Semi-supervised learning stands as a pivotal branch of artificial intelligence, skillfully combining labeled and unlabeled data to enhance model training. At LEARNS.EDU.VN, we offer comprehensive resources to navigate this intricate domain, empowering you to leverage its potential. This method addresses the challenge of scarce labeled data, optimizing AI model performance and promoting innovation in machine learning.
Embark on a journey into the realm of semi-supervised learning with LEARNS.EDU.VN, unlocking advanced strategies for machine learning, neural networks, and data augmentation.
1. What is Semi-Supervised Learning in the Context of AI?
Yes, semi-supervised learning is a significant part of AI, specifically within machine learning, addressing scenarios where labeled data is limited and unlabeled data is abundant. Semi-supervised learning leverages both labeled and unlabeled data to train AI models, combining techniques from supervised and unsupervised learning to improve accuracy and efficiency. This approach is particularly beneficial when labeling data is costly or time-consuming, enhancing the model’s ability to generalize from limited labeled examples.
Semi-supervised learning is a branch of machine learning that addresses the challenge of training AI models with both labeled and unlabeled data. This approach leverages the strengths of both supervised and unsupervised learning, allowing models to learn from limited labeled data while also utilizing the patterns and structures within a larger set of unlabeled data. This method is highly valuable in real-world scenarios where obtaining labeled data is expensive, time-consuming, or impractical. By effectively combining these data sources, semi-supervised learning enhances model accuracy, efficiency, and generalization capabilities, making it a vital tool in modern AI development.
2. When Should You Use Semi-Supervised Machine Learning Techniques?
Semi-supervised machine learning is particularly useful when you have a small amount of labeled data and a large amount of unlabeled data, as labeling large datasets can be expensive and time-consuming. It is also beneficial when you need to improve model performance beyond what can be achieved with labeled data alone, allowing the model to learn from the inherent structure in unlabeled data. This technique is applicable in various fields, including image recognition, natural language processing, and medical diagnostics.
Consider using semi-supervised machine learning in scenarios where:
- Labeling Data is Expensive: When annotating data requires significant time, resources, or expertise.
- Labeled Data is Scarce: When you have a limited amount of labeled data compared to the available unlabeled data.
- Improved Model Performance is Needed: When you want to enhance the accuracy and generalization of your models by leveraging unlabeled data.
- Exploring Data Structure: When you need to discover patterns and insights from unlabeled data to complement labeled data.
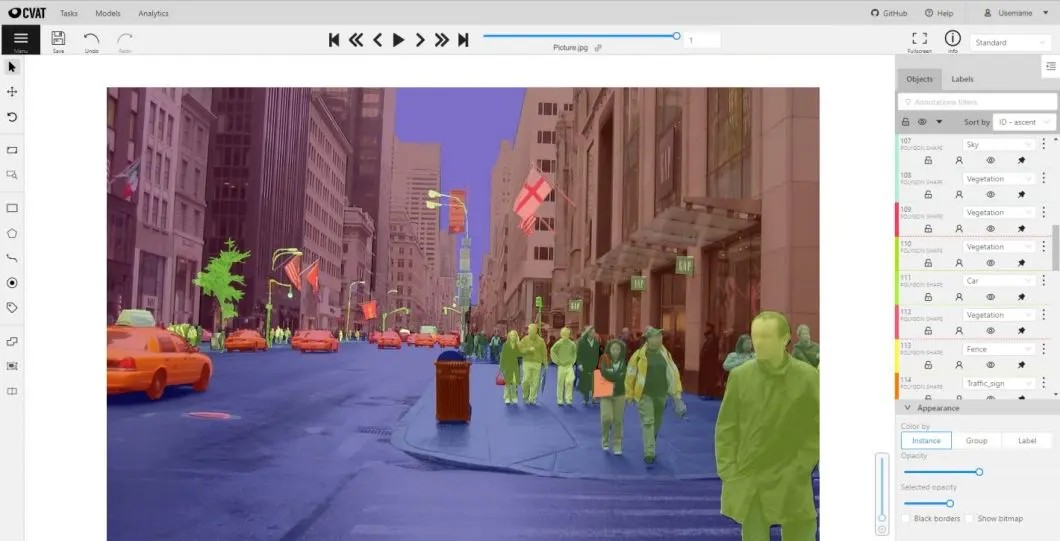
Semi-supervised learning is particularly effective when combined with techniques such as self-training, co-training, and multi-view learning. These methods allow the model to iteratively learn from the unlabeled data, improving its performance over time. For instance, in medical imaging, manually annotating a large dataset can be time-consuming and costly. In such cases, using a smaller set of labeled data in combination with a larger set of unlabeled data can lead to improved model performance compared to using only labeled data.
Image Annotation using CVAT software. Alt text: Medical image annotation in CVAT for semi-supervised learning, showing efficient data labeling.
3. What are the Key Benefits of Semi-Supervised Learning in AI?
The key benefits of semi-supervised learning in AI include improved model accuracy, reduced labeling costs, enhanced generalization, and the ability to leverage large amounts of readily available unlabeled data. By combining limited labeled data with abundant unlabeled data, semi-supervised learning enhances the performance and efficiency of AI models in various applications. This approach is particularly valuable when labeled data is expensive or difficult to obtain.
Here are the key benefits:
- Improved Accuracy: By leveraging unlabeled data, semi-supervised learning can significantly enhance model accuracy, especially when labeled data is scarce.
- Reduced Labeling Costs: Minimizes the need for extensive manual labeling, saving time and resources.
- Enhanced Generalization: Models trained with semi-supervised learning tend to generalize better to new, unseen data due to the incorporation of broader data patterns.
- Effective Use of Unlabeled Data: Transforms readily available unlabeled data into valuable information, maximizing data utility.
4. What are Popular Semi-Supervised Learning Techniques Used Today?
Popular techniques in semi-supervised learning include self-training, co-training, multi-view learning, and generative models like Generative Adversarial Networks (GANs). Self-training involves iteratively labeling unlabeled data using a trained model, while co-training uses multiple models trained on different views of the data. Multi-view learning combines information from multiple representations of the data, and GANs generate new samples similar to the labeled data.
Some widely used techniques include:
-
Self-Training:
- Process: Trains a model on labeled data and then uses it to predict labels for unlabeled data. The most confidently predicted unlabeled data points are added to the labeled dataset, and the model is retrained.
- Use Cases: Image classification, natural language processing, and anomaly detection.
-
Co-Training:
- Process: Trains two or more models on different views or subsets of the data. Each model labels the unlabeled data for the others, iteratively improving performance.
- Use Cases: Situations where data has multiple representations (e.g., text and images).
-
Multi-View Learning:
- Process: Trains a model that leverages multiple views or representations of the data to improve performance.
- Use Cases: Scenarios where data can be represented in different ways (e.g., text, images, and audio).
-
Generative Adversarial Networks (GANs):
- Process: Uses a generator to create new samples similar to the labeled data and a discriminator to distinguish between real and generated samples.
- Use Cases: Image generation, data augmentation, and semi-supervised classification.
-
Label Propagation:
- Process: Assigns labels to unlabeled data points based on their similarity to labeled data points.
- Use Cases: Node classification in graphs, image segmentation, and document classification.
5. How Does Self-Training Work in Semi-Supervised Learning?
Self-training is a semi-supervised learning technique where a model is initially trained on labeled data and then used to predict labels for unlabeled data. The model’s most confident predictions are added to the labeled dataset, and the model is retrained, iteratively improving its performance. This process continues until a stopping criterion is met, effectively expanding the labeled dataset and enhancing the model’s ability to generalize.
Self-training involves the following steps:
- Initial Training: Train a model on the available labeled data.
- Label Prediction: Use the trained model to predict labels for the unlabeled data.
- Confidence Assessment: Assess the confidence of the predicted labels.
- Data Augmentation: Add the most confidently labeled data points to the labeled dataset.
- Model Retraining: Retrain the model using the augmented labeled dataset.
- Iteration: Repeat steps 2-5 until a stopping criterion is met (e.g., maximum iterations or performance plateau).
Self-training algorithms train a model to fit pseudo labels predicted by another previously learned supervised model. These algorithms have been successful in the past for learning using neural networks with unlabeled data. In each step of self-training, a part of the unlabeled data points are labeled according to the current decision function, and the supervised model is retrained using its predictions as additional labeled points.
Data augmentation to artificially expand image datasets by generating new data samples. Alt text: Image dataset and data augmentation, showing the artificial expansion of image datasets for semi-supervised learning.
6. What is the Difference Between Semi-Supervised and Self-Supervised Learning?
The key difference between semi-supervised and self-supervised learning lies in the use of labeled data. Semi-supervised learning utilizes a small amount of labeled data in conjunction with a large amount of unlabeled data, whereas self-supervised learning uses only unlabeled data by creating pretext tasks to generate pseudo-labels. Self-supervised learning is often used to learn useful features that can be transferred to other tasks, while semi-supervised learning aims to improve the performance of a specific task by leveraging unlabeled data.
Here is a detailed comparison:
| Feature | Semi-Supervised Learning | Self-Supervised Learning |
|---|---|---|
| Labeled Data | Uses a small amount of labeled data and a large amount of unlabeled data | Uses only unlabeled data |
| Pretext Task | Not required | Requires a pretext task to generate pseudo-labels from unlabeled data |
| Transfer Learning | Improves performance on a specific task | Learns general features that can be transferred to various downstream tasks |
| Purpose | Enhances accuracy and generalization with limited labeled data | Learns useful representations from data without human-provided labels |

7. What are the Underlying Assumptions in Semi-Supervised Learning?
The underlying assumptions in semi-supervised learning include the smoothness assumption, the cluster assumption, and the manifold assumption. The smoothness assumption states that if two points are close in a high-density region, their corresponding outputs should also be close. The cluster assumption suggests that points in the same cluster are likely to be of the same class. The manifold assumption posits that the data lies on a low-dimensional manifold embedded in a higher-dimensional space.
These assumptions are empirical mathematical observations that justify otherwise arbitrary choices of approach.
- Smoothness Assumption: Points that are close to each other are more likely to have the same label.
- Cluster Assumption: Data points within the same cluster are likely to belong to the same class.
- Manifold Assumption: Data lies on a low-dimensional manifold within a high-dimensional space.
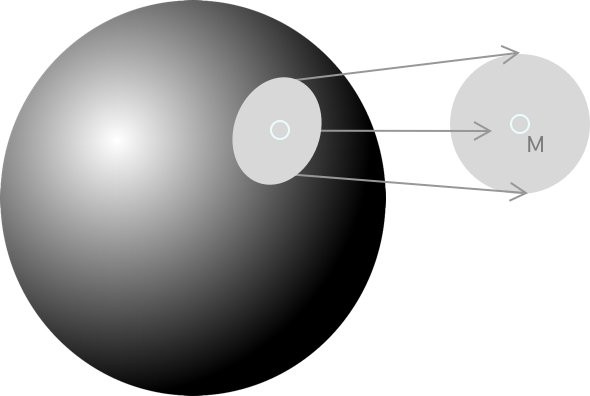
7.1 Smoothness Assumption
The semi-supervised smoothness assumption states that if two points (x1 and x2) in a high-density region are close, then so should their corresponding outputs (y1 and y2). By the transitive property, this assumption entails that when two points are linked by a path of high data density (for example, belonging to the same cluster), then their outputs are also likely to be close together. When they are separated by low-density regions, their outputs do not have to be as close.
The accuracy of predicting correctly increases with increasing smoothness. Alt text: Smoothness assumption diagram, illustrating the relationship between input proximity and output similarity in machine learning.
7.2 Cluster Assumption
The cluster assumption, in essence, states that if points are in the same cluster, they are likely to be of the same class. Clusters are high-density regions, so if two points are close together, they’re likely to belong to the same cluster, and thus, their labels are likely to be the same. Low-density regions are spaces of separation between high-density regions, so samples belonging to low-density regions are more likely to be boundary points rather than belong to the same class as the rest of the cluster.
Cluster assumption. Alt text: Cluster assumption in machine learning, showing data points in the same cluster sharing the same class labels.
7.3 Manifold Assumption
The manifold assumption states that the data used for semi-supervised learning lies on a low-dimensional manifold embedded in higher-dimensional space. Therefore, data points that follow this assumption need to be densely sampled. In other words, the data should, instead of coming from every part of the possible space, come from relatively low-dimensional manifolds.
Manifold assumption. Alt text: Manifold assumption diagram, demonstrating data points lying on a low-dimensional manifold within a high-dimensional space.
8. What is Transductive Learning in Semi-Supervised Learning?
Transductive learning in semi-supervised learning focuses on predicting labels only for the unlabeled data points in the current dataset, without aiming to generalize to new, unseen data. Instead of modeling the entire distribution p(y|x), transductive learning is interested in finding the distribution of the unlabeled points. This approach is particularly useful when the primary goal is to improve knowledge about the specific unlabeled dataset at hand, rather than building a generalizable model.
Transductive learning can be time-saving and is preferable when the goal is oriented toward improving our knowledge about the unlabeled dataset. However, because this scenario implies that the knowledge of the labeled dataset can improve our knowledge of the unlabeled dataset, it is not ideal or usable for causal processes.
9. How Does Inductive Learning Differ from Transductive Learning in Semi-Supervised Scenarios?
Inductive learning aims to build a general model that can predict labels for any data point, including those not present in the training set, while transductive learning focuses solely on predicting labels for the unlabeled data points within the training set. Inductive learning considers all data points and tries to determine a complete function where y = f(x) can map both labeled and unlabeled data points to their prospective labels. This method is more complex than transductive learning and proportionately requires more computational time.
Here’s a comparison table:
| Feature | Transductive Learning | Inductive Learning |
|---|---|---|
| Goal | Predict labels for unlabeled data in the current dataset | Build a general model to predict labels for any data point |
| Generalization | Does not generalize to new data | Generalizes to new, unseen data |
| Model Scope | Focuses on the specific dataset | Creates a global function applicable to any data point |
| Complexity | Less complex | More complex |
| Computational Time | Less time-consuming | More time-consuming |
10. What is the Role of Generative Models Like Gaussian Mixture in Semi-Supervised Learning?
Generative models, such as Gaussian Mixture Models (GMMs), play a crucial role in semi-supervised learning by modeling the underlying data distribution and generating new data points that resemble the labeled data. These models can effectively cluster data and estimate the probability of data points belonging to different classes, aiding in classification and pattern recognition tasks. Generative Gaussian Mixture is an inductive algorithm for semi-supervised classification and is especially helpful when the goal is to find a model explaining the structure of existing data points.
Key aspects of using GMMs in semi-supervised learning include:
- Modeling Data Distribution: GMMs model the data-generating process using a sum of weighted Gaussian distributions.
- Clustering: The structure of the algorithms allows us to cluster the given datasets into well-defined regions (Gaussians).
- Probability Estimation: The algorithm can output the probability of new data points belonging to each of the classes.
- Pattern Recognition: The model is generative, meaning the probability distribution of data is modeled to perform pattern recognition.
11. How Can Semi-Supervised Learning Enhance Computer Vision Applications?
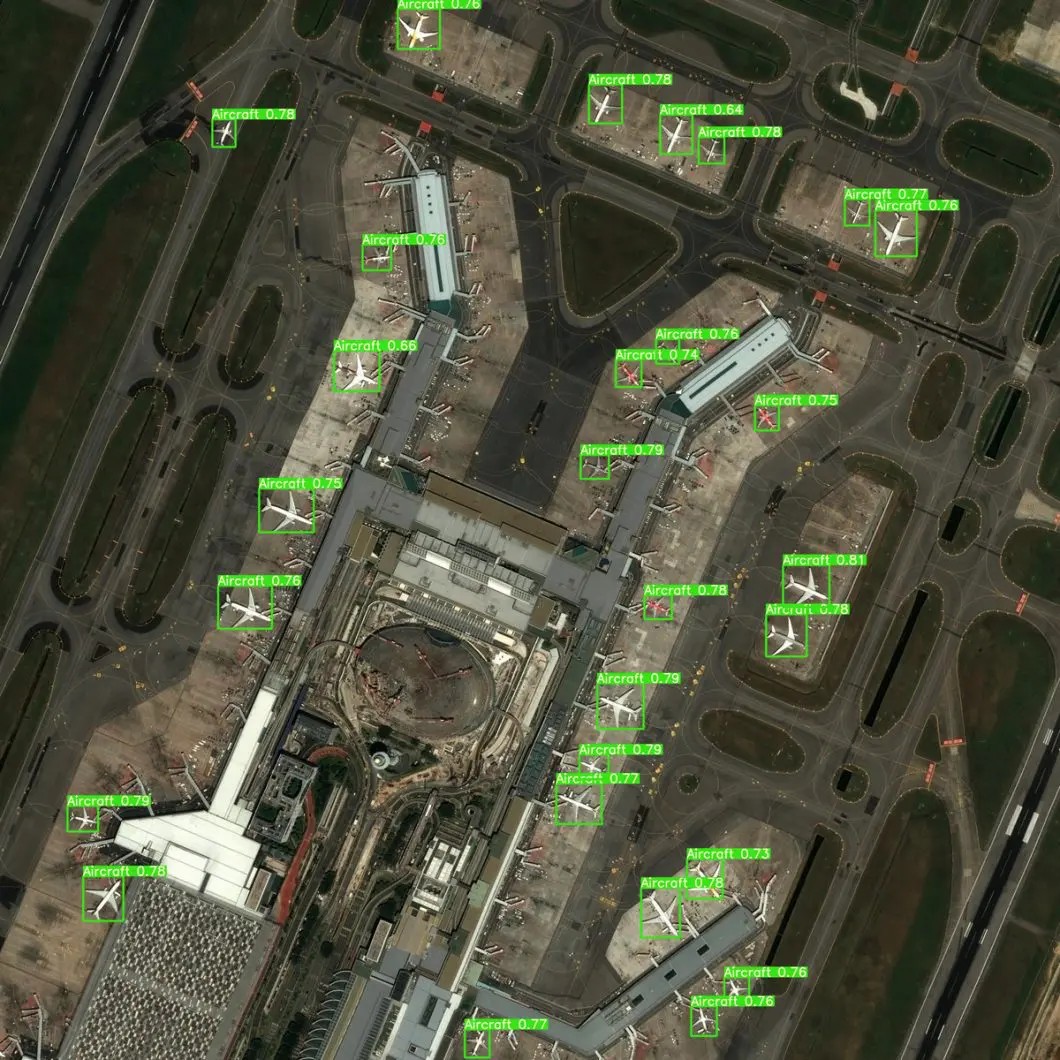
Semi-supervised learning enhances computer vision applications by allowing models to leverage large amounts of unlabeled image data to improve performance in tasks such as image classification, object detection, and image segmentation. By combining limited labeled data with abundant unlabeled data, semi-supervised techniques can significantly boost the accuracy and robustness of computer vision models. Semi-supervised learning methods for computer vision have also been developing into advanced processes at rapid rates during the past few years.
Examples of how semi-supervised learning improves computer vision:
- Image Classification: Training models to classify images with higher accuracy using both labeled and unlabeled images.
- Object Detection: Improving the detection of objects in images by leveraging unlabeled data to learn more robust features.
- Image Segmentation: Enhancing the precision of image segmentation tasks by incorporating unlabeled data to better understand image structures.
Applied object detection in Aviation to detect aircraft – Built with Viso Suite. Alt text: Aircraft detection using computer vision, illustrating the application of object detection in aviation with semi-supervised learning.
12. What are the Challenges of Implementing Semi-Supervised Learning?
Implementing semi-supervised learning comes with several challenges, including ensuring the quality of unlabeled data, selecting appropriate algorithms, and validating model performance. The effectiveness of semi-supervised learning heavily relies on the assumptions that the unlabeled data is representative of the labeled data and that the chosen algorithm aligns with the underlying data structure. Addressing these challenges requires careful data preprocessing, algorithm selection, and rigorous evaluation techniques.
Key challenges include:
- Data Quality: Ensuring the unlabeled data is relevant and does not introduce noise or bias.
- Algorithm Selection: Choosing the right semi-supervised algorithm that aligns with the data characteristics.
- Assumption Validation: Verifying that the underlying assumptions (smoothness, cluster, manifold) hold true for the data.
- Performance Evaluation: Accurately assessing the model’s performance, especially when labels are limited.
- Computational Complexity: Managing the increased computational demands of training with large unlabeled datasets.
13. What Real-World Applications Benefit Most from Semi-Supervised Learning?
Several real-world applications benefit significantly from semi-supervised learning, including medical imaging, natural language processing, speech recognition, and fraud detection. In these domains, obtaining large labeled datasets is often expensive and time-consuming, making semi-supervised learning a cost-effective approach to improve model performance. For example, in medical imaging, annotating a large dataset can be time-consuming and costly.
Specific applications include:
- Medical Imaging: Enhancing the accuracy of disease diagnosis using limited labeled medical images.
- Natural Language Processing: Improving text classification and sentiment analysis with large amounts of unlabeled text data.
- Speech Recognition: Training more accurate speech recognition systems by leveraging unlabeled audio data.
- Fraud Detection: Identifying fraudulent transactions by combining labeled and unlabeled transaction data.
14. How Does Co-Training Enhance Semi-Supervised Learning?
Co-training enhances semi-supervised learning by training multiple models on different views or subsets of the data, allowing each model to learn complementary information and label the unlabeled data for the others. This iterative process improves the overall performance and robustness of the models, especially when the data has multiple representations, such as text and images. Co-training requires the training of two models on different views of the data and then using them to label the unlabeled data.
Benefits of co-training include:
- Leveraging Multiple Views: Utilizing different representations of the data to capture more comprehensive information.
- Improved Robustness: Training models that are less sensitive to noise and variations in the data.
- Enhanced Accuracy: Achieving higher accuracy by combining the strengths of multiple models.
15. What Future Trends Can We Expect in Semi-Supervised Learning?
Future trends in semi-supervised learning include the development of more robust and efficient algorithms, integration with deep learning architectures, and applications in emerging fields such as autonomous driving and personalized medicine. We can expect to see advancements in techniques that better leverage unlabeled data, handle noisy data, and scale to large datasets. Additionally, the combination of semi-supervised learning with other machine learning paradigms, such as transfer learning and reinforcement learning, will likely lead to new and innovative solutions.
Anticipated future trends:
- Advanced Algorithms: Development of more sophisticated algorithms that better leverage unlabeled data.
- Deep Learning Integration: Seamless integration of semi-supervised learning with deep learning architectures.
- Scalability: Techniques that can efficiently handle large datasets and high-dimensional data.
- Applications in New Fields: Adoption of semi-supervised learning in emerging fields such as autonomous driving and personalized medicine.
16. Can Semi-Supervised Learning be Applied to Time Series Data?
Yes, semi-supervised learning can be effectively applied to time series data for tasks such as anomaly detection, forecasting, and classification. By leveraging both labeled and unlabeled time series data, models can learn temporal patterns and dependencies, improving their ability to predict future values or detect anomalies. Techniques such as self-training and generative models can be adapted to handle the sequential nature of time series data.
Applications in time series analysis:
- Anomaly Detection: Identifying unusual patterns or events in time series data using limited labeled anomaly examples.
- Forecasting: Improving the accuracy of time series forecasting models by leveraging unlabeled historical data.
- Classification: Classifying different types of time series patterns using both labeled and unlabeled data.
17. What Role Does Data Augmentation Play in Semi-Supervised Learning?
Data augmentation plays a significant role in semi-supervised learning by artificially expanding the labeled dataset, improving model generalization and reducing overfitting. By generating new data samples from existing labeled data, augmentation techniques help models become more robust and better able to handle variations in the input data. This is particularly useful when labeled data is scarce, as it effectively increases the size and diversity of the training set.
Common data augmentation techniques:
- Image Data: Rotation, scaling, flipping, and cropping.
- Text Data: Synonym replacement, random insertion, and back-translation.
- Audio Data: Adding noise, time stretching, and pitch shifting.
Applied object detection in Aviation to detect aircraft. Alt text: Aircraft detection with computer vision, augmented for robust semi-supervised learning in aviation.
18. How Do You Evaluate the Performance of a Semi-Supervised Learning Model?
Evaluating the performance of a semi-supervised learning model involves using appropriate metrics, validation techniques, and comparisons with supervised and unsupervised models. Common metrics include accuracy, precision, recall, F1-score, and area under the ROC curve (AUC). Validation techniques such as cross-validation and hold-out validation are used to assess the model’s ability to generalize to new data.
Key evaluation strategies:
- Metrics: Use appropriate metrics based on the task (e.g., accuracy for classification, RMSE for regression).
- Validation: Employ cross-validation or hold-out validation to assess generalization.
- Comparison: Compare the model’s performance with supervised and unsupervised models to gauge the benefits of semi-supervised learning.
- Ablation Studies: Conduct ablation studies to understand the impact of different components of the semi-supervised learning approach.
19. What Tools and Libraries Are Available for Semi-Supervised Learning?
Several tools and libraries are available for implementing semi-supervised learning, including scikit-learn, TensorFlow, PyTorch, and specific semi-supervised learning packages like scikit-learn-contrib. These tools provide a range of algorithms, functions, and utilities for data preprocessing, model training, and evaluation. Scikit-learn offers basic semi-supervised learning algorithms, while TensorFlow and PyTorch provide the flexibility to implement more complex models and custom training loops.
Popular tools and libraries:
- Scikit-learn: Offers basic semi-supervised learning algorithms and utilities for data preprocessing and evaluation.
- TensorFlow: Provides a comprehensive framework for building and training custom semi-supervised models.
- PyTorch: Offers a flexible and dynamic platform for implementing advanced semi-supervised learning techniques.
- Scikit-learn-contrib: Contains additional semi-supervised learning algorithms not available in the core scikit-learn library.
20. Is Semi-Supervised Learning Always Better Than Supervised or Unsupervised Learning?
No, semi-supervised learning is not always better than supervised or unsupervised learning. The effectiveness of semi-supervised learning depends on the availability and quality of labeled data, the characteristics of the unlabeled data, and the appropriateness of the chosen algorithm. If labeled data is abundant and representative, supervised learning may be sufficient. If the data lacks clear structure or the assumptions of semi-supervised learning are not met, unsupervised learning may be more appropriate.
Factors to consider:
- Labeled Data Availability: If labeled data is abundant and representative, supervised learning may be sufficient.
- Data Characteristics: If the data lacks clear structure or the assumptions of semi-supervised learning are not met, unsupervised learning may be more appropriate.
- Algorithm Appropriateness: The chosen semi-supervised algorithm must align with the underlying data structure.
- Performance Goals: The specific performance goals of the application will influence the choice between supervised, unsupervised, and semi-supervised learning.
FAQ: Semi-Supervised Learning
-
What is semi-supervised learning?
- Semi-supervised learning is a machine learning approach that combines a small amount of labeled data with a large amount of unlabeled data to train models.
-
Why use semi-supervised learning?
- It is useful when labeled data is scarce or expensive to obtain, improving model accuracy and generalization.
-
What are common techniques in semi-supervised learning?
- Common techniques include self-training, co-training, multi-view learning, and generative models like GANs.
-
How does self-training work?
- A model is trained on labeled data and then used to predict labels for unlabeled data, iteratively improving performance.
-
What is the difference between semi-supervised and self-supervised learning?
- Semi-supervised learning uses both labeled and unlabeled data, while self-supervised learning uses only unlabeled data by creating pretext tasks.
-
What are the key assumptions in semi-supervised learning?
- The smoothness assumption, the cluster assumption, and the manifold assumption.
-
What is transductive learning?
- Transductive learning focuses on predicting labels only for the unlabeled data points in the current dataset.
-
How does data augmentation help in semi-supervised learning?
- Data augmentation artificially expands the labeled dataset, improving model generalization and reducing overfitting.
-
What are some real-world applications of semi-supervised learning?
- Medical imaging, natural language processing, speech recognition, and fraud detection.
-
What tools and libraries are available for semi-supervised learning?
- Scikit-learn, TensorFlow, PyTorch, and specific semi-supervised learning packages.
Ready to dive deeper into semi-supervised learning? Visit LEARNS.EDU.VN for comprehensive guides, expert tutorials, and cutting-edge courses designed to help you master this powerful AI technique. Whether you’re looking to enhance your skills or explore new career opportunities, LEARNS.EDU.VN is your ultimate resource for AI education.
Unlock your potential with LEARNS.EDU.VN today. For more information, contact us at 123 Education Way, Learnville, CA 90210, United States. Reach out via Whatsapp at +1 555-555-1212 or visit our website at learns.edu.vn.