A/b Testing In Machine Learning is a powerful method for comparing different models and strategies to optimize performance, and at LEARNS.EDU.VN, we provide detailed guides and resources to help you master this technique. By understanding the nuances of A/B testing, you can make data-driven decisions that enhance your machine learning projects. Discover the advantages of split testing, multivariate testing, and conversion rate optimization by diving into our rich collection of articles and courses.
1. What Is A/B Testing in Machine Learning?
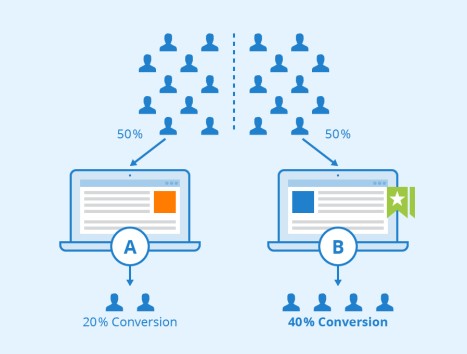
A/B testing, also known as split testing or bucket testing, in machine learning is a statistical method used to compare two versions of a model or strategy against each other to determine which one performs better. In its simplest form, A/B testing involves randomly assigning subjects to two groups: a control group (A) and a treatment group (B). The control group is exposed to the existing version (the champion), while the treatment group is exposed to the new version (the challenger). By measuring and comparing the performance of each group, data scientists can make informed decisions about which version to implement.
A/B testing helps organizations to make data-driven decisions by experiment and iteration in order to improve their business continually.
1.1. The Historical Roots of A/B Testing
The concept of A/B testing is not new. Its origins can be traced back to agricultural experiments where farmers divided their fields to test different treatments and improve crop yields. One of the earliest documented experiments resembling A/B testing appears in the Old Testament, where a nutrition test was conducted (Daniel 1:12-13).
“Please test your servants for ten days. Let us be given vegetables to eat and water to drink. You can then compare our appearance with the appearance of the young men who eat the royal rations…” (Daniel 1:12-13)
In 1747, Dr. James Lind conducted a clinical trial to test the effectiveness of citrus fruits in curing scurvy.
1.2. Modern Applications of A/B Testing
Today, A/B testing is a key business tool used in various fields, including product pricing, website design, marketing campaigns, and brand messaging. In data science, A/B tests are used to compare the performance of different models in real-world scenarios. The existing model is known as the “champion,” while the new model being tested is called the “challenger.”
1.3. Distinguishing A/B Testing from Hyperparameter Optimization
In machine learning, the terms “experiments” and “trials” often refer to finding the best training configuration for a problem, which is known as hyperparameter optimization. In contrast, A/B testing compares the performance of different models in production environments. This article focuses on the use of A/B tests to evaluate model performance in real-world conditions.
2. Key Components of Designing a Machine Learning A/B Test
Designing an effective A/B test involves several critical decisions that ensure the results are reliable and meaningful. Here are the key components to consider:
2.1. Defining the Overall Evaluation Criterion (OEC)
The first step in designing an A/B test is to define what you are trying to measure. This is known as the Overall Evaluation Criterion (OEC). The OEC should be business-focused and measurable. Common examples include:
- Revenue
- Click-Through Rate (CTR)
- Conversion Rate
- Process Completion Rate
The OEC should align with the business goals and provide a clear metric for evaluating the success of the challenger model.
2.2. Determining the Minimum Delta Effect Size
Next, you need to determine how much better the challenger model needs to be to be considered a winner. Simply stating that the challenger should be “better” is not sufficient for statistical testing. Define two key quantities:
- y0: The champion’s assumed OEC. This is the baseline performance of the existing model.
- δ: The minimum delta effect size that you want to reliably detect. This is the minimum improvement required for the challenger to be declared the winner.
For example, if the champion’s conversion rate is 2% (y0 = 0.02) and you want the challenger to improve the conversion rate by at least 1%, then the challenger needs to achieve a conversion rate of 2.02%. In this case, δ = 0.002.
It’s important to note whether sample size calculators specify minimum effect size as a relative delta or an absolute delta. In the example above, the relative delta is 1%, while the absolute delta is 0.002.
2.3. Setting Error Tolerance Levels
Error tolerance is another critical aspect of A/B testing. You need to decide how much error you are willing to tolerate. The less error you tolerate, the more data you will need, and the longer the test will run. The key parameters for describing error are:
- α: The significance level, or false positive rate, that you are willing to tolerate. This is typically set to 0.05, meaning that you are willing to incorrectly pick an inferior challenger 5% of the time.
- β: The power, or true positive rate, that you want to achieve. This is typically set to 0.8, meaning that you want to correctly pick a superior challenger 80% of the time.
α and β represent incompatible circumstances; α assumes the challenger is worse, while β assumes it is better. The goal of the A/B test is to determine which situation you are in.
2.4. Calculating the Minimum Sample Size (n)
The final parameter in an A/B test is the minimum number of examples (n) needed to ensure that the false positive rate (α) and true positive rate (β) thresholds are met. This ensures that the results achieve statistical significance.
Note that n is per model. If you are routing traffic between A and B with a 50-50 split, the total experiment size is 2*n. If you are routing 90% of traffic to A and 10% to B, then B must see at least n customers, and A will see around 9*n. A 50-50 split is the most efficient, but unbalanced splits may be preferred for safety or stability reasons.
To determine n, you can use power calculators or sample-size calculators. For example, Statsig offers a calculator for rates that defaults to α = 0.05, β = 0.8, and a split ratio of 50-50.
2.5. Determining the Winner
Once you have run the A/B test long enough to achieve the necessary n, measure the OEC for each model. If OECchallenger – OECchampion > δ, then the challenger wins. Otherwise, stick with the champion model.
3. Practical Considerations for Implementing A/B Tests
Implementing A/B tests in real-world scenarios requires careful attention to several practical considerations. These include ensuring randomness, avoiding biases, and maintaining consistency.
3.1. Splitting Subjects Randomly
When splitting subjects between models, ensure the process is truly random. Any bias in group assignments can invalidate the results. Consider potential interference between the two groups. Do they communicate or influence each other in any way? Also, make sure the randomization method does not introduce unintended biases.
3.2. Running A/A Tests
It is a good practice to run A/A tests, where both groups are control or treatment groups. This helps surface unintentional biases or errors in processing and provides a better understanding of how random variations can affect intermediate results.
3.3. Avoiding Premature Conclusions
Resist the temptation to peek at the results early and draw conclusions or stop the experiment before the minimum sample size is reached. The “wrong” model may get lucky for a while. Run the test long enough to be confident that the observed behavior is representative and not just a fluke.
3.4. Understanding Test Sensitivity
The resolution of an A/B test (how small a delta effect size you can detect) increases as the square root of the sample size. To halve the delta effect size you can detect, you must quadruple your sample size.
4. Advanced A/B Testing Techniques
Beyond the classical A/B testing approach, there are advanced techniques that can provide deeper insights and more efficient experimentation.
4.1. Bayesian A/B Tests
The classical, or frequentist, approach to A/B testing can be unintuitive for some people. The definitions of α and β assume that you run the A/B test repeatedly, but in practice, you usually run it only once. The Bayesian approach takes the data from a single run as a given and asks, “What OEC values are consistent with what I’ve observed?”
The general steps for a Bayesian analysis are:
- Specify Prior Beliefs: Define prior beliefs about possible values of the OEC for the experiment groups. For example, conversion rates for both groups are different and both between 0 and 10%.
- Define a Statistical Model: Use a Bayesian analysis tool and flat, uninformative, or equal priors for each group.
- Collect Data and Update Beliefs: Update the beliefs on possible values for the OEC parameters as you collect data. The distributions of possible OEC parameters start out encompassing a wide range of possible values, and as the experiment continues, the distributions tend to narrow and separate if there is a difference.
- Continue the Experiment: Continue the experiment as long as it seems valuable to refine the estimates of the OEC. From the posterior distributions of the effect sizes, it is possible to estimate the delta effect size.
A Bayesian approach does not necessarily make the test shorter but makes quantifying the uncertainties in the experiment more straightforward and intuitive.
4.2. Multi-Armed Bandits
If you want to minimize waiting until the end of an experiment before taking action, consider Multi-Armed Bandit approaches. Multi-armed bandits dynamically adjust the percentage of new requests that go to each option based on that option’s past performance. The better a model performs, the more traffic it gets, but some small amount of traffic still goes to poorly performing models, allowing the experiment to continue collecting information.
This balances the trade-off between exploitation (extracting maximal value by using models that appear to be the best) and exploration (collecting information about other models in case they turn out to be better than they currently appear). If a multi-armed bandit experiment is run long enough, it will eventually converge to the best model, if one exists.
Multi-armed bandit tests can be useful if you cannot run a test long enough to achieve statistical significance. The exploitation-exploration tradeoff means that you potentially gain more value during the experiment than you would have running a standard A/B test.
5. A/B Testing in Production with Wallaroo
Once you have designed your A/B test, the Wallaroo ML deployment platform can help you get it up and running quickly and easily. The platform provides specialized pipeline configurations for setting up production experiments, including A/B tests. All the models in an experimentation pipeline receive data via the same endpoint; the pipeline allocates the requests to each of the models as desired.
5.1. Random Split Experimentation
Requests can be allocated in several ways. For an A/B test, you would use random split. In this allocation scheme, requests are distributed randomly in the proportions you specify: 50-50, 80-20, or whatever is appropriate. If session information is provided, the pipeline ensures that it is respected. Customer ID information can be used to ensure that a specific customer always sees the output from the same model.
5.2. Tracking and Calculating OECs
The Wallaroo pipeline keeps track of which requests have been routed to each model and the resulting inferences. This information can then be used to calculate OECs to determine each model’s performance.
6. Other Types of Experiments in Wallaroo
Wallaroo experimentation pipelines allow other kinds of experiments to be run in production.
6.1. Key Split Experimentation
With key split, requests are distributed according to the value of a key or query attribute. For example, in a credit card company scenario, gold card customers might be routed to model A, platinum cardholders to model B, and all other cardholders to model C. This is not a good way to split for A/B tests but can be useful for other situations, such as a slow rollout of a new model.
6.2. Shadow Deployments
With shadow deployments, all the models in the experiment pipeline get all the data, and all inferences are logged. However, the pipeline only outputs the inferences from one model—the default, or champion model.
Shadow deployments are useful for “sanity checking” a model before it goes truly live. For example, you might have built a smaller, leaner version of an existing model using knowledge distillation or other model optimization techniques. A shadow deployment of the new model alongside the original model can help ensure that the new model meets desired accuracy and performance requirements before it’s put into production.
A/B tests and other types of experimentation are part of the ML lifecycle. The ability to quickly experiment and test new models in the real world helps data scientists to continually learn, innovate, and improve AI-driven decision processes.
7. How Can I Ensure My A/B Tests Are Effective?
To ensure your A/B tests are effective, it’s crucial to adhere to statistical best practices and avoid common pitfalls. Here are some key guidelines:
- Define Clear Objectives: Clearly define the goals of your A/B test, including the specific metrics you intend to measure.
- Random Assignment: Ensure that subjects are randomly assigned to either the control or treatment group to avoid selection bias.
- Sufficient Sample Size: Calculate the appropriate sample size required to achieve statistical significance based on your desired power and significance levels.
- Control for Confounding Variables: Identify and control for any confounding variables that could influence the results of your A/B test.
- Monitor Test Progress: Continuously monitor the progress of your A/B test to ensure that data is being collected correctly and that no unexpected issues arise.
- Proper Statistical Analysis: Use appropriate statistical methods to analyze the data collected during your A/B test and draw valid conclusions.
- Document Everything: Keep detailed records of all aspects of your A/B test, including the experimental design, data collection procedures, and statistical analysis.
7.1. Ensuring Statistical Significance
Statistical significance is a critical concept in A/B testing. It refers to the probability that the observed difference between the control and treatment groups is not due to random chance. In other words, it indicates whether the results of your A/B test are likely to be real and not just a fluke.
To determine statistical significance, you need to calculate a p-value. The p-value represents the probability of observing the results you obtained if there is no real difference between the control and treatment groups. A p-value of 0.05 or less is typically considered statistically significant, meaning that there is a less than 5% chance that the observed difference is due to random chance.
7.2. Addressing Common Pitfalls in A/B Testing
Despite its simplicity, A/B testing is subject to several potential pitfalls that can compromise the validity of the results. Here are some common mistakes to avoid:
- Insufficient Sample Size: Running an A/B test with too small of a sample size can lead to statistically insignificant results, making it difficult to draw any meaningful conclusions.
- Selection Bias: Non-random assignment of subjects to the control and treatment groups can introduce selection bias, skewing the results of your A/B test.
- Multiple Testing: Conducting multiple A/B tests simultaneously or performing multiple analyses on the same dataset can increase the risk of false positives, leading to incorrect conclusions.
- Ignoring External Factors: Failing to account for external factors that could influence the results of your A/B test, such as seasonality or marketing campaigns, can lead to inaccurate conclusions.
- Premature Termination: Stopping an A/B test before reaching statistical significance can result in misleading results and incorrect decisions.
- Over-Optimization: Over-optimizing your models or strategies based on the results of a single A/B test can lead to overfitting, reducing the generalizability of your findings.
8. Leveraging A/B Testing for Machine Learning Model Optimization
A/B testing is an essential tool for optimizing machine learning models and improving their performance in real-world scenarios. By conducting rigorous A/B tests, data scientists can identify the most effective model configurations, refine model parameters, and enhance overall model accuracy. Here are some ways to leverage A/B testing for machine learning model optimization:
- Model Selection: Use A/B testing to compare the performance of different machine learning models and select the one that performs best for your specific task.
- Feature Engineering: Experiment with different feature engineering techniques and use A/B testing to determine which features contribute most to model accuracy.
- Hyperparameter Tuning: Optimize model hyperparameters by conducting A/B tests to identify the parameter values that yield the best performance.
- Algorithm Selection: Compare different machine learning algorithms using A/B testing to determine which algorithm is most suitable for your dataset and task.
- Ensemble Methods: Evaluate the performance of ensemble methods by conducting A/B tests to determine whether combining multiple models improves overall accuracy.
- Model Explainability: Use A/B testing to assess the impact of different model explainability techniques on user understanding and trust in your machine learning models.
9. Examples of A/B Testing in Machine Learning
A/B testing in machine learning can be applied to various real-world scenarios to improve model performance and user experience. Here are some examples of how A/B testing can be used in machine learning:
- E-commerce Product Recommendations: Test different algorithms for recommending products to users on an e-commerce website and use A/B testing to determine which algorithm leads to higher conversion rates and sales.
- Personalized Email Marketing: Experiment with different subject lines, email content, and send times for personalized email marketing campaigns and use A/B testing to determine which combination results in higher open rates and click-through rates.
- Fraud Detection: Compare different machine learning models for detecting fraudulent transactions and use A/B testing to determine which model has the highest accuracy and lowest false positive rate.
- Customer Churn Prediction: Test different machine learning models for predicting customer churn and use A/B testing to determine which model has the highest accuracy and can effectively identify customers at risk of churning.
- Search Engine Ranking: Experiment with different ranking algorithms for search engine results and use A/B testing to determine which algorithm provides the most relevant and accurate search results for users.
- Healthcare Diagnosis: Compare different machine learning models for diagnosing medical conditions and use A/B testing to determine which model has the highest accuracy and can assist healthcare professionals in making accurate diagnoses.
By implementing A/B testing in these scenarios, organizations can continuously improve their machine learning models and provide better experiences for their users.
10. Maximizing Learning Outcomes with LEARNS.EDU.VN
A/B testing is more than just a tool; it is a mindset that encourages continuous improvement and data-driven decision-making. By mastering the art of A/B testing, you can significantly enhance your machine learning projects and drive better business outcomes.
Are you ready to take your machine learning skills to the next level? Visit LEARNS.EDU.VN today to explore our comprehensive resources, including detailed guides, practical tutorials, and expert insights on A/B testing and other essential machine learning techniques. Our platform is designed to help you overcome learning challenges, master complex concepts, and achieve your academic and professional goals.
At LEARNS.EDU.VN, we understand the challenges that learners face when trying to master new skills and concepts. That’s why we’ve created a platform that provides the resources and support you need to succeed. Whether you’re a student, a professional, or simply someone who wants to learn more, we have something for you.
Our resources include:
- In-depth articles and guides that cover a wide range of topics
- Practical tutorials that walk you through step-by-step instructions
- Expert insights from industry leaders and academic experts
- A supportive community of learners who can help you along the way
We’re committed to providing you with the best possible learning experience. That’s why we’re constantly updating our resources and adding new content. We want to help you achieve your goals and reach your full potential.
To further enhance your learning experience and practical skills, consider exploring the diverse courses and resources available at LEARNS.EDU.VN. Our platform offers comprehensive materials on machine learning, data science, and other cutting-edge technologies, designed to empower you with the knowledge and expertise needed to excel in your career.
Don’t miss out on the opportunity to transform your skills and advance your career. Visit LEARNS.EDU.VN today and start your journey towards becoming a machine learning expert.
Contact Us:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: learns.edu.vn
FAQ: A/B Testing in Machine Learning
1. What is the primary goal of A/B testing in machine learning?
The primary goal is to compare two versions of a model or strategy to determine which one performs better based on predefined metrics.
2. How does A/B testing differ from hyperparameter optimization in machine learning?
A/B testing compares the performance of different models in production, while hyperparameter optimization focuses on finding the best training configuration for a single model.
3. What is the Overall Evaluation Criterion (OEC) in A/B testing?
The OEC is a business-focused, measurable metric used to evaluate the success of the challenger model, such as revenue, click-through rate, or conversion rate.
4. What is the significance level (α) in A/B testing, and why is it important?
The significance level (α) is the false positive rate that we are willing to tolerate, typically set to 0.05, meaning a 5% chance of incorrectly picking an inferior challenger.
5. What is the power (β) in A/B testing, and what does it represent?
The power (β) is the true positive rate we want to achieve, typically set to 0.8, meaning an 80% chance of correctly picking a superior challenger.
6. What is the minimum sample size (n) in A/B testing, and how is it determined?
The minimum sample size (n) is the number of examples needed to ensure that the false positive rate (α) and true positive rate (β) thresholds are met, often calculated using power calculators or sample-size calculators.
7. What are A/A tests, and why are they useful in A/B testing?
A/A tests involve running both groups as control or treatment groups to surface unintentional biases or errors in processing.
8. What is the Bayesian approach to A/B testing, and how does it differ from the classical approach?
The Bayesian approach takes data from a single run and asks what OEC values are consistent with the observations, quantifying uncertainties more intuitively than the classical approach.
9. What are Multi-Armed Bandits, and how do they optimize experimentation?
Multi-Armed Bandits dynamically adjust the percentage of new requests to each option based on past performance, balancing exploitation and exploration to converge to the best model more efficiently.
10. How does the Wallaroo platform aid in A/B testing for machine learning models?
Wallaroo provides specialized pipeline configurations for setting up production experiments, including A/B tests, with features like random split and key split experimentation.
 Data-driven decision-making in machine learning
Data-driven decision-making in machine learning