, and open-source projects provide valuable information and support.
