Creating a training dataset for machine learning is essential for building effective AI models, and LEARNS.EDU.VN is here to guide you. Learn how to transform raw data into actionable insights, accelerating your AI projects with cutting-edge automation techniques. Unlock the power of high-quality labeled data, active learning pipelines, and optimized data annotation processes to enhance model performance and scalability.
1. Why is Training Data Crucial for Machine Learning?
Training data is the bedrock of any successful machine learning model. The quality of training data profoundly impacts a model’s development, performance, and accuracy. Imagine training data as the textbook from which a model gains its foundational knowledge. It guides the model, showing it patterns and helping it understand what to look for. Once trained, the model should be able to identify patterns in new datasets based on what it has learned.
In essence, the training dataset serves as the “teacher” for machine learning models. Like students, models perform better when they have access to well-curated and relevant examples. Models trained on unreliable or irrelevant data can become functionally useless. This highlights the importance of the adage: “garbage in, garbage out,” emphasizing that the quality of input directly affects the output.
2. How Do Training Datasets Train Computer Vision Models?
Computer vision models learn from training datasets through two primary approaches: unsupervised and supervised learning. Understanding the difference is crucial for creating an effective training dataset.
2.1. Unsupervised Machine Learning Models
Unsupervised learning involves feeding data into a model without providing specific instructions or feedback. In this approach, the training data is raw, without annotations or identifying labels. The computer vision model then trains without human guidance, independently discovering patterns within the data.
Unsupervised machine learning diagram (Source)
These models can cluster and identify patterns in data but can’t perform tasks with a desired outcome. For example, an unsupervised model might group images of animals by color instead of by species, as there is no human input to guide it.
2.2. Supervised Machine Learning Models
Supervised learning models are used when the desired outcomes are predetermined, such as identifying a tumor or changes in weather patterns. A human provides the model with labeled data and supervises the machine learning process, offering feedback on its performance.
HTIL process (Source)
Human-in-the-loop (HITL) is essential. The first step is to curate and label the training data, often using data labeling tools, active learning pipelines, and AI-assisted tools to convert raw material into labeled datasets. Labeling data allows data science teams to structure the data, making it readable for the model. Specialists identify a target outcome and annotate objects in images and videos by giving them labels.
Well-chosen labels are critical for guiding a model’s learning. For example, if you want a computer vision model to identify different types of birds, every bird in the training data must be labeled appropriately. Annotators and data scientists make corrections based on the model’s outputs, providing feedback to correct any inaccuracies.
3. What Constitutes a High-Quality Machine Learning Training Dataset?
Several factors contribute to making a training dataset suitable for machine learning. Let’s explore these factors in detail:
3.1. Relevance and Appropriateness
For a training dataset to be effective, it must be applicable and appropriately labeled for the specific use case. The curated data must directly relate to the problem the model is trying to solve. For instance, if a computer vision model is designed to identify bicycles, the data should contain images of bicycles, preferably various types.
3.2. Data Cleanliness
The cleanliness of the data significantly impacts the performance of a model. A model trained on corrupt or broken data, or datasets with duplicate images, will likely make incorrect predictions. Therefore, ensuring the data is free from errors and inconsistencies is essential.
3.3. Annotation Quality
As discussed, the quality of annotations has a tremendous effect on the quality of the training data. High-quality annotations ensure that the model focuses on the correct features and learns accurate patterns. This is why labeling images is time-consuming and requires specialized tools and expertise.
LEARNS.EDU.VN provides resources and courses to help you understand these best practices. We also give insights into how to ensure your training data meets the highest standards.
4. How to Create Image or Video-Based Datasets for Machine Learning Effectively
Creating, evaluating, and managing training data requires the right tools and approach. The following steps offer a structured guide to creating effective image or video-based datasets for machine learning:
4.1. Data Collection
Gather a diverse and representative collection of images or videos relevant to the problem you are trying to solve. Ensure the data covers a wide range of scenarios, conditions, and variations to enhance the model’s generalization capability.
4.2. Data Annotation
Label the collected data accurately and consistently. Use appropriate annotation tools such as bounding boxes, polygons, or segmentation masks, depending on the specific requirements of your computer vision task.
4.2.1. Image Classification
Assign labels to entire images based on their content. For single-label classification, each image has one label. For multi-label classification, each image has multiple labels that are not mutually exclusive.
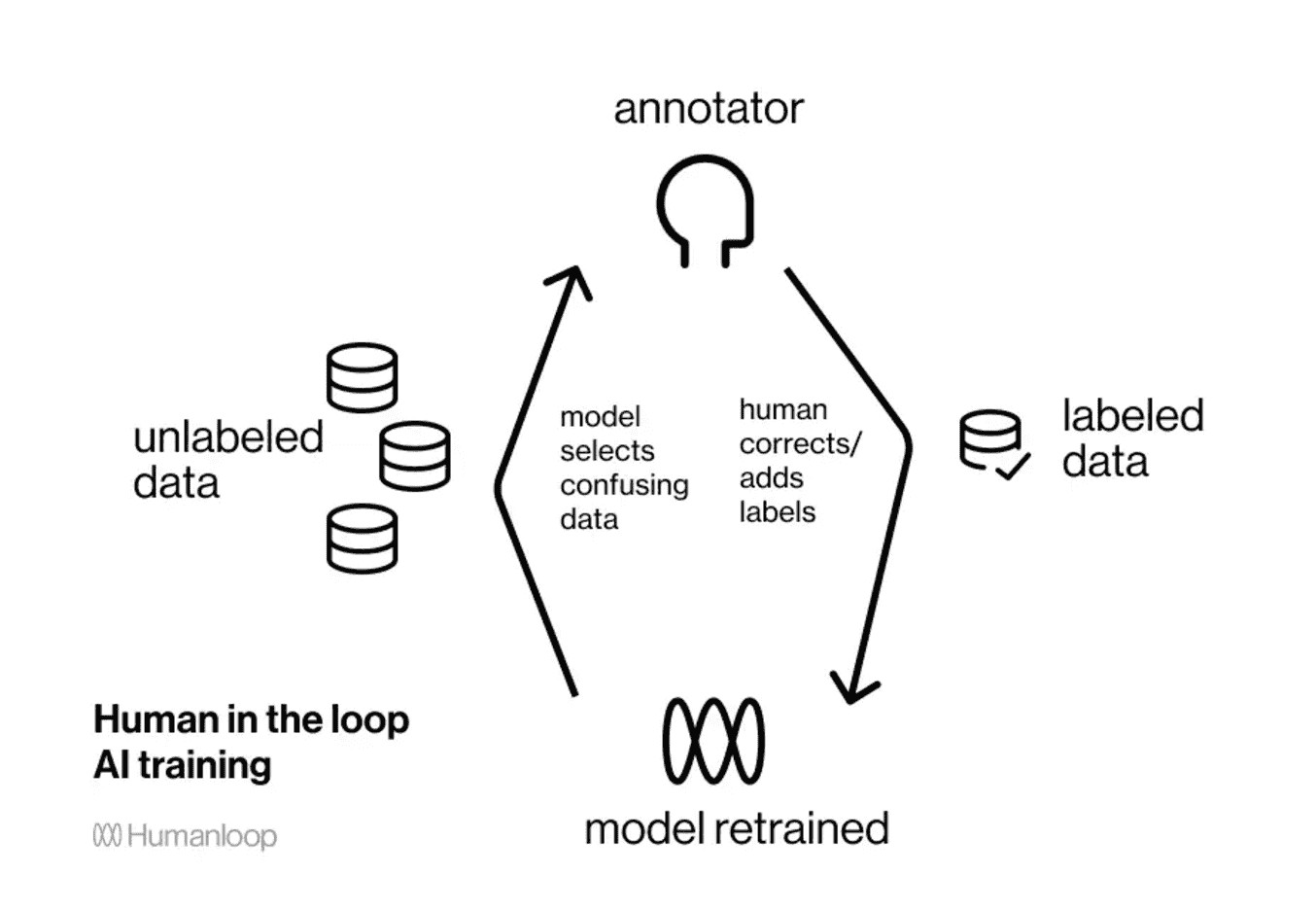
4.2.2. Bounding Boxes
Draw rectangular boxes around objects of interest to detect and locate them within the image. This is suitable for object detection tasks where the precise shape of the object is not critical.
Bounding box annotation in Encord platform
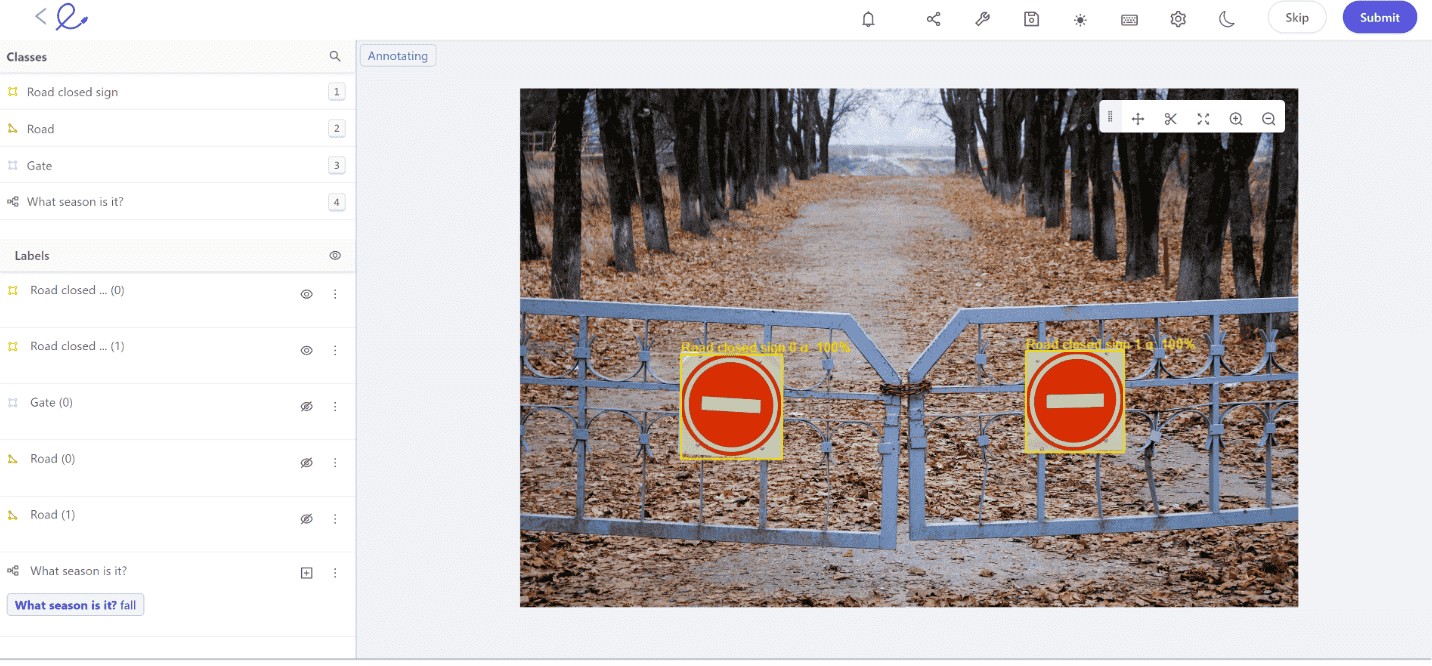
4.2.3. Polygons/Segments
Create precise outlines around objects using polygons or segments to separate them from the background and other objects. This is useful for image segmentation tasks where the shape and boundary of the object are important.
Polygon annotation of brain in Encord platform
4.3. Data Augmentation
Increase the size and diversity of your dataset by applying various transformations to the existing data. This can include rotations, flips, crops, and color adjustments, which help the model become more robust to variations in real-world scenarios.
4.4. Quality Assurance
Implement rigorous quality control measures to verify the accuracy and consistency of the annotations. This can involve multiple annotators reviewing and validating the labeled data to minimize errors and biases.
4.5. Data Management
Organize and manage your dataset effectively using appropriate data management tools and techniques. This includes version control, data storage, and data retrieval mechanisms to ensure the data is easily accessible and traceable.
5. What are the Key Tools for Creating Image or Video-Based Datasets for Machine Learning?
Various tools are available to facilitate the creation, evaluation, and management of training data.
| Tool Category | Description |
|---|---|
| Data Collection Tools | Tools for gathering images and videos from various sources, such as web scraping, APIs, or existing datasets. |
| Data Annotation Platforms | Platforms that provide a user-friendly interface for labeling images and videos with bounding boxes, polygons, semantic segmentation, and other annotation types. |
| Data Augmentation Libraries | Libraries that offer a wide range of image and video transformations to increase the size and diversity of the dataset. |
| Data Management Systems | Systems for organizing, storing, and versioning datasets, including features for data governance, access control, and collaboration. |
| Model Training Frameworks | Frameworks such as TensorFlow and PyTorch that facilitate the training and evaluation of machine learning models using the created training data. |
| Active Learning Tools | Tools that automate the process of selecting the most informative data points for annotation, thereby reducing the overall annotation effort and improving model performance. |
| AI-Assisted Labeling Tools | Tools that leverage pre-trained models or AI algorithms to automatically generate initial annotations, which can then be reviewed and refined by human annotators. This significantly speeds up the process. |

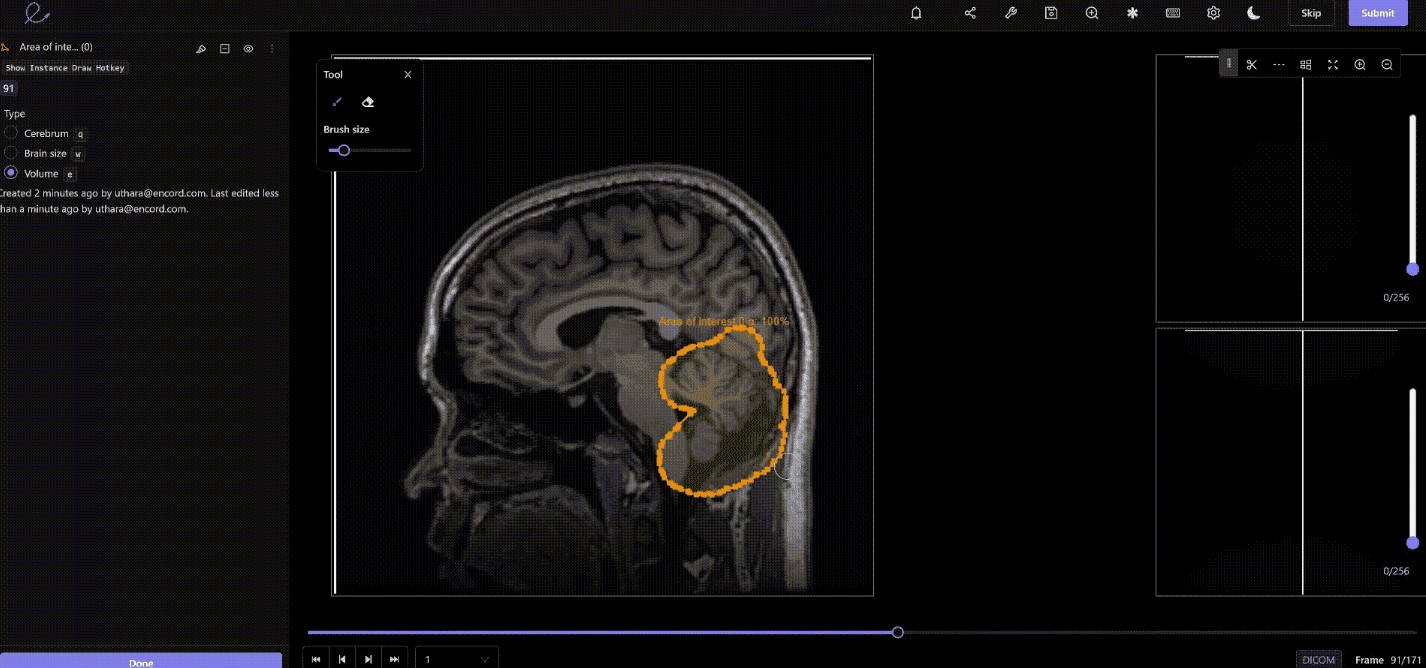
5.1. Encord’s Computer Vision-First Toolkit
Encord offers a comprehensive computer vision-first toolkit that allows users to label any computer vision modality in one platform. Its fast and intuitive collaboration tools enrich data, enabling the building of cutting-edge AI applications. Encord’s platform automates object classification, detects segments, and tracks objects in images and videos.
The platform supports various data formats, including images, videos, SAR, satellite, thermal imaging, and DICOM images (X-Ray, CT, MRI, etc.).
Labeling training data for machine learning in Encord
6. How to Create Better Training Datasets for Machine Learning and Computer Vision Models
While the world is awash with data, most of it is unlabeled and therefore can’t be used in supervised machine learning models. Computer vision models, such as those designed for medical imaging or self-driving cars, need to be confident in their predictions, requiring them to train on vast amounts of data. Acquiring large quantities of labeled data remains a serious obstacle to the advancement of AI.
6.1. Leveraging Open-Source Datasets
Utilize available open-source datasets to jumpstart your projects. Many datasets cater to specific computer vision tasks.
| Dataset Name | Description | Size |
|---|---|---|
| MNIST | A dataset of handwritten digits commonly used for introductory machine learning tasks. | 60,000 training images |
| CIFAR-10 | A dataset of 60,000 32×32 color images in 10 different classes, such as airplanes, cars, birds, etc. | 50,000 training images |
| ImageNet | A large dataset of images organized according to the WordNet hierarchy, used for training models on a wide range of objects and scenes. | Over 14 million images |
| COCO (Common Objects in Context) | A dataset designed for object detection, segmentation, and captioning tasks, containing images with multiple objects and detailed annotations. | Over 330,000 images |
| Pascal VOC (Visual Object Classes) | A dataset used for object detection and image segmentation tasks, with annotations for various object categories. | Approximately 11,000 images |
| Open Images Dataset | A large dataset of images with object bounding boxes and instance segmentation masks, covering a wide range of object categories. | Over 9 million images |
| Labeled Faces in the Wild (LFW) | A dataset of labeled face images used for face recognition tasks. | Over 13,000 images |
| Fashion-MNIST | A dataset of Zalando’s article images used for fashion-related image classification tasks. | 60,000 training images |
| Cityscapes | A dataset for semantic segmentation and object detection in urban street scenes, with high-quality pixel-level annotations. | 5,000 images |
| Visual Genome | A dataset that provides detailed annotations and relationships between objects in images, enabling tasks such as scene graph generation and visual reasoning. | Over 108,000 images |
6.2. Prioritizing Quality Assurance
Recognize that every incorrect label negatively impacts a model’s performance. Data annotators play a vital role in the process of creating high-quality training data, underscoring the importance of quality assurance in the data labeling workflow.
Ideally, data annotators should be subject-matter experts in the domain for which the model is answering questions. Their domain expertise allows them to understand the connection between the data and the problem the machine is trying to solve, resulting in more informative and accurate labels.
6.3. Addressing the Time and Expertise Challenge
Understand that data labeling can be time-consuming and tedious. One hour of video data can take humans up to 800 hours to annotate. Data labeling can be outsourced, but doing so means losing the input of subject-matter experts, which could result in low-quality training data if the labeling requires industry-specific knowledge.
When outsourcing isn’t possible, teams often build internal tools and use their in-house workforces to label their data manually, leading to cumbersome data infrastructure and annotation tools that are expensive to maintain and challenging to scale.
7. How Can Micro-Models Automate Data Labeling for Machine Learning?
Encord uses micro-models to build its automation features. In semi-supervised learning, data scientists feed machines a small amount of labeled data in combination with a large amount of unlabeled data during training.
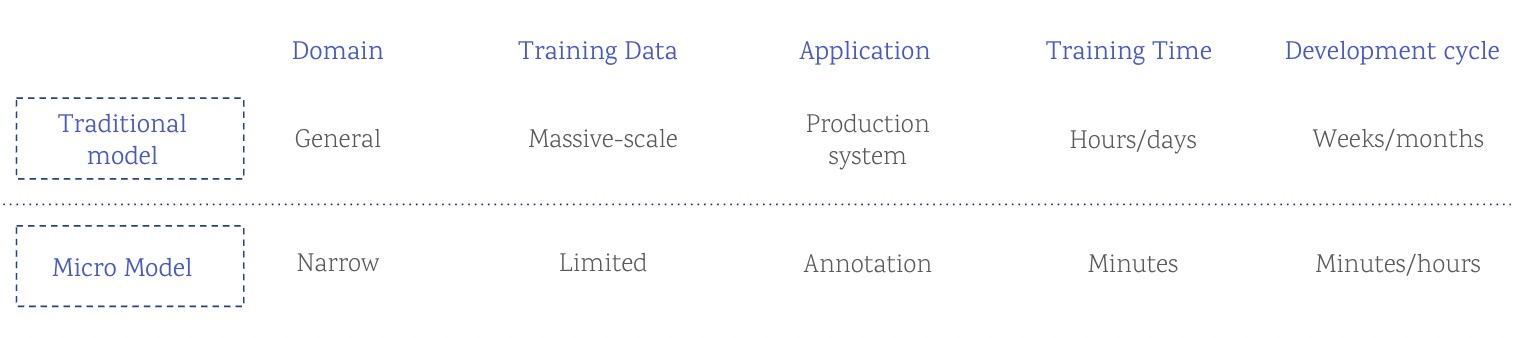
The micro-model methodology is based on the idea that a model can produce strong results when trained on a small set of purposefully selected and well-labeled data. Micro-models have different domains of applications and use cases compared to traditional models.
7.1. Overfitting Micro-Models
While overfitting a production model is problematic because it prevents generalization, Encord’s micro-models are purposefully overfitted. They are annotation-specific models intentionally designed to look at one piece of data, identify one thing, and overtrain that specific task.
7.2. Streamlining the Annotation Process
Because micro-models don’t take much time to build, require huge datasets, or need weeks to train, the humans in the loop can start training the micro-models after annotating only a handful of examples. Micro-models then automate the annotation process. With automated data labeling, the number of labels that require human annotation decreases over time because the system gets more intelligent each time the model runs.
8. Comparing Traditional and Micro-Models for Creating Machine Learning Training Data
| Feature | Traditional Models | Micro-Models |
|---|---|---|
| Training Data Size | Require massive amounts of data to generalize well. | Can achieve strong results with smaller, purposefully selected datasets. |
| Training Time | Can take weeks or months to train. | Train quickly, often in a matter of hours. |
| Generalization | Designed to generalize to a wide range of scenarios and unseen data. | Intentionally overfitted to specific tasks, not intended for general application. |
| Application | Used in production for real-world predictions and decision-making. | Primarily used to automate data annotation processes, improving efficiency and reducing the need for manual labeling. |
| Human-in-the-Loop | May still require human validation and refinement, but less frequently than with manual annotation processes. | Humans play a crucial role in the initial training and light-touch supervision, but the model largely validates itself over time. |
With micro-models, users can quickly create training data to feed into downstream computer vision models, enabling faster development and deployment of AI solutions.
9. Case Study: King’s College London (KCL) and Encord
Encord worked with King’s College London (KCL) to make video annotations for computer vision projects 6x faster than previous methods and tools.
Clinicians at KCL wanted to find a way to reduce the amount of time highly-skilled medical professionals spent annotating videos of precancerous polyps for training data to develop AI-aided medical diagnostic tools.
Using Encord’s micro-models and AI-assisted labeling tools, clinicians increased annotation output speeds, completing the task 6.4x faster than when manual labeling. Only three percent of the datasets required manual labeling from clinicians. Encord’s technology saved clinicians valuable time and provided King’s College with access to training data much more quickly than if the institution had relied on a manual annotation process. This increased efficiency allowed King’s College to move the AI into production faster, cutting model development time from one year to two months.
10. Frequently Asked Questions (FAQs)
10.1. What is a training dataset in machine learning?
A training dataset is a collection of labeled data used to train machine learning models. It serves as the foundation for the model to learn patterns and relationships, enabling it to make accurate predictions or classifications.
10.2. Why is the quality of training data important?
The quality of training data directly impacts the performance and accuracy of machine learning models. High-quality data ensures the model learns correct patterns and generalizes well to new, unseen data. Poor-quality data can lead to biased or inaccurate models.
10.3. How much data do I need for a training dataset?
The amount of data required depends on the complexity of the problem and the model being used. More complex problems and models typically require larger datasets to achieve good performance. It’s essential to have a representative and diverse dataset.
10.4. What are the common methods for creating a training dataset?
Common methods include manual annotation, using existing datasets, web scraping, and synthetic data generation. The choice of method depends on the availability of data, the specific requirements of the task, and the resources available.
10.5. How do I ensure the accuracy of my training data?
To ensure accuracy, implement rigorous quality control measures, such as multiple annotators reviewing and validating the labeled data. Use clear annotation guidelines, conduct regular audits, and leverage automated tools to identify and correct errors.
10.6. What are the best practices for labeling data?
Best practices for labeling data include using clear and consistent annotation guidelines, providing annotators with adequate training, implementing quality control measures, and using appropriate annotation tools. Also, ensure the labels are relevant to the problem being solved.
10.7. How can I augment my training dataset?
You can augment your training dataset by applying various transformations to the existing data, such as rotations, flips, crops, and color adjustments. This increases the size and diversity of the dataset, improving the model’s robustness and generalization capability.
10.8. What role do micro-models play in creating training data?
Micro-models automate the data labeling process by training on a small set of labeled data and then applying those labels to larger amounts of unlabeled data. This reduces the need for manual annotation, saving time and resources while maintaining data quality.
10.9. How can I balance the classes in my training dataset?
To balance classes, you can use techniques such as oversampling the minority class, undersampling the majority class, or using synthetic data generation to create more samples for the minority class. Class balancing helps prevent the model from being biased toward the majority class.
10.10. What are the key considerations for data privacy and security when creating a training dataset?
Key considerations include anonymizing or pseudonymizing sensitive data, complying with data protection regulations (such as GDPR or HIPAA), implementing access controls, and ensuring secure storage and transfer of data. It’s important to protect the privacy and security of individuals whose data is being used.
Creating effective training datasets is crucial for machine learning success. LEARNS.EDU.VN offers comprehensive resources, courses, and tools to guide you through every step of the process. From data collection to annotation and model training, we provide the expertise you need to build high-performing AI solutions.
Ready to dive deeper into the world of machine learning and create impactful AI applications? Visit LEARNS.EDU.VN to explore our extensive range of courses, articles, and resources. Our expert instructors and comprehensive curriculum will empower you to master the skills and knowledge needed to succeed in this exciting field.
For more information, contact us at:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: LEARNS.EDU.VN
Take the next step in your learning journey with learns.edu.vn and unlock your full potential in the world of machine learning.
