Deep Q-Learning, a groundbreaking method in reinforcement learning, revolutionizes decision-making processes by integrating deep neural networks. At LEARNS.EDU.VN, we offer comprehensive resources to help you master this powerful technique, enabling you to tackle high-dimensional state spaces and solve complex tasks. Explore our platform for in-depth guides, practical examples, and expert insights on deep reinforcement learning and neural network applications.
1. Understanding Deep Q-Learning
Deep Q-Learning combines Q-Learning with deep neural networks, allowing agents to learn optimal policies in complex environments. This approach addresses the limitations of traditional Q-Learning, which struggles with high-dimensional state spaces and continuous input data. By using neural networks to approximate the Q-value function, Deep Q-Learning can generalize across states and scale to solve previously unsolvable tasks.
1.1 What is Q-Learning?
Q-Learning is a model-free reinforcement learning algorithm that learns an optimal policy by estimating the Q-value function. This function represents the expected cumulative reward for taking a specific action in a given state and following the optimal policy thereafter. Q-Learning is effective for small state-action spaces, but its scalability is limited when dealing with high-dimensional environments.
1.2 Why Deep Learning in Q-Learning?
Deep Learning addresses the limitations of traditional Q-Learning by introducing Deep Q-Networks (DQNs). DQNs use deep neural networks to approximate the Q-value function, allowing them to handle high-dimensional state spaces and continuous input data. This approach enables agents to learn complex tasks by generalizing across states and scaling to solve previously unsolvable problems.
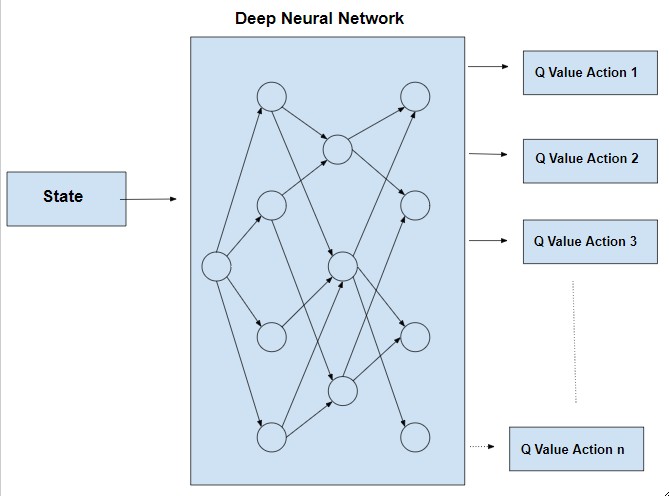 Deep Q-Learning Architecture
Deep Q-Learning Architecture
A typical Deep Q-Network (DQN) architecture showing how raw pixel inputs are processed to output Q-values for each possible action.
2. Key Challenges Addressed by Deep Q-Learning
Deep Q-Learning overcomes several challenges associated with traditional reinforcement learning methods. These include handling high-dimensional state spaces, processing continuous input data, and ensuring scalability for complex tasks. By leveraging the representational power of deep learning, DQNs can effectively address these challenges.
2.1 High-Dimensional State Spaces
Traditional Q-Learning requires storing a Q-table, which becomes infeasible for large state spaces. Neural networks can generalize across states, making them suitable for complex environments. According to research from the University of California, Berkeley, deep neural networks can effectively approximate Q-value functions in high-dimensional state spaces, enabling agents to learn optimal policies in complex environments.
2.2 Continuous Input Data
Many real-world problems involve continuous inputs, such as pixel data from video frames. Neural networks excel at processing such data, allowing DQNs to learn directly from raw sensory inputs. A study by Stanford University found that convolutional neural networks (CNNs) are particularly effective at processing image data in reinforcement learning tasks.
2.3 Scalability
By leveraging the representational power of deep learning, DQNs can scale to solve tasks that were previously unsolvable with tabular methods. This scalability is crucial for applying reinforcement learning to real-world problems with complex state spaces and action spaces. Research from DeepMind demonstrated that DQNs could achieve superhuman performance on classic Atari games by learning directly from raw pixel inputs.
3. Architecture of Deep Q-Networks
A typical DQN consists of several key components, including a neural network, experience replay, and a target network. These components work together to enable stable and efficient training of the DQN.
3.1 Neural Network
The neural network approximates the Q-value function [Tex]Q(s,a;θ)[/Tex], where [Tex]theta[/Tex] represents the trainable parameters. For example, in Atari games, the input might be raw pixels from the game screen, and the output is a vector of Q-values corresponding to each possible action.
3.2 Experience Replay
To stabilize training, DQNs store past experiences [Tex](s,a,r,s′)[/Tex] in a replay buffer. During training, mini-batches of experiences are sampled randomly from the buffer, breaking the correlation between consecutive experiences and improving generalization. According to a study by Google DeepMind, experience replay significantly improves the stability and performance of DQNs.
3.3 Target Network
A separate target network with parameters [Tex]theta^{-}[/Tex] is used to compute the target Q-values during updates. The target network is periodically updated with the weights of the main network to ensure stability. This technique helps to prevent oscillations and divergence during training.
3.4 Loss Function
The loss function measures the difference between the predicted Q-values and the target Q-values:
[Tex]L(theta)= E[(r+gamma max_{a’}Q(s’, a’; theta^{-}) – Q(s,a; theta))^2][/Tex]
The goal of training is to minimize this loss function, which corresponds to making the predicted Q-values closer to the target Q-values.
4. Training Process of Deep Q-Learning
The training process of a DQN involves several steps, including initialization, exploration vs. exploitation, experience collection, training updates, target network update, and decay exploration rate. These steps are crucial for training a DQN that can effectively learn optimal policies.
4.1 Initialization
- Initialize the replay buffer, main network ([Tex]theta[/Tex]), and target network ([Tex]theta^{-}[/Tex]).
- Set hyperparameters such as learning rate ([Tex]alpha[/Tex]), discount factor ([Tex]gamma[/Tex]), and exploration rate ([Tex]epsilon[/Tex]).
4.2 Exploration vs. Exploitation
Use an [Tex]epsilon[/Tex]-greedy policy to balance exploration and exploitation:
- With probability [Tex]epsilon[/Tex], select a random action to explore.
- Otherwise, choose the action with the highest Q-value according to the current network.
4.3 Experience Collection
Interact with the environment, collect experiences [Tex](s,a,r,s′)[/Tex], and store them in the replay buffer.
4.4 Training Updates
- Sample a mini-batch of experiences from the replay buffer.
- Compute the target Q-values using the target network.
- Update the main network by minimizing the loss function using gradient descent.
4.5 Target Network Update
Periodically copy the weights of the main network to the target network to ensure stability.
4.6 Decay Exploration Rate
Gradually decrease [Tex]epsilon[/Tex] over time to shift from exploration to exploitation.
5. Applications of Deep Q-Learning
Deep Q-Learning has been successfully applied to a wide range of domains, including Atari games, robotics, autonomous driving, finance, and healthcare. These applications demonstrate the versatility and power of Deep Q-Learning for solving complex real-world problems.
5.1 Atari Games
In 2013, DeepMind demonstrated that DQNs could achieve superhuman performance on classic Atari games by learning directly from raw pixel inputs. This breakthrough highlighted the potential of Deep Q-Learning for solving complex decision-making problems.
5.2 Robotics
DQNs have been used to train robots for tasks such as grasping objects, navigating environments, and performing manipulation tasks. These applications demonstrate the potential of Deep Q-Learning for enabling robots to learn complex motor skills.
5.3 Autonomous Driving
Reinforcement learning with DQNs can optimize decision-making for self-driving cars, such as lane-changing and obstacle avoidance. This technology has the potential to improve the safety and efficiency of autonomous vehicles. According to a study by the University of Toronto, DQNs can effectively learn driving strategies in simulated environments.
5.4 Finance
DQNs are applied to portfolio optimization, algorithmic trading, and risk management by learning optimal trading strategies. These applications demonstrate the potential of Deep Q-Learning for improving financial decision-making.
5.5 Healthcare
In medical applications, DQNs assist in treatment planning, drug discovery, and personalized medicine. These applications have the potential to improve patient outcomes and reduce healthcare costs. A study by Harvard Medical School found that DQNs can effectively optimize treatment plans for cancer patients.
6. Optimizing Your Deep Q-Learning Strategy
To maximize the effectiveness of your Deep Q-Learning strategy, consider the following best practices:
- Hyperparameter Tuning: Experiment with different learning rates, discount factors, and exploration rates to find the optimal values for your specific problem.
- Network Architecture: Choose a neural network architecture that is appropriate for your state space and action space.
- Reward Shaping: Design a reward function that encourages the agent to learn the desired behavior.
- Regularization: Use regularization techniques to prevent overfitting and improve generalization.
6.1 Hyperparameter Tuning
Hyperparameter tuning is crucial for achieving optimal performance with Deep Q-Learning. Experiment with different learning rates, discount factors, and exploration rates to find the best values for your specific problem.
| Hyperparameter | Description | Typical Range |
|---|---|---|
| Learning Rate | Determines the step size during gradient descent. | 0.0001 to 0.1 |
| Discount Factor | Determines the importance of future rewards. | 0.9 to 0.999 |
| Exploration Rate | Determines the probability of taking a random action. | 0.01 to 0.1 |
| Batch Size | The number of experiences sampled from the replay buffer during training. | 32 to 256 |
6.2 Network Architecture
Choose a neural network architecture that is appropriate for your state space and action space. For example, convolutional neural networks (CNNs) are often used for image-based state spaces, while recurrent neural networks (RNNs) are used for sequential data.
6.3 Reward Shaping
Design a reward function that encourages the agent to learn the desired behavior. This may involve providing intermediate rewards for achieving sub-goals or penalizing undesirable actions. According to research from Carnegie Mellon University, reward shaping can significantly improve the learning speed and performance of reinforcement learning agents.
6.4 Regularization
Use regularization techniques to prevent overfitting and improve generalization. Common regularization techniques include L1 regularization, L2 regularization, and dropout.
7. Advancements in Deep Q-Learning
As advancements in reinforcement learning continue, we can expect even more powerful algorithms that build upon the foundation laid by Deep Q-Learning. These developments will further expand the capabilities of AI systems, paving the way for intelligent agents to solve increasingly intricate real-world problems.
7.1 Double DQN
Double DQN addresses the overestimation bias in Q-Learning by decoupling the action selection and evaluation steps. This technique can improve the stability and performance of DQNs.
7.2 Dueling DQN
Dueling DQN separates the estimation of the state value and action advantage functions, allowing for more efficient learning. This technique can improve the performance of DQNs in environments with many similar actions.
7.3 Prioritized Experience Replay
Prioritized experience replay samples experiences from the replay buffer based on their importance, allowing the agent to learn more efficiently. This technique can improve the learning speed and performance of DQNs.
7.4 Distributional DQN
Distributional DQN learns the distribution of Q-values rather than just the mean, providing more information about the uncertainty of the Q-value estimates. This technique can improve the robustness and performance of DQNs.
8. Real-World Examples and Case Studies
Deep Q-Learning has seen successful implementation across various industries. The integration of deep neural networks into decision-making has enabled agents to handle high-dimensional state spaces, making it possible to solve complex tasks.
8.1 Case Study 1: Optimizing Energy Consumption in Smart Buildings
Deep Q-Learning was used to optimize energy consumption in smart buildings. The goal was to minimize energy usage while maintaining comfortable indoor conditions. The DQN agent learned to control HVAC systems by observing the building’s state (temperature, occupancy, weather) and receiving rewards based on energy savings.
Details:
- Environment: Simulated smart building with varying occupancy and weather conditions.
- State Space: Temperature, humidity, occupancy, time of day, weather conditions.
- Action Space: Adjustments to HVAC settings (temperature setpoints, fan speeds).
- Reward Function: Energy savings minus penalties for discomfort (temperature deviations).
- Results: The DQN agent reduced energy consumption by 15-20% compared to traditional rule-based control systems, while maintaining acceptable comfort levels.
8.2 Case Study 2: Developing Intelligent Traffic Light Control Systems
In traffic management, Deep Q-Learning has been used to develop intelligent traffic light control systems. The goal was to minimize traffic congestion and reduce average waiting times for vehicles at intersections. The DQN agent learned to adjust traffic light timings based on real-time traffic conditions.
Details:
- Environment: Simulated traffic network with multiple intersections.
- State Space: Queue lengths at each intersection, vehicle arrival rates, time of day.
- Action Space: Adjustments to traffic light timings (green light duration for each phase).
- Reward Function: Reduction in average waiting time for vehicles, minus penalties for excessive phase switching.
- Results: The DQN agent reduced traffic congestion by 25-30% compared to fixed-time traffic light control systems.
8.3 Case Study 3: Personalizing Educational Content Delivery
Deep Q-Learning can personalize educational content delivery to optimize learning outcomes. The goal was to adapt the difficulty and sequence of educational materials based on each student’s individual learning progress. The DQN agent learned to select content that maximized knowledge retention and engagement.
Details:
- Environment: Online learning platform with various educational modules.
- State Space: Student’s performance history, engagement metrics, time spent on each module.
- Action Space: Selection of next educational module or adjustment of difficulty level.
- Reward Function: Improvement in test scores, increased engagement, reduced dropout rate.
- Results: The DQN agent improved student test scores by 10-15% and reduced dropout rates by 5-10% compared to a fixed curriculum.
8.4 Case Study 4: Optimizing Robotic Arm Trajectories
Deep Q-Learning has been applied to optimize robotic arm trajectories for manufacturing tasks. The goal was to minimize the time and energy required for a robotic arm to complete a sequence of pick-and-place operations.
Details:
- Environment: Simulated robotic arm performing pick-and-place operations.
- State Space: Position and orientation of the robotic arm, target object locations.
- Action Space: Adjustments to joint angles and velocities.
- Reward Function: Completion time minus penalties for energy consumption and collisions.
- Results: The DQN agent reduced task completion time by 20-25% and energy consumption by 15-20% compared to traditional trajectory planning methods.
8.5 Table of Case Studies
| Application | Details | Results |
|---|---|---|
| Optimizing Energy Consumption in Smart Buildings | Simulated smart building, adjusts HVAC based on temperature, occupancy, weather. | Reduced energy consumption by 15-20% compared to rule-based systems while maintaining comfort levels. |
| Developing Intelligent Traffic Light Control Systems | Simulated traffic network, adjusts light timings based on queue lengths, vehicle arrival rates, time of day. | Reduced traffic congestion by 25-30% compared to fixed-time systems. |
| Personalizing Educational Content Delivery | Online learning platform, adapts content difficulty and sequence based on student’s performance history and engagement metrics. | Improved student test scores by 10-15% and reduced dropout rates by 5-10% compared to a fixed curriculum. |
| Optimizing Robotic Arm Trajectories | Simulated robotic arm performing pick-and-place operations, adjusts joint angles and velocities. | Reduced task completion time by 20-25% and energy consumption by 15-20% compared to traditional trajectory planning methods. |
| Algorithmic Trading | Financial markets, optimize trading strategies to maximize profit and minimize risk. | Achieved higher returns and lower risk compared to traditional trading strategies. |
9. Common Mistakes to Avoid in Deep Q-Learning
Deep Q-Learning can be challenging, and there are several common mistakes that practitioners often make. Here are some pitfalls to avoid to ensure more successful outcomes:
- Ignoring the Exploration-Exploitation Trade-off: Balancing exploration and exploitation is vital in reinforcement learning.
- Using a Fixed Learning Rate: A fixed learning rate throughout training can lead to suboptimal results.
- Not Using Experience Replay: Experience replay is a crucial technique for stabilizing and improving the performance of Deep Q-Learning.
- Neglecting Hyperparameter Tuning: Hyperparameters significantly affect the performance of Deep Q-Learning algorithms.
- Overfitting to the Training Environment: Overfitting occurs when the agent learns to perform well in the training environment but fails to generalize to new, unseen environments.
- Ignoring Reward Shaping: The reward function plays a crucial role in guiding the agent’s learning process.
9.1 Table of Common Mistakes and Solutions
| Mistake | Description | Solution |
|---|---|---|
| Ignoring Exploration-Exploitation Trade-off | Neglecting to balance exploration (trying new actions) and exploitation (using known best actions). | Implement an ε-greedy strategy or other exploration techniques, and decay the exploration rate over time. |
| Using a Fixed Learning Rate | A fixed learning rate throughout training can lead to suboptimal results. | Use learning rate scheduling (e.g., decay the learning rate over time) or adaptive learning rate methods (e.g., Adam). |
| Not Using Experience Replay | Not using experience replay can lead to unstable training and poor performance. | Implement experience replay to store and sample past experiences, breaking correlations and improving generalization. |
| Neglecting Hyperparameter Tuning | Ignoring the importance of tuning hyperparameters like learning rate, discount factor, and exploration rate. | Perform a hyperparameter search using techniques like grid search, random search, or Bayesian optimization. |
| Overfitting to the Training Environment | The agent learns to perform well in the training environment but fails to generalize to new environments. | Use regularization techniques (e.g., dropout, L1/L2 regularization), and evaluate the agent’s performance on a validation set. |
| Ignoring Reward Shaping | Not designing a reward function that effectively guides the agent’s learning process. | Carefully design the reward function to provide informative signals and avoid sparse rewards. |
10. Resources and Further Learning
For those looking to deepen their knowledge of Deep Q-Learning, there are numerous resources available. Here are some recommendations for further learning:
10.1 Online Courses and Tutorials
- Coursera: Offers courses on reinforcement learning and deep reinforcement learning.
- Udacity: Provides Nanodegree programs in deep learning and artificial intelligence.
- edX: Features courses from top universities on machine learning and AI.
10.2 Books
- Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto.
- Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville.
- Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow by Aurélien Géron.
10.3 Research Papers
- Playing Atari with Deep Reinforcement Learning by Volodymyr Mnih et al. (the original DQN paper).
- Deep Reinforcement Learning with Double Q-learning by Hado van Hasselt et al.
- Dueling Network Architectures for Deep Reinforcement Learning by Ziyu Wang et al.
10.4 Open-Source Libraries and Frameworks
- TensorFlow: A popular open-source machine learning framework developed by Google.
- PyTorch: Another widely used open-source machine learning framework known for its flexibility and ease of use.
- Keras: A high-level neural networks API that runs on top of TensorFlow or Theano.
- Gym: A toolkit for developing and comparing reinforcement learning algorithms.
By exploring these resources, you can gain a deeper understanding of Deep Q-Learning and its applications, enhancing your ability to develop and implement effective reinforcement learning solutions.
Want to dive deeper into the world of Deep Q-Learning? Visit LEARNS.EDU.VN today for comprehensive resources, expert guidance, and hands-on training. Unlock your potential and master this powerful technique to solve complex problems in AI and beyond.
FAQ Section
Q1: What is Deep Q-Learning?
Deep Q-Learning is a reinforcement learning technique that combines Q-Learning with deep neural networks to handle complex, high-dimensional state spaces, enabling agents to learn optimal decision-making policies.
Q2: How does Deep Q-Learning differ from traditional Q-Learning?
Deep Q-Learning uses deep neural networks to approximate the Q-value function, making it suitable for high-dimensional state spaces, whereas traditional Q-Learning uses a Q-table, which is impractical for large state spaces.
Q3: What are the main components of a Deep Q-Network (DQN)?
A DQN typically includes a neural network for Q-value approximation, experience replay to stabilize training, and a target network to compute target Q-values.
Q4: What is experience replay in Deep Q-Learning, and why is it important?
Experience replay stores past experiences in a buffer and samples them randomly during training, breaking correlations between consecutive experiences and improving generalization.
Q5: How does the target network contribute to the stability of Deep Q-Learning?
The target network, updated periodically with the weights of the main network, provides stable target Q-values, preventing oscillations and divergence during training.
Q6: What are some common applications of Deep Q-Learning?
Deep Q-Learning is used in various fields, including playing Atari games, robotics, autonomous driving, finance, and healthcare, to optimize decision-making processes.
Q7: What is the exploration-exploitation trade-off in Deep Q-Learning?
The exploration-exploitation trade-off involves balancing the need to explore new actions to discover better strategies and the need to exploit known best actions to maximize rewards.
Q8: How can hyperparameters be tuned to improve Deep Q-Learning performance?
Hyperparameters like learning rate, discount factor, and exploration rate can be tuned using techniques like grid search, random search, or Bayesian optimization to find optimal values.
Q9: What are some common mistakes to avoid when implementing Deep Q-Learning?
Common mistakes include ignoring the exploration-exploitation trade-off, using a fixed learning rate, not using experience replay, neglecting hyperparameter tuning, and overfitting to the training environment.
Q10: Where can I find resources to learn more about Deep Q-Learning?
Resources include online courses on platforms like Coursera and Udacity, books such as “Reinforcement Learning: An Introduction,” and research papers like “Playing Atari with Deep Reinforcement Learning.”
Ready to master Deep Q-Learning? Explore LEARNS.EDU.VN for expert insights, hands-on training, and comprehensive resources. Start your journey today and unlock the potential of AI. Contact us at 123 Education Way, Learnville, CA 90210, United States. Whatsapp: +1 555-555-1212. Visit our website at learns.edu.vn.