Artificial intelligence (AI) self learning models are revolutionizing how machines acquire knowledge, offering powerful solutions for complex problems and continuous improvement. At LEARNS.EDU.VN, we believe understanding this technology is crucial for everyone from students to professionals. Discover the mechanisms, applications, and benefits of AI self learning and gain a competitive edge in today’s rapidly evolving world. Let’s explore this interesting topic together. This exploration will cover adaptive algorithms, machine learning, and neural networks.
1. Understanding AI Self Learning: A Comprehensive Guide
AI self learning, also known as unsupervised learning or self-supervised learning, allows machines to learn from data without explicit human guidance. Unlike supervised learning, where AI models are trained on labeled datasets, self learning algorithms identify patterns, relationships, and structures within unlabeled data. This approach enables AI to adapt, evolve, and make predictions based on its own analysis, mimicking human learning processes. This opens up new opportunities for innovation and problem-solving across various domains.
1.1 Key Concepts and Definitions
Understanding the core concepts of AI self learning is essential for grasping its potential and applications.
- Unsupervised Learning: AI learns from unlabeled data, identifying patterns and structures without explicit guidance.
- Self-Supervised Learning: AI generates its own labels from the data to learn representations and improve performance.
- Reinforcement Learning: AI learns by trial and error, receiving feedback in the form of rewards or penalties to optimize its actions.
- Generative Models: AI creates new data instances that resemble the training data, enabling applications like image generation and data augmentation.
- Clustering: AI groups similar data points together, revealing hidden patterns and segments within the data.
1.2 How AI Self Learning Differs from Other Machine Learning Approaches
AI self learning stands apart from other machine learning approaches, such as supervised learning and reinforcement learning, due to its unique characteristics and methodologies.
| Feature | Supervised Learning | Unsupervised Learning (Self Learning) | Reinforcement Learning |
|---|---|---|---|
| Data | Labeled data with input-output pairs | Unlabeled data | Data from trial-and-error interactions with an environment |
| Learning Method | Learns a mapping function to predict outputs from inputs | Identifies patterns and structures in the data | Learns to optimize actions based on rewards and penalties |
| Human Guidance | Explicit guidance through labeled data | Minimal or no guidance; learns autonomously | Feedback through rewards and penalties |
| Typical Tasks | Classification, regression | Clustering, dimensionality reduction, anomaly detection | Game playing, robotics, control systems |
| Data Preparation | Requires extensive data labeling | Less data preparation; handles raw, unlabeled data | Defines environment and reward structure |
| Adaptation | Limited adaptation to new, unseen data | High adaptability; can discover new patterns over time | Adapts to new environments and tasks through learning |
| Use Cases | Predictive modeling, image recognition | Customer segmentation, fraud detection, recommendation systems | Autonomous navigation, resource management |

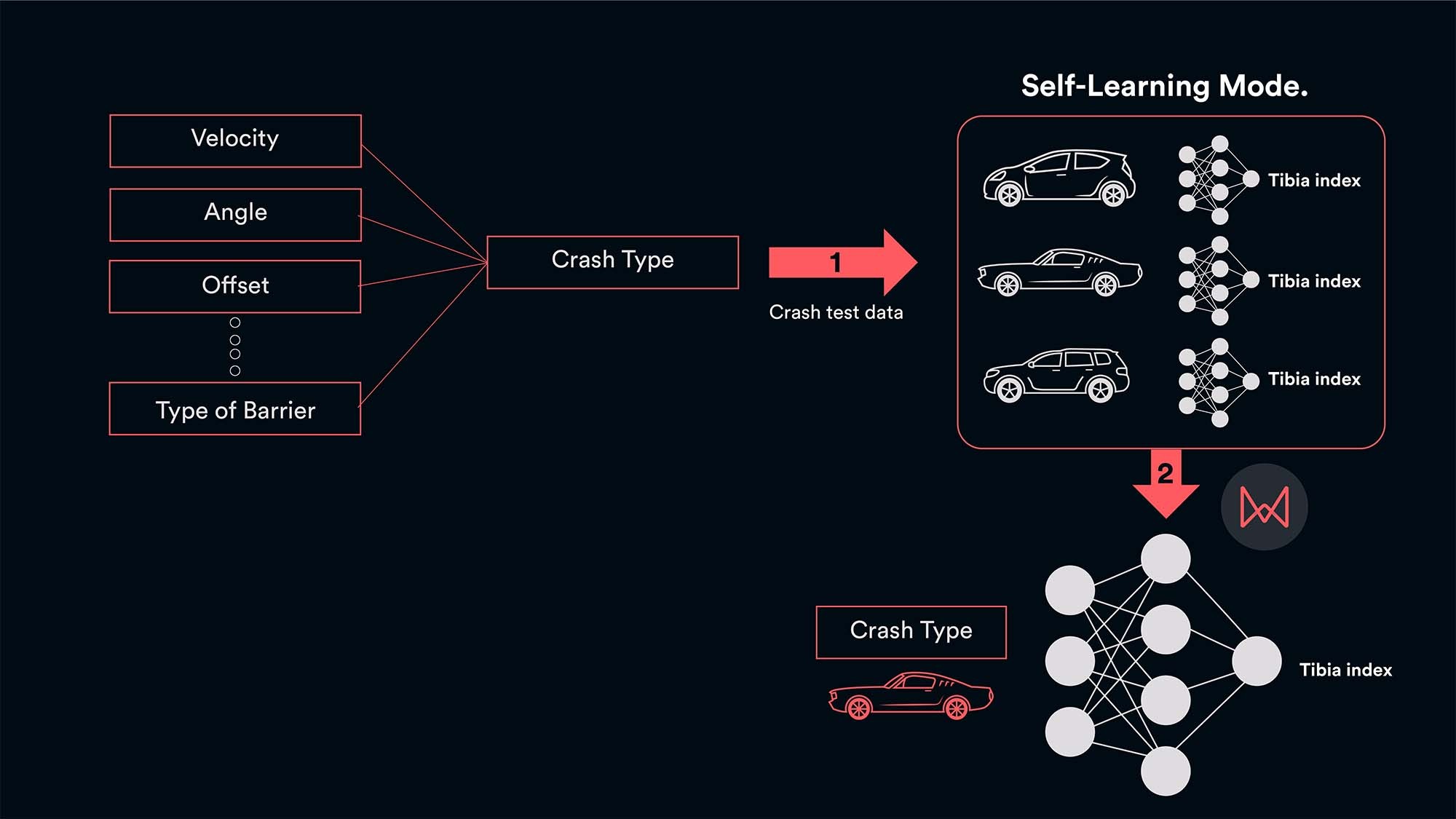
1.3 The Importance of Data Quality and Quantity
Data quality and quantity play a pivotal role in the success of AI self learning models. High-quality data ensures that the model learns accurate patterns and relationships, while a sufficient quantity of data provides the model with enough examples to generalize effectively. However, the nature of self learning allows models to make valuable insights even from unlabeled data.
- Data Quality: Clean, accurate, and relevant data is crucial for training effective self learning models.
- Data Quantity: A larger dataset provides more opportunities for the model to learn and generalize.
- Data Preprocessing: Cleaning, transforming, and preparing the data can significantly improve model performance.
- Data Augmentation: Creating synthetic data instances can increase the size and diversity of the training dataset.
2. The Mechanisms Behind AI Self Learning
AI self learning relies on various algorithms and techniques to extract knowledge from data without explicit human intervention. Understanding these mechanisms provides insights into how AI models learn and adapt autonomously.
2.1 Clustering Algorithms: Grouping Similar Data Points
Clustering algorithms group similar data points together based on their inherent characteristics, revealing hidden patterns and segments within the data. These algorithms are widely used in customer segmentation, anomaly detection, and image analysis.
- K-Means Clustering: Partitions data into K clusters, where each data point belongs to the cluster with the nearest mean.
- Hierarchical Clustering: Builds a hierarchy of clusters by iteratively merging or splitting them based on their similarity.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Identifies clusters based on the density of data points, separating them from noise.
- Gaussian Mixture Models (GMM): Models data as a mixture of Gaussian distributions, assigning each data point a probability of belonging to each cluster.
2.2 Dimensionality Reduction Techniques: Simplifying Complex Data
Dimensionality reduction techniques reduce the number of variables in a dataset while preserving its essential information, simplifying complex data and improving model performance. These techniques are used in data visualization, feature extraction, and noise reduction.
- Principal Component Analysis (PCA): Transforms data into a new coordinate system where the principal components capture the most variance.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): Reduces dimensionality while preserving the local structure of the data, useful for visualizing high-dimensional data.
- Autoencoders: Neural networks that learn to encode and decode data, reducing dimensionality and extracting important features.
- Independent Component Analysis (ICA): Separates a multivariate signal into additive subcomponents that are statistically independent.
2.3 Neural Networks and Deep Learning in Self Learning
Neural networks and deep learning play a crucial role in AI self learning, enabling models to learn complex patterns and representations from unlabeled data. Deep learning models, such as autoencoders and generative adversarial networks (GANs), have achieved remarkable results in image generation, natural language processing, and anomaly detection.
- Autoencoders: Learn to encode and decode data, extracting important features and reducing dimensionality.
- Generative Adversarial Networks (GANs): Consist of a generator that creates new data instances and a discriminator that distinguishes between real and generated data, improving each other through adversarial training.
- Self-Organizing Maps (SOMs): Neural networks that map high-dimensional data onto a low-dimensional grid, preserving the topological relationships between data points.
- Restricted Boltzmann Machines (RBMs): Probabilistic graphical models that learn to represent data in a compact and meaningful way.
2.4 Reinforcement Learning: Learning Through Trial and Error
Reinforcement learning enables AI agents to learn by interacting with an environment and receiving feedback in the form of rewards or penalties. This approach is widely used in robotics, game playing, and control systems.
- Q-Learning: Learns a Q-function that estimates the optimal action for each state based on future rewards.
- Deep Q-Networks (DQN): Combines Q-learning with deep neural networks to handle high-dimensional state spaces.
- Policy Gradients: Directly optimizes the policy of the agent, maximizing the expected reward.
- Actor-Critic Methods: Combine policy gradients with value-based methods, using an actor to select actions and a critic to evaluate their performance.
3. Applications of AI Self Learning Across Industries
AI self learning has a wide range of applications across various industries, enabling organizations to solve complex problems, automate tasks, and gain valuable insights from data.
3.1 Healthcare: Diagnosis, Personalized Treatment, and Drug Discovery
In healthcare, AI self learning is used to improve diagnosis accuracy, personalize treatment plans, and accelerate drug discovery.
- Diagnosis: AI models analyze medical images, patient records, and other data to identify diseases and conditions.
- Personalized Treatment: AI algorithms tailor treatment plans based on individual patient characteristics and medical history.
- Drug Discovery: AI models identify potential drug candidates and predict their efficacy and safety.
- Predictive Analytics: AI algorithms predict patient outcomes, enabling proactive interventions and improved care management.
LEARNS.EDU.VN offers courses that delve into the ethical considerations and practical applications of AI in healthcare. Explore our resources to learn more about how AI is transforming the medical field.
3.2 Finance: Fraud Detection, Risk Assessment, and Algorithmic Trading
In finance, AI self learning is used to detect fraudulent transactions, assess risk, and optimize trading strategies.
- Fraud Detection: AI models identify unusual patterns and anomalies in financial transactions to prevent fraud.
- Risk Assessment: AI algorithms assess credit risk, market risk, and operational risk to make informed decisions.
- Algorithmic Trading: AI models optimize trading strategies based on market conditions and historical data.
- Customer Service: AI-powered chatbots and virtual assistants provide personalized support and answer customer inquiries.
3.3 Retail: Customer Segmentation, Recommendation Systems, and Inventory Management
In retail, AI self learning is used to segment customers, recommend products, and optimize inventory management.
- Customer Segmentation: AI models group customers based on their purchasing behavior, demographics, and preferences.
- Recommendation Systems: AI algorithms recommend products to customers based on their past purchases and browsing history.
- Inventory Management: AI models predict demand and optimize inventory levels to minimize costs and maximize sales.
- Personalized Marketing: AI algorithms tailor marketing messages and promotions to individual customers.
3.4 Manufacturing: Predictive Maintenance, Quality Control, and Process Optimization
In manufacturing, AI self learning is used to predict equipment failures, improve quality control, and optimize production processes.
- Predictive Maintenance: AI models analyze sensor data to predict equipment failures and schedule maintenance proactively.
- Quality Control: AI algorithms detect defects and anomalies in products to ensure quality.
- Process Optimization: AI models optimize production processes to minimize costs and maximize efficiency.
- Supply Chain Management: AI algorithms optimize supply chain operations, including procurement, logistics, and distribution.
3.5 Education: Personalized Learning, Automated Grading, and Curriculum Development
In education, AI self learning is used to personalize learning experiences, automate grading, and develop curricula.
- Personalized Learning: AI models adapt learning materials and activities to individual student needs and learning styles.
- Automated Grading: AI algorithms automate the grading of assignments and exams, providing instant feedback to students.
- Curriculum Development: AI models analyze student performance data to identify areas for improvement and develop effective curricula.
- Educational Chatbots: AI-powered chatbots provide students with personalized support and answer their questions.
At LEARNS.EDU.VN, we are committed to providing innovative AI-driven solutions to enhance education. Explore our offerings to see how you can leverage AI to transform the learning experience.
4. Benefits of AI Self Learning: Advantages and Opportunities
AI self learning offers numerous benefits and opportunities for organizations across various industries.
4.1 Improved Accuracy and Efficiency
AI self learning models can achieve higher accuracy and efficiency compared to traditional machine learning approaches by learning from unlabeled data and adapting to changing conditions.
- Automated Pattern Recognition: AI models automatically identify patterns and relationships in data without human intervention.
- Real-Time Adaptation: AI algorithms adapt to changing conditions in real-time, improving performance over time.
- Reduced Human Error: AI models minimize human error by automating tasks and making data-driven decisions.
- Increased Productivity: AI-powered systems increase productivity by automating repetitive tasks and freeing up human resources.
4.2 Discovery of Hidden Patterns and Insights
AI self learning can uncover hidden patterns and insights in data that would be difficult or impossible for humans to identify, leading to new discoveries and innovations.
- Anomaly Detection: AI models identify unusual patterns and anomalies in data, detecting fraud, errors, and other issues.
- Trend Analysis: AI algorithms analyze historical data to identify trends and predict future outcomes.
- Relationship Mapping: AI models map relationships between variables, revealing dependencies and correlations.
- Data Mining: AI-powered data mining tools extract valuable information from large datasets.
4.3 Automation of Complex Tasks
AI self learning enables the automation of complex tasks, such as natural language processing, image recognition, and decision-making, freeing up human resources for more strategic activities.
- Natural Language Processing: AI models understand and generate human language, enabling chatbots, virtual assistants, and sentiment analysis.
- Image Recognition: AI algorithms identify objects, faces, and scenes in images and videos, enabling applications like facial recognition and object detection.
- Decision-Making: AI models make data-driven decisions based on complex data analysis, optimizing outcomes and minimizing risks.
- Robotics: AI-powered robots automate physical tasks, such as manufacturing, logistics, and healthcare.
4.4 Cost Reduction and Resource Optimization
AI self learning can reduce costs and optimize resource allocation by automating tasks, improving efficiency, and making data-driven decisions.
- Predictive Maintenance: AI models predict equipment failures, reducing maintenance costs and downtime.
- Inventory Management: AI algorithms optimize inventory levels, minimizing storage costs and waste.
- Energy Management: AI models optimize energy consumption, reducing utility costs and environmental impact.
- Supply Chain Optimization: AI algorithms optimize supply chain operations, reducing transportation costs and delivery times.
4.5 Enhanced Personalization and Customer Experience
AI self learning enables personalized experiences and improved customer satisfaction by tailoring products, services, and marketing messages to individual preferences.
- Personalized Recommendations: AI algorithms recommend products and services based on customer preferences and past purchases.
- Personalized Marketing: AI models tailor marketing messages and promotions to individual customers.
- Personalized Customer Service: AI-powered chatbots and virtual assistants provide personalized support and answer customer inquiries.
- Personalized Learning: AI models adapt learning materials and activities to individual student needs and learning styles.
5. Challenges and Limitations of AI Self Learning
While AI self learning offers numerous benefits, it also presents several challenges and limitations that organizations need to address.
5.1 Data Bias and Ethical Concerns
AI self learning models can perpetuate and amplify data biases, leading to unfair or discriminatory outcomes. Ethical concerns related to privacy, transparency, and accountability need to be addressed.
- Bias Detection: AI models and tools identify and mitigate biases in data and algorithms.
- Ethical Guidelines: Organizations establish ethical guidelines for the development and deployment of AI systems.
- Transparency and Explainability: AI models provide insights into their decision-making processes, improving transparency and explainability.
- Privacy Protection: AI systems protect sensitive data and comply with privacy regulations.
5.2 Need for Large Datasets
AI self learning models often require large datasets to achieve high accuracy and generalization, which can be challenging for organizations with limited data resources.
- Data Augmentation: Create synthetic data instances to increase the size and diversity of the training dataset.
- Transfer Learning: Use pre-trained models on large datasets and fine-tune them for specific tasks.
- Federated Learning: Train AI models on decentralized data sources without sharing the data.
- Active Learning: Select the most informative data points for labeling, reducing the amount of labeled data needed.
5.3 Difficulty in Interpreting Results
AI self learning models can be complex and difficult to interpret, making it challenging to understand their decision-making processes and identify potential errors.
- Explainable AI (XAI): Develop AI models that provide insights into their decision-making processes.
- Visualization Tools: Use visualization tools to explore and understand the behavior of AI models.
- Model Auditing: Conduct regular audits of AI models to ensure they are performing as expected and identify potential issues.
- Human-in-the-Loop: Involve human experts in the decision-making process to validate and interpret AI results.
5.4 Computational Requirements
AI self learning can be computationally intensive, requiring powerful hardware and software resources to train and deploy models effectively.
- Cloud Computing: Use cloud computing resources to access scalable and cost-effective computing power.
- Hardware Acceleration: Use specialized hardware, such as GPUs and TPUs, to accelerate AI model training and inference.
- Model Optimization: Optimize AI models to reduce their computational requirements without sacrificing accuracy.
- Distributed Training: Train AI models on multiple machines to reduce training time.
5.5 Overfitting and Generalization Issues
AI self learning models can overfit the training data, leading to poor performance on new, unseen data. Generalization issues need to be addressed to ensure models can perform well in real-world scenarios.
- Regularization: Use regularization techniques to prevent overfitting.
- Cross-Validation: Evaluate model performance on multiple subsets of the data to ensure generalization.
- Ensemble Methods: Combine multiple models to improve generalization and reduce overfitting.
- Data Augmentation: Increase the size and diversity of the training dataset to improve generalization.
6. Getting Started with AI Self Learning: A Practical Guide
Getting started with AI self learning involves several steps, including selecting the right tools and platforms, preparing data, training models, and evaluating performance.
6.1 Choosing the Right Tools and Platforms
Selecting the right tools and platforms is essential for successful AI self learning projects. Several popular options are available, each with its own strengths and weaknesses.
| Tool/Platform | Description | Strengths | Weaknesses |
|---|---|---|---|
| TensorFlow | Open-source machine learning framework developed by Google | Flexible, scalable, and widely used; supports various programming languages and platforms | Can be complex and require a steep learning curve |
| PyTorch | Open-source machine learning framework developed by Facebook | Dynamic computation graph, easy to use, and popular in research community | Less mature than TensorFlow in some areas |
| scikit-learn | Simple and efficient tools for data mining and data analysis | Easy to use, well-documented, and provides a wide range of algorithms | Limited support for deep learning and large datasets |
| Keras | High-level neural networks API, written in Python and capable of running on top of TensorFlow or Theano | Simple and easy to use, allows for rapid prototyping | Less flexible than TensorFlow or PyTorch |
| AWS SageMaker | Fully managed machine learning service provided by Amazon Web Services | Scalable, secure, and integrated with other AWS services; provides a wide range of tools for building, training, and deploying models | Can be expensive and complex to set up |
| Google Cloud AI Platform | End-to-end machine learning platform provided by Google Cloud | Scalable, secure, and integrated with other Google Cloud services; provides a wide range of tools for building, training, and deploying models | Can be expensive and complex to set up |
| Azure Machine Learning | Cloud-based machine learning service provided by Microsoft Azure | Scalable, secure, and integrated with other Azure services; provides a wide range of tools for building, training, and deploying models | Can be expensive and complex to set up |
6.2 Preparing and Preprocessing Data
Preparing and preprocessing data is a crucial step in AI self learning, ensuring that the data is clean, accurate, and ready for model training.
- Data Cleaning: Remove or correct errors, inconsistencies, and missing values in the data.
- Data Transformation: Convert data into a suitable format for model training, such as scaling or normalization.
- Feature Engineering: Create new features from existing data to improve model performance.
- Data Splitting: Divide the data into training, validation, and test sets to evaluate model performance.
6.3 Training and Evaluating Models
Training and evaluating AI self learning models involves selecting the appropriate algorithms, tuning hyperparameters, and assessing performance using various metrics.
- Algorithm Selection: Choose the appropriate algorithms based on the nature of the data and the specific task.
- Hyperparameter Tuning: Optimize model hyperparameters to improve performance.
- Performance Metrics: Evaluate model performance using metrics such as accuracy, precision, recall, and F1-score.
- Cross-Validation: Evaluate model performance on multiple subsets of the data to ensure generalization.
6.4 Deploying and Monitoring AI Systems
Deploying and monitoring AI self learning systems involves integrating models into real-world applications, monitoring their performance, and retraining them as needed.
- Model Deployment: Integrate AI models into real-world applications, such as web services, mobile apps, or embedded systems.
- Performance Monitoring: Monitor model performance over time, tracking metrics such as accuracy, latency, and resource usage.
- Retraining: Retrain models periodically to maintain performance and adapt to changing conditions.
- Feedback Loops: Incorporate feedback from users and stakeholders to improve model performance and address ethical concerns.
7. Future Trends in AI Self Learning
AI self learning is a rapidly evolving field, with several emerging trends that are likely to shape its future development and applications.
7.1 Advancements in Unsupervised and Self-Supervised Learning
Advancements in unsupervised and self-supervised learning are enabling AI models to learn more effectively from unlabeled data, reducing the need for human intervention and improving performance.
- Contrastive Learning: Learn representations by comparing similar and dissimilar data points.
- Generative Pre-training: Pre-train models on large datasets using generative tasks, such as language modeling, and fine-tune them for specific tasks.
- Meta-Learning: Learn how to learn, enabling models to adapt quickly to new tasks and environments.
- Self-Distillation: Train smaller models to mimic the behavior of larger, more complex models.
7.2 Integration with Edge Computing
Integrating AI self learning with edge computing enables models to be deployed and trained on edge devices, reducing latency, improving privacy, and enabling real-time decision-making.
- Federated Learning: Train AI models on decentralized data sources without sharing the data.
- Model Compression: Reduce the size and complexity of AI models to enable deployment on resource-constrained devices.
- Edge Inference: Deploy AI models on edge devices to perform real-time inference.
- On-Device Learning: Train AI models on edge devices using local data.
7.3 Development of More Explainable and Trustworthy AI
The development of more explainable and trustworthy AI is crucial for addressing ethical concerns, improving transparency, and building user confidence.
- Explainable AI (XAI): Develop AI models that provide insights into their decision-making processes.
- Adversarial Robustness: Develop AI models that are resistant to adversarial attacks.
- Fairness and Bias Mitigation: Develop AI models that are fair and unbiased.
- Transparency and Accountability: Ensure that AI systems are transparent and accountable.
7.4 Expansion into New Industries and Applications
AI self learning is expanding into new industries and applications, such as robotics, autonomous vehicles, and personalized medicine, transforming how we live and work.
- Robotics: AI-powered robots automate physical tasks, such as manufacturing, logistics, and healthcare.
- Autonomous Vehicles: AI models enable self-driving cars to navigate and make decisions without human intervention.
- Personalized Medicine: AI algorithms tailor treatment plans based on individual patient characteristics and medical history.
- Smart Cities: AI-powered systems optimize urban infrastructure, such as transportation, energy, and waste management.
8. Conclusion: The Future is Self-Learned
AI self learning is a transformative technology with the potential to revolutionize industries, improve lives, and drive innovation. By understanding its mechanisms, applications, and challenges, organizations and individuals can harness its power and unlock its full potential.
LEARNS.EDU.VN is dedicated to providing the resources and knowledge you need to navigate the world of AI self learning. Visit our website at LEARNS.EDU.VN or contact us via WhatsApp at +1 555-555-1212 to learn more. Our address is 123 Education Way, Learnville, CA 90210, United States. Let’s explore the future of AI self learning together!
Want to learn a new skill, understand a complex concept, or find effective learning methods? Discover a wealth of in-depth, easy-to-understand articles and explore tailored courses at learns.edu.vn.
9. FAQ: Frequently Asked Questions About How AI Self Learns
9.1 What is the main difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train models, while unsupervised learning uses unlabeled data to find patterns and structures.
9.2 How does reinforcement learning work?
Reinforcement learning involves an agent learning by interacting with an environment and receiving rewards or penalties for its actions.
9.3 What are some common applications of AI self learning in healthcare?
AI self learning is used in healthcare for diagnosis, personalized treatment plans, drug discovery, and predictive analytics.
9.4 What are the ethical concerns associated with AI self learning?
Ethical concerns include data bias, privacy, transparency, and accountability.
9.5 How can I get started with AI self learning?
Start by selecting the right tools and platforms, preparing your data, training your models, and evaluating performance.
9.6 What is transfer learning?
Transfer learning involves using pre-trained models on large datasets and fine-tuning them for specific tasks.
9.7 How can I ensure my AI models are fair and unbiased?
Develop AI models that are fair and unbiased by using bias detection tools, ethical guidelines, and transparency measures.
9.8 What are some future trends in AI self learning?
Future trends include advancements in unsupervised learning, integration with edge computing, and the development of more explainable AI.
9.9 How does AI self learning contribute to personalized learning in education?
AI models adapt learning materials to individual student needs, providing customized learning experiences.
9.10 What role does data quality play in AI self learning?
Data quality is crucial for training effective self learning models, ensuring accurate patterns and reliable results.
