Is Knn Unsupervised Learning? Dive into the depths of K-Nearest Neighbors (KNN) to uncover its nature, applications, and benefits with LEARNS.EDU.VN. Learn whether KNN aligns with unsupervised or supervised learning paradigms and discover how it can empower your educational journey. Uncover the secrets of this versatile algorithm and enhance your understanding of machine learning concepts and non-parametric methods.
1. Introduction: Unveiling the Nature of KNN
K-Nearest Neighbors (KNN) is a versatile and intuitive machine-learning algorithm used for classification and regression tasks. While often associated with supervised learning, its unsupervised variant unlocks even broader possibilities. Understanding the nuances of KNN is crucial for anyone venturing into the world of data science and machine learning. With KNN algorithms being a foundational concept, let’s explore the various implementations of KNN within scikit-learn to equip you with the knowledge to leverage its power effectively, whether you’re a student, educator, or professional.
 KNN Visualization
KNN Visualization
2. KNN: Supervised or Unsupervised?
KNN primarily falls under the umbrella of supervised learning when used for classification or regression. In these scenarios, the algorithm learns from labeled data, where each data point has a known output or target value. However, KNN can also be adapted for unsupervised learning tasks, such as nearest neighbor searches and anomaly detection, where the algorithm explores the inherent structure of unlabeled data. Let’s delve into both aspects:
2.1 KNN as a Supervised Learning Algorithm
In supervised learning, KNN leverages labeled data to predict the class or value of new, unseen data points. The algorithm identifies the k nearest neighbors to the new data point based on a distance metric (e.g., Euclidean distance) and assigns the most frequent class (classification) or the average value (regression) of those neighbors as the prediction.
2.2 KNN as an Unsupervised Learning Tool
In unsupervised learning, KNN focuses on discovering patterns and relationships within unlabeled data. The NearestNeighbors algorithm in sklearn.neighbors provides functionalities for unsupervised nearest neighbor searches. This can be used for:
- Manifold Learning: Understanding the underlying structure and dimensionality of the data.
- Spectral Clustering: Grouping data points based on the connectivity of their nearest neighbors.
- Anomaly Detection: Identifying data points that deviate significantly from their neighbors.
3. Understanding Unsupervised Nearest Neighbors
The NearestNeighbors implementation in sklearn.neighbors serves as a uniform interface to various nearest neighbor algorithms, including BallTree, KDTree, and a brute-force approach. This flexibility allows users to choose the most efficient algorithm based on their data characteristics.
3.1 Algorithms for Nearest Neighbor Search
- Brute Force: Computes distances between all pairs of points, suitable for small datasets.
- KD Tree: A tree-based data structure that partitions the parameter space along data axes, efficient for low-dimensional data.
- Ball Tree: A tree-based data structure that partitions data in a series of nesting hyper-spheres, effective for high-dimensional data.
3.2 Finding Nearest Neighbors with NearestNeighbors
To find the nearest neighbors between two sets of data, the NearestNeighbors algorithm can be used as follows:
from sklearn.neighbors import NearestNeighbors
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
distances, indices = nbrs.kneighbors(X)
print("Indices:", indices)
print("Distances:", distances)This code snippet demonstrates how to find the two nearest neighbors for each point in the dataset X using the Ball Tree algorithm.
4. Use Cases for Unsupervised KNN
Unsupervised KNN finds applications in diverse fields, including:
- Recommender Systems: Identifying similar users or items based on their attributes.
- Anomaly Detection: Detecting fraudulent transactions or network intrusions by identifying outliers.
- Image Processing: Segmenting images based on pixel similarity.
- Bioinformatics: Clustering genes or proteins based on their expression patterns.
5. KNN Variants: Classification and Regression
KNN isn’t just a single algorithm; it’s a family of algorithms that can be tailored to different machine learning tasks. Here, we’ll explore the two main types of KNN: classification and regression.
5.1 KNN Classification: Predicting Categories
KNN classification is used when you want to predict which category a new data point belongs to.
5.1.1 How KNN Classification Works
- Choose k: Determine the number of neighbors to consider.
- Calculate Distances: Compute the distance between the new data point and all points in your training set.
- Find Nearest Neighbors: Identify the k closest data points (the “nearest neighbors”).
- Vote: Assign the new data point to the category that appears most frequently among its k nearest neighbors.
5.1.2 KNN Classification in Scikit-learn
Scikit-learn offers two main KNN classifiers:
KNeighborsClassifier: Classifies based on the k nearest neighbors.RadiusNeighborsClassifier: Classifies based on neighbors within a fixed radius.
5.1.3 Key Considerations for KNN Classification
- Choosing k: A larger k can reduce noise but blur category boundaries.
- Distance Metric: Euclidean distance is common, but others exist.
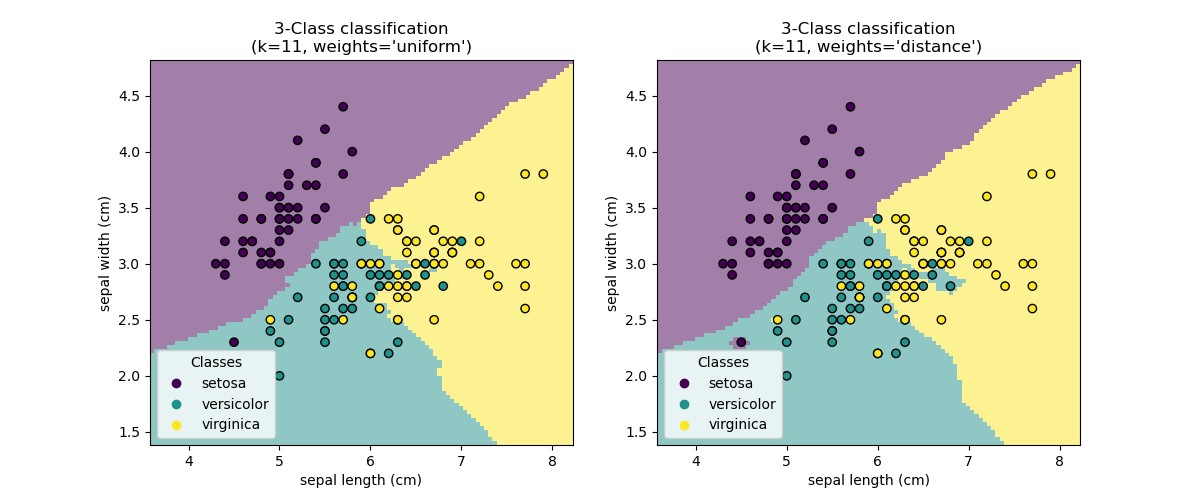
- Uniform vs. Distance Weights: Uniform weights give equal importance to all neighbors. Distance weights prioritize closer neighbors.
5.2 KNN Regression: Predicting Continuous Values
KNN regression is used when you want to predict a continuous value for a new data point.
5.2.1 How KNN Regression Works
The process is similar to KNN classification, but instead of voting, KNN regression averages the values of the k nearest neighbors.
- Choose k: As with classification, decide how many neighbors to use.
- Calculate Distances: Find the distances to all training points.
- Find Nearest Neighbors: Identify the k closest points.
- Average: Calculate the average value of the target variable for those k neighbors. This average is the prediction.
5.2.2 KNN Regression in Scikit-learn
Scikit-learn provides two KNN regressors:
KNeighborsRegressor: Predicts based on the k nearest neighbors.RadiusNeighborsRegressor: Predicts based on neighbors within a fixed radius.
5.2.3 Key Considerations for KNN Regression
- All points contribute uniformly to the classification of a query point.
- Weight points such that nearby points contribute more to the regression than faraway points.
- A user-defined function of the distance can be supplied, which will be used to compute the weights.
6. Advantages and Limitations
Like any algorithm, KNN has its strengths and weaknesses:
6.1 Advantages
- Simple and Intuitive: Easy to understand and implement.
- Versatile: Applicable to classification, regression, and unsupervised learning tasks.
- Non-Parametric: Makes no assumptions about the underlying data distribution.
- Adaptable: Can be used with various distance metrics and weighting schemes.
6.2 Limitations
- Computationally Expensive: Can be slow for large datasets, especially with brute-force search.
- Sensitive to Feature Scaling: Features with larger scales can dominate distance calculations.
- Curse of Dimensionality: Performance degrades in high-dimensional spaces.
- Memory Intensive: Requires storing the entire training dataset.
7. Optimizing KNN Performance
To overcome the limitations of KNN, several optimization techniques can be employed:
- Feature Scaling: Standardize or normalize features to ensure equal contributions to distance calculations.
- Dimensionality Reduction: Reduce the number of features using techniques like PCA or feature selection.
- Efficient Data Structures: Use KD Trees or Ball Trees to speed up nearest neighbor searches.
- Cross-Validation: Optimize the value of k and other hyperparameters using cross-validation techniques.
8. Nearest Centroid Classifier
The NearestCentroid classifier is a simple algorithm that represents each class by the centroid of its members, in effect, this makes it similar to the label updating phase of the KMeans algorithm. It also has no parameters to choose, making it a good baseline classifier. It does, however, suffer on non-convex classes, as well as when classes have drastically different variances, as equal variance in all dimensions is assumed.
8.1 Nearest Shrunken Centroid
The NearestCentroid classifier has a shrink_threshold parameter, which implements the nearest shrunken centroid classifier. In effect, the value of each feature for each centroid is divided by the within-class variance of that feature. The feature values are then reduced by shrink_threshold. Most notably, if a particular feature value crosses zero, it is set to zero. In effect, this removes the feature from affecting the classification. This is useful, for example, for removing noisy features.
9. Leveraging KNN as a Transformer
Many scikit-learn estimators rely on nearest neighbors such as KNeighborsClassifier and KNeighborsRegressor.
9.1 Benefits of the Sparse Graph API
- The precomputed graph can be re-used multiple times, for instance while varying a parameter of the estimator.
- Precomputing the graph can give finer control on the nearest neighbors estimation, for instance enabling multiprocessing though the parameter
n_jobs, which might not be available in all estimators. - The precomputation can be performed by custom estimators to use different implementations, such as approximate nearest neighbors methods, or implementation with special data types.
10. Real-World Applications and Examples
Let’s explore how KNN is used in various industries:
10.1 Healthcare
- Diagnosis: Predicting diseases based on patient symptoms and medical history.
- Drug Discovery: Identifying potential drug candidates based on their similarity to known drugs.
- Personalized Medicine: Tailoring treatment plans based on individual patient characteristics.
10.2 Finance
- Credit Scoring: Assessing the creditworthiness of loan applicants.
- Fraud Detection: Identifying fraudulent transactions by detecting unusual patterns.
- Algorithmic Trading: Developing trading strategies based on historical market data.
10.3 E-commerce
- Recommender Systems: Suggesting products to customers based on their past purchases and browsing history.
- Customer Segmentation: Grouping customers based on their demographics and purchasing behavior.
- Price Optimization: Determining optimal product prices based on market demand and competitor pricing.
10.4 Education
- Student Performance Prediction: Identifying students at risk of academic failure.
- Personalized Learning: Tailoring educational content to individual student needs.
- Course Recommendation: Suggesting relevant courses based on student interests and skills.
11. Getting Started with KNN on LEARNS.EDU.VN
Ready to delve deeper into KNN and explore its applications? LEARNS.EDU.VN offers a wealth of resources to guide you on your learning journey:
- Comprehensive Articles: In-depth explanations of KNN concepts and algorithms.
- Practical Tutorials: Step-by-step guides to implementing KNN in Python.
- Real-World Case Studies: Examples of how KNN is used in various industries.
- Expert Insights: Advice and guidance from experienced data scientists and machine learning professionals.
12. Call to Action
Unlock your potential and master the power of KNN with LEARNS.EDU.VN. Explore our extensive collection of educational resources and take your data science skills to the next level. Visit LEARNS.EDU.VN today and embark on a journey of discovery and innovation. For more information, contact us at 123 Education Way, Learnville, CA 90210, United States or Whatsapp: +1 555-555-1212.
13. Neighborhood Components Analysis (NCA)
Neighborhood Components Analysis (NCA) is a distance metric learning algorithm which aims to improve the accuracy of nearest neighbors classification compared to the standard Euclidean distance. The algorithm directly maximizes a stochastic variant of the leave-one-out k-nearest neighbors (KNN) score on the training set. It can also learn a low-dimensional linear projection of data that can be used for data visualization and fast classification.
13.1 Dimensionality Reduction
NCA can be used to perform supervised dimensionality reduction. The input data are projected onto a linear subspace consisting of the directions which minimize the NCA objective. The desired dimensionality can be set using the parameter n_components.
13.2 Mathematical Formulation
The goal of NCA is to learn an optimal linear transformation matrix of size (n_components, n_features), which maximises the sum over all samples i of the probability p_i that i is correctly classified, i.e.:
arg max Σ p_iwhere N = n_samples and p_i the probability of sample i being correctly classified according to a stochastic nearest neighbors rule in the learned embedded space:
p_{i}=sumlimits_{j in C_i}{p_{i j}}14. FAQs about KNN
Q1: Is KNN a supervised or unsupervised learning algorithm?
A: KNN can be both. When used for classification or regression with labeled data, it’s supervised. When used for nearest neighbor searches or anomaly detection with unlabeled data, it’s unsupervised.
Q2: How does KNN work?
A: KNN identifies the k nearest neighbors to a new data point based on a distance metric and assigns the most frequent class (classification) or the average value (regression) of those neighbors as the prediction.
Q3: What are the advantages of KNN?
A: KNN is simple, intuitive, versatile, non-parametric, and adaptable.
Q4: What are the limitations of KNN?
A: KNN can be computationally expensive, sensitive to feature scaling, susceptible to the curse of dimensionality, and memory-intensive.
Q5: How can I optimize KNN performance?
A: Use feature scaling, dimensionality reduction, efficient data structures, and cross-validation.
Q6: What are some real-world applications of KNN?
A: KNN is used in healthcare, finance, e-commerce, and education for tasks like diagnosis, fraud detection, recommender systems, and student performance prediction.
Q7: What is the KD Tree algorithm?
A: The KD Tree is a binary tree structure which recursively partitions the parameter space along the data axes, dividing it into nested orthotropic regions into which data points are filed.
Q8: What is the Ball Tree algorithm?
A: A ball tree recursively divides the data into nodes defined by a centroid C and radius r, such that each point in the node lies within the hyper-sphere defined by r and C.
Q9: What is Neighborhood Components Analysis (NCA)?
A: Neighborhood Components Analysis (NCA) is a distance metric learning algorithm which aims to improve the accuracy of nearest neighbors classification compared to the standard Euclidean distance.
Q10: What is the Nearest Centroid Classifier?
A: The NearestCentroid classifier is a simple algorithm that represents each class by the centroid of its members.
15. The Future of KNN: Trends and Innovations
As machine learning continues to evolve, KNN is also undergoing transformations. Here are some emerging trends and innovations:
15.1 Approximate Nearest Neighbors (ANN)
ANN algorithms sacrifice some accuracy for significant speed gains, making KNN feasible for massive datasets. Libraries like FAISS and Annoy are leading the way in this area.
15.2 GPU Acceleration
Leveraging the parallel processing power of GPUs can dramatically accelerate distance calculations, especially for high-dimensional data.
15.3 Ensemble Methods
Combining KNN with other machine learning algorithms can create more robust and accurate models. For example, KNN can be used as a base learner in ensemble methods like boosting or bagging.
15.4 Automated Machine Learning (AutoML)
AutoML platforms are automating the process of hyperparameter tuning and algorithm selection for KNN, making it easier for non-experts to achieve optimal results.
15.5 Explainable AI (XAI)
Researchers are developing techniques to make KNN more transparent and interpretable, addressing concerns about the “black box” nature of some machine learning models.
16. Choice of Nearest Neighbors Algorithm
The optimal algorithm for a given dataset is a complicated choice, and depends on a number of factors:
- number of samples
Nand dimensionalityD. - data structure: intrinsic dimensionality of the data and/or sparsity of the data.
- number of neighbors
krequested for a query point. - number of query points.
16.1 Effect of leaf_size
For small sample sizes a brute force search can be more efficient than a tree-based query. This fact is accounted for in the ball tree and KD tree by internally switching to brute force searches within leaf nodes. The level of this switch can be specified with the parameter leaf_size. This parameter choice has many effects:
- construction time: A larger
leaf_sizeleads to a faster tree construction time, because fewer nodes need to be created. - query time: Both a large or small
leaf_sizecan lead to suboptimal query cost. - memory: As
leaf_sizeincreases, the memory required to store a tree structure decreases.
17. The Impact of Feature Engineering on KNN
Feature engineering is the art of transforming raw data into features that better represent the underlying problem to the machine learning model. For KNN, the quality of features is paramount.
17.1 Feature Selection
- Why it matters: Irrelevant or redundant features can confuse the KNN algorithm, leading to decreased accuracy and increased computational cost.
- Techniques:
- Univariate Feature Selection: Select features based on statistical tests like chi-squared or ANOVA.
- Recursive Feature Elimination: Iteratively remove features and evaluate model performance.
- Feature Importance from Tree-Based Models: Use models like Random Forests to rank features by importance.
17.2 Feature Transformation
- Why it matters: Transforming features can make them more suitable for distance-based calculations in KNN.
- Techniques:
- Polynomial Features: Create new features by raising existing features to various powers.
- Interaction Features: Create new features by combining two or more existing features.
17.3 Domain-Specific Feature Engineering
- Why it matters: Understanding the specific domain of your data allows you to create features that capture meaningful relationships and patterns.
18. Advanced KNN Techniques
For those seeking to push the boundaries of KNN, here are some advanced techniques:
18.1 Weighted KNN
- How it works: Assign different weights to neighbors based on their distance to the query point. Closer neighbors have a greater influence on the prediction.
- Benefits: Can improve accuracy, especially when neighbors are not uniformly distributed.
18.2 KNN with Data Editing
- How it works: Remove noisy or irrelevant data points from the training set.
- Benefits: Can improve accuracy and reduce memory requirements.
18.3 Multi-Modal KNN
- How it works: Combine KNN with other machine learning algorithms to create more robust and accurate models.
19. Addressing Common Challenges with KNN
Even with careful optimization and feature engineering, you may encounter challenges when working with KNN. Here’s how to tackle some common issues:
19.1 Imbalanced Datasets
- The problem: If one class has significantly more data points than others, KNN may be biased towards the majority class.
- Solutions:
- Resampling: Oversample the minority class or undersample the majority class.
- Cost-Sensitive Learning: Assign higher misclassification costs to the minority class.
19.2 Missing Data
- The problem: KNN cannot handle missing values directly.
- Solutions:
- Imputation: Replace missing values with estimates like the mean, median, or mode.
- KNN Imputation: Use KNN to predict missing values based on the values of other features.
19.3 High Dimensionality
- The problem: The curse of dimensionality can significantly degrade KNN performance in high-dimensional spaces.
- Solutions:
- Feature Selection: Reduce the number of features.
- Dimensionality Reduction: Use techniques like PCA to project data into a lower-dimensional space.
20. Valid Metrics for Nearest Neighbor Algorithms
For a list of available metrics, see the documentation of the DistanceMetric class and the metrics listed in sklearn.metrics.pairwise.PAIRWISE_DISTANCE_FUNCTIONS. Note that the “cosine” metric uses cosine_distances.
A list of valid metrics for any of the above algorithms can be obtained by using their valid_metric attribute. For example, valid metrics for KDTree can be generated by:
from sklearn.neighbors import KDTree
print(sorted(KDTree.valid_metrics))21. KNN: Ethical Considerations and Responsible Use
As with any powerful technology, it’s important to consider the ethical implications of KNN and use it responsibly.
21.1 Bias and Fairness
- The risk: KNN models can perpetuate and amplify biases present in the training data, leading to unfair or discriminatory outcomes.
- Mitigation:
- Careful Data Collection: Ensure that your data is representative and free from bias.
- Bias Detection and Mitigation Techniques: Use algorithms to identify and mitigate bias in your data and models.
21.2 Transparency and Interpretability
- The challenge: KNN can be difficult to interpret, especially in high-dimensional spaces.
- Solutions:
- Feature Importance Analysis: Identify the features that have the greatest impact on KNN predictions.
- Explainable AI (XAI) Techniques: Use methods to make KNN more transparent and understandable.
21.3 Privacy
- The risk: KNN models can potentially reveal sensitive information about individuals in the training data.
- Mitigation:
- Data Anonymization: Remove or obfuscate personally identifiable information.
- Differential Privacy: Add noise to the data to protect individual privacy.
22. Conclusion: Embracing the Potential of KNN
KNN stands as a versatile and powerful algorithm with applications spanning various domains. Whether used in a supervised or unsupervised manner, its intuitive nature and adaptability make it a valuable tool for learners, educators, and professionals alike. By understanding its strengths, limitations, and optimization techniques, you can harness the full potential of KNN to solve real-world problems and drive innovation. Explore the resources at learns.edu.vn to deepen your understanding and embark on a transformative learning experience. Remember, continuous learning is the key to unlocking new possibilities and shaping a brighter future.
