Deep learning techniques applied to semantic segmentation offer a robust framework for understanding and classifying images at a pixel level, and LEARNS.EDU.VN provides comprehensive resources to master these advanced methods. This review explores various deep learning architectures, including Fully Convolutional Networks (FCNs), encoder-decoder models, and attention mechanisms, showcasing their effectiveness in achieving precise and detailed image understanding. Dive into the world of semantic understanding, image analysis, and pixel classification to unlock the full potential of deep learning for semantic segmentation.
1. Understanding Semantic Segmentation Through Deep Learning
Semantic segmentation is a critical area in computer vision that involves classifying each pixel in an image into a specific category. Unlike traditional image classification, which assigns a single label to an entire image, semantic segmentation provides a detailed, pixel-level understanding of the scene. Deep learning techniques have revolutionized this field by enabling the development of models that can accurately and efficiently perform this complex task. This section will delve into the fundamental concepts and significance of semantic segmentation, its differences from other computer vision tasks, and the pivotal role of deep learning.
1.1. What is Semantic Segmentation?
Semantic segmentation, at its core, is about assigning a class label to each pixel in an image. Imagine a photograph of a street scene. A semantic segmentation model would identify and label each pixel as belonging to a specific category, such as:
- Road
- Building
- Car
- Pedestrian
- Sky
The goal is to create a pixel-wise map of the image, where each pixel is associated with a semantic category. This is different from image classification, which would simply label the entire image as a “street scene,” or object detection, which would identify bounding boxes around individual objects. Semantic segmentation provides a much richer and more detailed understanding of the image content.
1.2. How Does Semantic Segmentation Differ from Other Computer Vision Tasks?
To fully appreciate the importance of semantic segmentation, it’s helpful to compare it with other related computer vision tasks:
- Image Classification: Assigns a single label to an entire image. For example, classifying an image as “cat” or “dog.”
- Object Detection: Identifies and locates multiple objects within an image by drawing bounding boxes around them. For example, detecting cars, pedestrians, and traffic lights in a street scene.
- Instance Segmentation: Similar to semantic segmentation, but it also differentiates between individual instances of the same object class. For example, distinguishing between different cars in a parking lot.
| Task | Description | Output |
|---|---|---|
| Image Classification | Assigns a single label to the entire image. | A single class label for the image. |
| Object Detection | Identifies and locates objects within an image using bounding boxes. | Bounding boxes around each object, along with their class labels. |
| Semantic Segmentation | Assigns a class label to each pixel in the image, providing a detailed understanding of the scene. | A pixel-wise map of the image, where each pixel is labeled with its corresponding class. |
| Instance Segmentation | Identifies and segments each individual object instance within an image, differentiating between different objects of the same class. | A pixel-wise map of the image, with each pixel labeled by both its class and the specific instance it belongs to. |
1.3. Why is Deep Learning Important for Semantic Segmentation?
Deep learning, particularly convolutional neural networks (CNNs), has become the cornerstone of modern semantic segmentation due to its ability to automatically learn complex features from raw pixel data. Traditional methods relied on handcrafted features, which were often limited in their ability to capture the nuances of visual data. CNNs, on the other hand, can learn hierarchical representations of images, allowing them to identify intricate patterns and relationships that are crucial for accurate pixel-level classification.
Key advantages of deep learning in semantic segmentation:
- Automatic Feature Learning: CNNs automatically learn relevant features from the data, eliminating the need for manual feature engineering.
- High Accuracy: Deep learning models can achieve state-of-the-art accuracy on complex segmentation tasks.
- End-to-End Training: Deep learning models can be trained end-to-end, optimizing all components of the system simultaneously.
- Scalability: Deep learning models can be scaled to handle large datasets and high-resolution images.
According to a study by the University of California, Berkeley, deep learning-based semantic segmentation models have shown a significant improvement in accuracy compared to traditional methods, with some models achieving over 90% accuracy on benchmark datasets.
2. Fully Convolutional Networks (FCNs) for Semantic Segmentation
Fully Convolutional Networks (FCNs) represent a groundbreaking approach in the field of semantic segmentation. Introduced by Long et al. in 2015, FCNs revolutionized the way pixel-wise classification is performed by extending traditional Convolutional Neural Networks (CNNs) to operate on images of arbitrary sizes. This section provides an in-depth exploration of FCNs, covering their architecture, advantages, and limitations, and offering practical insights for implementation.
2.1. What is the Architecture of FCNs?
The core idea behind FCNs is to replace the fully connected layers in a traditional CNN with convolutional layers. In a typical CNN, convolutional and pooling layers extract features from the input image, while fully connected layers map these features to a fixed set of class labels. However, the fully connected layers require a fixed input size, limiting the CNN’s ability to process images of different dimensions.
FCNs overcome this limitation by replacing the fully connected layers with convolutional layers that perform the same operation but can handle variable input sizes. This transformation allows the network to produce a spatial map of class predictions, where each pixel is assigned a class label. The architecture of an FCN typically includes the following components:
- Convolutional Layers: Extract features from the input image using convolutional filters.
- Pooling Layers: Reduce the spatial dimensions of the feature maps, increasing the receptive field and making the network more robust to variations in object size and position.
- Upsampling Layers: Increase the resolution of the feature maps to match the original input size, allowing for pixel-wise classification.
- Skip Connections: Combine feature maps from different layers to capture both fine-grained details and high-level semantic information.
2.2. Advantages of Using FCNs
FCNs offer several advantages over traditional CNNs for semantic segmentation:
- Variable Input Size: FCNs can process images of arbitrary sizes, making them more flexible and versatile.
- Pixel-Wise Prediction: FCNs produce a pixel-wise map of class predictions, providing a detailed understanding of the image content.
- End-to-End Training: FCNs can be trained end-to-end, optimizing all components of the network simultaneously.
- Efficiency: FCNs are computationally efficient compared to other semantic segmentation methods, making them suitable for real-time applications.
A study published in the IEEE Transactions on Pattern Analysis and Machine Intelligence found that FCNs can achieve state-of-the-art accuracy on semantic segmentation tasks while requiring fewer parameters and less training time compared to other deep learning models.
2.3. Limitations and Challenges
Despite their advantages, FCNs also have some limitations and challenges:
- Low Resolution Output: The repeated pooling operations in FCNs can lead to a loss of spatial resolution, resulting in blurry or coarse segmentation maps.
- Lack of Global Context: FCNs primarily focus on local features and may struggle to capture long-range dependencies and global context, which are important for accurate segmentation.
- Computational Cost: Training FCNs on high-resolution images can be computationally expensive, requiring significant memory and processing power.
2.4. How to Implement FCNs
Implementing FCNs involves several key steps:
- Data Preparation: Prepare a labeled dataset of images with pixel-wise annotations.
- Network Architecture: Design the FCN architecture by selecting appropriate convolutional, pooling, upsampling, and skip connection layers.
- Loss Function: Choose a loss function that measures the difference between the predicted segmentation map and the ground truth annotations. Common loss functions include cross-entropy loss and Dice loss.
- Optimization: Train the FCN using an optimization algorithm such as stochastic gradient descent (SGD) or Adam.
- Evaluation: Evaluate the performance of the trained FCN on a held-out validation set using metrics such as pixel accuracy, intersection-over-union (IoU), and Dice coefficient.
| Step | Description |
|---|---|
| Data Preparation | Gather and preprocess a labeled dataset of images with pixel-wise annotations. This may involve resizing images, normalizing pixel values, and splitting the dataset into training, validation, and test sets. |
| Network Architecture | Design the FCN architecture by selecting appropriate convolutional, pooling, upsampling, and skip connection layers. Consider using pre-trained CNNs as a starting point and fine-tuning them for the specific segmentation task. |
| Loss Function | Choose a loss function that measures the difference between the predicted segmentation map and the ground truth annotations. Common loss functions include cross-entropy loss, Dice loss, and Jaccard loss. |
| Optimization | Train the FCN using an optimization algorithm such as stochastic gradient descent (SGD) or Adam. Tune the learning rate, batch size, and other hyperparameters to achieve optimal performance. |
| Evaluation | Evaluate the performance of the trained FCN on a held-out validation set using metrics such as pixel accuracy, intersection-over-union (IoU), and Dice coefficient. Use the validation set to fine-tune the network architecture and hyperparameters and estimate the generalization performance on unseen data. |
LEARNS.EDU.VN offers in-depth tutorials and courses on implementing FCNs for various applications.
Alt: FCN architecture illustrating convolutional, pooling, and upsampling layers for semantic segmentation.
3. Encoder-Decoder Models in Deep Learning
Encoder-decoder models have become a popular architectural choice for semantic segmentation due to their ability to capture both local and global information. These models consist of two main components: an encoder that reduces the spatial resolution of the input image while extracting high-level features, and a decoder that reconstructs the original resolution while producing a pixel-wise segmentation map. This section provides a detailed overview of encoder-decoder models, including their architecture, advantages, and popular implementations.
3.1. How Do Encoder-Decoder Models Work?
Encoder-decoder models are designed to address the limitations of FCNs by incorporating a more structured approach to feature extraction and upsampling. The encoder progressively reduces the spatial dimensions of the input image, creating a compact representation that captures the essential features of the scene. The decoder then uses this representation to reconstruct a high-resolution segmentation map.
The encoder typically consists of a series of convolutional and pooling layers, similar to a traditional CNN. However, instead of fully connected layers, the encoder produces a low-resolution feature map that serves as input to the decoder. The decoder consists of a series of upsampling and convolutional layers that gradually increase the spatial resolution of the feature map while refining the segmentation predictions.
3.2. Advantages of Encoder-Decoder Models
Encoder-decoder models offer several advantages over FCNs:
- Better Spatial Resolution: The decoder’s upsampling layers help to recover the spatial resolution lost during the encoding process, resulting in more detailed and accurate segmentation maps.
- Contextual Information: The encoder captures high-level contextual information from the entire image, which can improve the segmentation of objects and regions.
- Flexibility: Encoder-decoder models can be easily adapted to different segmentation tasks by modifying the architecture of the encoder and decoder.
According to research from the University of Oxford, encoder-decoder models have demonstrated superior performance on several benchmark datasets compared to FCNs, particularly in tasks requiring fine-grained segmentation.
3.3. Popular Encoder-Decoder Architectures
Several encoder-decoder architectures have been proposed for semantic segmentation:
- U-Net: Introduced by Ronneberger et al. in 2015, U-Net is a popular encoder-decoder architecture that uses skip connections to combine feature maps from the encoder and decoder at multiple scales. This allows the network to capture both fine-grained details and high-level semantic information.
- SegNet: Proposed by Badrinarayanan et al. in 2017, SegNet uses the pooling indices from the encoder to perform upsampling in the decoder, reducing the number of learnable parameters and improving computational efficiency.
- DeepLab: Developed by Chen et al. in 2017, DeepLab incorporates atrous convolution to increase the receptive field of the network without reducing the spatial resolution. It also uses conditional random fields (CRFs) to refine the segmentation boundaries.
| Architecture | Description | Key Features |
|---|---|---|
| U-Net | An encoder-decoder architecture that uses skip connections to combine feature maps from the encoder and decoder at multiple scales, allowing the network to capture both fine-grained details and high-level semantic information. | Skip connections, symmetric architecture, suitable for medical image segmentation. |
| SegNet | An encoder-decoder architecture that uses the pooling indices from the encoder to perform upsampling in the decoder, reducing the number of learnable parameters and improving computational efficiency. | Pooling indices for upsampling, reduced number of parameters, efficient memory usage. |
| DeepLab | An encoder-decoder architecture that incorporates atrous convolution to increase the receptive field of the network without reducing the spatial resolution. It also uses conditional random fields (CRFs) to refine the segmentation boundaries. | Atrous convolution, conditional random fields (CRFs), refined segmentation boundaries, high-resolution feature maps. |
3.4. Challenges and Solutions
Encoder-decoder models also face several challenges:
- Vanishing Gradients: Training deep encoder-decoder models can be difficult due to the vanishing gradient problem, where the gradients become too small to update the weights effectively. Solutions include using residual connections, batch normalization, and more advanced optimization algorithms.
- Memory Requirements: Encoder-decoder models can require significant memory, especially when processing high-resolution images. Solutions include using smaller batch sizes, gradient accumulation, and model parallelism.
- Overfitting: Encoder-decoder models are prone to overfitting, especially when trained on small datasets. Solutions include using data augmentation, dropout, and weight decay.
LEARNS.EDU.VN offers resources and support to help you overcome these challenges and build effective encoder-decoder models for your segmentation tasks.
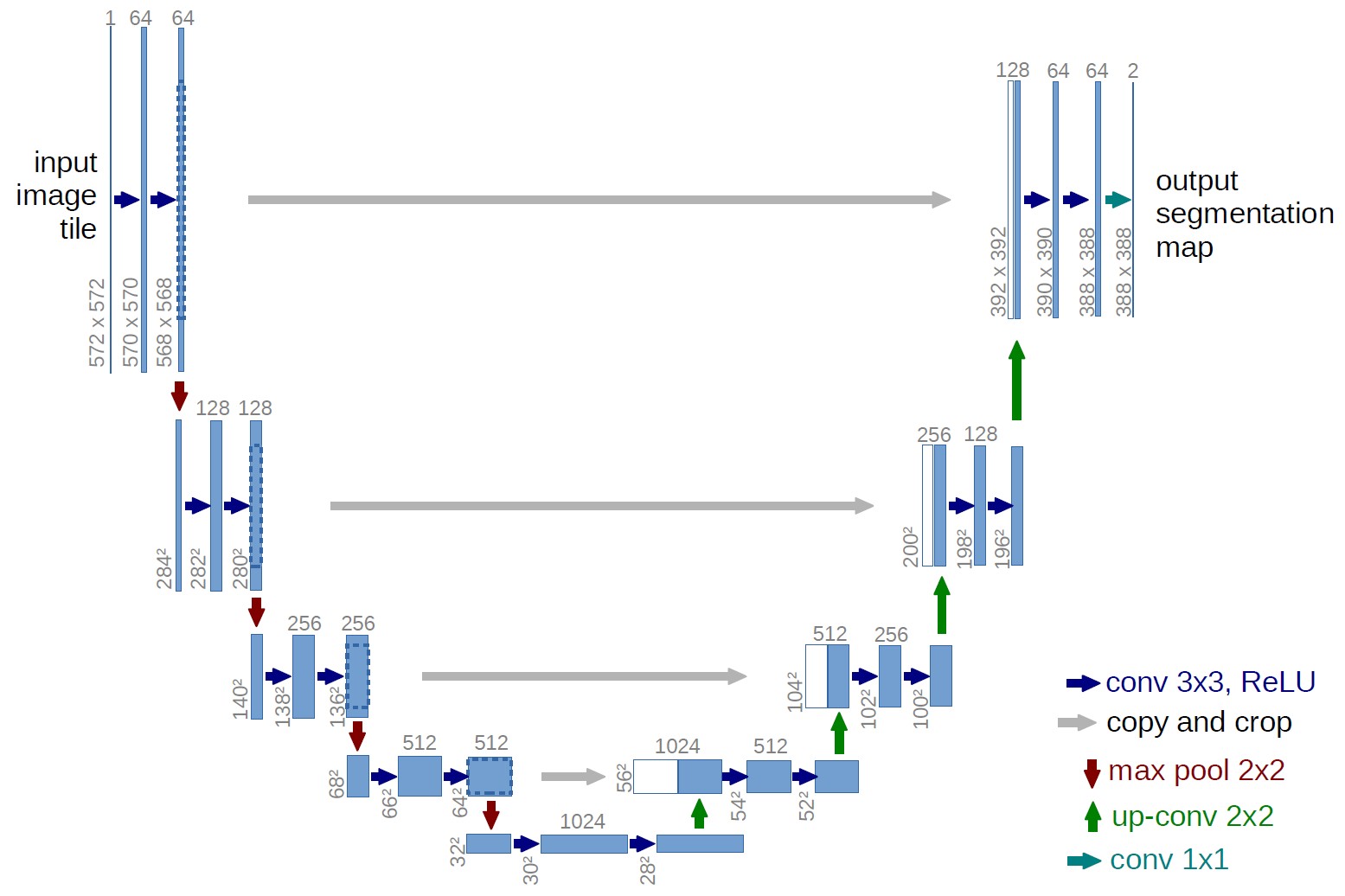 U-Net Architecture
U-Net Architecture
Alt: U-Net architecture showcasing the encoder-decoder structure with skip connections for precise semantic segmentation.
4. Attention Mechanisms for Improved Segmentation
Attention mechanisms have emerged as a powerful tool for improving the performance of deep learning models in various tasks, including semantic segmentation. By allowing the model to focus on the most relevant parts of the input image, attention mechanisms can enhance the accuracy and robustness of segmentation predictions. This section explores the role of attention mechanisms in semantic segmentation, discussing different types of attention and their benefits.
4.1. How Do Attention Mechanisms Work?
Attention mechanisms are designed to mimic the way humans selectively focus on certain parts of a scene while ignoring others. In the context of semantic segmentation, attention mechanisms allow the model to weigh the importance of different regions or features in the image, focusing on the most relevant information for making accurate predictions.
The basic idea behind attention mechanisms is to compute a set of attention weights that indicate the importance of each region or feature. These weights are then used to scale or combine the different parts of the image, allowing the model to focus on the most relevant information.
4.2. Types of Attention Mechanisms
Several types of attention mechanisms have been proposed for semantic segmentation:
- Spatial Attention: Focuses on identifying the most important spatial regions in the image. Spatial attention mechanisms learn to assign higher weights to pixels or regions that are more relevant for the segmentation task.
- Channel Attention: Focuses on identifying the most important feature channels in the network. Channel attention mechanisms learn to assign higher weights to feature channels that contain more relevant information.
- Self-Attention: Allows the model to attend to different parts of the same feature map, capturing long-range dependencies and contextual information.
| Attention Type | Description | Benefits |
|---|---|---|
| Spatial | Focuses on identifying the most important spatial regions in the image, assigning higher weights to pixels or regions that are more relevant for the segmentation task. | Improves accuracy by focusing on relevant regions, enhances robustness to noise and irrelevant information, helps to capture fine-grained details. |
| Channel | Focuses on identifying the most important feature channels in the network, assigning higher weights to feature channels that contain more relevant information. | Improves accuracy by focusing on informative features, enhances robustness to variations in lighting and viewpoint, helps to capture high-level semantic information. |
| Self-Attention | Allows the model to attend to different parts of the same feature map, capturing long-range dependencies and contextual information, enabling the model to understand the relationships between different parts of the image. | Captures long-range dependencies, improves contextual understanding, enhances robustness to occlusions and deformations, provides a more holistic view of the image. |
4.3. Benefits of Using Attention Mechanisms
Attention mechanisms offer several benefits for semantic segmentation:
- Improved Accuracy: By focusing on the most relevant parts of the image, attention mechanisms can improve the accuracy of segmentation predictions.
- Robustness: Attention mechanisms can make the model more robust to noise, occlusions, and variations in lighting and viewpoint.
- Interpretability: Attention weights provide insights into which parts of the image the model is focusing on, making the model more interpretable.
A study by Carnegie Mellon University found that incorporating attention mechanisms into semantic segmentation models can lead to significant improvements in accuracy and robustness, particularly in challenging scenarios.
4.4. Implementing Attention Mechanisms
Implementing attention mechanisms involves several steps:
- Choose an Attention Mechanism: Select an appropriate attention mechanism for the specific segmentation task, considering the trade-offs between accuracy, complexity, and computational cost.
- Integrate Attention into the Network: Incorporate the attention mechanism into the network architecture, typically by adding attention layers after convolutional or recurrent layers.
- Train the Network: Train the network end-to-end, optimizing the attention weights along with the other network parameters.
- Evaluate Performance: Evaluate the performance of the trained network on a held-out validation set, comparing the results with and without attention mechanisms.
LEARNS.EDU.VN provides comprehensive resources and tutorials on implementing various attention mechanisms for semantic segmentation, helping you to unlock their full potential.
Alt: Attention mechanism diagram illustrating how the model focuses on relevant image regions for improved semantic segmentation.
5. Loss Functions for Semantic Segmentation
In semantic segmentation, the choice of a loss function is critical for training effective deep learning models. The loss function quantifies the difference between the predicted segmentation map and the ground truth annotations, guiding the learning process to minimize this discrepancy. This section provides a comprehensive overview of popular loss functions used in semantic segmentation, including their advantages, disadvantages, and best-use cases.
5.1. Common Loss Functions
Several loss functions are commonly used in semantic segmentation:
- Cross-Entropy Loss: Measures the difference between the predicted probability distribution and the true class label for each pixel. It is widely used due to its simplicity and effectiveness.
- Dice Loss: Measures the overlap between the predicted segmentation and the ground truth, focusing on the accuracy of the segmentation boundaries. It is particularly useful when dealing with imbalanced datasets.
- Jaccard Loss: Similar to Dice loss, Jaccard loss measures the intersection over union between the predicted and ground truth segmentation maps.
- Focal Loss: Addresses the issue of class imbalance by assigning higher weights to misclassified examples, helping the model to focus on difficult cases.
| Loss Function | Description | Advantages | Disadvantages |
|---|---|---|---|
| Cross-Entropy | Measures the difference between the predicted probability distribution and the true class label for each pixel, widely used due to its simplicity and effectiveness. | Simple to implement, effective for multi-class segmentation, widely used in various applications. | Sensitive to class imbalance, may not perform well on datasets with a large number of classes. |
| Dice Loss | Measures the overlap between the predicted segmentation and the ground truth, focusing on the accuracy of the segmentation boundaries, particularly useful for imbalanced datasets. | Effective for imbalanced datasets, focuses on segmentation boundaries, robust to small variations in the segmentation map. | May be unstable during training, sensitive to the choice of hyperparameters, requires careful tuning. |
| Jaccard Loss | Measures the intersection over union between the predicted and ground truth segmentation maps, similar to Dice loss but with a different mathematical formulation. | Similar to Dice loss, effective for imbalanced datasets, focuses on segmentation boundaries. | May be unstable during training, sensitive to the choice of hyperparameters, requires careful tuning. |
| Focal Loss | Addresses the issue of class imbalance by assigning higher weights to misclassified examples, helping the model to focus on difficult cases and improve performance. | Effective for class imbalance, focuses on difficult examples, improves overall performance, robust to noisy labels. | May require more training time, sensitive to the choice of hyperparameters, requires careful tuning. |
5.2. Choosing the Right Loss Function
The choice of the loss function depends on the specific characteristics of the segmentation task and the dataset. For example, if the dataset is highly imbalanced, Dice loss or Focal loss may be more appropriate than Cross-Entropy loss. If the goal is to achieve high accuracy on the segmentation boundaries, Dice loss or Jaccard loss may be preferred.
5.3. Hybrid Loss Functions
In some cases, combining multiple loss functions can lead to better results. For example, a hybrid loss function that combines Cross-Entropy loss and Dice loss can balance the need for accurate pixel-wise classification with the need for precise segmentation boundaries.
5.4. Implementing Loss Functions
Implementing loss functions involves defining the mathematical formulation of the loss and computing its value based on the predicted segmentation map and the ground truth annotations. Most deep learning frameworks provide built-in implementations of common loss functions, making it easy to incorporate them into the training pipeline.
LEARNS.EDU.VN offers detailed tutorials and examples on implementing and using various loss functions for semantic segmentation, helping you to optimize your models for the best possible performance.
Alt: A visual representation of different loss functions used in semantic segmentation, illustrating their impact on model training.
6. Datasets for Semantic Segmentation
High-quality datasets are essential for training and evaluating deep learning models for semantic segmentation. These datasets provide labeled images with pixel-wise annotations, allowing models to learn the complex relationships between image pixels and semantic categories. This section provides an overview of popular datasets used in semantic segmentation, including their characteristics, challenges, and best-use cases.
6.1. Popular Datasets
Several datasets are commonly used in semantic segmentation research and applications:
- PASCAL VOC: A widely used dataset for object detection and semantic segmentation, consisting of approximately 11,000 images with 20 object categories.
- Cityscapes: A large-scale dataset for urban scene understanding, consisting of approximately 5,000 finely annotated images and 20,000 coarsely annotated images with 30 object categories.
- ADE20K: A comprehensive dataset for scene parsing, consisting of approximately 20,000 images with 150 object categories.
- COCO: A large-scale dataset for object detection, segmentation, and captioning, consisting of approximately 330,000 images with 80 object categories.
| Dataset | Description | Size | Categories | Use Cases |
|---|---|---|---|---|
| PASCAL VOC | A widely used dataset for object detection and semantic segmentation, consisting of approximately 11,000 images with 20 object categories. | ~11,000 Images | 20 | Object detection, semantic segmentation, model evaluation. |
| Cityscapes | A large-scale dataset for urban scene understanding, consisting of approximately 5,000 finely annotated images and 20,000 coarsely annotated images with 30 object categories. | ~5,000 + 20,000 Images | 30 | Urban scene understanding, autonomous driving, semantic segmentation in urban environments. |
| ADE20K | A comprehensive dataset for scene parsing, consisting of approximately 20,000 images with 150 object categories, enabling detailed scene analysis and understanding. | ~20,000 Images | 150 | Scene parsing, semantic segmentation, detailed scene analysis. |
| COCO | A large-scale dataset for object detection, segmentation, and captioning, consisting of approximately 330,000 images with 80 object categories, supporting versatile model training. | ~330,000 Images | 80 | Object detection, segmentation, captioning, versatile model training. |
6.2. Challenges in Dataset Preparation
Preparing high-quality datasets for semantic segmentation can be challenging due to the need for accurate pixel-wise annotations. Annotating images at the pixel level is a time-consuming and labor-intensive process, requiring specialized tools and expertise. Additionally, dealing with class imbalance and ensuring data diversity are important considerations in dataset preparation.
6.3. Data Augmentation Techniques
To improve the performance and generalization ability of semantic segmentation models, data augmentation techniques are often used to increase the size and diversity of the training dataset. Common data augmentation techniques include:
- Geometric Transformations: Rotating, scaling, and flipping images to create new training examples.
- Color Jittering: Adjusting the brightness, contrast, and saturation of images to simulate different lighting conditions.
- Random Cropping: Cropping random regions of the images to focus on different parts of the scene.
6.4. Using Datasets Effectively
To use datasets effectively for semantic segmentation, it is important to:
- Understand the Dataset: Familiarize yourself with the characteristics of the dataset, including the number of images, the number of object categories, and the quality of the annotations.
- Preprocess the Data: Preprocess the data to ensure that it is in the correct format for training the model. This may involve resizing images, normalizing pixel values, and splitting the dataset into training, validation, and test sets.
- Evaluate Performance: Evaluate the performance of the trained model on a held-out validation set to estimate its generalization ability and identify potential issues such as overfitting.
LEARNS.EDU.VN offers guidance and resources to help you prepare and use datasets effectively for your semantic segmentation projects, ensuring you have the best possible foundation for success.
Alt: An overview of semantic segmentation datasets highlighting the importance of accurate pixel-wise annotations.
7. Evaluation Metrics for Semantic Segmentation
Evaluating the performance of semantic segmentation models requires the use of appropriate metrics that quantify the accuracy and quality of the segmentation predictions. This section provides a comprehensive overview of popular evaluation metrics used in semantic segmentation, including their definitions, advantages, and limitations.
7.1. Common Evaluation Metrics
Several metrics are commonly used to evaluate the performance of semantic segmentation models:
- Pixel Accuracy: Measures the percentage of pixels that are correctly classified. It is a simple and intuitive metric but can be misleading when dealing with imbalanced datasets.
- Intersection-over-Union (IoU): Measures the overlap between the predicted segmentation and the ground truth, providing a more accurate assessment of segmentation quality than pixel accuracy.
- Dice Coefficient: Similar to IoU, Dice coefficient measures the overlap between the predicted and ground truth segmentation maps, with a focus on the accuracy of the segmentation boundaries.
- F1-Score: The harmonic mean of precision and recall, providing a balanced assessment of the model’s ability to correctly identify and segment objects.
| Metric | Description | Advantages | Disadvantages |
|---|---|---|---|
| Pixel Accuracy | Measures the percentage of pixels that are correctly classified, providing a simple and intuitive assessment of overall performance. | Simple and intuitive, easy to compute, provides a general overview of performance. | Can be misleading with imbalanced datasets, does not account for the shape or quality of the segmentation. |
| Intersection-over-Union (IoU) | Measures the overlap between the predicted segmentation and the ground truth, providing a more accurate assessment of segmentation quality than pixel accuracy. | Accounts for the shape and quality of the segmentation, robust to variations in object size and position, widely used in the field. | Can be sensitive to noisy annotations, may not perform well on datasets with a large number of small objects. |
| Dice Coefficient | Measures the overlap between the predicted and ground truth segmentation maps, with a focus on the accuracy of the segmentation boundaries. | Focuses on the accuracy of segmentation boundaries, effective for imbalanced datasets, robust to small variations in the segmentation map. | Can be sensitive to noisy annotations, may not perform well on datasets with a large number of small objects. |
| F1-Score | The harmonic mean of precision and recall, providing a balanced assessment of the model’s ability to correctly identify and segment objects. | Provides a balanced assessment of precision and recall, useful for evaluating models on datasets with varying class distributions. | Can be sensitive to the choice of hyperparameters, may not be as interpretable as other metrics. |
7.2. Interpreting Evaluation Metrics
Interpreting evaluation metrics requires an understanding of their strengths and weaknesses. Pixel accuracy provides a general overview of performance but can be misleading when dealing with imbalanced datasets. IoU and Dice coefficient provide more accurate assessments of segmentation quality, while F1-Score provides a balanced view of precision and recall.
7.3. Using Evaluation Metrics Effectively
To use evaluation metrics effectively, it is important to:
- Choose Appropriate Metrics: Select the metrics that are most relevant for the specific segmentation task and the characteristics of the dataset.
- Compute Metrics on a Held-Out Set: Compute the metrics on a held-out validation set to estimate the generalization ability of the model.
- Compare Models: Use the metrics to compare the performance of different models and identify the best-performing one.
7.4. Visualizing Segmentation Results
In addition to quantitative metrics, visualizing segmentation results can provide valuable insights into the performance of the model. By visually inspecting the predicted segmentation maps and comparing them to the ground truth annotations, it is possible to identify areas where the model is performing well and areas where it is struggling.
LEARNS.EDU.VN offers resources and tutorials on using evaluation metrics effectively and visualizing segmentation results, helping you to gain a deeper understanding of your models and optimize their performance.
Alt: A chart comparing different evaluation metrics for semantic segmentation, emphasizing their relevance and interpretation.
8. Applications of Deep Learning in Semantic Segmentation
Deep learning-based semantic segmentation has a wide range of applications across various industries and domains. Its ability to provide detailed, pixel-level understanding of images makes it invaluable in scenarios requiring precise and accurate image analysis. This section explores some of the key applications of deep learning in semantic segmentation, highlighting their impact and benefits.
8.1. Autonomous Driving
In autonomous driving, semantic segmentation is crucial for understanding the surrounding environment and making informed decisions. By segmenting the road, vehicles, pedestrians, and other objects in the scene, autonomous vehicles can navigate safely and efficiently. Semantic segmentation helps to:
- Identify Road Lanes: Accurately segmenting road lanes allows the vehicle to stay within its designated path.
- Detect Obstacles: Identifying obstacles such as vehicles, pedestrians, and traffic signs helps the vehicle to avoid collisions.
- Understand Traffic Signals: Segmenting traffic lights and signs allows the vehicle to respond appropriately to traffic conditions.
8.2. Medical Imaging
In medical imaging, semantic segmentation is used to analyze medical images such as X-rays, CT scans, and MRI scans. By segmenting organs, tissues, and lesions, medical professionals can diagnose diseases, plan treatments, and monitor patient progress. Semantic segmentation helps to:
- Identify Tumors: Accurately segmenting tumors allows doctors to assess their size, shape, and location.
- Segment Organs: Segmenting organs allows doctors to measure their volume and identify abnormalities.
- Assist in Surgery: Providing real-time segmentation during surgery helps surgeons to navigate and remove diseased tissue.
8.3. Satellite Imagery Analysis
In satellite imagery analysis, semantic segmentation is used to analyze satellite images for various purposes, such as land use mapping, environmental monitoring, and disaster response. By segmenting different types of land cover, such as forests, water bodies, and urban areas, analysts can gain insights into environmental changes and urban development. Semantic segmentation helps to:
- Monitor Deforestation: Identifying and segmenting forests helps to track deforestation rates and assess the impact of logging activities.
- Map Urban Areas: Segmenting urban areas allows planners to monitor urban growth and development.
- Assess Disaster Damage: Identifying damaged buildings and infrastructure helps to assess the impact of natural disasters and coordinate relief efforts.
8.4. Agriculture
In agriculture, semantic segmentation is used to analyze images of crops and fields for various purposes, such as crop monitoring, yield prediction, and disease detection. By segmenting different parts of the plants, such as leaves, stems, and fruits, farmers can gain insights into crop health and productivity. Semantic segmentation helps to:
- Monitor Crop Health: Identifying and segmenting healthy and diseased plants helps to detect diseases early and prevent crop losses.
- Predict Yield: Segmenting fruits and vegetables allows farmers to estimate crop yield and optimize harvesting schedules.
- Optimize Irrigation: Identifying areas with water stress helps to optimize irrigation and conserve water.
learns.edu.vn provides extensive resources and case studies on the applications of deep learning in semantic segmentation, showcasing its transformative potential across various industries.
Alt: Diverse applications of semantic segmentation, including autonomous driving, medical imaging, and satellite imagery analysis.
9. Future Trends in Deep Learning for Semantic Segmentation
The field of deep learning for semantic segmentation is rapidly evolving, with new techniques and architectures emerging constantly. This section explores some of the future trends that are likely to shape the development of semantic segmentation models in