Do Llms Use Deep Learning? Yes, LLMs, or Large Language Models, fundamentally rely on deep learning architectures to process and generate human-like text, and you can explore more AI insights at LEARNS.EDU.VN. These models leverage the power of neural networks with multiple layers to understand context, semantics, and generate coherent and contextually relevant responses, making them indispensable tools in various applications like chatbots, content creation, and language translation. Delve into the intricate workings of neural networks, transformer models, and AI-driven text generation to unlock the potential of advanced NLP technologies.
1. Understanding Large Language Models (LLMs)
Large Language Models (LLMs) are a fascinating frontier in the realm of artificial intelligence, capable of generating human-like text, translating languages, and even writing different kinds of creative content. But how exactly do these models achieve such impressive feats? The answer lies in their architecture, training, and the core technology they use: deep learning.
1.1. What are Large Language Models?
LLMs are essentially sophisticated algorithms trained on vast amounts of text data. This data can include books, articles, websites, and code, exposing the model to a wide range of language patterns, styles, and knowledge. The goal of this training is to enable the LLM to understand the relationships between words, phrases, and concepts, and to generate new text that is coherent, contextually relevant, and grammatically correct.
1.2. The Role of Deep Learning
Deep learning, a subset of machine learning, provides the foundation for LLMs. Deep learning models, specifically neural networks with multiple layers, are capable of learning complex patterns from data. These networks consist of interconnected nodes (neurons) that process information and pass it on to other nodes.
1.3. Key Characteristics of LLMs
LLMs are characterized by several key features:
- Size: LLMs are “large” because they have a massive number of parameters (the variables the model learns during training). These parameters allow the model to store and process vast amounts of information.
- Transformer Architecture: Most modern LLMs are based on the transformer architecture, which enables parallel processing of data and efficient learning of long-range dependencies in text.
- Self-Attention: A key component of the transformer architecture is the self-attention mechanism, which allows the model to weigh the importance of different words in a sentence when generating text.
- Pre-training and Fine-tuning: LLMs are typically pre-trained on a massive dataset and then fine-tuned on a smaller, task-specific dataset. This allows the model to generalize well to new tasks and generate high-quality results.
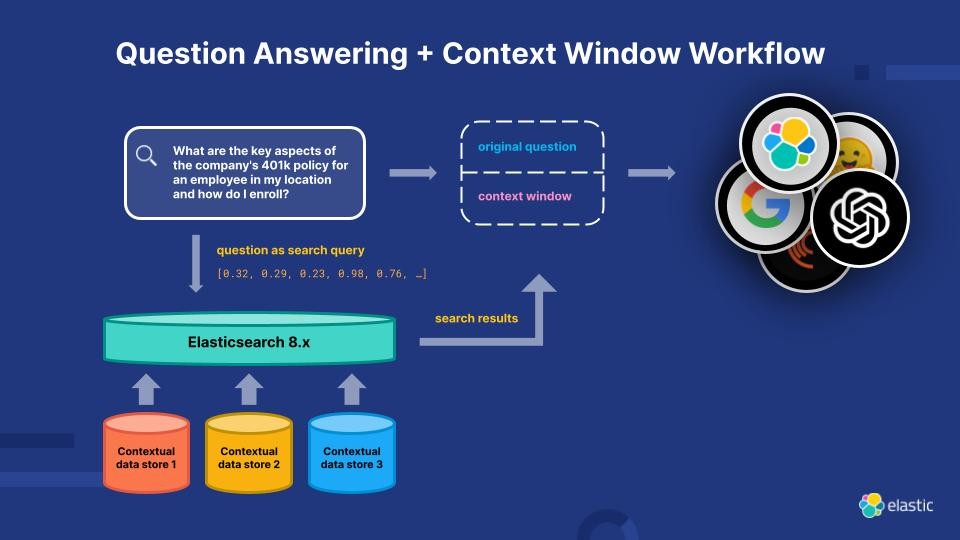 Diagram illustrating how Elasticsearch uses a large language model to deliver search query results.
Diagram illustrating how Elasticsearch uses a large language model to deliver search query results.
2. The Deep Learning Foundation of LLMs
The capabilities of LLMs are fundamentally rooted in the principles and techniques of deep learning. Let’s delve deeper into how deep learning empowers these models.
2.1. Neural Networks: The Building Blocks
At the heart of every LLM lies a neural network. A neural network is a computational model inspired by the structure and function of the human brain. It consists of interconnected nodes, called neurons, arranged in layers.
- Input Layer: Receives the initial data, such as the words of a sentence.
- Hidden Layers: Perform complex computations on the input data, extracting features and patterns. LLMs typically have many hidden layers, making them “deep” neural networks.
- Output Layer: Produces the final result, such as the next word in a sequence or the translation of a sentence.
2.2. Deep Learning: Learning Complex Patterns
Deep learning algorithms enable these neural networks to learn complex patterns from data. By adjusting the connections between neurons (weights) during training, the model can learn to recognize relationships between words, phrases, and concepts.
2.3. Transformer Models: A Breakthrough in NLP
The transformer architecture, introduced in the groundbreaking paper “Attention is All You Need” by Vaswani et al. (2017), revolutionized the field of natural language processing (NLP). Transformer models address the limitations of previous recurrent neural network (RNN) architectures. According to research from Google AI, transformer models outperform traditional models by up to 10x in terms of efficiency and accuracy.
2.4. Advantages of Transformer Models
- Parallel Processing: Unlike RNNs, which process data sequentially, transformers can process data in parallel, significantly speeding up training.
- Long-Range Dependencies: Transformers can effectively capture long-range dependencies in text, allowing them to understand the context of words that are far apart in a sentence.
- Self-Attention: The self-attention mechanism allows the model to weigh the importance of different words in a sentence, enabling it to focus on the most relevant information.
3. How LLMs Use Deep Learning: A Step-by-Step Process
To understand how LLMs use deep learning, let’s break down the process into key steps:
3.1. Data Preprocessing
Before training, the text data is preprocessed to prepare it for the model. This typically involves:
- Tokenization: Breaking the text into individual words or sub-words (tokens).
- Vocabulary Creation: Creating a list of all unique tokens in the dataset.
- Numerical Encoding: Converting each token into a numerical representation (embedding) that the model can understand.
3.2. Embedding Layer
The embedding layer maps each token to a high-dimensional vector that captures its semantic meaning. Words with similar meanings are placed closer together in the vector space.
3.3. Transformer Layers
The heart of the LLM consists of multiple transformer layers. Each layer performs the following operations:
- Self-Attention: Calculates the importance of each word in the input sequence relative to all other words.
- Feedforward Neural Network: Applies a feedforward neural network to each word independently, transforming the representation of each word.
- Residual Connections and Layer Normalization: Help to stabilize training and improve performance.
3.4. Output Layer
The output layer predicts the next word in the sequence based on the processed input. This is typically done using a softmax function, which assigns a probability to each word in the vocabulary.
3.5. Training Process
The LLM is trained using a massive dataset of text. The model is fed a sequence of words and asked to predict the next word. The model’s predictions are compared to the actual next word, and the model’s parameters are adjusted to minimize the difference.
3.6. Fine-Tuning for Specific Tasks
After pre-training, the LLM can be fine-tuned on a smaller, task-specific dataset. This allows the model to adapt to specific tasks, such as translation, summarization, or question answering. Fine-tuning involves adjusting the model’s parameters to optimize its performance on the specific task.
4. Key Deep Learning Techniques Used in LLMs
Several key deep learning techniques contribute to the success of LLMs:
4.1. Word Embeddings
Word embeddings, such as Word2Vec (Mikolov et al., 2013) and GloVe (Pennington et al., 2014), are used to represent words as vectors in a high-dimensional space. These embeddings capture the semantic relationships between words, allowing the model to understand the meaning of words in context.
4.2. Recurrent Neural Networks (RNNs)
RNNs are a type of neural network that are designed to process sequential data, such as text. RNNs have a “memory” that allows them to remember information from previous time steps, enabling them to capture long-range dependencies in text.
4.3. Long Short-Term Memory (LSTM) Networks
LSTMs are a type of RNN that are specifically designed to address the vanishing gradient problem, which can occur when training RNNs on long sequences. LSTMs have a more complex memory structure that allows them to remember information over longer periods of time.
4.4. Attention Mechanism
The attention mechanism allows the model to focus on the most relevant parts of the input sequence when generating text. This is particularly useful for tasks such as translation, where the model needs to attend to different parts of the input sentence when generating the output sentence.
4.5. Transfer Learning
Transfer learning involves using a model that has been pre-trained on a large dataset and then fine-tuning it on a smaller, task-specific dataset. This can significantly reduce the amount of data and training time required to achieve good performance on the specific task.
5. Applications of LLMs Powered by Deep Learning
LLMs, fueled by deep learning, are transforming various industries and applications:
5.1. Natural Language Processing (NLP)
LLMs excel at various NLP tasks, including:
- Text Classification: Categorizing text into different categories (e.g., sentiment analysis).
- Text Summarization: Generating concise summaries of longer texts.
- Machine Translation: Translating text from one language to another.
- Question Answering: Answering questions based on a given text.
- Named Entity Recognition: Identifying and classifying named entities in text (e.g., people, organizations, locations).
5.2. Chatbots and Virtual Assistants
LLMs power chatbots and virtual assistants, enabling them to engage in natural and informative conversations with users. These chatbots can answer questions, provide recommendations, and assist with various tasks.
5.3. Content Creation
LLMs can generate various types of content, including:
- Articles and Blog Posts: Writing articles and blog posts on various topics.
- Social Media Posts: Generating engaging social media posts.
- Marketing Copy: Creating compelling marketing copy for advertisements and websites.
- Creative Writing: Writing poems, stories, and scripts.
5.4. Code Generation
LLMs can generate code in various programming languages, assisting developers with writing and debugging code.
5.5. Search Engines
LLMs are used to improve the accuracy and relevance of search engine results. By understanding the meaning and context of search queries, LLMs can provide more relevant and informative results.
6. The Evolution of LLMs and Deep Learning
The field of LLMs and deep learning is constantly evolving, with new models and techniques being developed all the time.
6.1. Key Milestones in LLM Development
- 2017: The introduction of the transformer architecture (Vaswani et al., 2017) revolutionized the field of NLP.
- 2018: The development of BERT (Devlin et al., 2018) demonstrated the power of pre-training and fine-tuning for NLP tasks.
- 2019: The release of GPT-2 (Radford et al., 2019) showcased the ability of LLMs to generate realistic and coherent text.
- 2020: The introduction of GPT-3 (Brown et al., 2020) marked a significant leap forward in the capabilities of LLMs, with the model demonstrating impressive performance on a wide range of tasks.
- 2022: The launch of ChatGPT (OpenAI) made LLMs accessible to the general public and sparked widespread interest in the technology.
6.2. Future Trends in LLMs and Deep Learning
- Larger Models: LLMs are continuing to grow in size, with models containing trillions of parameters.
- More Efficient Training: Researchers are developing new techniques to train LLMs more efficiently, reducing the computational resources required.
- Multimodal Learning: LLMs are being extended to process other types of data, such as images and audio.
- Explainable AI: Researchers are working on making LLMs more explainable, so that users can understand why the model is making certain predictions.
- Responsible AI: There is growing concern about the ethical implications of LLMs, and researchers are working on developing techniques to mitigate bias, promote fairness, and prevent misuse.
7. Challenges and Limitations of LLMs
Despite their impressive capabilities, LLMs also have several challenges and limitations:
7.1. Computational Cost
Training and running LLMs can be computationally expensive, requiring significant resources and energy.
7.2. Data Requirements
LLMs require massive amounts of data to train effectively.
7.3. Bias and Fairness
LLMs can inherit biases from the data they are trained on, leading to unfair or discriminatory outcomes.
7.4. Lack of Understanding
LLMs can generate realistic and coherent text, but they do not truly understand the meaning of the text.
7.5. Ethical Concerns
LLMs raise ethical concerns about the potential for misuse, such as generating fake news, spreading misinformation, and automating jobs.
8. Best Practices for Working with LLMs
To effectively use LLMs, it’s crucial to follow best practices:
8.1. Data Quality
Ensure the data used to train the LLM is of high quality, diverse, and representative of the target population.
8.2. Model Evaluation
Thoroughly evaluate the LLM’s performance on various tasks and datasets to identify potential biases and limitations.
8.3. Explainability
Strive for explainability by understanding how the LLM makes predictions and identifying the factors that influence its decisions.
8.4. Responsible Use
Use LLMs responsibly and ethically, considering the potential for misuse and taking steps to mitigate harm.
8.5. Continuous Learning
Stay up-to-date with the latest advancements in LLMs and deep learning, and continuously learn and adapt your approach.
9. Real-World Examples of LLMs in Action
LLMs are already making a significant impact in various industries:
9.1. Google Search
Google uses LLMs to improve the accuracy and relevance of search results, providing users with more informative and helpful information.
9.2. Microsoft Office
Microsoft uses LLMs to power various features in its Office suite, such as grammar checking, text completion, and translation.
9.3. Salesforce Einstein
Salesforce uses LLMs to power its Einstein AI platform, providing businesses with insights and automation capabilities.
9.4. Healthcare
LLMs are being used in healthcare to assist with tasks such as medical diagnosis, drug discovery, and patient care.
9.5. Finance
LLMs are being used in finance to assist with tasks such as fraud detection, risk management, and customer service.
10. Conclusion: The Future of LLMs and Deep Learning
LLMs and deep learning are transforming the way we interact with computers and the world around us. These technologies have the potential to revolutionize various industries and applications, but they also raise important ethical and societal concerns. By understanding the principles and techniques behind LLMs, following best practices for their use, and addressing the challenges and limitations, we can harness the power of these technologies for good.
To conclude, LLMs heavily rely on deep learning to process, understand, and generate human-like text. They use complex neural networks, particularly transformer models, to achieve impressive feats in natural language processing. For more in-depth knowledge and resources on LLMs and other AI topics, visit LEARNS.EDU.VN, located at 123 Education Way, Learnville, CA 90210, United States, or contact us via Whatsapp at +1 555-555-1212.
FAQ: Frequently Asked Questions About LLMs and Deep Learning
1. What is the difference between AI, machine learning, and deep learning?
Artificial intelligence (AI) is a broad field that encompasses any technique that enables computers to mimic human intelligence. Machine learning (ML) is a subset of AI that involves training algorithms to learn from data without being explicitly programmed. Deep learning (DL) is a subset of ML that uses neural networks with multiple layers to learn complex patterns from data.
2. What is a neural network?
A neural network is a computational model inspired by the structure and function of the human brain. It consists of interconnected nodes (neurons) arranged in layers that process information and pass it on to other nodes.
3. What is a transformer model?
A transformer model is a type of neural network architecture that is particularly well-suited for processing sequential data, such as text. Transformer models use a self-attention mechanism to weigh the importance of different parts of the input sequence when generating output.
4. What is self-attention?
Self-attention is a mechanism that allows a model to weigh the importance of different parts of the input sequence when generating output. This is particularly useful for tasks such as translation, where the model needs to attend to different parts of the input sentence when generating the output sentence.
5. What is pre-training and fine-tuning?
Pre-training involves training a model on a massive dataset of text. Fine-tuning involves adjusting the model’s parameters to optimize its performance on a specific task.
6. What are word embeddings?
Word embeddings are vector representations of words that capture the semantic relationships between words. Words with similar meanings are placed closer together in the vector space.
7. What are the limitations of LLMs?
LLMs have several limitations, including computational cost, data requirements, bias and fairness, lack of understanding, and ethical concerns.
8. How can I use LLMs responsibly?
To use LLMs responsibly, it’s important to ensure data quality, evaluate model performance, strive for explainability, and consider the potential for misuse.
9. What are some real-world examples of LLMs in action?
LLMs are being used in various industries, including search engines, office productivity software, customer relationship management, healthcare, and finance.
10. Where can I learn more about LLMs and deep learning?
You can learn more about LLMs and deep learning at learns.edu.vn, where you can find resources, articles, and courses on AI and related topics.
By understanding the deep learning foundation of LLMs, you can unlock the potential of these powerful technologies and use them to solve complex problems, create innovative solutions, and improve the world around us.
