Deep learning, a sophisticated evolution of machine learning, is transforming industries worldwide. At LEARNS.EDU.VN, we aim to clarify the distinction between these two powerful technologies, empowering you to harness their potential. Explore our resources to master machine intelligence, artificial neural networks, and predictive analytics.
1. Defining Machine Learning: The Foundation of Intelligent Systems
Machine learning (ML) is a field at the intersection of computer science and statistics. It enables computers to learn from data without explicit programming. Instead of being explicitly coded for every possible scenario, machine learning algorithms identify patterns in data, make predictions, and improve their performance over time as they are exposed to more data. This capability makes machine learning invaluable in a wide array of applications, from spam filtering and personalized recommendations to fraud detection and medical diagnosis.
1.1. Supervised vs. Unsupervised Learning: Two Approaches to Machine Learning
Machine learning algorithms can be broadly categorized into two main types: supervised learning and unsupervised learning. The distinction between these two approaches lies in the nature of the data used to train the algorithms and the type of problem they are designed to solve.
-
Supervised Learning: In supervised learning, the algorithm is trained on a labeled dataset, meaning that each data point is associated with a known outcome or target variable. The goal of the algorithm is to learn a mapping function that can accurately predict the outcome for new, unseen data points. Common supervised learning tasks include classification (categorizing data into predefined classes) and regression (predicting continuous values). Examples of supervised learning algorithms include:
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVM)
- Decision Trees
- Random Forests
-
Unsupervised Learning: In unsupervised learning, the algorithm is trained on an unlabeled dataset, meaning that the data points are not associated with any known outcomes. The goal of the algorithm is to discover hidden patterns, structures, or relationships within the data. Common unsupervised learning tasks include clustering (grouping similar data points together) and dimensionality reduction (reducing the number of variables while preserving important information). Examples of unsupervised learning algorithms include:
- K-Means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- Association Rule Learning
1.2. The Machine Learning Process: From Data to Insights
The machine learning process typically involves the following steps:
- Data Collection: Gathering relevant and high-quality data is the first and most crucial step. The quality and quantity of the data directly impact the performance of the machine learning model. Data can come from various sources, such as databases, files, sensors, or APIs.
- Data Preprocessing: This step involves cleaning, transforming, and preparing the data for the machine learning algorithm. Data preprocessing may include handling missing values, removing outliers, normalizing or standardizing the data, and converting categorical variables into numerical representations.
- Feature Engineering: Feature engineering involves selecting, transforming, or creating new features (variables) that are relevant to the problem being solved. Effective feature engineering can significantly improve the accuracy and performance of the machine learning model. This often requires domain expertise.
- Model Selection: Choosing the appropriate machine learning algorithm for the task at hand is a critical decision. The choice of algorithm depends on the type of problem (e.g., classification, regression, clustering), the characteristics of the data, and the desired performance metrics.
- Model Training: The machine learning algorithm is trained on the prepared data. During training, the algorithm learns the underlying patterns and relationships in the data and adjusts its internal parameters to minimize the error between its predictions and the actual outcomes.
- Model Evaluation: The trained model is evaluated on a separate dataset (called the test set) to assess its performance and generalization ability. Performance metrics such as accuracy, precision, recall, F1-score, and area under the ROC curve (AUC) are used to evaluate the model.
- Model Tuning: If the model’s performance is not satisfactory, the hyperparameters of the algorithm can be tuned to optimize its performance. Hyperparameters are parameters that are not learned from the data but are set prior to training (e.g., the learning rate, the number of trees in a random forest).
- Model Deployment: Once the model is trained, evaluated, and tuned, it can be deployed into a production environment to make predictions on new, unseen data. The deployed model can be integrated into software applications, web services, or other systems.
1.3. Machine Learning in Action: Real-World Applications
Machine learning is used extensively in various industries. Here are some notable examples:
- Healthcare: Machine learning is used for medical diagnosis, drug discovery, personalized medicine, and predicting patient outcomes.
- Finance: Machine learning is used for fraud detection, risk assessment, algorithmic trading, and customer relationship management.
- Retail: Machine learning is used for personalized recommendations, inventory management, price optimization, and customer segmentation.
- Manufacturing: Machine learning is used for predictive maintenance, quality control, process optimization, and supply chain management.
- Transportation: Machine learning is used for autonomous driving, traffic prediction, route optimization, and logistics management.
2. Unveiling Deep Learning: A Neural Network Approach
Deep learning is a specialized subset of machine learning that uses artificial neural networks (ANNs) with multiple layers (hence, “deep”) to analyze data. These neural networks are inspired by the structure and function of the human brain, allowing them to learn complex patterns and representations from large amounts of data. Deep learning excels at tasks such as image recognition, natural language processing, and speech recognition, where traditional machine learning algorithms often struggle.
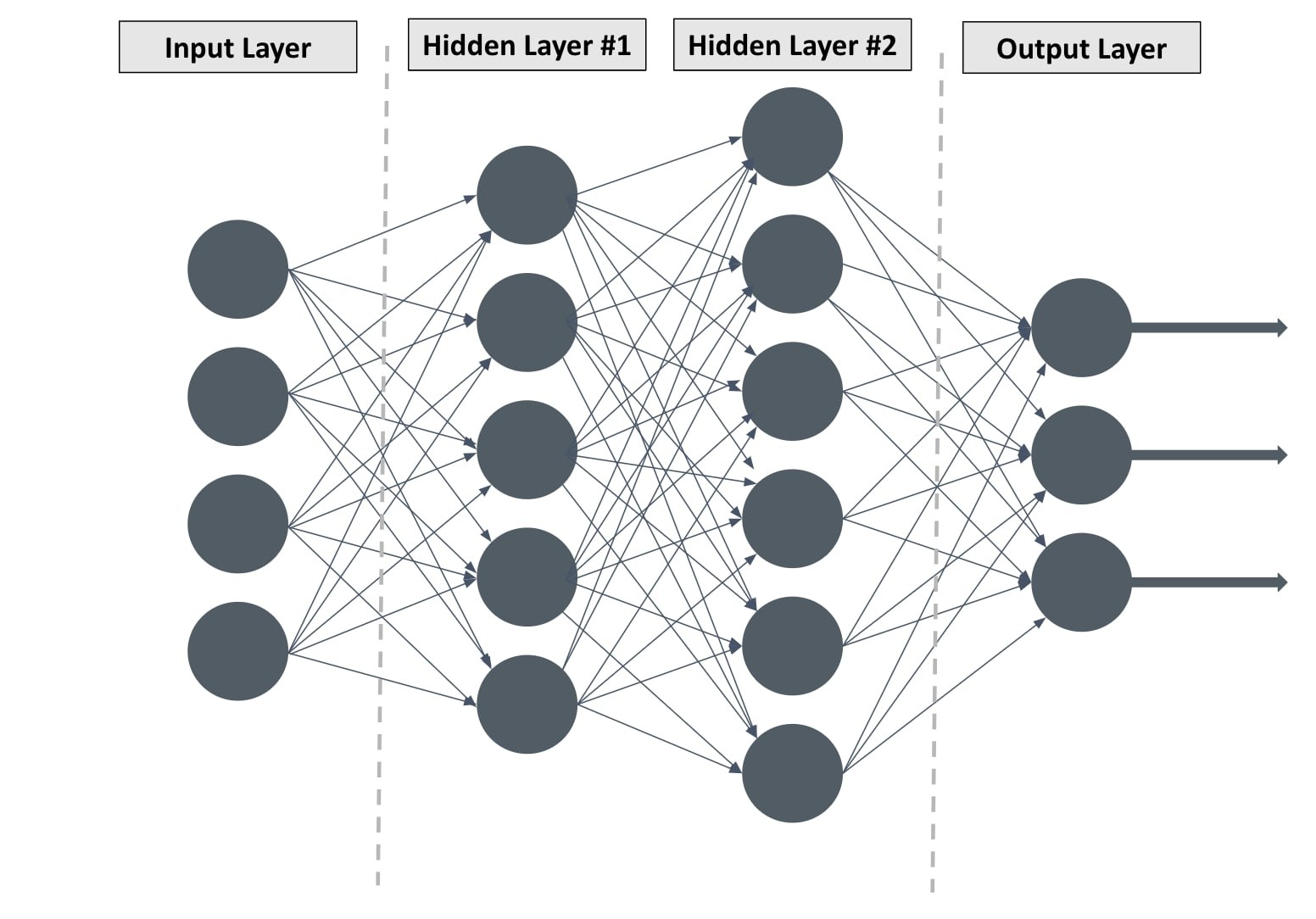
2.1. The Architecture of Deep Neural Networks: Layers of Abstraction
Deep neural networks are composed of interconnected layers of nodes (also called neurons or perceptrons). Each layer transforms the input data into a higher-level representation, allowing the network to learn hierarchical features. The architecture of a deep neural network typically includes the following types of layers:
- Input Layer: The input layer receives the raw data and passes it to the subsequent layers. The number of nodes in the input layer corresponds to the number of features in the input data.
- Hidden Layers: Hidden layers are the intermediate layers between the input and output layers. Each hidden layer applies a non-linear transformation to the data received from the previous layer, allowing the network to learn complex patterns. Deep neural networks can have many hidden layers, ranging from a few to hundreds or even thousands.
- Output Layer: The output layer produces the final output of the network. The number of nodes in the output layer depends on the type of problem being solved. For example, in a classification problem with n classes, the output layer would have n nodes, each representing the probability of the input belonging to that class.
2.2. The Learning Process in Deep Learning: From Data to Knowledge
The learning process in deep learning involves adjusting the weights and biases of the connections between the nodes in the neural network to minimize the error between the network’s predictions and the actual outcomes. This is typically done using a process called backpropagation, which involves the following steps:
- Forward Pass: The input data is fed forward through the network, and the output of each layer is computed.
- Loss Calculation: The difference between the network’s predictions and the actual outcomes is calculated using a loss function. The loss function quantifies the error of the network.
- Backpropagation: The error is propagated backward through the network, and the gradients of the loss function with respect to the weights and biases are computed. The gradients indicate the direction and magnitude of the changes needed to reduce the error.
- Weight Update: The weights and biases are updated using an optimization algorithm, such as gradient descent, to minimize the loss function. The learning rate determines the size of the steps taken during the weight update.
- Iteration: Steps 1-4 are repeated for multiple iterations (epochs) until the network converges and the loss function reaches a minimum.
2.3. Types of Deep Learning Architectures: Tailoring Networks to Tasks
Various types of deep learning architectures have been developed to address specific types of problems. Here are some of the most common types:
-
Convolutional Neural Networks (CNNs): CNNs are designed for processing images and videos. They use convolutional layers to extract features from the input data and pooling layers to reduce the dimensionality of the feature maps. CNNs are widely used in image recognition, object detection, and image segmentation.
-
Recurrent Neural Networks (RNNs): RNNs are designed for processing sequential data, such as text, speech, and time series. They have recurrent connections that allow them to maintain a memory of past inputs. RNNs are widely used in natural language processing, speech recognition, and machine translation.
-
Long Short-Term Memory (LSTM) Networks: LSTMs are a type of RNN that are better at handling long-range dependencies in sequential data. They use memory cells and gating mechanisms to selectively remember or forget information. LSTMs are widely used in natural language processing, speech recognition, and machine translation.
-
Generative Adversarial Networks (GANs): GANs are designed for generating new data that is similar to the training data. They consist of two networks: a generator that generates new data and a discriminator that distinguishes between real and generated data. GANs are widely used in image generation, image editing, and data augmentation.
2.4. Deep Learning’s Impact: Transforming Industries
Deep learning has had a profound impact on various industries, including:
- Computer Vision: Deep learning has enabled significant advances in image recognition, object detection, and image segmentation, leading to applications such as autonomous driving, facial recognition, and medical image analysis.
- Natural Language Processing: Deep learning has revolutionized natural language processing, enabling applications such as machine translation, sentiment analysis, and chatbot development.
- Speech Recognition: Deep learning has significantly improved speech recognition accuracy, leading to applications such as virtual assistants, voice search, and dictation software.
3. Key Differences Between Machine Learning and Deep Learning
While deep learning is a subset of machine learning, there are several key differences between the two:
| Feature | Machine Learning | Deep Learning |
|---|---|---|
| Data Requirements | Works well with smaller datasets. | Requires large amounts of data to train effectively. |
| Feature Extraction | Requires manual feature extraction by domain experts. | Performs automatic feature extraction through its neural network structure. |
| Computational Power | Can be trained on CPUs or less powerful GPUs. | Requires high-performance GPUs or specialized hardware for training. |
| Complexity | Simpler algorithms, easier to interpret. | More complex algorithms, harder to interpret (black box). |
| Training Time | Typically faster to train. | Can take significantly longer to train. |
| Applications | Suitable for a wide range of problems, including those with structured data. | Excels at complex tasks such as image recognition, natural language processing, and speech recognition. |

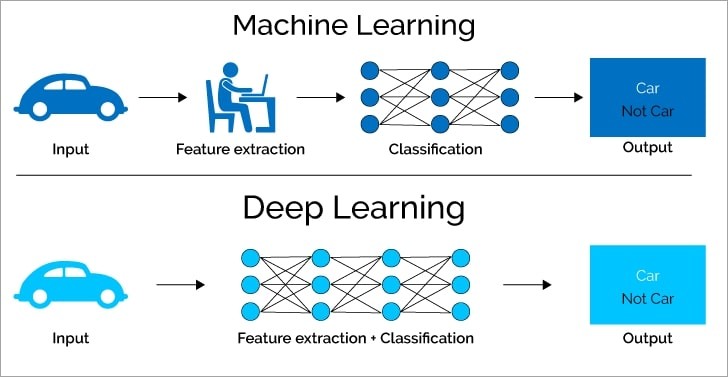

3.1. Feature Engineering: The Human Touch vs. Automated Learning
One of the most significant differences between machine learning and deep learning lies in the area of feature engineering. In traditional machine learning, feature engineering is a crucial step that requires domain expertise and manual effort. Data scientists or domain experts need to identify and extract relevant features from the raw data that can be used by the machine learning algorithm. This process can be time-consuming and challenging, as it requires a deep understanding of the data and the problem being solved.
In contrast, deep learning algorithms can automatically learn features from the raw data without the need for manual feature engineering. The deep neural network learns hierarchical representations of the data, with each layer extracting more abstract and complex features. This automated feature extraction capability is one of the key advantages of deep learning, as it eliminates the need for manual effort and can often lead to better performance.
3.2. Data Dependency: The Need for Big Data
Another significant difference between machine learning and deep learning is the amount of data required to train the algorithms effectively. Traditional machine learning algorithms can often perform well with relatively small datasets, while deep learning algorithms typically require large amounts of data to learn complex patterns and achieve high accuracy.
The reason for this data dependency is that deep neural networks have a large number of parameters that need to be tuned during training. With limited data, the network may overfit the training data, leading to poor generalization performance on new, unseen data. To prevent overfitting and ensure good generalization, deep learning algorithms need to be trained on large datasets that cover a wide range of scenarios and variations.
3.3. Computational Resources: The Power of GPUs
Deep learning algorithms are computationally intensive and require significant processing power to train effectively. The training process involves performing a large number of matrix multiplications and other operations on large datasets, which can take a long time on CPUs.
To accelerate the training process, deep learning algorithms are often trained on GPUs (Graphics Processing Units), which are specialized hardware accelerators that are designed for performing parallel computations. GPUs can significantly reduce the training time of deep learning models, making it possible to train complex models on large datasets in a reasonable amount of time.
3.4. Interpretability: The Black Box Challenge
One of the challenges with deep learning models is their lack of interpretability. Deep neural networks are often considered “black boxes” because it is difficult to understand how they arrive at their predictions. The complex interactions between the many layers and nodes in the network make it challenging to trace the decision-making process and identify the factors that are most influential in the prediction.
In contrast, traditional machine learning models are often more interpretable. For example, decision trees and linear regression models provide clear explanations of how the model makes its predictions. The interpretability of machine learning models is important in many applications, such as healthcare and finance, where it is crucial to understand the reasons behind the model’s predictions.
4. Bridging the Gap: Transfer Learning and Pre-trained Models
One of the key recent advances in deep learning is the development of transfer learning and pre-trained models. Transfer learning is a technique that allows a deep learning model trained on one task to be adapted to a different but related task. This can be done by fine-tuning the pre-trained model on a smaller dataset for the new task.
Pre-trained models are deep learning models that have been trained on large datasets and made available for others to use. These models can be used as a starting point for new deep learning projects, saving time and resources. Transfer learning and pre-trained models have made deep learning more accessible to researchers and practitioners who do not have access to large datasets or the computational resources to train models from scratch.
5. Choosing the Right Approach: Machine Learning vs. Deep Learning
The choice between machine learning and deep learning depends on the specific problem being solved, the amount of data available, the computational resources, and the desired level of interpretability. Here are some general guidelines:
-
Use machine learning when:
- You have a limited amount of data.
- You need a model that is easy to interpret.
- You have limited computational resources.
- The problem can be solved with traditional algorithms.
-
Use deep learning when:
- You have a large amount of data.
- You need to solve a complex problem such as image recognition, natural language processing, or speech recognition.
- You have access to high-performance GPUs or specialized hardware.
- Interpretability is not a primary concern.
6. Deep Learning and Machine Learning: A Synergistic Relationship
It’s important to recognize that deep learning and machine learning are not mutually exclusive. Deep learning is a subset of machine learning, and many real-world applications involve combining both approaches. For example, a system might use machine learning for data preprocessing and feature selection, and then use deep learning for the core prediction task.
7. Navigating the Future of AI: Embracing Continuous Learning
The fields of machine learning and deep learning are constantly evolving. New algorithms, architectures, and techniques are being developed at a rapid pace. To stay at the forefront of AI, it’s essential to embrace continuous learning and stay up-to-date on the latest advancements.
8. LEARNS.EDU.VN: Your Gateway to Mastering AI
At LEARNS.EDU.VN, we are committed to providing high-quality educational resources to help you master the concepts and techniques of machine learning and deep learning. Whether you are a student, a professional, or simply curious about AI, we have something to offer.
8.1. Explore Our Comprehensive Learning Resources
Visit LEARNS.EDU.VN to discover a wealth of articles, tutorials, and courses covering a wide range of topics in machine learning and deep learning.
8.2. Unlock Your Potential with Expert Guidance
Our team of experienced educators and industry experts is dedicated to providing you with the guidance and support you need to succeed in your AI journey.
9. Frequently Asked Questions (FAQ)
9.1. What is the main difference between machine learning and deep learning?
Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to analyze data. Unlike traditional machine learning, deep learning algorithms can automatically learn features from raw data.
9.2. Which one is better, machine learning or deep learning?
Neither is inherently better. The choice depends on the specific problem, data availability, computational resources, and desired level of interpretability.
9.3. What are some applications of deep learning?
Deep learning is used in computer vision, natural language processing, speech recognition, and many other fields.
9.4. Do I need to be a programmer to learn machine learning or deep learning?
While programming skills are helpful, many user-friendly tools and platforms are available that allow you to build and deploy machine learning models without extensive coding knowledge.
9.5. How much data do I need to train a deep learning model?
Deep learning models typically require large amounts of data to train effectively. The exact amount depends on the complexity of the model and the problem being solved.
9.6. What are some popular deep learning frameworks?
Popular deep learning frameworks include TensorFlow, PyTorch, and Keras.
9.7. Can I use pre-trained models for my deep learning projects?
Yes, pre-trained models can save time and resources by providing a starting point for your projects.
9.8. Is deep learning a black box?
Deep learning models can be difficult to interpret, but techniques are being developed to improve their explainability.
9.9. How can I stay up-to-date on the latest advancements in machine learning and deep learning?
Follow reputable blogs, attend conferences, and take online courses to stay current on the latest developments.
9.10. Where can I find more information and resources on machine learning and deep learning?
Visit LEARNS.EDU.VN to access a wealth of articles, tutorials, and courses.
10. Your Next Step: Embark on Your AI Learning Journey
Ready to dive deeper into the world of machine learning and deep learning? LEARNS.EDU.VN offers a wealth of resources to help you gain the knowledge and skills you need to succeed. Visit our website today to explore our comprehensive learning materials and take the first step towards mastering AI. Let LEARNS.EDU.VN be your guide on this exciting journey.
For more information, visit our website at LEARNS.EDU.VN or contact us at 123 Education Way, Learnville, CA 90210, United States, or Whatsapp: +1 555-555-1212. Discover the power of AI with learns.edu.vn today!
