Supervised Vs Unsupervised Machine Learning are two distinct approaches to machine learning, each with unique strengths and applications. At LEARNS.EDU.VN, we aim to clarify these concepts and guide you in choosing the right approach for your specific needs, enabling you to achieve your desired outcomes effectively. Understanding the difference between these methods and how they apply to real-world scenarios will enhance your machine learning knowledge and decision-making skills. Learn about data analysis techniques and explore the capabilities of machine learning algorithms to improve your machine learning journey.
1. What is Supervised Learning?
Supervised learning, often likened to learning with a teacher, involves training a machine learning model using well-labeled data. This means each input data point is paired with a correct answer or classification. The algorithm analyzes this training data to learn a function that maps inputs to outputs, enabling it to predict outcomes for new, unseen data.
1.1 How Supervised Learning Works
In supervised learning, the algorithm learns from labeled data, which acts as a guide or supervisor. This labeled data provides the algorithm with the correct answers, allowing it to adjust its internal parameters to minimize errors and improve accuracy.
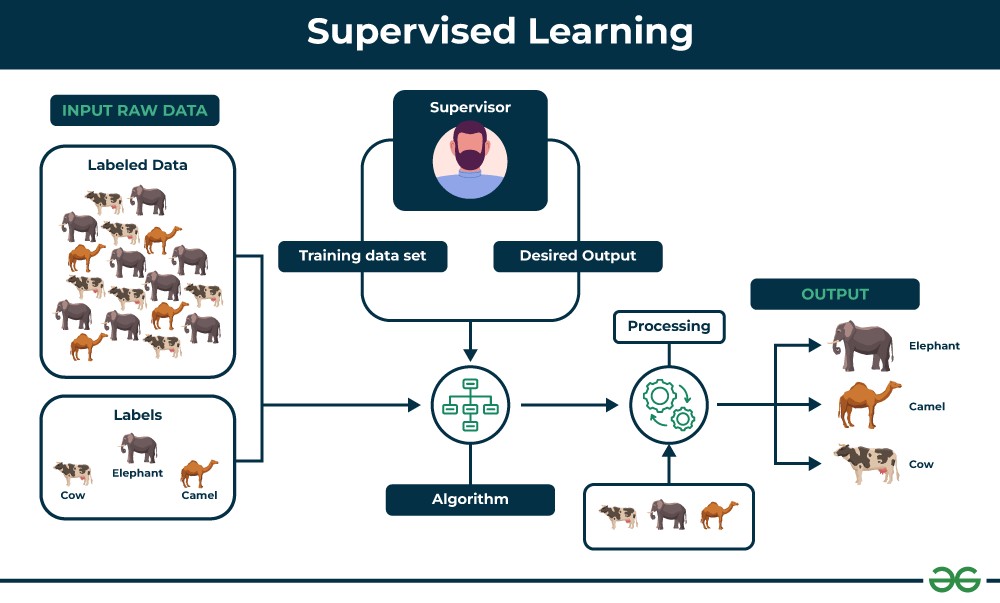 Supervised learning example with labeled data
Supervised learning example with labeled data
1.2 Example Scenario: Fruit Identification
Imagine training a model to identify different types of fruits. You would provide the model with images of various fruits, such as apples, bananas, and oranges, and label each image with the corresponding fruit name. The model would then learn to associate the visual features of each fruit (shape, color, texture) with its label. When presented with a new image of a fruit, the model would use its learned knowledge to predict the fruit’s identity.
1.3 Types of Supervised Learning Algorithms
Supervised learning algorithms can be broadly categorized into two types: regression and classification.
1.3.1 Regression
Regression algorithms are used to predict continuous values, such as house prices, stock prices, or temperature. These algorithms learn a function that maps input features to a continuous output value. Common regression algorithms include:
- Linear Regression
- Polynomial Regression
- Support Vector Regression
- Decision Tree Regression
- Random Forest Regression
1.3.2 Classification
Classification algorithms are used to predict categorical values, such as whether a customer will churn, whether an email is spam, or whether a medical image shows a tumor. These algorithms learn a function that maps input features to a probability distribution over the output classes. Common classification algorithms include:
- Logistic Regression
- K-Nearest Neighbors (KNN)
- Support Vector Machines (SVM)
- Decision Trees
- Random Forests
- Naive Bayes
1.4 Applications of Supervised Learning
Supervised learning has a wide range of applications across various industries:
- Spam Filtering: Classifying emails as spam or not spam based on their content and sender information.
- Image Classification: Identifying objects, animals, or scenes in images, such as recognizing faces in photos or classifying medical images for diagnosis.
- Medical Diagnosis: Predicting the likelihood of a disease based on patient data, such as symptoms, medical history, and test results.
- Fraud Detection: Identifying fraudulent transactions based on patterns in financial data.
- Natural Language Processing (NLP): Performing tasks such as sentiment analysis, machine translation, and text summarization.
1.5 Advantages of Supervised Learning
- Accurate Predictions: Supervised learning models can make highly accurate predictions when trained on well-labeled data.
- Clear Objectives: The availability of labeled data provides clear objectives for the learning process, making it easier to evaluate model performance.
- Wide Applicability: Supervised learning can be applied to a wide range of problems across various domains.
- Easy to Understand: The learning process and results of supervised learning models are often easier to understand and interpret compared to unsupervised learning models.
1.6 Disadvantages of Supervised Learning
- Requires Labeled Data: Supervised learning requires a large amount of well-labeled data, which can be expensive and time-consuming to obtain.
- Limited to Known Outcomes: Supervised learning models can only predict outcomes that are present in the training data, limiting their ability to generalize to new or unseen situations.
- Overfitting: Supervised learning models are prone to overfitting, where they learn the training data too well and fail to generalize to new data.
- Bias: Supervised learning models can be biased if the training data is biased, leading to inaccurate or unfair predictions.
2. What is Unsupervised Learning?
Unsupervised learning is a type of machine learning that involves training a model on unlabeled data, where the algorithm must discover patterns, structures, and relationships within the data without any predefined outputs or guidance.
2.1 How Unsupervised Learning Works
In unsupervised learning, the algorithm explores the data on its own, searching for inherent structures and patterns. It does not have access to any labeled examples or correct answers, forcing it to learn from the data’s intrinsic properties.
2.2 Example Scenario: Customer Segmentation
Imagine a marketing team wanting to segment their customer base into different groups based on their purchasing behavior. They have access to data on customer demographics, purchase history, and website activity, but they don’t have any predefined labels or categories for their customers. Using unsupervised learning techniques, such as clustering, they can group customers with similar characteristics and behaviors, allowing them to tailor their marketing efforts to each segment.
2.3 Types of Unsupervised Learning Algorithms
Unsupervised learning algorithms can be broadly categorized into two types: clustering and association rule learning.
2.3.1 Clustering
Clustering algorithms group similar data points together based on their inherent characteristics. These algorithms aim to minimize the distance between data points within the same cluster while maximizing the distance between data points in different clusters. Common clustering algorithms include:
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaussian Mixture Models (GMM)
2.3.2 Association Rule Learning
Association rule learning algorithms identify relationships between different items in a dataset. These algorithms are often used in market basket analysis to discover which items are frequently purchased together. A common association rule learning algorithm is:
- Apriori Algorithm
2.4 Applications of Unsupervised Learning
Unsupervised learning has a wide range of applications across various industries:
- Anomaly Detection: Identifying unusual patterns or outliers in data, such as detecting fraudulent transactions or identifying faulty equipment.
- Customer Segmentation: Grouping customers into different segments based on their demographics, purchasing behavior, and other characteristics.
- Recommendation Systems: Recommending products or content to users based on their past behavior and preferences.
- Dimensionality Reduction: Reducing the number of variables in a dataset while preserving its essential information, which can be useful for data visualization and feature extraction.
- Topic Modeling: Discovering the underlying topics in a collection of documents.
2.5 Advantages of Unsupervised Learning
- No Labeled Data Required: Unsupervised learning can be used on unlabeled data, which is often easier and cheaper to obtain than labeled data.
- Discovers Hidden Patterns: Unsupervised learning can uncover hidden patterns and relationships in data that may not be apparent through manual analysis.
- Exploratory Analysis: Unsupervised learning is a valuable tool for exploratory data analysis, allowing you to gain insights into the structure and characteristics of your data.
- Adaptability: Unsupervised learning models can adapt to changes in the data without requiring retraining on new labeled data.
2.6 Disadvantages of Unsupervised Learning
- Difficult to Evaluate: Evaluating the performance of unsupervised learning models can be challenging, as there are no predefined outputs or correct answers to compare against.
- Less Accurate: Unsupervised learning models are generally less accurate than supervised learning models, as they do not have access to labeled data to guide their learning process.
- Requires Domain Expertise: Interpreting the results of unsupervised learning models often requires domain expertise to understand the meaning and significance of the discovered patterns.
- Sensitive to Noise: Unsupervised learning models can be sensitive to noise and outliers in the data, which can distort the results and lead to inaccurate conclusions.
3. Supervised vs Unsupervised Machine Learning: Key Differences
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled data | Unlabeled data |
| Goal | Predict outcomes based on labeled data | Discover patterns and relationships in unlabeled data |
| Algorithms | Regression, Classification | Clustering, Association Rule Learning |
| Evaluation | Easier to evaluate using labeled data | More difficult to evaluate |
| Accuracy | Generally more accurate | Generally less accurate |
| Applications | Spam filtering, image classification, medical diagnosis | Anomaly detection, customer segmentation, recommendation systems |
| Complexity | Simpler to implement | More complex to implement |
| Human Input | Requires significant human input for labeling data | Requires less human input |
| Feedback Mechanism | Has a feedback mechanism to improve accuracy | Lacks a direct feedback mechanism |
| Real-time Analysis | Less suited for real-time analysis | Suitable for real-time analysis |
| Model Testing | Model can be easily tested | Model testing is more challenging |
| Supervision | Requires supervision to train the model | Does not need supervision |
| Output | Desired output is given | Desired output is not given |
| Training Data | Uses training data to infer a model | Does not use training data |
3.1 Data and Learning Process
The fundamental difference lies in the data used. Supervised learning relies on labeled data, where each input is paired with a known output. The algorithm learns from this labeled data to predict outcomes for new, unseen inputs. In contrast, unsupervised learning works with unlabeled data, where the algorithm must discover patterns and relationships without any prior knowledge of the correct outputs.
3.2 Goal and Objectives
In supervised learning, the goal is to learn a function that maps inputs to outputs, enabling the model to make accurate predictions. In unsupervised learning, the goal is to discover hidden structures and patterns in the data, such as clusters, associations, or anomalies.
3.3 Evaluation and Accuracy
Evaluating the performance of supervised learning models is relatively straightforward, as you can compare the model’s predictions to the known labels in the test data. Evaluating unsupervised learning models is more challenging, as there are no predefined outputs to compare against. As a result, supervised learning models generally achieve higher accuracy than unsupervised learning models.
3.4 Applications and Use Cases
Supervised learning is well-suited for tasks where you have labeled data and want to predict specific outcomes, such as classifying emails as spam or predicting customer churn. Unsupervised learning is well-suited for tasks where you want to explore the data and discover hidden patterns, such as segmenting customers or detecting anomalies.
3.5 Complexity and Implementation
Supervised learning algorithms are generally simpler to implement than unsupervised learning algorithms. This is because supervised learning algorithms have a clear objective and a well-defined learning process. Unsupervised learning algorithms, on the other hand, require more sophisticated techniques to explore the data and discover meaningful patterns.
4. Choosing the Right Approach
Choosing between supervised and unsupervised learning depends on several factors, including the availability of labeled data, the desired outcome, and the complexity of the problem.
4.1 Availability of Labeled Data
If you have access to a large amount of well-labeled data, supervised learning is generally the preferred approach. Labeled data provides the algorithm with the necessary guidance to learn accurate predictive models. If you have limited or no labeled data, unsupervised learning is the only option.
4.2 Desired Outcome
If you have a clear objective and want to predict specific outcomes, supervised learning is the better choice. If you want to explore the data and discover hidden patterns, unsupervised learning is more appropriate.
4.3 Complexity of the Problem
For simple problems with well-defined relationships between inputs and outputs, supervised learning is often sufficient. For complex problems with intricate relationships and hidden patterns, unsupervised learning may be necessary to uncover valuable insights.
5. Real-World Examples of Supervised and Unsupervised Learning
To further illustrate the differences and applications of supervised and unsupervised learning, let’s consider some real-world examples.
5.1 Supervised Learning Examples:
- Credit Risk Assessment: Banks use supervised learning to assess the credit risk of loan applicants. By training a model on historical data of loan applications with labeled outcomes (e.g., whether the loan was repaid or defaulted), the model can predict the likelihood of a new applicant defaulting on their loan. This helps banks make informed decisions about loan approvals.
- Predictive Maintenance: Manufacturing companies use supervised learning to predict when equipment is likely to fail. By training a model on sensor data from equipment with labeled outcomes (e.g., whether the equipment failed or not), the model can identify patterns that indicate an impending failure. This allows companies to schedule maintenance proactively, preventing costly downtime. According to a study by Deloitte, predictive maintenance can reduce maintenance costs by up to 25% and increase equipment uptime by up to 20%.
- Spam Email Detection: Email providers use supervised learning to detect and filter spam emails. By training a model on a dataset of emails labeled as either spam or not spam, the model can learn to identify the characteristics of spam emails and automatically filter them out of users’ inboxes.
5.2 Unsupervised Learning Examples:
- Customer Segmentation for Targeted Marketing: Retail companies use unsupervised learning to segment their customer base into distinct groups based on their purchasing behavior, demographics, and other characteristics. By identifying these segments, companies can tailor their marketing campaigns and promotions to each group, increasing the effectiveness of their marketing efforts.
- Fraud Detection in Financial Transactions: Financial institutions use unsupervised learning to detect fraudulent transactions by identifying unusual patterns and anomalies in transaction data. For example, an unsupervised learning algorithm might identify a cluster of transactions originating from a new location with unusually high values, indicating potential fraud.
- Anomaly Detection in Network Security: Cybersecurity firms use unsupervised learning to detect anomalies in network traffic that may indicate a cyberattack. By training a model on normal network traffic patterns, the model can identify deviations from these patterns that may signal malicious activity, such as a denial-of-service attack or data breach.
6. Deep Dive into Algorithms: Supervised Learning
6.1 Linear Regression
Linear regression is a fundamental supervised learning algorithm used for predicting continuous values. It models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to the observed data. The goal is to find the line that best fits the data, minimizing the difference between the predicted and actual values.
- Use Cases: Predicting house prices based on square footage, estimating sales based on advertising spend, forecasting temperature based on historical data.
- Advantages: Simple to implement and interpret, computationally efficient.
- Disadvantages: Assumes a linear relationship between variables, sensitive to outliers.
- Example: According to Zillow, linear regression models are widely used in real estate to estimate property values based on various features like location, size, and amenities.
6.2 Logistic Regression
Logistic regression is a supervised learning algorithm used for binary classification problems, where the goal is to predict one of two possible outcomes. It models the probability of an event occurring by fitting a logistic function to the observed data. The output is a value between 0 and 1, representing the probability of the event occurring.
- Use Cases: Predicting whether a customer will churn, classifying emails as spam or not spam, diagnosing whether a patient has a disease.
- Advantages: Easy to implement and interpret, provides probabilities for classification.
- Disadvantages: Assumes a linear relationship between variables, sensitive to outliers.
- Example: According to a study by IBM, logistic regression is commonly used in healthcare to predict the likelihood of a patient developing a disease based on various risk factors.
6.3 Decision Trees
Decision trees are supervised learning algorithms used for both classification and regression problems. They work by partitioning the data into subsets based on a series of decisions, represented as a tree structure. Each internal node represents a decision based on an attribute, and each leaf node represents the final outcome.
- Use Cases: Predicting customer behavior, diagnosing medical conditions, assessing credit risk.
- Advantages: Easy to understand and interpret, can handle both numerical and categorical data.
- Disadvantages: Prone to overfitting, can be unstable.
- Example: According to a report by Gartner, decision trees are widely used in customer relationship management (CRM) to predict customer behavior and improve customer satisfaction.
6.4 Random Forests
Random forests are supervised learning algorithms that combine multiple decision trees to improve accuracy and reduce overfitting. They work by creating a collection of decision trees, each trained on a random subset of the data and a random subset of the features. The final prediction is made by aggregating the predictions of all the individual trees.
- Use Cases: Image classification, fraud detection, predicting stock prices.
- Advantages: High accuracy, robust to outliers and noise, reduces overfitting.
- Disadvantages: More complex to implement and interpret than decision trees, computationally intensive.
- Example: According to research by the University of California, Berkeley, random forests are widely used in image classification tasks due to their high accuracy and robustness.
6.5 Support Vector Machines (SVM)
Support Vector Machines (SVM) are supervised learning algorithms used for both classification and regression problems. They work by finding the optimal hyperplane that separates the data into different classes, maximizing the margin between the hyperplane and the closest data points.
- Use Cases: Image classification, text categorization, bioinformatics.
- Advantages: High accuracy, effective in high-dimensional spaces, robust to outliers.
- Disadvantages: Computationally intensive, sensitive to parameter tuning.
- Example: According to a study by Stanford University, SVMs are widely used in bioinformatics for tasks such as protein classification and gene expression analysis.
7. Unveiling the Power of Algorithms: Unsupervised Learning
7.1 K-Means Clustering
K-Means Clustering is an unsupervised learning algorithm used for partitioning data into K clusters, where each data point belongs to the cluster with the nearest mean (centroid). The algorithm iteratively assigns data points to clusters and updates the centroids until the clusters stabilize.
- Use Cases: Customer segmentation, image compression, anomaly detection.
- Advantages: Simple to implement and interpret, computationally efficient.
- Disadvantages: Requires specifying the number of clusters (K) in advance, sensitive to initial centroid placement.
- Example: According to a report by McKinsey, K-Means Clustering is commonly used in marketing to segment customers based on their purchasing behavior and demographics.
7.2 Hierarchical Clustering
Hierarchical Clustering is an unsupervised learning algorithm used for building a hierarchy of clusters, where each data point starts as its own cluster, and clusters are iteratively merged based on their similarity until a single cluster remains. The results are represented as a dendrogram, which shows the hierarchical relationships between the clusters.
- Use Cases: Document clustering, biological taxonomy, image segmentation.
- Advantages: Does not require specifying the number of clusters in advance, provides a hierarchical view of the data.
- Disadvantages: Computationally intensive, sensitive to noise and outliers.
- Example: According to research by the National Institutes of Health (NIH), hierarchical clustering is widely used in bioinformatics to analyze gene expression data and identify patterns of gene co-expression.
7.3 DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is an unsupervised learning algorithm used for finding clusters of data points that are densely packed together, while also identifying noise points that lie in low-density regions. It works by grouping together data points that are close to each other, based on a distance metric and a minimum number of points within a specified radius.
- Use Cases: Anomaly detection, image segmentation, geographic data analysis.
- Advantages: Does not require specifying the number of clusters in advance, can identify clusters of arbitrary shapes, robust to noise and outliers.
- Disadvantages: Sensitive to parameter tuning, can struggle with high-dimensional data.
- Example: According to a study by the University of Oxford, DBSCAN is commonly used in geographic data analysis to identify clusters of crime incidents or traffic accidents.
7.4 Association Rule Learning
Association Rule Learning is an unsupervised learning algorithm used for discovering interesting relationships between variables in large datasets. It identifies frequent itemsets (sets of items that occur together frequently) and generates association rules, which describe the relationships between these items.
- Use Cases: Market basket analysis, recommendation systems, web usage mining.
- Advantages: Can uncover hidden relationships between variables, easy to interpret.
- Disadvantages: Can generate a large number of rules, sensitive to data sparsity.
- Example: According to a report by Amazon, association rule learning is widely used in e-commerce to recommend products to customers based on their past purchases and browsing history.
8. Best Practices for Supervised and Unsupervised Learning
To maximize the effectiveness of supervised and unsupervised learning, it’s essential to follow best practices for data preparation, model selection, and evaluation.
8.1 Data Preparation
- Data Cleaning: Remove or correct inaccurate, incomplete, or irrelevant data.
- Data Transformation: Convert data into a suitable format for the chosen algorithm, such as scaling numerical features or encoding categorical features.
- Feature Engineering: Create new features from existing ones to improve model performance.
8.2 Model Selection
- Algorithm Selection: Choose an algorithm that is appropriate for the type of problem and data.
- Hyperparameter Tuning: Optimize the algorithm’s hyperparameters to achieve the best performance.
- Cross-Validation: Use cross-validation to evaluate model performance and prevent overfitting.
8.3 Evaluation
- Metrics: Use appropriate metrics to evaluate model performance, such as accuracy, precision, recall, or F1-score for classification problems, and mean squared error or R-squared for regression problems.
- Visualization: Use visualizations to gain insights into model performance and identify areas for improvement.
- Benchmarking: Compare model performance to a baseline or existing solution to assess its effectiveness.
9. The Future of Supervised and Unsupervised Learning
The fields of supervised and unsupervised learning are constantly evolving, with new algorithms and techniques emerging all the time. Some of the key trends and future directions include:
- Deep Learning: Deep learning, a subset of machine learning that uses artificial neural networks with multiple layers, has achieved remarkable success in various tasks, including image recognition, natural language processing, and speech recognition. Deep learning models can be trained using both supervised and unsupervised learning techniques.
- Self-Supervised Learning: Self-supervised learning is a type of unsupervised learning where the model learns from the data itself, without relying on external labels. This approach involves creating artificial labels from the data and using them to train the model. Self-supervised learning has shown promising results in areas such as image and video understanding.
- Federated Learning: Federated learning is a distributed learning approach where models are trained on decentralized data sources, such as mobile devices or edge servers, without sharing the data itself. This approach enables collaborative learning while preserving data privacy.
- Explainable AI (XAI): Explainable AI (XAI) aims to develop machine learning models that are more transparent and interpretable, allowing humans to understand how the models make decisions. XAI techniques can be applied to both supervised and unsupervised learning models.
10. Enhancing Your Learning Journey with LEARNS.EDU.VN
At LEARNS.EDU.VN, we understand the challenges you face in finding reliable and high-quality learning resources. That’s why we’re dedicated to providing comprehensive and easy-to-understand guides on various topics, including machine learning, data science, and artificial intelligence. Our goal is to empower you with the knowledge and skills you need to succeed in today’s rapidly evolving world.
10.1 Comprehensive Learning Resources
We offer a wide range of articles, tutorials, and courses covering various aspects of supervised and unsupervised machine learning. Whether you’re a beginner or an experienced practitioner, you’ll find valuable resources to enhance your understanding and skills.
10.2 Expert Guidance
Our team of experienced educators and industry experts is committed to providing you with accurate and up-to-date information. We carefully curate our content to ensure that it meets the highest standards of quality and relevance.
10.3 Personalized Learning Experience
We believe that everyone learns differently. That’s why we offer a personalized learning experience that adapts to your individual needs and preferences. Our platform allows you to track your progress, identify areas for improvement, and receive customized recommendations.
10.4 Community Support
Join our vibrant community of learners and connect with like-minded individuals from around the world. Share your knowledge, ask questions, and collaborate on projects. Our community is a valuable resource for support and inspiration.
Don’t let the complexities of machine learning hold you back. Visit LEARNS.EDU.VN today and unlock your full potential. Explore our comprehensive learning resources, connect with our expert educators, and join our supportive community.
FAQ: Supervised vs Unsupervised Machine Learning
1. What is the main difference between supervised and unsupervised learning?
Supervised learning uses labeled data for training, while unsupervised learning uses unlabeled data.
2. Which type of learning is more accurate?
Supervised learning is generally more accurate due to the availability of labeled data for guidance.
3. When should I use supervised learning?
Use supervised learning when you have labeled data and want to predict specific outcomes.
4. When should I use unsupervised learning?
Use unsupervised learning when you want to explore data and discover hidden patterns.
5. What are some common supervised learning algorithms?
Common supervised learning algorithms include linear regression, logistic regression, decision trees, and support vector machines.
6. What are some common unsupervised learning algorithms?
Common unsupervised learning algorithms include k-means clustering, hierarchical clustering, and association rule learning.
7. Which type of learning requires more human input?
Supervised learning requires more human input for labeling data.
8. Is it easier to evaluate supervised or unsupervised learning models?
It is easier to evaluate supervised learning models due to the availability of labeled data for comparison.
9. Can I use both supervised and unsupervised learning together?
Yes, you can use both supervised and unsupervised learning techniques in combination to solve complex problems.
10. How can I learn more about supervised and unsupervised learning?
Visit LEARNS.EDU.VN for comprehensive learning resources, expert guidance, and community support.
Ready to dive deeper into the world of machine learning? Visit learns.edu.vn to explore our extensive resources and courses. Whether you’re looking to master the intricacies of supervised learning or uncover the hidden patterns with unsupervised methods, we have the tools and expertise to guide you. Join our community of learners and start your journey toward becoming a machine learning expert today! Contact us at 123 Education Way, Learnville, CA 90210, United States or Whatsapp: +1 555-555-1212.