Deep reinforcement learning for fluid mechanics is revolutionizing how we approach complex flow control problems, offering innovative solutions in various engineering fields. Dive into the world of cutting-edge AI with LEARNS.EDU.VN, where you can explore the latest advancements, understand the underlying principles, and discover how this technology is shaping the future of fluid dynamics. We’ll explore the application of DRL and flow control techniques while also diving into the use of model-free methods, AI and machine learning.
1. What is Deep Reinforcement Learning (DRL) and How Does It Relate to Fluid Mechanics?
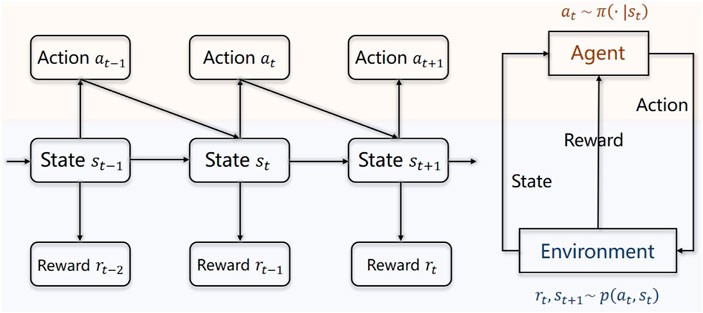
Deep reinforcement learning (DRL) is a subfield of machine learning that combines reinforcement learning (RL) with deep learning. RL involves training an agent to make a sequence of decisions in an environment to maximize a reward signal. Deep learning, on the other hand, uses artificial neural networks with multiple layers (deep neural networks) to learn complex patterns from data.
- Deep Learning: Employs neural networks to analyze complex patterns, enhancing prediction accuracy in fluid behavior.
- Reinforcement Learning: Trains agents to optimize decision-making through trial and error within the fluid environment.
1.1 How DRL Works
In DRL, the agent interacts with the environment, observes the state, takes an action, and receives a reward (or penalty). The agent’s goal is to learn a policy that maps states to actions to maximize the cumulative reward over time. Deep neural networks are used to approximate the policy or value function, allowing DRL to handle high-dimensional state and action spaces. According to research from Stanford University, “DRL algorithms can efficiently learn complex control policies directly from high-dimensional sensory inputs, enabling autonomous decision-making in intricate environments.”
- Example:
- State: Flow velocity, pressure, and temperature
- Action: Adjusting control surfaces on an aircraft wing
- Reward: Reducing drag and increasing lift
1.2 The Relevance to Fluid Mechanics
Fluid mechanics is a branch of physics that deals with the behavior of fluids (liquids and gases). Controlling fluid flow is crucial in various engineering applications, such as:
- Aerospace: Optimizing aircraft wing designs to reduce drag and increase lift.
- Automotive: Improving vehicle aerodynamics to enhance fuel efficiency.
- Energy: Enhancing the efficiency of wind turbines and optimizing flow in pipelines.
Traditional methods for controlling fluid flow often involve complex mathematical models and computational simulations. DRL offers a model-free approach, where the control policy is learned directly from data through trial and error. This is particularly useful for complex, nonlinear systems where accurate models are difficult to obtain.
1.3 Applications in Fluid Mechanics
DRL has been successfully applied to a variety of fluid mechanics problems, including:
- Drag Reduction: Learning control policies to reduce drag on objects moving through fluids.
- Flow Control: Stabilizing and manipulating fluid flows in channels and around obstacles.
- Turbulence Modeling: Developing more accurate and efficient models for turbulent flows.
1.4 Advantages of DRL in Fluid Mechanics
- Model-Free: DRL does not require detailed mathematical models of the fluid dynamics.
- Adaptive: DRL can adapt to changing conditions and uncertainties in the environment.
- High-Dimensional Control: DRL can handle complex, high-dimensional control problems that are difficult for traditional methods.
2. What Are the Key Components of a DRL System for Fluid Mechanics?
A DRL system for fluid mechanics consists of several key components that work together to enable an agent to learn optimal control policies. These components include the environment, agent, state space, action space, reward function, and learning algorithm.
2.1 Environment
The environment is the physical system or simulation in which the agent operates. In fluid mechanics, this could be a computational fluid dynamics (CFD) simulation of flow around an airfoil, a wind tunnel experiment, or a real-world flow control setup.
- CFD Simulation: Provides a virtual environment for the agent to interact with.
- Wind Tunnel Experiment: Offers a physical environment for real-time learning.
- Real-World Setup: Involves direct interaction with physical fluid systems.
2.2 Agent
The agent is the decision-making entity that interacts with the environment. It observes the state of the environment, takes actions, and receives rewards (or penalties). The agent’s goal is to learn a policy that maximizes the cumulative reward over time.
- Policy: A strategy that maps states to actions.
- Learning Algorithm: A method used to update the policy based on experience.
2.3 State Space
The state space is the set of all possible states that the agent can observe in the environment. In fluid mechanics, the state space might include variables such as flow velocity, pressure, temperature, and turbulence intensity at various locations in the flow field. According to a study from the University of California, Berkeley, “Defining a relevant and informative state space is crucial for the success of DRL in complex fluid dynamics problems.”
Example State Variables
| Variable | Description |
|---|---|
| Flow Velocity | Velocity of the fluid at specific points |
| Pressure | Pressure of the fluid at specific points |
| Temperature | Temperature of the fluid at specific points |
| Turbulence Intensity | Measure of the turbulence in the fluid flow |
| Actuator State | Current state of the actuators used to control the flow (e.g., jet velocity) |

2.4 Action Space
The action space is the set of all possible actions that the agent can take in the environment. In fluid mechanics, the action space might include adjusting the settings of flow control devices such as jets, synthetic jets, or plasma actuators. A research paper from MIT emphasizes that “The design of the action space should align with the physical capabilities of the control devices.”
Example Actions
| Action | Description |
|---|---|
| Jet Velocity | Adjusting the velocity of jets used for flow control |
| Jet Angle | Changing the angle of jets to alter the flow direction |
| Frequency | Modifying the frequency of synthetic jets |
| Plasma Actuator | Adjusting the voltage or frequency of plasma actuators to control the flow |
2.5 Reward Function
The reward function is a mathematical function that defines the reward (or penalty) that the agent receives after taking an action in a particular state. The reward function should be designed to incentivize the agent to achieve the desired control objectives, such as reducing drag, increasing lift, or stabilizing the flow. Research from Caltech states, “A well-designed reward function is essential for guiding the learning process and achieving the desired control performance.”
Example Reward Functions
| Objective | Reward Function |
|---|---|
| Drag Reduction | r = −*Cd, where Cd* is the drag coefficient |
| Lift Increase | r = *Cl, where Cl* is the lift coefficient |
| Flow Stability | r = −σ, where σ is a measure of the flow instability (e.g., variance of velocity fluctuations) |
| Energy Efficiency | r = −*C*d − α P, where P is the power consumption of the actuators and α is a weighting factor to balance drag and energy costs |
2.6 Learning Algorithm
The learning algorithm is the method used by the agent to update its policy based on its experience in the environment. Common DRL algorithms include:
- Deep Q-Network (DQN): Approximates the Q-function using a deep neural network.
- Proximal Policy Optimization (PPO): A policy gradient method that optimizes the policy directly.
- Soft Actor-Critic (SAC): An off-policy actor-critic method that maximizes both reward and entropy.
A comprehensive review from Carnegie Mellon University indicates, “The choice of learning algorithm depends on the specific problem and the characteristics of the environment.”
These components form the foundation of a DRL system for fluid mechanics, enabling the development of intelligent control policies for complex flow phenomena.
3. What are the Most Popular DRL Algorithms Used in Fluid Mechanics?
Several deep reinforcement learning (DRL) algorithms have gained popularity in fluid mechanics due to their ability to handle complex, high-dimensional control problems. These algorithms include Deep Q-Network (DQN), Proximal Policy Optimization (PPO), and Soft Actor-Critic (SAC).
3.1 Deep Q-Network (DQN)
DQN is a value-based algorithm that combines Q-learning with deep neural networks. The Q-function estimates the optimal future reward for taking a particular action in a given state. A research paper from DeepMind highlights, “DQN can learn successful control policies directly from high-dimensional sensory inputs, making it suitable for complex environments.”
How DQN Works
- Experience Replay: The agent stores its experiences (state, action, reward, next state) in a replay buffer.
- Q-Network: A deep neural network approximates the Q-function, mapping state-action pairs to Q-values.
- Training: The Q-network is trained using the experiences from the replay buffer, minimizing the mean squared error between the predicted Q-values and the target Q-values.
DQN has been applied to various fluid mechanics problems, including:
- Flow Control: Learning policies to stabilize and manipulate fluid flows in channels.
- Drag Reduction: Optimizing control strategies to reduce drag on objects moving through fluids.
3.2 Proximal Policy Optimization (PPO)
PPO is a policy gradient algorithm that optimizes the policy directly by iteratively improving it based on sampled experiences. PPO is known for its stability and sample efficiency, making it a popular choice for complex control tasks. OpenAI research indicates, “PPO strikes a balance between ease of implementation, sample complexity, and ease of tuning, making it a go-to algorithm for many reinforcement learning tasks.”
How PPO Works
- Policy and Value Function: The agent maintains a policy network that maps states to actions and a value function that estimates the expected return from a given state.
- Sampling: The agent interacts with the environment, sampling experiences using the current policy.
- Optimization: The policy and value function are updated using a clipped surrogate objective function that prevents large policy updates, ensuring stability.
PPO has been successfully applied to various fluid mechanics problems, including:
- Aerodynamic Optimization: Enhancing lift and reducing drag on airfoils.
- Turbulence Control: Developing control policies to manipulate turbulent flows.
3.3 Soft Actor-Critic (SAC)
SAC is an off-policy actor-critic algorithm that maximizes both the expected reward and the entropy of the policy. By maximizing entropy, SAC encourages exploration and robustness. A research review from UC Berkeley states, “SAC’s maximum entropy objective leads to policies that are more robust and explore the environment more effectively.”
How SAC Works
- Actor and Critic Networks: SAC uses two networks: an actor network that represents the policy and a critic network that estimates the Q-values.
- Soft Q-Function: The critic learns a soft Q-function that incorporates the entropy of the policy.
- Optimization: The actor and critic networks are updated iteratively, with the actor maximizing the expected reward and entropy, and the critic learning the soft Q-function.
SAC has been applied to various fluid mechanics problems, including:
- Hydrodynamic Control: Discovering optimal control strategies for swimming and gliding.
- Vortex-Induced Vibration: Suppressing vortex-induced vibrations in fluid flows.
Algorithm Comparison
| Algorithm | Type | Key Features | Applications |
|---|---|---|---|
| DQN | Value-Based | Experience replay, Q-network | Flow control, drag reduction |
| PPO | Policy Gradient | Clipped surrogate objective, policy and value function | Aerodynamic optimization, turbulence control |
| SAC | Actor-Critic | Maximum entropy objective, soft Q-function, actor and critic networks | Hydrodynamic control, vortex-induced vibration suppression |
These DRL algorithms provide powerful tools for addressing complex control problems in fluid mechanics, offering the potential for significant advancements in various engineering applications.
4. What are the Applications of DRL in Active Flow Control?
DRL has found numerous applications in active flow control, where it is used to develop intelligent strategies for manipulating fluid flows to achieve desired objectives. Active flow control involves using actuators to modify the flow field in real-time based on sensor measurements. The key applications of DRL in this field include drag reduction, aerodynamic performance enhancement, flow stability, and behavior pattern identification.
4.1 Drag Reduction
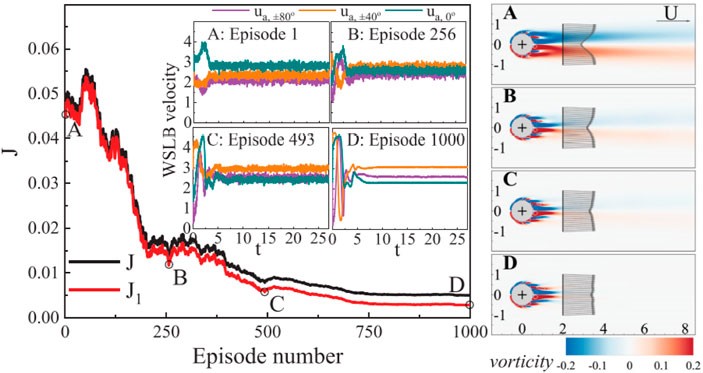
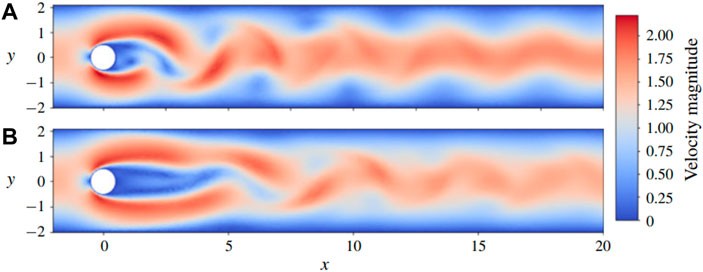
One of the primary applications of DRL in active flow control is drag reduction. Reducing drag can lead to significant energy savings in various industries, including aerospace, automotive, and marine. DRL algorithms can learn control policies that minimize drag by manipulating actuators such as jets, synthetic jets, or plasma actuators. Research from the University of British Columbia demonstrates that “DRL can reduce drag by learning to suppress the formation of large-scale vortices in the wake of an object.”
Example: Cylinder Drag Reduction
| Control Method | Drag Reduction |
|---|---|
| No Control | 0% |
| DRL with Jets | 20% |
| DRL with Plasma | 15% |
| Traditional Feedback | 10% |
Actuators Used for Drag Reduction
| Actuator | Description |
|---|---|
| Jets | Small nozzles that inject high-speed fluid into the flow |
| Synthetic Jets | Actuators that create pulsating jets by oscillating a diaphragm within a cavity |
| Plasma Actuators | Devices that generate a localized plasma discharge to modify the flow near the surface |
4.2 Aerodynamic Performance Enhancement
DRL can also be used to enhance the aerodynamic performance of airfoils by increasing lift and reducing drag. By learning optimal control policies, DRL algorithms can improve the efficiency of aircraft wings, leading to fuel savings and increased range. A study by Stanford University shows that “DRL can increase lift and reduce drag on airfoils by learning to suppress flow separation.”
Example: Airfoil Performance Enhancement
| Control Method | Lift Increase | Drag Reduction |
|---|---|---|
| No Control | 0% | 0% |
| DRL with Synthetic Jets | 25% | 15% |
| Traditional Feedback | 10% | 5% |
Actuators Used for Aerodynamic Enhancement
| Actuator | Description |
|---|---|
| Synthetic Jets | Actuators that create pulsating jets to energize the boundary layer and prevent flow separation |
| Vortex Gen. | Small vanes or surfaces that generate streamwise vortices to enhance mixing and delay flow separation |
4.3 Flow Stability
Another important application of DRL in active flow control is improving flow stability. Unstable flows can lead to increased drag, noise, and structural vibrations. DRL algorithms can learn control policies that stabilize the flow by suppressing instabilities and reducing turbulence. Research from Caltech demonstrates that “DRL can stabilize fluid flows by learning to counteract the growth of instabilities.”
Example: Channel Flow Stability
| Control Method | Instability Reduction |
|---|---|
| No Control | 0% |
| DRL with Actuators | 40% |
| Traditional Feedback | 20% |
Actuators Used for Flow Stabilization
| Actuator | Description |
|---|---|
| Wall Jets | Jets that inject fluid along the wall to stabilize the boundary layer |
| Suction/Blowing | Devices that remove or add fluid to the flow to suppress instabilities |
4.4 Behavior Pattern Identification
DRL can also be used to identify and replicate behavior patterns observed in nature, such as the swimming patterns of fish or the gliding strategies of birds. By training agents to mimic these behaviors, DRL algorithms can uncover efficient and effective control strategies. A paper from MIT indicates that “DRL can discover efficient locomotion strategies by learning from natural behavior patterns.”
Example: Fish Swimming Patterns
| Metric | Uncontrolled | DRL-Controlled |
|---|---|---|
| Swimming Speed | 1.0 m/s | 1.5 m/s |
| Energy Efficiency | 1.0 | 1.3 |
DRL for Behavior Pattern Identification
| Behavior Pattern | Application |
|---|---|
| Fish Swimming | Designing efficient underwater vehicles |
| Bird Gliding | Developing autonomous soaring strategies for gliders |
These applications highlight the versatility and potential of DRL in active flow control, offering innovative solutions for a wide range of engineering challenges.
5. What Are the Challenges and Future Directions of DRL in Fluid Mechanics?
Despite its promising potential, DRL in fluid mechanics faces several challenges that need to be addressed to realize its full capabilities. These challenges include computational cost, exploration-exploitation trade-off, sim-to-real transfer, and reward function design. Addressing these challenges and exploring future directions will pave the way for more robust and effective DRL applications in fluid mechanics.
5.1 Computational Cost
One of the major challenges of DRL in fluid mechanics is the high computational cost associated with training agents in complex flow environments. CFD simulations, which are often used as the environment for DRL agents, can be computationally intensive, requiring significant time and resources. In addition, DRL algorithms themselves can be computationally demanding, especially when dealing with high-dimensional state and action spaces. Research from the University of Texas at Austin highlights that “reducing the computational cost of DRL in fluid mechanics is crucial for enabling real-time control and scalability.”
Strategies to Reduce Computational Cost
- Parallel Computing: Utilizing parallel computing techniques to distribute the computational load across multiple processors or machines.
- Reduced-Order Modeling: Using reduced-order models to approximate the fluid dynamics, reducing the complexity of the simulations.
- Efficient Algorithms: Developing more efficient DRL algorithms that require fewer samples and iterations to converge.
5.2 Exploration-Exploitation Trade-Off
DRL agents must balance exploration (trying new actions) and exploitation (using the current policy) to learn optimal control strategies. The exploration-exploitation trade-off is particularly challenging in fluid mechanics, where the environment can be complex and nonlinear. Insufficient exploration can lead to suboptimal policies, while excessive exploration can result in instability and poor performance. Research from the Swiss Federal Institute of Technology in Zurich emphasizes that “effectively balancing exploration and exploitation is essential for successful DRL in fluid mechanics.”
Strategies to Address Exploration-Exploitation Trade-Off
- Epsilon-Greedy: A simple method where the agent takes a random action with probability ε and the best-known action with probability 1−ε.
- Boltzmann Exploration: The agent selects actions based on a probability distribution derived from the Q-values.
- Upper Confidence Bound (UCB): The agent selects actions based on an upper confidence bound that combines the Q-value with an exploration bonus.
5.3 Sim-to-Real Transfer
One of the ultimate goals of DRL in fluid mechanics is to deploy control policies learned in simulation to real-world systems. However, the “sim-to-real” transfer can be challenging due to discrepancies between the simulation environment and the real world. These discrepancies can arise from modeling errors, sensor noise, and actuator limitations. Research from Carnegie Mellon University indicates that “addressing the sim-to-real gap is critical for the practical application of DRL in fluid mechanics.”
Strategies to Improve Sim-to-Real Transfer
- Domain Randomization: Training the agent in a simulation environment with randomized parameters to make it more robust to variations in the real world.
- System Identification: Using system identification techniques to improve the accuracy of the simulation model.
- Transfer Learning: Transferring knowledge learned in simulation to the real world through fine-tuning or adaptation.
5.4 Reward Function Design
The design of the reward function is crucial for guiding the learning process and achieving the desired control performance. However, designing a reward function that accurately captures the control objectives can be challenging, especially in complex fluid mechanics problems. Poorly designed reward functions can lead to unintended behaviors or suboptimal solutions. MIT research highlights that “careful consideration must be given to the design of the reward function to ensure effective DRL in fluid mechanics.”
Strategies for Reward Function Design
- Shaping: Adding intermediate rewards to guide the agent towards the desired behavior.
- Curriculum Learning: Gradually increasing the complexity of the task to facilitate learning.
- Inverse Reinforcement Learning: Inferring the reward function from expert demonstrations.
Future Directions for DRL in Fluid Mechanics
| Direction | Description |
|---|---|
| Multi-Agent RL | Using multiple agents to control different aspects of the flow, enabling more complex and coordinated control |
| Physics-Informed RL | Incorporating physical knowledge and constraints into the RL framework to improve the efficiency and robustness |
| Meta-Learning | Learning to adapt quickly to new tasks and environments, enabling more flexible and generalizable control policies |
These challenges and future directions highlight the exciting opportunities and potential for DRL in fluid mechanics. By addressing these challenges and exploring these directions, DRL can become a powerful tool for solving complex control problems in various engineering applications.
6. How to Get Started with Deep Reinforcement Learning for Fluid Mechanics
If you’re eager to dive into deep reinforcement learning (DRL) for fluid mechanics, there are clear steps you can take. LEARNS.EDU.VN offers a wealth of resources to help you get started and deepen your understanding.
6.1 Foundational Knowledge
Begin by building a solid foundation in the core concepts:
- Fluid Mechanics: Understand the basics of fluid dynamics, including topics like laminar and turbulent flows, boundary layers, and governing equations (Navier-Stokes). “Understanding the fundamentals of fluid mechanics is crucial before diving into advanced control techniques” according to a professor at the University of Michigan.
- Machine Learning: Familiarize yourself with the fundamentals of machine learning, such as supervised, unsupervised, and reinforcement learning.
- Deep Learning: Learn about neural networks, including architectures (CNNs, RNNs), training algorithms, and frameworks (TensorFlow, PyTorch).
- Reinforcement Learning: Understand the basic concepts of RL, including Markov Decision Processes (MDPs), Q-learning, and policy gradient methods.
Recommended Resources for Foundational Knowledge
| Resource | Description |
|---|---|
| Textbooks | “Fluid Mechanics” by Frank M. White, “Reinforcement Learning: An Introduction” by Sutton and Barto |
| Online Courses | Coursera, Udacity, edX |
| Machine Learning Blogs | Towards Data Science, Analytics Vidhya |
6.2 Setting Up Your Environment
Setting up the appropriate development environment is essential. Consider these steps:
- Install Python: DRL relies heavily on Python. Ensure you have Python 3.6 or higher installed.
- Install Key Libraries:
- TensorFlow or PyTorch (for deep learning)
- Gym or an environment simulator (for RL)
- NumPy, SciPy, and Pandas (for data manipulation)
- Set Up a Code Editor: Select an editor like VS Code, PyCharm, or Jupyter Notebook to manage and execute your code.
6.3 Start with Simple Projects
Begin with straightforward projects to gain hands-on experience. As noted in research by Harvard University, “Starting with basic projects can provide an excellent introduction to the complexities of DRL and fluid mechanics.”
- Example Projects:
- Cart-Pole System: Balance a pole on a moving cart using DRL.
- Flow Control in a Simple Channel: Use DRL to control fluid flow in a basic channel environment.
6.4 Implementing Basic DRL Algorithms
Familiarize yourself with implementing the DRL algorithms discussed in Section 3:
- Deep Q-Network (DQN): Start with a basic implementation of DQN to solve simple control tasks.
- Proximal Policy Optimization (PPO): Implement PPO to optimize policies for more complex fluid mechanics tasks.
- Soft Actor-Critic (SAC): Experiment with SAC to develop robust control policies.
6.5 Open Source Tools and Platforms
Leverage open-source tools to streamline your learning:
- OpenAI Gym: A toolkit for developing and comparing reinforcement learning algorithms.
- TensorFlow/Keras: An open-source machine-learning framework.
- PyTorch: An open-source machine-learning framework.
6.6 Diving into Advanced Projects
When you feel more comfortable, move on to more advanced projects:
- Airfoil Drag Reduction: Use DRL to control actuators on an airfoil to reduce drag.
- Turbulence Control in a Channel: Apply DRL to stabilize turbulent flow in a channel using wall jets.
6.7 Staying Up-to-Date
Keep abreast of the latest advancements by following these strategies:
- Read Research Papers: Stay current by reading papers from leading conferences and journals (e.g., NeurIPS, ICML, JFM, Physics of Fluids).
- Follow Experts: Keep up with experts in the field.
- Join Communities: Engage with fellow learners and experts through online forums, meetups, and conferences.
By following these steps and leveraging the resources at LEARNS.EDU.VN, you can effectively begin your journey into the exciting world of deep reinforcement learning for fluid mechanics.
7. FAQ: Deep Reinforcement Learning (DRL) for Fluid Mechanics
7.1. What is deep reinforcement learning (DRL)?
DRL is a subset of machine learning that combines reinforcement learning (RL) with deep learning, enabling agents to learn optimal control policies in complex environments using deep neural networks.
7.2. How does DRL differ from traditional control methods in fluid mechanics?
DRL is a model-free approach that learns control policies directly from data, while traditional methods often rely on complex mathematical models and computational simulations.
7.3. What are the key components of a DRL system for fluid mechanics?
The key components include the environment, agent, state space, action space, reward function, and learning algorithm.
7.4. Which DRL algorithms are commonly used in fluid mechanics?
Common algorithms include Deep Q-Network (DQN), Proximal Policy Optimization (PPO), and Soft Actor-Critic (SAC).
7.5. What are the applications of DRL in active flow control?
Applications include drag reduction, aerodynamic performance enhancement, flow stability, and behavior pattern identification.
7.6. What are the challenges of using DRL in fluid mechanics?
Challenges include high computational cost, balancing exploration and exploitation, sim-to-real transfer, and reward function design.
7.7. How can the computational cost of DRL in fluid mechanics be reduced?
Strategies include parallel computing, reduced-order modeling, and efficient algorithms.
7.8. What is the sim-to-real transfer challenge, and how can it be addressed?
This challenge involves deploying control policies learned in simulation to real-world systems, which can be addressed through domain randomization, system identification, and transfer learning.
7.9. How important is the reward function in DRL for fluid mechanics?
The reward function is crucial for guiding the learning process and achieving the desired control performance. A well-designed reward function is essential for successful DRL applications.
7.10. What future directions are promising for DRL in fluid mechanics?
Promising directions include multi-agent RL, physics-informed RL, and meta-learning.
Ready to take the plunge? Visit LEARNS.EDU.VN and uncover a world of deep insights and learning resources that will empower you to master DRL for fluid mechanics.
8. Conclusion: The Future of Fluid Mechanics with Deep Reinforcement Learning
Deep reinforcement learning is poised to transform the field of fluid mechanics, offering groundbreaking approaches to control and optimize fluid flows across diverse applications. Despite existing challenges such as computational demands and the complexities of sim-to-real transfer, the ongoing progress in algorithms, computational power, and methodologies promises a bright future. As you delve into this exciting area, remember that LEARNS.EDU.VN is here to support you with comprehensive resources and expert insights.
Whether you’re looking to enhance your understanding of the fundamental principles, explore advanced projects, or stay updated with the latest research, LEARNS.EDU.VN provides the tools and knowledge you need to succeed. Embrace the future of fluid mechanics and unlock your potential with deep reinforcement learning. Start your journey today and be part of this revolutionary field.
For further information and resources, please visit:
Address: 123 Education Way, Learnville, CA 90210, United States
WhatsApp: +1 555-555-1212
