Data science and machine learning are undeniably intertwined, but do you absolutely need data science to delve into the world of machine learning? Yes, you do need data science for machine learning. Machine learning is a subset of data science, so understanding data science principles is crucial for effectively applying machine learning techniques. At LEARNS.EDU.VN, we break down the essentials to help you navigate this landscape.
Data science lays the foundation, providing the context, tools, and techniques to prepare, analyze, and interpret data, all of which are vital for successful machine learning projects. Enhance your learning journey with insights into statistical modeling, data visualization, and predictive analytics to discover the data-driven world through data mining, machine learning algorithms, and big data analytics.
1. Understanding the Relationship Between Data Science and Machine Learning
The relationship between data science and machine learning can be best understood by recognizing that machine learning is a subset, a powerful tool within the broader field of data science.
- Data Science: An interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It encompasses a wide range of activities, including data collection, cleaning, analysis, visualization, and interpretation.
- Machine Learning: A subset of artificial intelligence (AI) that focuses on enabling systems to learn from data without being explicitly programmed. It involves developing algorithms that can automatically learn patterns and make predictions or decisions based on data.
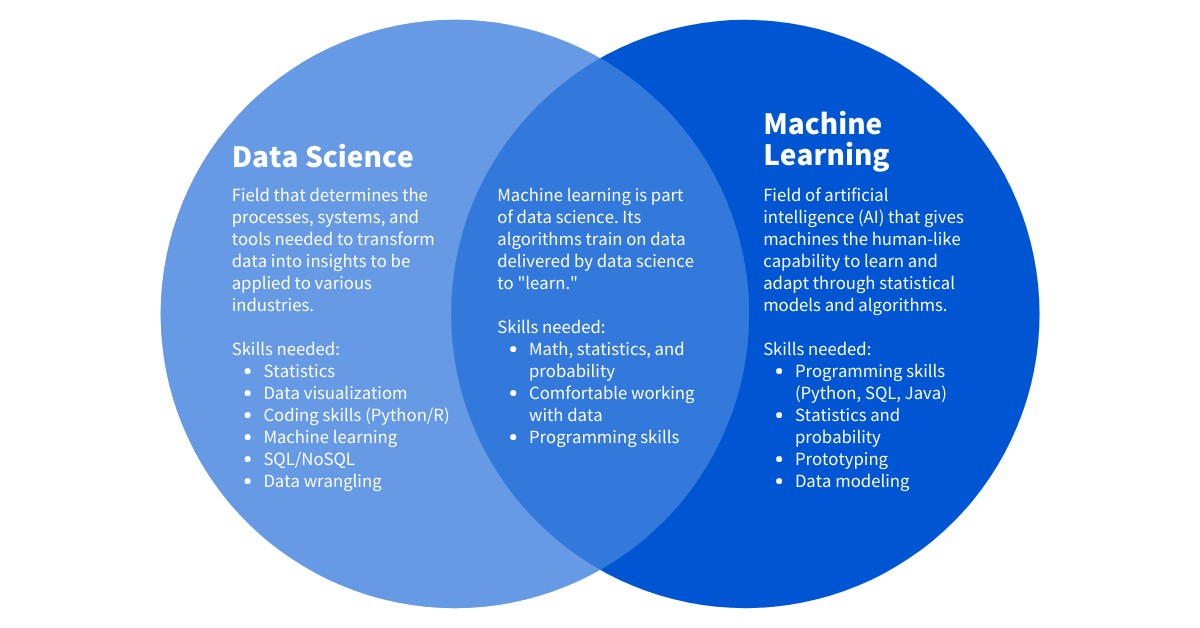 Venn Diagram Illustrating the Relationship Between Data Science and Machine Learning
Venn Diagram Illustrating the Relationship Between Data Science and Machine Learning
1.1. Data Science as the Umbrella
Data science provides the overarching framework for working with data. It includes:
- Data Collection: Gathering data from various sources.
- Data Cleaning: Handling missing values, outliers, and inconsistencies.
- Data Exploration: Understanding data through summary statistics and visualizations.
- Data Analysis: Applying statistical methods and machine learning algorithms to uncover patterns.
- Data Interpretation: Drawing meaningful conclusions and communicating insights.
1.2. Machine Learning as a Tool
Machine learning is a specific set of techniques used within data science to automate prediction and decision-making processes. It focuses on building models that can learn from data and improve their performance over time.
1.3. Why Data Science is Essential for Machine Learning
Without a solid understanding of data science principles, applying machine learning can be ineffective or even misleading. Here’s why:
- Data Preparation: Machine learning models require clean, well-prepared data to perform effectively. Data science skills are essential for handling data quality issues.
- Feature Engineering: Selecting and transforming relevant features from raw data is crucial for model performance. This requires domain knowledge and data understanding, both of which are part of data science.
- Model Selection: Choosing the right machine learning algorithm depends on the nature of the problem and the characteristics of the data. Data science provides the knowledge to make informed decisions.
- Model Evaluation: Assessing the performance of a machine learning model requires statistical techniques and domain expertise to ensure the results are meaningful and reliable.
- Interpretation: Understanding and explaining the results of a machine learning model is essential for making informed decisions. Data science helps translate model outputs into actionable insights.
2. Key Data Science Skills Needed for Machine Learning
To effectively leverage machine learning, several data science skills are essential. These skills ensure that you can handle data, build appropriate models, and interpret results accurately.
2.1. Statistical Analysis
Statistical analysis is fundamental to understanding data and evaluating machine learning models.
- Descriptive Statistics: Calculating measures like mean, median, standard deviation, and percentiles to summarize data distributions.
- Inferential Statistics: Using sample data to make inferences about populations, including hypothesis testing and confidence intervals.
- Regression Analysis: Modeling the relationship between variables to make predictions.
- Time Series Analysis: Analyzing data points indexed in time order to forecast future values.
Example: Understanding p-values in hypothesis testing is crucial for determining whether the results of a machine learning experiment are statistically significant or due to random chance.
2.2. Data Visualization
Data visualization helps in exploring data, identifying patterns, and communicating findings effectively.
- Histograms: Displaying the distribution of a single variable.
- Scatter Plots: Showing the relationship between two variables.
- Box Plots: Summarizing the distribution of data, including quartiles and outliers.
- Heatmaps: Visualizing the correlation between multiple variables.
Example: Creating scatter plots to visualize the relationship between features and target variables can help identify potential predictors for a machine learning model.
2.3. Data Wrangling and Preprocessing
Data wrangling involves cleaning, transforming, and preparing data for analysis.
- Handling Missing Values: Imputing missing data using techniques like mean imputation, median imputation, or model-based imputation.
- Outlier Detection and Treatment: Identifying and handling outliers using methods like Z-score, IQR, or clustering.
- Data Transformation: Scaling or normalizing data to ensure that all features contribute equally to the model.
- Feature Engineering: Creating new features from existing ones to improve model performance.
Example: Using Python libraries like Pandas to clean and preprocess data, ensuring that it is in the right format for machine learning algorithms.
2.4. Programming Skills
Programming skills are essential for implementing data science and machine learning tasks.
- Python: A versatile language with rich libraries like NumPy, Pandas, Scikit-learn, and TensorFlow.
- R: A language specifically designed for statistical computing and graphics.
- SQL: Used for querying and managing data in relational databases.
Example: Writing Python scripts to automate data cleaning, feature engineering, and model training.
2.5. Domain Knowledge
Domain knowledge is the understanding of the specific industry or field in which you are applying data science and machine learning.
- Industry-Specific Knowledge: Understanding the unique challenges and opportunities in a particular industry.
- Business Acumen: Understanding how data insights can drive business decisions and improve outcomes.
- Contextual Awareness: Being able to interpret data and model results within the context of the business or industry.
Example: Applying machine learning to predict customer churn in the telecommunications industry requires understanding the factors that influence customer behavior in that specific domain.
3. How Data Science Principles Enhance Machine Learning Projects
Data science principles provide a structured approach to machine learning projects, ensuring that they are well-defined, properly executed, and deliver meaningful results.
3.1. Problem Definition
Clearly defining the problem is the first step in any data science or machine learning project.
- Understanding the Business Need: Identifying the specific business problem that needs to be addressed.
- Defining the Objectives: Setting clear, measurable, achievable, relevant, and time-bound (SMART) objectives.
- Identifying the Target Variable: Determining the variable that needs to be predicted or classified.
Example: In a marketing campaign, the problem might be to increase customer engagement. The objective could be to increase click-through rates by 20% within three months.
3.2. Data Collection and Preparation
Collecting and preparing data is a critical step that can significantly impact the performance of machine learning models.
- Gathering Data: Collecting data from various sources, including databases, APIs, and files.
- Cleaning Data: Handling missing values, outliers, and inconsistencies.
- Transforming Data: Scaling, normalizing, or encoding data to make it suitable for machine learning algorithms.
Example: Collecting customer data from a CRM system, cleaning it to remove duplicates and errors, and transforming it to a numerical format for machine learning.
3.3. Feature Selection and Engineering
Selecting the right features and engineering new ones can greatly improve model accuracy.
- Feature Selection: Choosing the most relevant features from the dataset.
- Feature Engineering: Creating new features from existing ones that might be more informative for the model.
Example: Selecting the most important features from a customer dataset, such as purchase history, demographics, and browsing behavior, and engineering new features like recency, frequency, and monetary value (RFM) scores.
3.4. Model Selection and Training
Choosing the right machine learning model and training it effectively is crucial for achieving desired results.
- Choosing the Right Model: Selecting a model that is appropriate for the problem and the data.
- Training the Model: Using the training data to teach the model to recognize patterns and make predictions.
- Hyperparameter Tuning: Optimizing the model’s parameters to improve its performance.
Example: Choosing a decision tree or random forest model for classification tasks, training it on a labeled dataset, and tuning the hyperparameters to maximize accuracy.
3.5. Model Evaluation and Validation
Evaluating and validating the model is essential to ensure that it generalizes well to new data.
- Splitting Data: Dividing the data into training, validation, and test sets.
- Evaluating Performance: Using metrics like accuracy, precision, recall, and F1-score to assess the model’s performance.
- Validating Results: Testing the model on a separate test set to ensure that it generalizes well.
Example: Splitting the data into 70% training, 15% validation, and 15% test sets, evaluating the model’s performance on the validation set, and validating the results on the test set to ensure that it generalizes well.
3.6. Deployment and Monitoring
Deploying the model and monitoring its performance over time is essential to ensure that it continues to deliver value.
- Deploying the Model: Integrating the model into a production environment.
- Monitoring Performance: Tracking the model’s performance over time and retraining it as needed.
- Gathering Feedback: Collecting feedback from users to improve the model.
Example: Deploying a machine learning model to predict customer churn, monitoring its performance over time, and retraining it with new data to ensure that it continues to deliver accurate predictions.
4. Real-World Examples of Data Science in Machine Learning
Several real-world examples illustrate how data science principles are applied in machine learning projects to solve complex problems and drive business value.
4.1. Fraud Detection
In the financial industry, machine learning is used to detect fraudulent transactions. Data science principles are applied to:
- Collect Data: Gather transaction data, customer data, and historical fraud data.
- Prepare Data: Clean and preprocess the data, handling missing values and outliers.
- Engineer Features: Create features like transaction frequency, amount, and location.
- Train Model: Train a machine learning model to identify patterns of fraudulent behavior.
- Evaluate Model: Evaluate the model’s performance using metrics like precision and recall.
- Deploy Model: Deploy the model to detect fraudulent transactions in real-time.
Example: Banks use machine learning models to analyze transaction data and identify suspicious patterns, such as unusual transaction amounts, locations, or frequencies, to prevent fraud.
4.2. Customer Churn Prediction
Companies use machine learning to predict which customers are likely to churn. Data science principles are applied to:
- Collect Data: Gather customer data, including demographics, purchase history, and customer service interactions.
- Prepare Data: Clean and preprocess the data, handling missing values and outliers.
- Engineer Features: Create features like recency, frequency, and monetary value (RFM) scores.
- Train Model: Train a machine learning model to predict which customers are likely to churn.
- Evaluate Model: Evaluate the model’s performance using metrics like accuracy and AUC.
- Deploy Model: Deploy the model to identify customers at risk of churn and take proactive measures to retain them.
Example: Telecommunications companies use machine learning models to analyze customer data and predict which customers are likely to switch to a competitor, allowing them to offer incentives or personalized services to retain those customers.
4.3. Recommendation Systems
E-commerce companies use machine learning to recommend products to customers. Data science principles are applied to:
- Collect Data: Gather data on customer behavior, including purchase history, browsing behavior, and ratings.
- Prepare Data: Clean and preprocess the data, handling missing values and outliers.
- Engineer Features: Create features like customer preferences and product attributes.
- Train Model: Train a machine learning model to predict which products a customer is likely to purchase.
- Evaluate Model: Evaluate the model’s performance using metrics like click-through rate and conversion rate.
- Deploy Model: Deploy the model to recommend products to customers in real-time.
Example: Amazon uses machine learning models to analyze customer behavior and recommend products that customers are likely to purchase, increasing sales and customer satisfaction.
4.4. Medical Diagnosis
In healthcare, machine learning is used to assist in medical diagnosis. Data science principles are applied to:
- Collect Data: Gather medical data, including patient history, test results, and imaging data.
- Prepare Data: Clean and preprocess the data, handling missing values and outliers.
- Engineer Features: Create features like patient demographics, symptoms, and medical history.
- Train Model: Train a machine learning model to predict the likelihood of a particular diagnosis.
- Evaluate Model: Evaluate the model’s performance using metrics like accuracy, sensitivity, and specificity.
- Deploy Model: Deploy the model to assist doctors in making accurate diagnoses.
Example: Hospitals use machine learning models to analyze medical images and patient data to detect diseases like cancer early, improving patient outcomes.
5. Building Your Data Science Foundation for Machine Learning
Building a strong data science foundation is essential for anyone looking to excel in machine learning. Here are the steps you can take to acquire the necessary skills and knowledge.
5.1. Formal Education
Consider pursuing formal education in data science or a related field.
- Bachelor’s Degree: A bachelor’s degree in data science, statistics, mathematics, or computer science can provide a solid foundation in the fundamental concepts.
- Master’s Degree: A master’s degree in data science or a related field can provide more advanced knowledge and skills.
- Online Courses and Certifications: Online courses and certifications from platforms like Coursera, edX, and Udacity can provide flexible learning options.
Example: Enrolling in a data science master’s program at a reputable university or completing a data science professional certification online.
5.2. Online Resources and Courses
Leverage online resources and courses to learn specific data science skills.
- Coursera: Offers courses and specializations in data science, machine learning, and related topics.
- edX: Provides courses and programs from top universities and institutions.
- Udacity: Offers nanodegrees in data science and machine learning.
- Kaggle: Provides datasets, tutorials, and competitions to practice data science skills.
Example: Taking online courses on statistical analysis, data visualization, and machine learning using Python.
5.3. Practice with Real-World Projects
Working on real-world projects is essential for applying your knowledge and building your portfolio.
- Kaggle Competitions: Participating in Kaggle competitions to solve real-world data science problems.
- Personal Projects: Working on personal projects to apply your skills to problems that interest you.
- Open Source Contributions: Contributing to open-source data science projects.
Example: Building a machine learning model to predict stock prices or analyzing customer data to identify marketing opportunities.
5.4. Networking and Community Engagement
Networking and engaging with the data science community can provide valuable learning and career opportunities.
- Attending Conferences: Attending data science conferences and meetups to learn from experts and network with peers.
- Joining Online Communities: Participating in online communities like Reddit, Stack Overflow, and LinkedIn groups.
- Contributing to Blogs and Forums: Sharing your knowledge and insights by contributing to data science blogs and forums.
Example: Attending a data science conference to learn about the latest trends and technologies or joining a LinkedIn group to connect with other data scientists.
6. Tools and Technologies for Data Science and Machine Learning
Several tools and technologies are essential for data science and machine learning projects. Familiarizing yourself with these tools can significantly enhance your productivity and effectiveness.
6.1. Programming Languages
- Python: A versatile language with rich libraries for data science and machine learning.
- R: A language specifically designed for statistical computing and graphics.
6.2. Data Manipulation and Analysis Libraries
- Pandas: A Python library for data manipulation and analysis.
- NumPy: A Python library for numerical computing.
- dplyr: An R package for data manipulation.
- data.table: An R package for fast data manipulation.
6.3. Machine Learning Libraries
- Scikit-learn: A Python library for machine learning.
- TensorFlow: A Python library for deep learning.
- Keras: A Python library for deep learning.
- PyTorch: A Python library for deep learning.
6.4. Data Visualization Tools
- Matplotlib: A Python library for creating static, interactive, and animated visualizations.
- Seaborn: A Python library for creating informative and attractive statistical graphics.
- ggplot2: An R package for creating elegant data visualizations.
- Tableau: A data visualization tool for creating interactive dashboards and reports.
6.5. Big Data Technologies
- Hadoop: A framework for distributed storage and processing of large datasets.
- Spark: A fast and general-purpose cluster computing system.
- SQL: A language for querying and managing data in relational databases.
- NoSQL: A class of database management systems that do not use SQL as their primary query language.
7. The Future of Data Science and Machine Learning
The fields of data science and machine learning are rapidly evolving, with new technologies and techniques emerging all the time. Staying up-to-date with the latest trends and developments is essential for anyone working in these fields.
7.1. Automation of Machine Learning
Automated machine learning (AutoML) is a growing trend that aims to automate the process of building and deploying machine learning models. AutoML tools can automatically perform tasks like data preprocessing, feature engineering, model selection, and hyperparameter tuning, making machine learning more accessible to non-experts.
7.2. Explainable AI
Explainable AI (XAI) is a field that focuses on developing machine learning models that are transparent and interpretable. XAI techniques can help users understand how a model makes its decisions, which is important for building trust and ensuring that models are used ethically and responsibly.
7.3. Edge Computing
Edge computing involves processing data closer to the source, rather than sending it to a centralized data center. Edge computing can improve the performance and efficiency of machine learning applications by reducing latency and bandwidth requirements.
7.4. Quantum Computing
Quantum computing is a new paradigm of computing that uses quantum mechanics to solve complex problems that are beyond the reach of classical computers. Quantum computing has the potential to revolutionize machine learning by enabling the development of new algorithms and models.
8. Overcoming Challenges in Learning Data Science for Machine Learning
Learning data science for machine learning can be challenging, but with the right approach and resources, you can overcome these obstacles and achieve your goals.
8.1. Lack of Prior Knowledge
If you don’t have a background in mathematics, statistics, or computer science, it can be difficult to grasp the fundamental concepts of data science and machine learning. To overcome this challenge:
- Start with the Basics: Focus on learning the fundamental concepts first, before moving on to more advanced topics.
- Take Introductory Courses: Enroll in introductory courses on mathematics, statistics, and computer science.
- Use Online Resources: Leverage online resources like tutorials, videos, and articles to learn at your own pace.
8.2. Overwhelming Amount of Information
The fields of data science and machine learning are vast and constantly evolving, which can be overwhelming for beginners. To overcome this challenge:
- Focus on a Specific Area: Choose a specific area of data science or machine learning to focus on, such as natural language processing or computer vision.
- Follow a Structured Learning Path: Follow a structured learning path that covers the essential topics in a logical order.
- Stay Up-to-Date: Stay up-to-date with the latest trends and developments by reading blogs, attending conferences, and participating in online communities.
8.3. Difficulty Applying Knowledge
It can be difficult to apply your knowledge to real-world problems, especially if you don’t have access to real-world datasets and projects. To overcome this challenge:
- Work on Personal Projects: Work on personal projects to apply your skills to problems that interest you.
- Participate in Kaggle Competitions: Participate in Kaggle competitions to solve real-world data science problems.
- Contribute to Open Source Projects: Contribute to open-source data science projects.
8.4. Lack of Motivation
Learning data science and machine learning can be a long and challenging process, and it’s easy to lose motivation along the way. To overcome this challenge:
- Set Realistic Goals: Set realistic goals that are achievable and measurable.
- Find a Mentor: Find a mentor who can provide guidance and support.
- Join a Community: Join a community of learners who can provide encouragement and motivation.
9. Resources at LEARNS.EDU.VN for Data Science and Machine Learning
At LEARNS.EDU.VN, we are committed to providing high-quality resources and support to help you succeed in your data science and machine learning journey.
9.1. Comprehensive Courses
We offer a wide range of comprehensive courses covering various topics in data science and machine learning. Our courses are designed to provide you with the knowledge and skills you need to excel in these fields.
Table: Comprehensive Courses at LEARNS.EDU.VN
| Course Title | Description |
|---|---|
| Introduction to Data Science | This course provides an overview of the field of data science, including data collection, data cleaning, data analysis, and data visualization. |
| Machine Learning Fundamentals | This course covers the fundamental concepts of machine learning, including supervised learning, unsupervised learning, and reinforcement learning. |
| Deep Learning with TensorFlow and Keras | This course teaches you how to build and train deep learning models using TensorFlow and Keras. |
| Data Visualization with Python | This course teaches you how to create informative and attractive data visualizations using Python libraries like Matplotlib and Seaborn. |
| Statistical Analysis for Data Science | This course covers the statistical concepts and techniques that are essential for data science, including descriptive statistics, inferential statistics, and hypothesis testing. |
| Big Data Analytics with Hadoop and Spark | This course teaches you how to process and analyze large datasets using Hadoop and Spark. |
| Natural Language Processing with Python | This course teaches you how to process and analyze text data using Python libraries like NLTK and SpaCy. |
| Computer Vision with Python | This course teaches you how to process and analyze images and videos using Python libraries like OpenCV and TensorFlow. |
| Time Series Analysis and Forecasting with Python | This course covers the techniques for analyzing time series data and making predictions about future values. |
| Recommender Systems with Machine Learning | This course teaches you how to build recommender systems using machine learning algorithms. |
| Practical Data Science for Business Professionals | This course equips business professionals with the foundational knowledge and practical skills to leverage data science in their roles, covering data analysis, visualization, and decision-making using real-world business cases. |
9.2. Expert Instructors
Our courses are taught by experienced instructors who are experts in their fields. They are passionate about teaching and committed to helping you succeed.
9.3. Hands-On Projects
Our courses include hands-on projects that allow you to apply your knowledge and build your portfolio. Working on real-world projects is essential for solidifying your understanding and demonstrating your skills to potential employers.
9.4. Community Support
We have a vibrant community of learners who are passionate about data science and machine learning. You can connect with other learners, ask questions, and share your knowledge in our online forums.
9.5. Career Resources
We provide career resources to help you find a job in data science or machine learning. Our career resources include resume review, interview preparation, and job search tips.
10. FAQs About Data Science and Machine Learning
10.1. What is the difference between data science and machine learning?
Data science is a broad field that encompasses the entire process of extracting knowledge and insights from data. Machine learning is a subset of data science that focuses on building algorithms that can learn from data and make predictions or decisions.
10.2. Do I need a degree in data science to work in machine learning?
While a degree in data science can be helpful, it is not always required. Many successful machine learning professionals come from diverse backgrounds, such as mathematics, statistics, computer science, and engineering.
10.3. What programming languages are used in data science and machine learning?
The most popular programming languages for data science and machine learning are Python and R. Python is widely used due to its rich ecosystem of libraries for data manipulation, analysis, and machine learning. R is also popular for statistical computing and graphics.
10.4. What are some popular machine learning algorithms?
Some popular machine learning algorithms include linear regression, logistic regression, decision trees, random forests, support vector machines, and neural networks.
10.5. How can I get started with data science and machine learning?
You can get started with data science and machine learning by taking online courses, reading books, working on personal projects, and participating in online communities.
10.6. What are some common applications of machine learning?
Machine learning is used in a wide range of applications, including fraud detection, customer churn prediction, recommendation systems, medical diagnosis, and self-driving cars.
10.7. What are the ethical considerations in data science and machine learning?
Ethical considerations in data science and machine learning include fairness, transparency, accountability, and privacy. It is important to ensure that machine learning models are used ethically and responsibly.
10.8. How can I stay up-to-date with the latest trends in data science and machine learning?
You can stay up-to-date with the latest trends in data science and machine learning by reading blogs, attending conferences, participating in online communities, and following experts on social media.
10.9. What are the career opportunities in data science and machine learning?
Career opportunities in data science and machine learning include data scientist, machine learning engineer, data analyst, data engineer, and business intelligence analyst.
10.10. What skills are required to be a data scientist?
To become a data scientist, you need a strong foundation in mathematics, statistics, computer science, and domain knowledge. You also need to be proficient in programming languages like Python and R, as well as data manipulation, analysis, and visualization tools.
Conclusion: Embracing Data Science for Machine Learning Success
While machine learning is a powerful tool on its own, it thrives when grounded in the principles of data science. Data science provides the necessary context, skills, and techniques to ensure that machine learning projects are well-defined, properly executed, and deliver meaningful results. By building a strong data science foundation, you can unlock the full potential of machine learning and drive innovation in various domains.
Ready to take your machine learning skills to the next level? Explore the comprehensive courses and resources available at LEARNS.EDU.VN. Our expert instructors, hands-on projects, and vibrant community will help you build the data science foundation you need to succeed in the exciting world of machine learning.
Contact us today:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: LEARNS.EDU.VN
Start your journey towards becoming a proficient data scientist and machine learning expert with learns.edu.vn! Discover more and enroll now to shape your future in the data-driven world.