Do Data Scientists Use Machine Learning? Yes, data scientists extensively use machine learning as a crucial tool in their work to extract insights, make predictions, and automate data analysis processes. LEARNS.EDU.VN offers resources and courses that thoroughly cover both data science and machine learning, empowering you to master these essential skills. Explore machine learning applications, data analytics techniques, and predictive modeling strategies to advance your career.
1. Understanding the Intersection of Data Science and Machine Learning
Data science and machine learning are interconnected fields that leverage data to create innovative products, services, and systems. Data science is the overarching field encompassing various methods for extracting knowledge from data, while machine learning is a subset focused on algorithms that enable systems to learn from data without explicit programming.
1.1. Data Science: The Comprehensive Field
Data science is an interdisciplinary field that employs scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Data scientists apply their expertise to various domains, including business, government, and research, to drive decision-making, optimize processes, and develop innovative solutions.
1.2. Machine Learning: A Subset of Artificial Intelligence
Machine learning, a branch of artificial intelligence (AI), focuses on developing algorithms that allow computers to learn from data without being explicitly programmed. These algorithms enable machines to identify patterns, make predictions, and improve their performance over time. Machine learning is a powerful tool for automating data analysis and extracting valuable insights from large datasets.
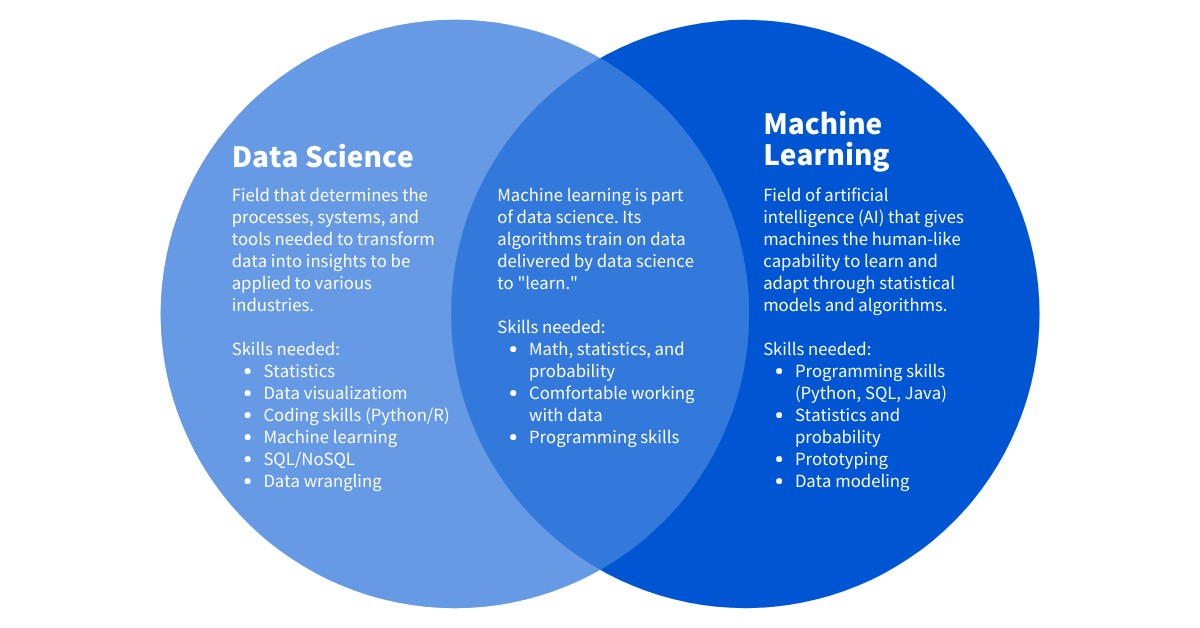 Venn diagram illustrating the relationship between Data Science and Machine Learning
Venn diagram illustrating the relationship between Data Science and Machine Learning
1.3. The Synergistic Relationship
Machine learning plays a significant role in data science, particularly in data analytics and business intelligence. Machine learning algorithms automate data analysis, enabling data scientists to efficiently process large datasets and identify relevant patterns. These patterns are then used to build predictive models and inform business strategies. According to a study by Stanford University, companies that effectively integrate machine learning into their data science workflows experience a 20% increase in efficiency and a 15% improvement in decision-making accuracy.
2. Key Applications of Machine Learning in Data Science
Machine learning is applied across various stages of the data science process, from data preprocessing to model deployment. Here are some key applications:
2.1. Data Preprocessing
Machine learning techniques are used to clean, transform, and prepare data for analysis. This includes:
- Handling Missing Values: Imputing missing values using techniques like mean imputation, median imputation, or k-nearest neighbors (KNN).
- Outlier Detection: Identifying and removing outliers using methods like z-score analysis or the interquartile range (IQR).
- Feature Scaling: Scaling numerical features to a similar range using techniques like standardization or normalization.
2.2. Feature Engineering
Machine learning assists in creating new features from existing ones to improve model performance. This involves:
- Polynomial Features: Generating polynomial combinations of existing features to capture non-linear relationships.
- Interaction Features: Creating interaction terms by multiplying or combining two or more features.
- Domain-Specific Features: Developing features based on domain knowledge to capture specific patterns relevant to the problem.
2.3. Model Building and Training
Machine learning algorithms are used to build predictive models based on historical data. This includes:
- Supervised Learning: Training models on labeled data to predict outcomes for new data points. Examples include linear regression, logistic regression, decision trees, and support vector machines (SVM).
- Unsupervised Learning: Discovering patterns and structures in unlabeled data. Examples include clustering algorithms like k-means and hierarchical clustering, and dimensionality reduction techniques like principal component analysis (PCA).
- Model Selection: Selecting the best model based on performance metrics like accuracy, precision, recall, and F1-score.
2.4. Model Evaluation and Validation
Machine learning provides methods for evaluating and validating the performance of predictive models. This includes:
- Cross-Validation: Splitting the data into multiple folds and training the model on different combinations of folds to assess its generalization performance.
- Hyperparameter Tuning: Optimizing the hyperparameters of a model using techniques like grid search or random search to improve its performance.
- Bias-Variance Tradeoff: Balancing the model’s ability to fit the training data (low bias) with its ability to generalize to new data (low variance).
2.5. Predictive Analytics
One of the primary applications of machine learning in data science is predictive analytics. Machine learning models can be trained to forecast future trends, behaviors, and outcomes based on historical data. This capability is invaluable in various industries for tasks such as:
- Sales Forecasting: Predicting future sales volumes to optimize inventory management and production planning.
- Customer Churn Prediction: Identifying customers who are likely to discontinue their services, enabling targeted retention efforts.
- Risk Assessment: Evaluating the risk of loan defaults, insurance claims, or fraudulent activities.
- Fraud Detection: Identifying fraudulent transactions in real-time, preventing financial losses and protecting customers.
For example, in the retail industry, machine learning algorithms analyze past sales data, customer demographics, and market trends to predict future sales with remarkable accuracy. This allows retailers to optimize their inventory levels, reduce waste, and improve profitability.
According to a study by McKinsey, companies that leverage predictive analytics powered by machine learning see a 10-20% improvement in their operational efficiency.
2.6. Data Visualization
Machine learning techniques can also be used to enhance data visualization. By identifying patterns and relationships in data, machine learning algorithms can create more informative and engaging visualizations. This includes:
- Dimensionality Reduction: Reducing the number of variables in a dataset while preserving its essential structure, making it easier to visualize high-dimensional data.
- Clustering: Grouping similar data points together to reveal underlying patterns and structures.
- Anomaly Detection: Identifying unusual data points that deviate from the norm, highlighting potential errors or opportunities.
2.7. Natural Language Processing (NLP)
NLP is a branch of AI focused on enabling computers to understand, interpret, and generate human language. Machine learning plays a crucial role in NLP tasks such as:
- Sentiment Analysis: Determining the emotional tone of text, identifying whether it expresses positive, negative, or neutral sentiments.
- Text Classification: Assigning predefined categories to text documents based on their content.
- Machine Translation: Automatically translating text from one language to another.
- Chatbots: Creating conversational agents that can interact with humans in a natural and intuitive way.
NLP is widely used in various industries, including customer service, marketing, and healthcare, to automate tasks, improve efficiency, and enhance customer experiences.
2.8. Recommendation Systems
Recommendation systems use machine learning algorithms to predict users’ preferences and recommend relevant products, services, or content. These systems are widely used in e-commerce, entertainment, and social media to personalize user experiences and drive engagement. Examples include:
- Product Recommendations: Suggesting products that a user might be interested in based on their past purchases, browsing history, or demographics.
- Movie Recommendations: Recommending movies that a user might enjoy based on their viewing history, ratings, or preferences.
- News Recommendations: Suggesting news articles that a user might find interesting based on their reading history, interests, or social connections.
Recommendation systems are highly effective in driving sales, increasing customer loyalty, and improving user satisfaction.
2.9. Image and Video Analytics
Machine learning is extensively used in image and video analytics to extract information, identify objects, and understand scenes. This includes:
- Object Detection: Identifying and locating objects of interest in images or videos.
- Image Classification: Assigning predefined categories to images based on their content.
- Facial Recognition: Identifying and verifying individuals based on their facial features.
- Video Surveillance: Monitoring video streams for suspicious activities or security threats.
Image and video analytics are used in various applications, including autonomous vehicles, medical imaging, and security systems.
3. Essential Machine Learning Algorithms for Data Scientists
Data scientists utilize a variety of machine learning algorithms to address different types of problems. Here are some essential algorithms every data scientist should know:
3.1. Linear Regression
Linear regression is a fundamental algorithm used for predicting a continuous target variable based on one or more predictor variables. It assumes a linear relationship between the variables and aims to find the best-fitting line that minimizes the difference between the predicted and actual values. Linear regression is widely used for tasks such as:
- Sales Forecasting: Predicting future sales volumes based on historical data and market trends.
- Price Prediction: Estimating the price of a product or service based on its features and market conditions.
- Demand Forecasting: Predicting the demand for a product or service based on historical data and market factors.
3.2. Logistic Regression
Logistic regression is a classification algorithm used for predicting the probability of a binary outcome. It uses a logistic function to model the relationship between the predictor variables and the probability of the outcome. Logistic regression is commonly used for tasks such as:
- Customer Churn Prediction: Identifying customers who are likely to discontinue their services.
- Spam Detection: Classifying emails as spam or not spam.
- Medical Diagnosis: Predicting the probability of a patient having a particular disease.
3.3. Decision Trees
Decision trees are versatile algorithms used for both classification and regression tasks. They work by recursively partitioning the data based on the values of the predictor variables, creating a tree-like structure that represents the decision-making process. Decision trees are easy to understand and interpret, making them valuable for tasks such as:
- Credit Risk Assessment: Evaluating the creditworthiness of loan applicants.
- Fraud Detection: Identifying fraudulent transactions based on patterns and rules.
- Customer Segmentation: Grouping customers into different segments based on their characteristics and behaviors.
3.4. Random Forests
Random forests are ensemble learning algorithms that combine multiple decision trees to improve prediction accuracy and robustness. They work by training multiple decision trees on random subsets of the data and averaging their predictions. Random forests are highly effective in handling complex datasets and are widely used for tasks such as:
- Image Classification: Assigning predefined categories to images based on their content.
- Object Detection: Identifying and locating objects of interest in images or videos.
- Medical Diagnosis: Predicting the probability of a patient having a particular disease.
3.5. Support Vector Machines (SVM)
Support Vector Machines (SVM) are powerful algorithms used for both classification and regression tasks. They work by finding the optimal hyperplane that separates the data points into different classes, maximizing the margin between the classes. SVMs are effective in handling high-dimensional data and are widely used for tasks such as:
- Text Classification: Assigning predefined categories to text documents based on their content.
- Image Recognition: Identifying and classifying objects in images.
- Bioinformatics: Analyzing biological data to identify patterns and relationships.
3.6. K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) is a simple yet effective algorithm used for both classification and regression tasks. It works by finding the k-nearest neighbors of a data point in the feature space and predicting its outcome based on the majority class or average value of its neighbors. KNN is easy to implement and understand, making it valuable for tasks such as:
- Recommendation Systems: Suggesting products or services to users based on the preferences of similar users.
- Anomaly Detection: Identifying unusual data points that deviate from the norm.
- Image Recognition: Identifying and classifying objects in images.
3.7. Clustering Algorithms (K-Means, Hierarchical Clustering)
Clustering algorithms are used to group similar data points together based on their characteristics. K-Means clustering aims to partition the data into k clusters, where each data point belongs to the cluster with the nearest mean. Hierarchical clustering builds a hierarchy of clusters, starting from individual data points and merging them iteratively until a single cluster is formed. Clustering algorithms are widely used for tasks such as:
- Customer Segmentation: Grouping customers into different segments based on their characteristics and behaviors.
- Market Segmentation: Identifying different market segments based on their demographics and preferences.
- Anomaly Detection: Identifying unusual data points that deviate from the norm.
3.8. Dimensionality Reduction Techniques (PCA)
Dimensionality reduction techniques are used to reduce the number of variables in a dataset while preserving its essential structure. Principal Component Analysis (PCA) is a popular technique that transforms the data into a new coordinate system where the principal components capture the maximum variance in the data. Dimensionality reduction is valuable for tasks such as:
- Data Visualization: Reducing the dimensionality of data to make it easier to visualize.
- Feature Extraction: Extracting the most important features from a dataset.
- Noise Reduction: Removing noise and irrelevant information from a dataset.
4. Skills Required for Data Scientists to Use Machine Learning Effectively
To effectively leverage machine learning in data science, professionals need a diverse skill set encompassing technical expertise, domain knowledge, and soft skills. These skills enable them to tackle complex problems, extract meaningful insights, and drive data-informed decisions.
4.1. Programming Languages
Proficiency in programming languages is essential for data scientists to implement machine learning algorithms, manipulate data, and develop custom solutions.
- Python: Python is the most popular programming language for data science, offering a rich ecosystem of libraries and tools for machine learning, data analysis, and visualization.
- R: R is another widely used programming language for statistical computing and data analysis, providing a comprehensive set of packages for machine learning and data mining.
4.2. Machine Learning Libraries
Familiarity with machine learning libraries is crucial for implementing and applying machine learning algorithms efficiently.
- Scikit-learn: Scikit-learn is a comprehensive library providing a wide range of machine learning algorithms, tools for model selection, evaluation, and preprocessing.
- TensorFlow: TensorFlow is a powerful library for deep learning, offering tools for building and training neural networks.
- Keras: Keras is a high-level API for building and training neural networks, providing a user-friendly interface to TensorFlow and other deep learning frameworks.
- PyTorch: PyTorch is another popular library for deep learning, known for its flexibility and dynamic computation graph.
4.3. Statistical Analysis
A strong foundation in statistical analysis is essential for understanding the underlying principles of machine learning algorithms, interpreting results, and making valid inferences.
- Descriptive Statistics: Calculating measures of central tendency, variability, and distribution to summarize data.
- Inferential Statistics: Using sample data to make inferences about populations, including hypothesis testing and confidence intervals.
- Regression Analysis: Modeling the relationship between variables to predict outcomes and understand their dependencies.
4.4. Data Visualization
Effective data visualization skills are essential for communicating insights, exploring data, and presenting results to stakeholders.
- Matplotlib: Matplotlib is a versatile library for creating static, interactive, and animated visualizations in Python.
- Seaborn: Seaborn is a high-level library built on top of Matplotlib, providing a more aesthetically pleasing and informative set of visualizations.
- Tableau: Tableau is a powerful data visualization tool that allows users to create interactive dashboards and visualizations without writing code.
4.5. Data Wrangling
Data wrangling involves cleaning, transforming, and preparing data for analysis. This is a crucial step in the data science process, as real-world data is often messy and inconsistent.
- Data Cleaning: Handling missing values, outliers, and inconsistencies in the data.
- Data Transformation: Converting data into a suitable format for analysis, including scaling, normalization, and encoding categorical variables.
- Data Integration: Combining data from multiple sources into a unified dataset.
4.6. Domain Knowledge
Domain knowledge refers to the understanding of the specific industry or area in which the data science project is being applied. This knowledge is crucial for identifying relevant problems, selecting appropriate algorithms, and interpreting results.
- Industry Expertise: Understanding the trends, challenges, and opportunities in the industry.
- Business Acumen: Understanding the business goals and objectives of the organization.
- Subject Matter Expertise: Understanding the specific concepts and processes related to the project.
4.7. Communication Skills
Effective communication skills are essential for data scientists to collaborate with stakeholders, explain complex concepts, and present results in a clear and concise manner.
- Written Communication: Writing clear and concise reports, presentations, and documentation.
- Verbal Communication: Presenting findings to stakeholders, explaining technical concepts to non-technical audiences, and participating in discussions.
- Active Listening: Understanding the needs and concerns of stakeholders and responding appropriately.
4.8. Problem-Solving Skills
Data science involves solving complex problems using data and machine learning techniques. Strong problem-solving skills are essential for identifying the root causes of problems, developing effective solutions, and evaluating their impact.
- Critical Thinking: Analyzing information objectively and making reasoned judgments.
- Creative Thinking: Generating new ideas and approaches to solving problems.
- Analytical Thinking: Breaking down complex problems into smaller, manageable components.
5. Real-World Examples of Data Scientists Using Machine Learning
To illustrate how data scientists use machine learning in practice, let’s explore some real-world examples across various industries:
5.1. Healthcare: Predicting Patient Readmissions
In healthcare, data scientists use machine learning to predict patient readmissions, which are costly for hospitals and can indicate poor patient outcomes. By analyzing patient data, including medical history, demographics, and lab results, machine learning models can identify patients at high risk of readmission. This allows hospitals to proactively intervene and provide targeted care to prevent readmissions.
According to a study by the Agency for Healthcare Research and Quality (AHRQ), machine learning models can predict patient readmissions with up to 80% accuracy.
5.2. Finance: Fraud Detection
In the finance industry, data scientists use machine learning to detect fraudulent transactions in real-time. By analyzing transaction data, including amount, location, and time, machine learning models can identify suspicious patterns and flag potentially fraudulent transactions. This helps financial institutions prevent financial losses and protect their customers.
According to a report by LexisNexis Risk Solutions, machine learning-based fraud detection systems can reduce fraud losses by up to 70%.
5.3. Retail: Personalized Recommendations
In the retail industry, data scientists use machine learning to provide personalized recommendations to customers. By analyzing customer data, including past purchases, browsing history, and demographics, machine learning models can predict which products a customer is likely to be interested in. This allows retailers to provide personalized recommendations, which can increase sales and improve customer satisfaction.
According to a study by McKinsey, personalized recommendations can increase sales by up to 20%.
5.4. Marketing: Customer Segmentation
In marketing, data scientists use machine learning to segment customers into different groups based on their characteristics and behaviors. By analyzing customer data, including demographics, purchase history, and website activity, machine learning models can identify different customer segments with unique needs and preferences. This allows marketers to tailor their campaigns and messaging to each segment, improving the effectiveness of their marketing efforts.
According to a report by the Aberdeen Group, companies that use customer segmentation can see a 10% increase in revenue.
5.5. Manufacturing: Predictive Maintenance
In manufacturing, data scientists use machine learning to predict when equipment is likely to fail. By analyzing data from sensors on the equipment, machine learning models can identify patterns that indicate potential failures. This allows manufacturers to proactively maintain their equipment, preventing costly downtime and improving productivity.
According to a report by Deloitte, predictive maintenance can reduce maintenance costs by up to 25%.
6. How to Get Started with Machine Learning for Data Science
If you’re interested in getting started with machine learning for data science, here are some steps you can take:
6.1. Learn the Fundamentals
Start by learning the fundamentals of data science, including statistics, linear algebra, calculus, and programming. There are many online resources, courses, and books that can help you learn these concepts.
6.2. Choose a Programming Language
Choose a programming language and become proficient in it. Python is the most popular language for data science, but R is also widely used.
6.3. Explore Machine Learning Libraries
Explore the various machine learning libraries available, such as Scikit-learn, TensorFlow, and Keras. These libraries provide a wide range of algorithms and tools that can help you build and train machine learning models.
6.4. Work on Projects
Work on projects to gain practical experience and build your portfolio. There are many publicly available datasets that you can use for your projects.
6.5. Participate in Competitions
Participate in machine learning competitions, such as those on Kaggle, to test your skills and learn from others.
6.6. Network with Others
Network with other data scientists and machine learning practitioners. Attend conferences, join online communities, and connect with people on LinkedIn.
6.7. Stay Up-to-Date
Stay up-to-date with the latest advancements in machine learning. Read research papers, follow blogs, and attend webinars and conferences.
7. The Future of Machine Learning in Data Science
The field of machine learning is rapidly evolving, with new algorithms, techniques, and tools being developed all the time. As machine learning continues to advance, it will play an even greater role in data science, enabling data scientists to solve more complex problems, extract deeper insights, and create more innovative solutions.
Here are some of the key trends shaping the future of machine learning in data science:
7.1. Automated Machine Learning (AutoML)
AutoML is a set of techniques that automate the process of building and deploying machine learning models. AutoML tools can automatically select the best algorithms, tune hyperparameters, and evaluate model performance, making machine learning more accessible to non-experts.
7.2. Explainable AI (XAI)
XAI is a set of techniques that make machine learning models more transparent and understandable. XAI tools can help data scientists understand why a model made a particular prediction, identify potential biases, and build trust in the model’s results.
7.3. Deep Learning
Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to extract complex patterns from data. Deep learning has achieved remarkable success in various applications, including image recognition, natural language processing, and speech recognition.
7.4. Federated Learning
Federated learning is a distributed machine learning technique that allows models to be trained on decentralized data sources without sharing the data itself. Federated learning is particularly useful for applications where data privacy is a concern, such as healthcare and finance.
7.5. Reinforcement Learning
Reinforcement learning is a type of machine learning that trains agents to make decisions in an environment to maximize a reward. Reinforcement learning has achieved remarkable success in various applications, including robotics, game playing, and autonomous driving.
8. Choosing the Right Machine Learning Tools
Selecting the appropriate machine-learning tools is critical for data scientists to maximize their productivity and achieve optimal results. The market offers a diverse range of tools, each with its strengths and weaknesses. Data scientists should carefully consider their specific requirements, project goals, and technical expertise when selecting tools.
8.1. Considerations for Choosing Tools
- Scalability: Consider the size and complexity of the datasets you’ll be working with. Choose tools that can scale to handle large datasets efficiently.
- Ease of Use: Evaluate the user interface and documentation. Opt for tools with intuitive interfaces and comprehensive documentation to minimize the learning curve.
- Algorithm Support: Ensure that the tools support the machine-learning algorithms you plan to use.
- Integration: Verify that the tools can seamlessly integrate with your existing data infrastructure and workflows.
- Cost: Compare the pricing models and licensing fees of different tools. Choose tools that fit your budget and offer the best value for your investment.
8.2. Popular Machine Learning Tools
| Tool | Description | Strengths | Weaknesses |
|---|---|---|---|
| Scikit-learn | Comprehensive library providing a wide range of machine learning algorithms | Easy to use, well-documented, versatile | Limited support for deep learning |
| TensorFlow | Powerful library for deep learning, offering tools for building and training neural networks | Flexible, scalable, supports distributed training | Steep learning curve, requires more coding |
| Keras | High-level API for building and training neural networks | User-friendly interface, simplifies deep learning model development | Limited flexibility compared to TensorFlow |
| PyTorch | Another popular library for deep learning, known for its flexibility | Dynamic computation graph, easy to debug, supports distributed training | Steeper learning curve compared to Keras |
| H2O.ai | Open-source platform for machine learning and predictive analytics | Scalable, supports various algorithms, provides AutoML features | Can be complex to set up and configure |
| RapidMiner | Comprehensive platform for data science and machine learning | Visual workflow designer, supports various algorithms, provides AutoML features | Can be expensive for commercial use |
| DataRobot | Automated machine learning platform | Automates the entire machine learning pipeline, from data preparation to model deployment | Can be expensive for commercial use |
9. Ethical Considerations in Using Machine Learning
As machine learning becomes more pervasive in data science, it’s crucial to consider the ethical implications of its use. Machine learning models can perpetuate biases, discriminate against certain groups, and raise privacy concerns. Data scientists must be aware of these ethical considerations and take steps to mitigate them.
9.1. Bias
Machine learning models can perpetuate biases if they are trained on biased data. For example, a model trained to predict loan defaults may discriminate against certain racial groups if the training data reflects historical biases in lending practices.
9.2. Discrimination
Machine learning models can discriminate against certain groups if they are not carefully designed and evaluated. For example, a model used for hiring may discriminate against women if it is trained on data that reflects historical biases in hiring practices.
9.3. Privacy
Machine learning models can raise privacy concerns if they are trained on sensitive data. For example, a model used to predict customer behavior may raise privacy concerns if it is trained on data that includes personal information.
9.4. Fairness
Fairness is a critical ethical consideration in machine learning. Data scientists must ensure that their models are fair to all groups, regardless of their race, gender, or other protected characteristics.
9.5. Transparency
Transparency is another important ethical consideration. Data scientists should strive to make their models as transparent as possible so that others can understand how they work and identify potential biases.
9.6. Accountability
Accountability is essential for ensuring that machine learning models are used responsibly. Data scientists should be accountable for the decisions made by their models and take steps to mitigate any negative consequences.
10. Resources for Continuous Learning
The field of data science and machine learning is constantly evolving, so it’s important to commit to continuous learning. Here are some resources to help you stay up-to-date and expand your knowledge:
10.1. Online Courses
- Coursera: Coursera offers a wide range of courses on data science and machine learning from top universities and institutions.
- edX: edX is another popular platform offering courses on data science and machine learning.
- Udacity: Udacity offers nanodegree programs in data science and machine learning, providing a comprehensive curriculum and hands-on projects.
- DataCamp: DataCamp focuses on data science education, offering courses and skill tracks in various programming languages and tools.
10.2. Books
- “Python for Data Analysis” by Wes McKinney
- “Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow” by Aurélien Géron
- “The Elements of Statistical Learning” by Trevor Hastie, Robert Tibshirani, and Jerome Friedman
- “Pattern Recognition and Machine Learning” by Christopher Bishop
10.3. Blogs and Websites
- Towards Data Science: A popular blog on Medium covering various topics in data science and machine learning.
- Analytics Vidhya: A website offering tutorials, articles, and resources on data science and machine learning.
- Kaggle: A platform for data science competitions and datasets, providing a great way to learn and practice your skills.
- Machine Learning Mastery: A blog offering tutorials and resources for machine learning.
10.4. Conferences
- NeurIPS (Neural Information Processing Systems): A leading conference on machine learning and neural information processing.
- ICML (International Conference on Machine Learning): A major conference on machine learning.
- KDD (Knowledge Discovery and Data Mining): A leading conference on data mining and knowledge discovery.
- Data Council: A conference focused on data engineering, data science, and machine learning.
10.5. Communities
- Kaggle: Join the Kaggle community to participate in competitions, discuss data science topics, and learn from others.
- Reddit: The r/datascience and r/machinelearning subreddits are popular communities for data scientists and machine learning practitioners.
- LinkedIn: Connect with other data scientists and machine learning practitioners on LinkedIn to share insights, ask questions, and network.
Machine learning is an indispensable tool for data scientists, enabling them to extract valuable insights, build predictive models, and automate data analysis processes. By mastering machine learning techniques and developing the necessary skills, data scientists can drive innovation, solve complex problems, and make data-informed decisions that benefit organizations and society.
Ready to enhance your data science skills and master machine learning? Visit learns.edu.vn today to explore our comprehensive courses and resources. Unlock your potential and transform your career with our expert-led programs designed to equip you with the knowledge and skills you need to succeed in the world of data science. Contact us at 123 Education Way, Learnville, CA 90210, United States or WhatsApp +1 555-555-1212.
