Convolutional Neural Networks (CNNs) are essential for image recognition and various computer vision tasks, and LEARNS.EDU.VN offers a comprehensive guide to understanding their workings. This article will explain how CNNs operate, their benefits, and their applications in deep learning, while also highlighting key deep learning concepts.
1. Understanding Convolutional Neural Networks (CNNs)
1.1. What is a Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN), or ConvNet, is a specialized deep neural network primarily used for analyzing visual data. Unlike traditional neural networks that rely solely on matrix multiplications, CNN architecture incorporates a technique called convolution. This process combines two functions to show how one modifies the other, effectively reducing images into a more manageable form without losing critical features needed for accurate predictions.
1.2. The Essence of CNNs
The main goal of CNNs is to simplify images for easier processing while retaining the vital features necessary for making precise predictions. This is achieved through convolutional layers that automatically learn and extract relevant features from the input images.
2. How CNNs Function: A Detailed Explanation
2.1. Representing Images: The Basics
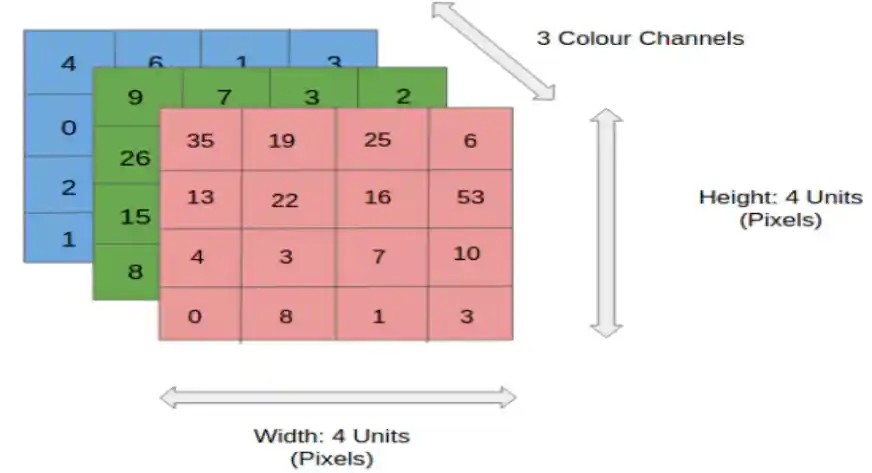
To understand how CNNs work, it’s important to first understand how images are represented. An RGB image is essentially a matrix of pixel values with three planes, representing the red, green, and blue color channels. A grayscale image is similar but has only one plane, representing varying shades of gray.
2.2. The Convolution Process
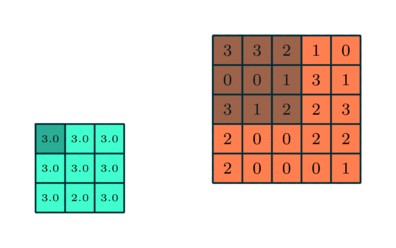
The convolution process is central to CNNs. It involves applying a filter or kernel (a small matrix, typically 3×3) to the input image. This filter slides over the image, performing element-wise multiplication and summing the results to produce a convolved feature. This feature map is then passed on to the next layer.
2.3. RGB Color Channels
For RGB color images, the CNN processes each color channel separately. The animation below illustrates how a ConvNet operates on RGB color images, applying filters to each channel and combining the results.
2.4. Key Components of CNN Layers
The number of parameters in a CNN layer depends on the size of the receptive fields (filter kernels) and the number of filters. Each neuron in a CNN layer receives inputs from a local region of the previous layer, known as its receptive field. These receptive fields move across the input, calculating dot products and creating a convolved feature map as the output. Typically, this map then undergoes a rectified linear unit (ReLU) activation function to introduce non-linearity.
2.5. The Role of Artificial Neurons
CNNs are composed of multiple layers of artificial neurons, which are mathematical functions that mimic biological neurons. These neurons calculate the weighted sum of multiple inputs and output an activation value. When an image is fed into a ConvNet, each layer generates several activation functions that are passed to the next layer for feature extraction.
3. Feature Extraction in CNNs
3.1. Layer-by-Layer Feature Detection
The initial layers of a CNN typically extract basic features such as horizontal or diagonal edges. These outputs are then passed to subsequent layers, which detect more complex features like corners or combinational edges. As the data moves deeper into the network, it can identify even more complex features, such as objects and faces. Unlike recurrent neural networks, CNNs are feed-forward networks that process input data in a single pass.
3.2. Classification Layer
Based on the activation map of the final convolution layer, the classification layer outputs a set of confidence scores (values between 0 and 1) that indicate the likelihood of the image belonging to a specific class. For example, a ConvNet trained to detect cats, dogs, and horses will output the probability that the input data contains any of these animals. Gradient descent is commonly used during training to adjust the weights of the input layer and subsequent layers.
4. The Evolution of CNNs in Deep Learning
4.1. Early Development
CNNs were initially developed and used around the 1980s. Early CNNs were limited to recognizing handwritten digits and were primarily used in the postal sector to read zip codes and pin codes.
4.2. Challenges and Limitations
Deep learning models require large amounts of data and significant computing resources for training, which posed a major challenge for early CNNs. Backpropagation, the algorithm used to train neural networks, was also computationally expensive at the time.
4.3. Revival of CNNs
In 2012, Alex Krizhevsky recognized the potential to revive deep learning using multi-layered neural networks. This revival was driven by:
- The availability of large datasets.
- The creation of specialized datasets like ImageNet, containing millions of labeled images.
- The increased availability of computing resources.
These advancements enabled researchers to improve upon earlier approaches to deep learning.
5. The Role of Pooling Layers
5.1. Reducing Computational Power
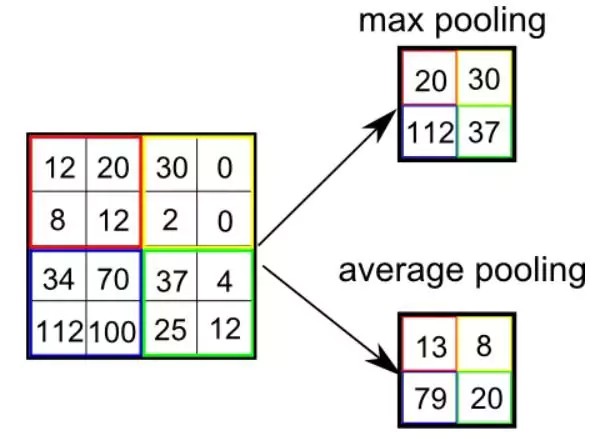
The pooling layer reduces the spatial size of the convolved feature, which decreases the computational power required to process the data by reducing the dimensions. There are two types of pooling: average pooling and max pooling.
5.2. Max Pooling
Max pooling involves finding the maximum pixel value from a portion of the image covered by the kernel. It acts as a noise suppressant by discarding noisy activations and performing de-noising along with dimensionality reduction.
5.3. Average Pooling
Average pooling returns the average of all the values from the portion of the image covered by the kernel. While it performs dimensionality reduction, it is less effective as a noise-suppressing mechanism compared to max pooling.
6. Limitations of CNNs
6.1. Understanding Image Content
Despite their power, CNNs primarily recognize patterns and minute details but struggle with understanding the overall content of an image. For example, a CNN might detect a person in their mid-30s and a child around 10 years old, but it cannot infer the relationship or context, such as a father and son enjoying a day out.
6.2. Practical Applications
This limitation is evident in practical applications like content moderation on social media. CNNs, despite being trained on vast datasets, often fail to completely block inappropriate content.
6.3. Real-World Scenarios
Studies indicate that CNNs trained on datasets like ImageNet often struggle to detect objects when lighting conditions or viewing angles change. Despite these limitations, CNNs have significantly advanced artificial intelligence and are widely used in applications such as facial recognition, image search, photo editing, and augmented reality.
7. Advantages and Disadvantages of CNNs
7.1. Advantages
| Advantage | Description |
|---|---|
| Automatic Feature Learning | CNNs automatically learn features without manual extraction, which simplifies the development process. |
| Shared Weights | The use of shared weights reduces the number of parameters, improving efficiency and reducing computational load. |
| Position Invariance | CNNs can recognize patterns regardless of their position in the input, making them robust to variations in images. |
| Effective Feature Capture | CNNs effectively capture both low-level and high-level features, enabling comprehensive image analysis. |
| Versatility | CNNs are versatile and applicable to various types of data, including images, audio, video, and text. |


7.2. Disadvantages
| Disadvantage | Description |
|---|---|
| High Computational Power Required | CNNs require significant computational power and resources, making them expensive to train and deploy. |
| Large Labeled Data Needed | Training CNNs requires large amounts of labeled data, which can be difficult and time-consuming to acquire. |
| Interpretability Challenges | It is often difficult to interpret how CNNs make decisions, limiting transparency and trust. |
| Overfitting | CNNs can overfit, especially with small datasets, leading to poor generalization performance. |
| Fixed Input Sizes | CNNs require fixed input sizes, which limits their flexibility in handling images of varying dimensions. |
8. Conclusion
This article has explored Convolutional Neural Networks (CNNs), detailing their functionality, background, and the role of pooling layers. Despite their effectiveness in image recognition, CNNs have limitations, including susceptibility to adversarial attacks and high computational requirements. CNNs are trained using a loss function that measures the difference between the predicted output and the ground truth. Fine-tuning pre-trained models on specific image data is a common practice to achieve better performance.
CNNs can be used for segmentation tasks, which involve labeling each pixel in an image. Unlike traditional multilayer perceptrons, the network architecture of CNNs is designed to take advantage of the spatial and temporal dependencies in image data. Overall, CNNs have revolutionized the field of computer vision and continue to be an active area of research.
CNNs are vital to deep learning. However, they also have limitations, including susceptibility to adversarial attacks and high computational requirements. To overcome these issues, ongoing research explores techniques such as transfer learning and network architecture optimization.
For more information and to further enhance your understanding of CNNs and deep learning, visit LEARNS.EDU.VN. We offer a wide array of resources, including detailed guides, tutorials, and courses designed to help you master these essential concepts.
9. Frequently Asked Questions (FAQs)
9.1. What Are the Components of a CNN?
CNNs consist of Convolutional Layers for feature extraction, Activation Functions for introducing non-linearities, Pooling Layers for reducing spatial dimensions, Fully Connected Layers for processing features, a Flattening Layer for converting feature maps, and an Output Layer for producing final predictions.
9.2. What is CNN in Machine Learning?
In machine learning, a CNN is a specialized neural network designed for image processing. It uses filters to extract features from images and makes predictions based on these features.
9.3. What is a Convolutional Neural Network in Deep Learning?
CNNs are a type of deep learning model specifically designed for processing and analyzing image data. They use filters to extract features and then use these features to make predictions. CNNs are commonly used for tasks like image classification, object detection, and image segmentation.
9.4. Where is the CNN Algorithm Used?
CNN algorithms are used in various fields, including image classification, object detection, facial recognition, autonomous vehicles, medical imaging, natural language processing, and video analysis. They excel at processing and understanding visual data, making them essential in numerous applications.
10. Enhance Your Learning with LEARNS.EDU.VN
Are you facing challenges in grasping the intricacies of CNNs and deep learning? Do you struggle to find reliable and comprehensive learning resources? At LEARNS.EDU.VN, we understand these challenges and are dedicated to providing you with the support and resources you need to succeed.
10.1. Comprehensive Learning Resources
LEARNS.EDU.VN offers a wide range of expertly crafted articles, detailed tutorials, and structured courses designed to simplify complex concepts and provide clear, actionable guidance. Our resources cover everything from the basics of neural networks to advanced CNN architectures, ensuring you have a solid foundation and can tackle more advanced topics with confidence.
10.2. Expert Guidance and Support
Our team of experienced educators and industry professionals is committed to helping you achieve your learning goals. We provide expert insights, practical tips, and step-by-step instructions to help you master CNNs and deep learning. Whether you’re a student, a professional, or simply a curious learner, LEARNS.EDU.VN is your trusted partner in education.
10.3. Start Your Learning Journey Today
Don’t let the complexities of CNNs hold you back. Visit LEARNS.EDU.VN today and discover the wealth of knowledge and resources available to you. Take the first step towards mastering deep learning and unlocking new opportunities in your career and personal growth.
For additional support and information, contact us at:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: LEARNS.EDU.VN
Let LEARNS.EDU.VN guide you on your path to success in the world of deep learning.
10.4. Additional FAQs
Q5. How do CNNs differ from traditional neural networks?
CNNs differ from traditional neural networks by using convolutional layers that exploit the spatial hierarchy in data, automatically learning features and reducing the number of parameters through shared weights. Traditional neural networks typically require manual feature extraction and have fully connected layers, which can be computationally expensive.
Q6. What are the key applications of CNNs in medical imaging?
In medical imaging, CNNs are used for tasks such as detecting tumors, classifying diseases, segmenting organs, and analyzing medical scans (e.g., X-rays, MRIs). They help improve diagnostic accuracy and efficiency, assisting medical professionals in making informed decisions.
Q7. How do activation functions enhance CNN performance?
Activation functions introduce non-linearities into CNNs, allowing the network to learn complex patterns and relationships in data. Common activation functions like ReLU, sigmoid, and tanh enable CNNs to model non-linear transformations, which are essential for tasks such as image classification and object detection.
Q8. What is the role of transfer learning in CNNs?
Transfer learning involves using pre-trained models on large datasets (e.g., ImageNet) and fine-tuning them for specific tasks with smaller datasets. This approach leverages the knowledge gained from the pre-trained model, reducing the need for extensive training and improving performance, especially when data is limited.
Q9. How do pooling layers contribute to CNN efficiency?
Pooling layers reduce the spatial dimensions of feature maps, decreasing the computational complexity and memory requirements of CNNs. By summarizing the presence of features in local regions, pooling layers also help make the network more robust to variations in object position and scale.
Q10. What are some advanced CNN architectures used today?
Some advanced CNN architectures include ResNet (Residual Networks), which mitigate the vanishing gradient problem; Inception networks, which use multiple filter sizes in parallel; and EfficientNet, which optimizes network scaling for improved efficiency and accuracy.
By providing comprehensive answers to these frequently asked questions, learns.edu.vn aims to equip you with the knowledge and understanding necessary to excel in the field of CNNs and deep learning.
