Large language models master language through training on massive datasets, enabling them to generate text, translate languages, and answer questions with impressive accuracy. At LEARNS.EDU.VN, we’ll explore how these models learn, their architecture, and their real-world applications, offering a clear path to understanding this fascinating field. Delve into the intricacies of neural networks, transformer models, and machine learning techniques to gain a solid foundation.
1. What Are Large Language Models (LLMs)?
Large Language Models (LLMs) are advanced artificial intelligence systems utilizing deep learning to understand, generate, and manipulate human language. These models, trained on vast datasets, have become integral in various applications, from chatbots to content creation, showcasing their adaptability and potential.
LLMs are essentially deep learning algorithms designed for Natural Language Processing (NLP) tasks. They leverage transformer models and are trained on massive amounts of data to recognize, translate, predict, and generate text and other content. These models are also referred to as neural networks, inspired by the human brain, using layered nodes to process information. In addition to language tasks, LLMs can be trained to understand protein structures and write software code, highlighting their versatility. Pre-training and fine-tuning enable them to tackle complex problems like text classification, question answering, and document summarization across fields such as healthcare, finance, and entertainment. The capabilities of LLMs are underpinned by a large number of parameters, which act as a knowledge bank gained through learning from the training data.
1.1. The Core Components of LLMs
LLMs consist of several key components:
- Embedding Layer: Converts input text into embeddings, capturing semantic and syntactic meaning.
- Feedforward Layer (FFN): Transforms input embeddings, enabling the model to understand the user’s intent.
- Recurrent Layer: Interprets words in sequence, capturing relationships between words in a sentence.
- Attention Mechanism: Focuses on relevant parts of the input text to generate accurate outputs.
1.2. Types of LLMs
LLMs are available in different types:
- Generic or Raw Language Models: Predict the next word based on training data, performing information retrieval tasks.
- Instruction-Tuned Language Models: Trained to predict responses to instructions, performing sentiment analysis or generating text/code.
- Dialog-Tuned Language Models: Trained to have dialogues by predicting the next response, such as chatbots or conversational AI.
1.3. LLMs vs Generative AI: What’s the Difference?
Generative AI is a broader term for AI models that can generate content, including text, code, images, video, and music, with examples like Midjourney, DALL-E, and ChatGPT. Large language models are a specific type of generative AI trained on text to produce textual content. ChatGPT is a popular example of generative text AI. Therefore, all large language models are generative AI.
 LLM Generative AI Relationship
LLM Generative AI Relationship
Alt text: Diagram illustrating the relationship between Generative AI and Large Language Models, showing LLMs as a subset of Generative AI technologies for textual content generation.
2. The Learning Process: How LLMs Are Trained
The magic behind LLMs lies in their training process, which involves feeding them vast amounts of text data and teaching them to predict the next word in a sequence. This process is known as unsupervised learning, where the model learns patterns and relationships in the data without explicit instructions.
LLMs are based on transformer models and operate by receiving input, encoding it, and then decoding it to produce an output prediction. The training process is divided into two main stages:
- Training: LLMs are pre-trained using large textual datasets from various sources, such as Wikipedia and GitHub. These datasets can contain trillions of words, and their quality significantly affects the model’s performance. During this stage, the LLM engages in unsupervised learning, processing datasets without specific instructions. The AI algorithm learns the meaning of words, relationships between words, and how to distinguish words based on context.
- Fine-Tuning: To perform specific tasks like translation, an LLM must be fine-tuned. This process optimizes the model’s performance for particular activities.
2.1. Unsupervised Learning: The Foundation
Unsupervised learning is the bedrock of LLM training. It allows the models to identify structures and patterns in vast datasets without human intervention. The AI algorithm learns the meaning of words, relationships between words, and how to distinguish words based on context.
2.2. Fine-Tuning: Sharpening the Focus
To enable LLMs to perform specific tasks, fine-tuning is essential. It optimizes their performance for activities like translation, sentiment analysis, and code generation.
2.3. Prompt Tuning: A Modern Approach
Prompt-tuning is similar to fine-tuning but uses few-shot or zero-shot prompting to train the model for specific tasks. A prompt is an instruction given to the LLM.
2.3.1. Few-Shot Prompting
Few-shot prompting teaches the model to predict outputs through the use of examples. For instance, in sentiment analysis:
Customer review: This product is excellent! Customer sentiment: positive
Customer review: This product is terrible! Customer sentiment: negativeThe language model understands the semantic meaning and opposite examples to determine the sentiment in new reviews.
2.3.2. Zero-Shot Prompting
Zero-shot prompting does not use examples but formulates the question directly: “The sentiment in ‘This product is awful’ is…” This approach clearly indicates the task without providing examples.
3. The Transformer Architecture: The Backbone of LLMs
The success of LLMs is largely due to the transformer architecture, which allows the model to process entire sequences of text in parallel, capturing long-range dependencies and contextual information more effectively than previous models.
A transformer model is the most common architecture for LLMs, consisting of an encoder and a decoder. It processes data by tokenizing the input and simultaneously conducting mathematical equations to discover relationships between tokens. This allows the computer to see patterns as a human would.
Transformer models use self-attention mechanisms, enabling faster learning than traditional models like long short-term memory (LSTM) models. Self-attention allows the model to consider different parts of the sequence or the entire context of a sentence to generate predictions.
3.1. Understanding Self-Attention
Self-attention is a crucial mechanism that enables the model to weigh the importance of different words in the input sequence when producing an output. This allows the model to focus on the most relevant parts of the input, improving the accuracy and coherence of the generated text.
Self-attention mechanisms enable transformer models to learn more quickly than traditional models like long short-term memory models. Self-attention enables the transformer model to consider different parts of the sequence, or the entire context of a sentence, to generate predictions.
3.2. Encoders and Decoders: The Dynamic Duo
The transformer architecture consists of two main components: the encoder and the decoder. The encoder processes the input sequence and generates a contextualized representation, while the decoder uses this representation to generate the output sequence.
- The encoder transforms input text into a machine-readable format.
- The decoder generates the output, using the encoded input as context.
4. Real-World Applications of LLMs
LLMs have found applications in various domains, revolutionizing how we interact with technology and process information.
- Tech: LLMs are used in search engines and to assist developers with writing code.
- Healthcare and Science: LLMs understand proteins, molecules, DNA, and RNA, assisting in vaccine development, finding cures for illnesses, and improving preventative care. They are also used as medical chatbots for patient intakes or basic diagnoses.
- Customer Service: Used for chatbots and conversational AI across industries.
- Marketing: Marketing teams use LLMs for sentiment analysis to generate campaign ideas or text as pitching examples.
- Legal: LLMs assist lawyers and legal staff by searching through massive textual datasets and generating legalese.
- Banking: LLMs support credit card companies in detecting fraud.
Here’s a detailed look at some key applications:
4.1. Information Retrieval: The Power of Search
LLMs power search engines like Bing and Google, producing information in response to queries. They retrieve information, then summarize and communicate the answer in a conversational style.
4.2. Sentiment Analysis: Gauging Public Opinion
As applications of natural language processing, LLMs enable companies to analyze the sentiment of textual data. This is crucial for understanding customer feedback, market trends, and brand perception.
4.3. Text Generation: Unleashing Creativity
LLMs are behind generative AI like ChatGPT, generating text based on inputs. They can produce text examples when prompted, such as writing poems or creating stories.
4.4. Code Generation: Automating Software Development
Like text generation, code generation is an application of generative AI. LLMs understand patterns, enabling them to generate code. This automates parts of the software development process, increasing efficiency and productivity.
4.5. Chatbots and Conversational AI: Enhancing Customer Interactions
LLMs enable customer service chatbots and conversational AI to engage with customers, interpret the meaning of their queries or responses, and offer responses in turn. This enhances customer experience and reduces the workload on human agents.
5. The Benefits of LLMs: Why They Matter
LLMs offer numerous benefits, making them indispensable tools for various industries.
- Large set of applications: They can be used for language translation, sentence completion, sentiment analysis, question answering, mathematical equations, and more.
- Always improving: LLM performance continually improves as more data and parameters are added. The more it learns, the better it gets. LLMs can exhibit “in-context learning,” learning from prompts without additional parameters.
- They learn fast: LLMs learn quickly because they do not require additional weight, resources, and parameters for training. It is fast in the sense that it doesn’t require too many examples.
5.1. Wide Range of Applications
LLMs can be used for a variety of purposes, from language translation to mathematical equations. Their versatility makes them valuable tools for many industries.
5.2. Continuous Improvement
LLM performance is constantly improving as more data and parameters are added. This continuous learning ensures that the models become more accurate and efficient over time.
5.3. Fast Learning Capabilities
LLMs learn quickly because they do not require additional weight, resources, and parameters for training. This rapid learning capability makes them efficient and adaptable to new tasks.
6. Limitations and Challenges of LLMs
Despite their impressive capabilities, LLMs face several limitations and challenges that need to be addressed.
- Hallucinations: LLMs can produce outputs that are false or do not match the user’s intent, such as claiming to be human or having emotions. This is because they predict the next syntactically correct word or phrase without fully interpreting human meaning.
- Security: LLMs present security risks if not managed properly. They can leak private information, participate in phishing scams, and produce spam. Malicious users can reprogram AI to their ideologies or biases, contributing to the spread of misinformation.
- Bias: The data used to train LLMs affects the outputs. If the data represents a single demographic or lacks diversity, the outputs will also lack diversity.
- Consent: LLMs are trained on trillions of datasets, some of which might not have been obtained consensually. They may ignore copyright licenses, plagiarize content, and repurpose proprietary content without permission.
- Scaling: Scaling and maintaining LLMs can be difficult, time-consuming, and resource-intensive.
- Deployment: Deploying LLMs requires deep learning, a transformer model, distributed software and hardware, and overall technical expertise.
6.1. Hallucinations: The Risk of Misinformation
Hallucinations occur when an LLM produces an output that is false or doesn’t align with the user’s intent, such as claiming to be human or having emotions. This is because they predict the next syntactically correct word or phrase without fully interpreting human meaning.
6.2. Security: Protecting Against Malicious Use
LLMs pose security risks if not managed properly. They can leak private information, participate in phishing scams, and produce spam. Malicious users can reprogram AI to their ideologies or biases, contributing to the spread of misinformation.
6.3. Bias: Ensuring Fairness and Diversity
The data used to train LLMs affects the outputs. If the data represents a single demographic or lacks diversity, the outputs will also lack diversity.
6.4. Consent: Addressing Ethical Concerns
LLMs are trained on trillions of datasets, some of which might not have been obtained consensually. They may ignore copyright licenses, plagiarize content, and repurpose proprietary content without permission.
6.5. Scaling and Deployment Challenges
Scaling and maintaining LLMs can be difficult, time-consuming, and resource-intensive. Deploying LLMs requires deep learning, a transformer model, distributed software and hardware, and overall technical expertise.
7. Popular LLMs: A Glimpse into the Landscape
Several LLMs have gained popularity, each with unique strengths and applications.
- PaLM: Google’s Pathways Language Model (PaLM) is a transformer language model capable of common-sense and arithmetic reasoning, joke explanation, code generation, and translation.
- BERT: The Bidirectional Encoder Representations from Transformers (BERT) language model was also developed at Google. It is a transformer-based model that can understand natural language and answer questions.
- XLNet: A permutation language model, XLNet generates output predictions in a random order, distinguishing it from BERT. It assesses the pattern of tokens encoded and then predicts tokens in random order, instead of a sequential order.
- GPT: Generative pre-trained transformers are perhaps the best-known LLMs. Developed by OpenAI, GPT is a popular foundational model whose numbered iterations are improvements on their predecessors (GPT-3, GPT-4, etc.). It can be fine-tuned to perform specific tasks downstream. Examples are EinsteinGPT, developed by Salesforce for CRM, and Bloomberg’s BloombergGPT for finance.
7.1. PaLM: Google’s Versatile Model
Google’s Pathways Language Model (PaLM) is a transformer language model capable of common-sense and arithmetic reasoning, joke explanation, code generation, and translation. Its versatility makes it a powerful tool for various applications.
7.2. BERT: Understanding Natural Language
The Bidirectional Encoder Representations from Transformers (BERT) language model was also developed at Google. It is a transformer-based model that can understand natural language and answer questions effectively.
7.3. XLNet: A Unique Approach to Prediction
A permutation language model, XLNet generates output predictions in a random order, distinguishing it from BERT. It assesses the pattern of tokens encoded and then predicts tokens in random order, instead of a sequential order.
7.4. GPT: The Generative Powerhouse
Generative pre-trained transformers are perhaps the best-known LLMs. Developed by OpenAI, GPT is a popular foundational model whose numbered iterations are improvements on their predecessors (GPT-3, GPT-4, etc.). It can be fine-tuned to perform specific tasks downstream. Examples are EinsteinGPT, developed by Salesforce for CRM, and Bloomberg’s BloombergGPT for finance.
8. Future Advancements in LLMs
The future of LLMs is bright, with ongoing research and development pushing the boundaries of what’s possible.
As LLMs continue to grow and improve their command of natural language, there is much concern regarding what their advancement would do to the job market. It’s clear that LLMs will develop the ability to replace workers in certain fields.
In the right hands, LLMs have the ability to increase productivity and process efficiency, but this has posed ethical questions for its use in human society.
8.1. Ethical Considerations
As LLMs become more powerful, ethical considerations surrounding their use become increasingly important. Issues such as bias, privacy, and job displacement need to be addressed to ensure that LLMs are used responsibly and for the benefit of society.
8.2. Job Market Impact
The increasing capabilities of LLMs raise concerns about their potential impact on the job market. While LLMs can increase productivity and efficiency, they may also displace workers in certain fields.
8.3. Productivity and Efficiency
In the right hands, LLMs have the ability to increase productivity and process efficiency. However, this has posed ethical questions for their use in human society.
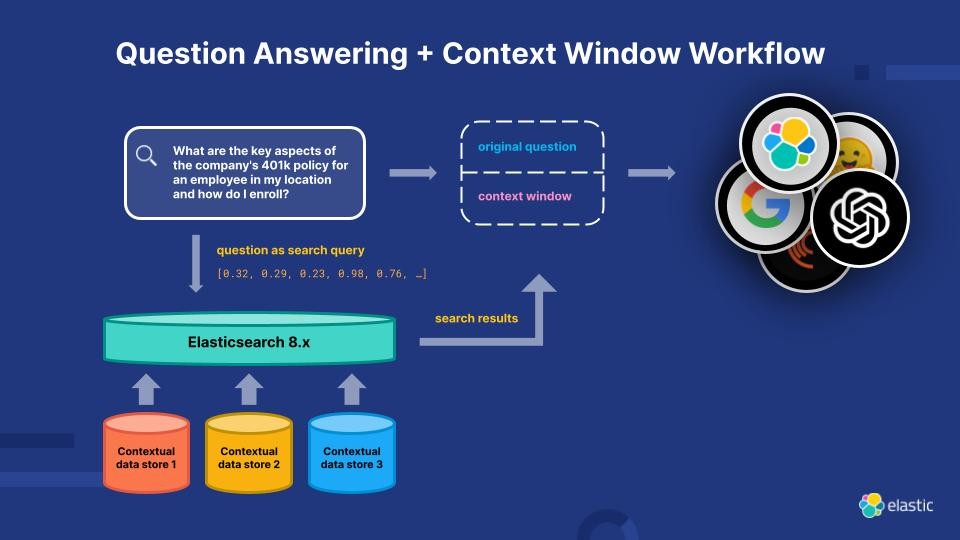
9. Elasticsearch Relevance Engine (ESRE): Enhancing AI-Powered Search
To address the current limitations of LLMs, the Elasticsearch Relevance Engine (ESRE) is a relevance engine built for artificial intelligence-powered search applications. With ESRE, developers are empowered to build their own semantic search applications, utilize their own transformer models, and combine NLP and generative AI to enhance their customers’ search experience.
10. Deep Dive Into LLM Learning: Answering Your Key Questions
To provide a comprehensive understanding of how large language models learn, let’s address some frequently asked questions:
| Question | Answer |
|---|---|
| How do LLMs acquire language proficiency? | LLMs acquire language proficiency through a process of training on vast amounts of text data. This involves exposing the model to a wide range of linguistic patterns, grammatical structures, and contextual information, enabling it to learn the statistical relationships between words and phrases. |
| What role does data play in the learning process of LLMs? | Data is the lifeblood of LLMs. The more diverse and comprehensive the data, the better the model’s ability to understand and generate human-like text. High-quality data ensures that the model learns accurate patterns and avoids biases. |
| How do LLMs handle ambiguity and context? | LLMs handle ambiguity and context by leveraging the self-attention mechanism, which allows the model to weigh the importance of different words in the input sequence. This enables the model to focus on the most relevant parts of the input, improving its ability to understand the context and resolve ambiguities. |
| Can LLMs learn new languages or concepts? | Yes, LLMs can learn new languages or concepts through a process called transfer learning. This involves fine-tuning the pre-trained model on a smaller dataset of the new language or concepts, allowing it to adapt its existing knowledge to the new task. |
| What are the challenges in training LLMs? | Training LLMs is a complex and resource-intensive process, with challenges such as the need for massive amounts of data, the risk of overfitting, and the difficulty of evaluating the model’s performance. |
| How do LLMs generate text? | LLMs generate text by predicting the next word in a sequence, based on the input and the patterns it has learned during training. This process is repeated iteratively, generating a coherent and contextually relevant output. |
| What are the potential risks of using LLMs? | The potential risks of using LLMs include the risk of generating biased or offensive content, the potential for misuse in generating fake news or propaganda, and the ethical concerns surrounding the use of AI in creative tasks. |
| How do LLMs differ from traditional NLP models? | LLMs differ from traditional NLP models in their size, architecture, and ability to capture long-range dependencies. Traditional NLP models typically rely on simpler architectures and are trained on smaller datasets, limiting their ability to understand and generate complex text. |
| What are the future trends in LLM research? | Future trends in LLM research include the development of more efficient and scalable training techniques, the exploration of new architectures and attention mechanisms, and the development of techniques for mitigating bias and improving the ethical use of LLMs. |
| How can I learn more about LLMs? | You can learn more about LLMs by exploring the resources available at LEARNS.EDU.VN, including articles, tutorials, and courses on machine learning, natural language processing, and artificial intelligence. Additionally, you can follow the latest research and developments in the field by reading academic papers and attending conferences. |
11. Boost Your Learning Journey with LEARNS.EDU.VN
Ready to take your understanding of LLMs to the next level? At LEARNS.EDU.VN, we offer a wide range of resources to help you delve deeper into this fascinating field.
- Comprehensive Articles: Explore in-depth articles on various aspects of LLMs, from their architecture to their applications.
- Step-by-Step Tutorials: Follow our easy-to-understand tutorials to learn how to train and fine-tune your own LLMs.
- Expert Insights: Gain valuable insights from industry experts and researchers through our exclusive interviews and webinars.
- Community Support: Connect with other learners and professionals in our online community, where you can ask questions, share ideas, and collaborate on projects.
Visit LEARNS.EDU.VN today and unlock your potential in the world of LLMs. For personalized guidance and to explore our comprehensive courses, contact us at 123 Education Way, Learnville, CA 90210, United States, or reach us via WhatsApp at +1 555-555-1212.
Unlock the power of large language models with learns.edu.vn! Join our community of learners and explore the endless possibilities of AI.
FAQ: Delving Deeper into Large Language Models
-
What makes large language models “large?”
Large language models are “large” due to the massive number of parameters they contain, often billions or even trillions. These parameters enable the model to learn complex patterns and relationships in the data, allowing it to generate more coherent and accurate text.
-
How do large language models handle different writing styles?
LLMs handle different writing styles by being exposed to a wide range of text during training. This allows them to learn the characteristics of different styles, such as formal, informal, and creative writing, and adapt their output accordingly.
-
Can large language models understand humor or sarcasm?
LLMs can understand humor and sarcasm to some extent, but it remains a challenge. They rely on patterns and contextual cues in the text, but may not always be able to grasp the nuances of human communication.
-
What is the role of attention mechanisms in large language models?
Attention mechanisms allow the model to weigh the importance of different words in the input sequence, improving its ability to understand the context and generate more accurate outputs.
-
How are large language models used in customer service?
LLMs are used in customer service to power chatbots and virtual assistants, enabling them to understand and respond to customer queries in a natural and conversational manner.
-
What are the ethical concerns surrounding the use of large language models in education?
Ethical concerns in education include the potential for plagiarism, the risk of over-reliance on AI, and the need to ensure equitable access to technology and resources.
-
How can large language models be used to personalize learning experiences?
LLMs can be used to analyze student data and adapt the learning content and pace to individual needs, creating more personalized and effective learning experiences.
-
What is the difference between fine-tuning and transfer learning in large language models?
Fine-tuning involves training a pre-trained model on a smaller dataset of a specific task, while transfer learning involves using the knowledge gained from one task to improve performance on a different but related task.
-
How do large language models contribute to scientific research?
LLMs contribute to scientific research by analyzing large datasets, generating hypotheses, and accelerating the discovery of new insights and knowledge.
-
What are the limitations of using large language models for creative writing?
Limitations include the potential for generating generic or unoriginal content, the lack of true creativity and emotional depth, and the risk of perpetuating biases and stereotypes.
This comprehensive guide has explored the intricacies of how large language models learn, their architecture, and their real-world applications. By understanding these concepts, you can harness the power of LLMs to enhance your learning, productivity, and creativity.