Machine Learning Cheat Sheets provide a condensed overview of key concepts, algorithms, and techniques. At LEARNS.EDU.VN, we understand the importance of having readily accessible resources to navigate the complexities of machine learning, ensuring you have the tools to master this field. These cheat sheets act as quick references, solidifying your understanding and improving your problem-solving skills.
1. Understanding Machine Learning Fundamentals
1.1 What is Machine Learning?
Machine learning is a subfield of artificial intelligence (AI) that focuses on enabling systems to learn from data without being explicitly programmed. It involves developing algorithms that allow computers to improve their performance on a task through experience. According to a study by Stanford University, machine learning algorithms are increasingly used across various industries, demonstrating their broad applicability and effectiveness.
1.2 Types of Machine Learning
Machine learning algorithms can be categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning.
-
Supervised Learning: This type of learning involves training a model on labeled data, where the input features and corresponding output labels are provided. The goal is to learn a mapping function that can accurately predict the output for new, unseen inputs. Common algorithms include linear regression, logistic regression, and support vector machines.
-
Unsupervised Learning: In contrast to supervised learning, unsupervised learning deals with unlabeled data, where the algorithm must discover patterns, structures, and relationships on its own. Clustering, dimensionality reduction, and association rule mining are common techniques used in unsupervised learning.
-
Reinforcement Learning: This type of learning involves training an agent to make decisions in an environment to maximize a reward signal. The agent learns through trial and error, receiving feedback in the form of rewards or penalties for its actions. Reinforcement learning is often used in robotics, game playing, and control systems.
1.3 Key Concepts in Machine Learning
Several fundamental concepts are essential for understanding and applying machine learning techniques effectively.
-
Features: These are the input variables or attributes used to make predictions or classifications. Feature selection and engineering are crucial steps in the machine learning pipeline.
-
Models: Models are mathematical representations of the relationships between features and target variables. They can range from simple linear models to complex neural networks.
-
Algorithms: Algorithms are the specific procedures or steps used to train a model on data. Different algorithms have different strengths and weaknesses, depending on the type of problem and the characteristics of the data.
-
Training Data: This is the data used to train a machine learning model. It should be representative of the problem domain and contain sufficient examples to allow the model to learn effectively.
-
Testing Data: This is the data used to evaluate the performance of a trained model. It should be separate from the training data to provide an unbiased assessment of the model’s generalization ability.
-
Overfitting and Underfitting: Overfitting occurs when a model learns the training data too well, capturing noise and irrelevant patterns that do not generalize to new data. Underfitting occurs when a model is too simple to capture the underlying patterns in the data.
1.4 The Machine Learning Workflow
The machine learning workflow typically involves the following steps:
- Data Collection: Gathering relevant data from various sources.
- Data Preprocessing: Cleaning, transforming, and preparing the data for analysis.
- Feature Engineering: Selecting, extracting, and transforming features to improve model performance.
- Model Selection: Choosing an appropriate model based on the problem type and data characteristics.
- Model Training: Training the model on the training data.
- Model Evaluation: Evaluating the model’s performance on the testing data.
- Hyperparameter Tuning: Optimizing the model’s hyperparameters to improve its performance.
- Deployment: Deploying the trained model for making predictions on new data.
- Monitoring: Continuously monitoring the model’s performance and retraining it as needed.
2. Essential Classification Metrics Cheat Sheet
2.1 Confusion Matrix
The confusion matrix is a fundamental tool for evaluating the performance of a classification model. It provides a breakdown of the model’s predictions into four categories:
- True Positives (TP): Instances that were correctly predicted as positive.
- False Positives (FP): Instances that were incorrectly predicted as positive (Type I error).
- True Negatives (TN): Instances that were correctly predicted as negative.
- False Negatives (FN): Instances that were incorrectly predicted as negative (Type II error).
Here’s a sample Confusion Matrix:
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
2.2 Key Classification Metrics
Several metrics can be derived from the confusion matrix to assess the performance of a classification model:
-
Accuracy: The overall proportion of correctly classified instances:
$$text{Accuracy} = frac{TP + TN}{TP + TN + FP + FN}$$
-
Precision: The proportion of true positive predictions among all positive predictions:
$$text{Precision} = frac{TP}{TP + FP}$$
-
Recall (Sensitivity): The proportion of true positive predictions among all actual positive instances:
$$text{Recall} = frac{TP}{TP + FN}$$
-
Specificity: The proportion of true negative predictions among all actual negative instances:
$$text{Specificity} = frac{TN}{TN + FP}$$
-
F1-Score: The harmonic mean of precision and recall, providing a balanced measure of performance:
$$text{F1-Score} = 2 times frac{text{Precision} times text{Recall}}{text{Precision} + text{Recall}}$$
2.3 ROC and AUC
The Receiver Operating Characteristic (ROC) curve is a graphical representation of the trade-off between the true positive rate (TPR) and the false positive rate (FPR) at various threshold settings. The Area Under the Curve (AUC) is a single scalar value that summarizes the overall performance of the classifier. A higher AUC indicates better performance.
-
True Positive Rate (TPR): Also known as recall or sensitivity:
$$TPR = frac{TP}{TP + FN}$$
-
False Positive Rate (FPR):
$$FPR = frac{FP}{TN + FP}$$
2.4 Practical Considerations
- When classes are imbalanced, accuracy can be misleading. Precision, recall, and F1-score provide a more nuanced view of performance.
- The choice of metric depends on the specific problem and the relative importance of minimizing false positives versus false negatives.
- ROC curves and AUC are useful for comparing the performance of different classifiers across a range of threshold settings.
3. Regression Metrics Cheat Sheet
3.1 Basic Regression Metrics
Evaluating regression models involves assessing how well the model’s predictions match the actual values. Several metrics are commonly used:
-
Mean Absolute Error (MAE): The average absolute difference between the predicted and actual values:
$$MAE = frac{1}{n} sum_{i=1}^{n} |y_i – hat{y}_i|$$
-
Mean Squared Error (MSE): The average squared difference between the predicted and actual values:
$$MSE = frac{1}{n} sum_{i=1}^{n} (y_i – hat{y}_i)^2$$
-
Root Mean Squared Error (RMSE): The square root of the MSE, providing a more interpretable measure in the original units of the target variable:
$$RMSE = sqrt{frac{1}{n} sum_{i=1}^{n} (y_i – hat{y}_i)^2}$$
-
R-squared (Coefficient of Determination): A measure of how well the model explains the variance in the target variable, ranging from 0 to 1:
$$R^2 = 1 – frac{sum_{i=1}^{n} (y_i – hat{y}i)^2}{sum{i=1}^{n} (y_i – bar{y})^2}$$
3.2 Adjusted R-squared
Adjusted R-squared is a modified version of R-squared that accounts for the number of predictors in the model. It penalizes the inclusion of irrelevant predictors that do not improve the model’s fit:
$$Adjusted R^2 = 1 – frac{(1 – R^2)(n – 1)}{n – k – 1}$$
where $n$ is the number of observations and $k$ is the number of predictors.
3.3 Practical Considerations
- MAE is less sensitive to outliers than MSE and RMSE.
- RMSE is more interpretable than MSE because it is in the same units as the target variable.
- R-squared provides a measure of the proportion of variance explained by the model, but it can be misleading if the model is overfitting.
- Adjusted R-squared is a more reliable measure of model fit when comparing models with different numbers of predictors.
4. Model Selection Cheat Sheet
4.1 Bias-Variance Tradeoff
Model selection involves finding the right balance between bias and variance. A high-bias model is too simple and underfits the data, while a high-variance model is too complex and overfits the data.
-
High Bias (Underfitting):
- Symptoms: High training error, high test error, model is too simple.
- Remedies: Use a more complex model, add more features, train longer.
-
High Variance (Overfitting):
- Symptoms: Low training error, high test error, model is too complex.
- Remedies: Use a simpler model, reduce the number of features, increase the amount of training data, apply regularization.
4.2 Cross-Validation
Cross-validation is a technique for estimating the performance of a model on unseen data. It involves partitioning the data into multiple folds, training the model on a subset of the folds, and evaluating its performance on the remaining fold. Common types of cross-validation include:
- k-Fold Cross-Validation: The data is divided into $k$ folds, and the model is trained and evaluated $k$ times, each time using a different fold as the validation set.
- Leave-One-Out Cross-Validation (LOOCV): A special case of k-fold cross-validation where $k$ is equal to the number of data points.
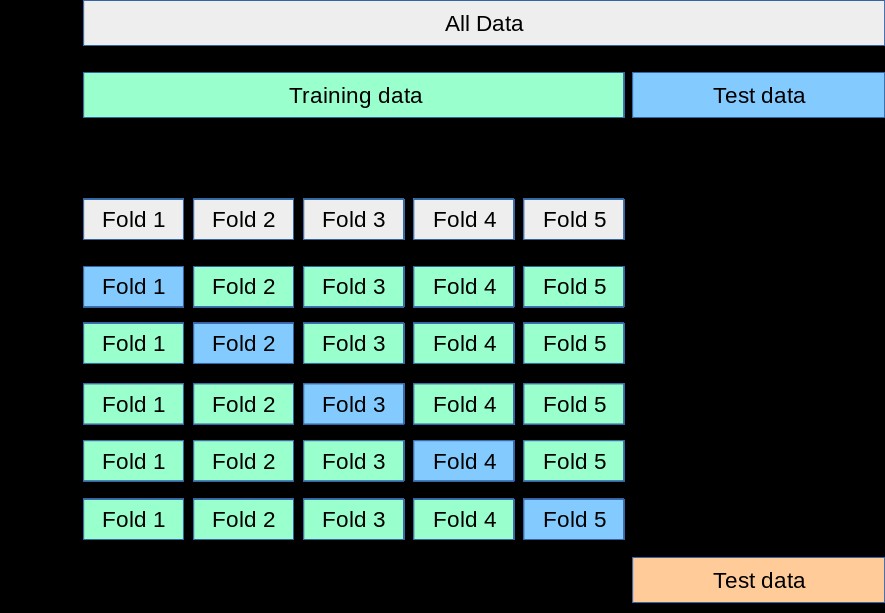 k-Fold Cross-Validation
k-Fold Cross-Validation
4.3 Regularization
Regularization is a technique for preventing overfitting by adding a penalty term to the loss function. Common types of regularization include:
- L1 Regularization (LASSO): Adds a penalty proportional to the absolute value of the coefficients, encouraging sparsity.
- L2 Regularization (Ridge): Adds a penalty proportional to the square of the coefficients, shrinking their magnitude.
- Elastic Net Regularization: A combination of L1 and L2 regularization.
| Regularization Type | Penalty Term | Effect |
|---|---|---|
| L1 (LASSO) | $$lambda sum_{i=1}^{n} | w_i |
| L2 (Ridge) | $$lambda sum_{i=1}^{n} w_i^2$$ | Shrinks coefficients, reduces multicollinearity |
| Elastic Net | $$lambda1 sum{i=1}^{n} | w_i |
4.4 Practical Considerations
- Use cross-validation to estimate the performance of different models and select the one that generalizes best to unseen data.
- Apply regularization to prevent overfitting, especially when dealing with high-dimensional data.
- Tune the hyperparameters of the model using techniques such as grid search or random search.
5. Common Machine Learning Algorithms
5.1 Supervised Learning Algorithms
Supervised learning algorithms learn from labeled data to make predictions or classifications. Here are some common algorithms:
- Linear Regression: Models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to the observed data.
- Logistic Regression: A binary classification algorithm that models the probability of a binary outcome using a logistic function.
- Support Vector Machines (SVM): A powerful classification algorithm that finds the optimal hyperplane to separate data points into different classes.
- Decision Trees: A tree-like model that makes decisions based on a series of if-then-else rules.
- Random Forests: An ensemble learning method that combines multiple decision trees to improve accuracy and reduce overfitting.
- Gradient Boosting Machines (GBM): Another ensemble learning method that builds a strong model by combining multiple weak learners in a sequential manner.
- Neural Networks: A complex model inspired by the structure of the human brain, consisting of interconnected nodes (neurons) organized in layers.
5.2 Unsupervised Learning Algorithms
Unsupervised learning algorithms discover patterns and structures in unlabeled data. Here are some common algorithms:
- K-Means Clustering: Partitions data points into $k$ clusters based on their distance to the cluster centroids.
- Hierarchical Clustering: Builds a hierarchy of clusters by iteratively merging or splitting clusters based on their similarity.
- Principal Component Analysis (PCA): A dimensionality reduction technique that transforms data into a new coordinate system where the principal components capture the most variance.
- Association Rule Mining: Discovers relationships between items in a dataset, such as frequent itemsets and association rules.
5.3 Algorithm Selection
Choosing the right algorithm depends on the specific problem, the type of data, and the desired outcome. Consider the following factors:
- Type of Problem: Is it a classification, regression, or clustering problem?
- Type of Data: Is the data labeled or unlabeled? Are there missing values or outliers?
- Desired Outcome: Do you need high accuracy, interpretability, or scalability?
- Computational Resources: How much time and memory do you have available?
6. Feature Engineering Cheat Sheet
6.1 Feature Transformation
Feature transformation involves scaling, normalizing, or transforming features to improve model performance. Common techniques include:
- Scaling: Rescaling features to a fixed range, such as [0, 1] (Min-Max Scaling) or to have zero mean and unit variance (Standard Scaling).
- Normalization: Adjusting feature values so that the sum of squares is equal to 1.
- Log Transformation: Applying a logarithmic function to reduce skewness and make the data more normally distributed.
- Polynomial Features: Creating new features by raising existing features to a power or combining them in polynomial terms.
6.2 Feature Selection
Feature selection involves selecting a subset of the most relevant features to improve model performance and reduce overfitting. Common techniques include:
- Univariate Selection: Selecting features based on statistical tests, such as chi-squared test or ANOVA.
- Recursive Feature Elimination (RFE): Iteratively removing features based on their importance to the model.
- Feature Importance from Tree-Based Models: Using the feature importances provided by tree-based models, such as random forests or gradient boosting machines.
- Regularization-Based Feature Selection: Using L1 regularization to shrink the coefficients of irrelevant features to zero.
6.3 Feature Encoding
Feature encoding involves converting categorical features into numerical representations that can be used by machine learning algorithms. Common techniques include:
- One-Hot Encoding: Creating binary indicator variables for each category.
- Label Encoding: Assigning a unique integer to each category.
- Target Encoding: Replacing each category with the mean of the target variable for that category.
7. Hyperparameter Tuning Cheat Sheet
7.1 Grid Search
Grid search involves exhaustively searching through a pre-defined grid of hyperparameter values and evaluating the model’s performance for each combination.
7.2 Random Search
Random search involves randomly sampling hyperparameter values from a pre-defined distribution and evaluating the model’s performance for each sample.
7.3 Bayesian Optimization
Bayesian optimization is a more advanced technique that uses a probabilistic model to guide the search for the optimal hyperparameters.
7.4 Practical Considerations
- Use cross-validation to evaluate the performance of different hyperparameter settings.
- Choose a suitable search space for the hyperparameters based on prior knowledge or experimentation.
- Consider using more advanced techniques, such as Bayesian optimization, for high-dimensional hyperparameter spaces.
8. Machine Learning Tools and Libraries
8.1 Python Libraries
Python is the most popular programming language for machine learning, with a rich ecosystem of libraries and tools. Some of the most commonly used libraries include:
-
Scikit-learn: A comprehensive library for machine learning, providing implementations of many common algorithms, as well as tools for data preprocessing, model evaluation, and hyperparameter tuning.
- Use Case: Implementing machine learning models from start to finish.
- Benefits: Wide range of algorithms, simple API, excellent documentation.
-
TensorFlow: A powerful library for deep learning, developed by Google.
- Use Case: Building and training deep neural networks.
- Benefits: Flexible, scalable, supports GPU acceleration.
-
Keras: A high-level API for building and training neural networks, running on top of TensorFlow, Theano, or CNTK.
- Use Case: Simplifying neural network construction.
- Benefits: User-friendly, modular, supports multiple backends.
-
PyTorch: Another popular library for deep learning, developed by Facebook.
- Use Case: Research and development in deep learning.
- Benefits: Dynamic computation graph, strong community support, easy to debug.
-
Pandas: A library for data manipulation and analysis, providing data structures such as DataFrames for storing and manipulating tabular data.
- Use Case: Data preprocessing, cleaning, and exploration.
- Benefits: Powerful data structures, flexible, easy to use.
-
NumPy: A library for numerical computing, providing support for arrays, matrices, and mathematical functions.
- Use Case: Numerical operations, linear algebra.
- Benefits: Efficient, optimized for numerical computation, widely used.
-
Matplotlib: A library for creating visualizations, such as plots, charts, and histograms.
- Use Case: Data visualization, exploratory data analysis.
- Benefits: Wide range of plot types, customizable, easy to use.
-
Seaborn: A library for creating statistical visualizations, building on top of Matplotlib.
- Use Case: Statistical data visualization, exploring relationships between variables.
- Benefits: High-level interface, aesthetically pleasing, informative.
8.2 Other Tools
In addition to Python libraries, several other tools can be helpful for machine learning:
- Jupyter Notebook: An interactive environment for writing and running code, creating visualizations, and documenting your work.
- Google Colab: A cloud-based Jupyter Notebook environment that provides free access to GPUs.
- Docker: A platform for containerizing applications, making it easy to deploy and run machine learning models in different environments.
9. Deployment Strategies Cheat Sheet
9.1 Model Deployment Options
Deploying a machine learning model involves making it available for making predictions on new data. Common deployment options include:
- Web API: Exposing the model as a web service that can be accessed via HTTP requests.
- Cloud Platform: Deploying the model on a cloud platform, such as Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure.
- Embedded System: Deploying the model on an embedded system, such as a smartphone or a microcontroller.
9.2 Model Monitoring
Once the model is deployed, it is essential to monitor its performance and retrain it as needed. Common monitoring metrics include:
- Accuracy: The overall proportion of correct predictions.
- Precision: The proportion of true positive predictions among all positive predictions.
- Recall: The proportion of true positive predictions among all actual positive instances.
- Latency: The time it takes to make a prediction.
- Throughput: The number of predictions that can be made per unit of time.
9.3 Practical Considerations
- Choose a deployment option that is appropriate for the specific application and the available resources.
- Implement model monitoring to detect and address performance degradation.
- Retrain the model periodically with new data to maintain its accuracy and relevance.
10. Ethical Considerations in Machine Learning
10.1 Bias and Fairness
Machine learning models can perpetuate and amplify biases present in the data, leading to unfair or discriminatory outcomes. It is essential to be aware of potential sources of bias and take steps to mitigate them.
10.2 Transparency and Interpretability
It is important to understand how machine learning models make decisions, especially in high-stakes applications. Techniques such as explainable AI (XAI) can help to improve the transparency and interpretability of models.
10.3 Privacy and Security
Machine learning models can be vulnerable to privacy and security risks, such as data breaches and adversarial attacks. It is essential to protect sensitive data and implement security measures to prevent attacks.
FAQ Section
1. What is a machine learning cheat sheet?
A machine learning cheat sheet is a condensed reference guide that summarizes key concepts, algorithms, and techniques in machine learning. It is designed to provide a quick overview of important information for practitioners and students.
2. Why do I need a machine learning cheat sheet?
A machine learning cheat sheet can help you quickly recall important concepts, algorithms, and techniques, saving you time and effort. It can also serve as a handy reference guide when working on machine learning projects.
3. What topics are typically covered in a machine learning cheat sheet?
Machine learning cheat sheets typically cover topics such as classification metrics, regression metrics, model selection, common algorithms, feature engineering, hyperparameter tuning, and ethical considerations.
4. Where can I find machine learning cheat sheets?
You can find machine learning cheat sheets on various websites, including academic institutions, research labs, and online communities. LEARNS.EDU.VN also provides comprehensive and up-to-date cheat sheets for various machine learning topics.
5. How can I use a machine learning cheat sheet effectively?
To use a machine learning cheat sheet effectively, familiarize yourself with the content and refer to it when you need a quick reminder or reference. Use it as a starting point for further exploration and learning.
6. Are machine learning cheat sheets suitable for beginners?
Yes, machine learning cheat sheets can be helpful for beginners as they provide a high-level overview of important concepts and techniques. However, it is important to supplement the cheat sheet with more detailed learning resources.
7. Can a machine learning cheat sheet help me prepare for interviews?
Yes, a machine learning cheat sheet can be a valuable tool for preparing for interviews as it helps you quickly review and recall key concepts and algorithms.
8. How often should I update my machine learning cheat sheet?
You should update your machine learning cheat sheet periodically to reflect new developments and advancements in the field. LEARNS.EDU.VN regularly updates its cheat sheets to ensure they are up-to-date.
9. What are the best practices for creating a machine learning cheat sheet?
When creating a machine learning cheat sheet, focus on clarity, conciseness, and accuracy. Use tables, diagrams, and bullet points to organize the information effectively.
10. Can I contribute to a machine learning cheat sheet?
Yes, many online communities and organizations welcome contributions to machine learning cheat sheets. Check their websites for guidelines and submission instructions.
Machine learning is a continuously evolving field, and staying updated with the latest trends, algorithms, and best practices is essential for success. These updates will be added into this page.
| Category | Update | Description |
|---|---|---|
| Explainable AI (XAI) | SHAP (SHapley Additive exPlanations) | A method to explain the output of any machine learning model using game-theoretic approach. |
| Federated Learning | Secure Aggregation | A privacy-preserving technique to aggregate model updates from multiple clients without sharing raw data. |
| Quantum ML | Quantum Support Vector Machines (QSVM) | Using quantum computing to speed up the training process and handle larger datasets. |
| AutoML | Neural Architecture Search (NAS) | Automates the design of neural networks, optimizing architectures for specific tasks. |
| Edge Computing | TinyML | Machine learning algorithms and applications optimized for deployment on low-power microcontrollers. |
| Generative Models | Variational Autoencoders (VAEs) | A type of generative model that learns a latent space representation of data. |
Mastering machine learning requires a solid understanding of fundamental concepts, practical techniques, and ethical considerations. By leveraging cheat sheets and continuously updating your knowledge, you can navigate the complexities of this field and build impactful solutions. At LEARNS.EDU.VN, we are committed to providing you with the resources and support you need to succeed in your machine learning journey.
Ready to take your machine learning skills to the next level? Visit LEARNS.EDU.VN today to explore our comprehensive courses and resources. Address: 123 Education Way, Learnville, CA 90210, United States. Whatsapp: +1 555-555-1212. Website: learns.edu.vn.

