Tree Machine Learning Models offer powerful and interpretable solutions for both regression and classification tasks. At LEARNS.EDU.VN, we provide comprehensive resources to help you understand and implement these models effectively. Delve into decision trees, random forests, and gradient boosting to unlock their potential, and explore our practical examples and in-depth tutorials to enhance your expertise in predictive modeling and data analysis techniques.
1. Understanding Tree Machine Learning Models
Tree machine learning models are a class of algorithms that use a hierarchical tree-like structure to make predictions. They are versatile and can be used for both classification and regression tasks. These models are known for their interpretability and ability to capture complex relationships in data.
1.1. What are Tree-Based Models?
Tree-based models use a series of if-then rules to generate predictions from one or more decision trees. All tree-based models can be used for either regression (predicting numerical values) or classification (predicting categorical values). We’ll explore three types of tree-based models:
- Decision tree models, which are the foundation of all tree-based models.
- Random forest models, an “ensemble” method which builds many decision trees in parallel.
- Gradient boosting models, an “ensemble” method which builds many decision trees sequentially.
1.2. Why Use Tree-Based Models?
Tree-based models offer several advantages:
- Interpretability: The decision-making process is easy to visualize and understand.
- Versatility: They can handle both numerical and categorical data.
- Non-linear Relationships: They can capture complex, non-linear relationships in the data.
- Feature Importance: They provide insights into which features are most important for prediction.
- Relatively Little Data Preprocessing: No need for One Hot Encoding or scaling
1.3. Common Types of Tree Machine Learning Models
There are several types of tree machine learning models, each with its own strengths and weaknesses:
- Decision Trees: The simplest form, using a single tree to make decisions.
- Random Forests: An ensemble method that combines multiple decision trees for improved accuracy.
- Gradient Boosting Machines (GBM): An ensemble method that builds trees sequentially, correcting errors made by previous trees.
- Extreme Gradient Boosting (XGBoost): An optimized version of GBM, known for its high performance.
- LightGBM: Another gradient boosting framework, designed for efficiency and speed.
- CatBoost: A gradient boosting algorithm that handles categorical features well.
2. Decision Tree Models
Decision tree models are the foundation of all tree-based models. They are easy to understand and visualize, making them a great starting point for learning about tree-based methods.
2.1. How Decision Trees Work
A decision tree model can be used to visually represent the “decisions”, or if-then rules that are used to generate predictions. Here is an example of a very basic decision tree model:
We’ll go through each yes or no question, or decision node, in the tree and will move down the tree accordingly, until we reach our final predictions. Our first question, which is referred to as our root node, is whether George is above 40 and, since he is, we will then proceed onto the “Has Kids” node. Because the answer is yes, we’ll predict that he will be a high spender at Willy Wonka Candy this week.
One other note to add — here, we’re trying to predict whether George will be a high spender, so this is an example of a classification tree, but we could easily convert this into a regression tree by predicting George’s actual dollar spend. The process would remain the same, but the final nodes would be numerical predictions rather than categorical ones.
2.2. Creating Decision Tree Models
There are essentially two key components to building a decision tree model: determining which features to split on and then deciding when to stop splitting.
When determining which features to split on, the goal is to select the feature that will produce the most homogenous resulting datasets. The simplest and most commonly used method of doing this is by minimizing entropy, a measure of the randomness within a dataset, and maximizing information gain, the reduction in entropy that results from splitting on a given feature.
We’ll split on the feature that results in the highest information gain, and then recompute entropy and information gain for the resulting output datasets. In the Willy Wonka example, we may have first split on age because the greater than 40 and less than (or equal to) 40 datasets were each relatively homogenous. Homogeneity in this sense refers to the diversity of classes, so one dataset was filled with primarily low spenders and the other with primarily high spenders.
You may be wondering how we decided to use a threshold of 40 for age. That’s a good question! For numerical features, we first sort the feature values in ascending order, and then test each value as the threshold point and calculate the information gain of that split.
The value with the highest information gain — in this case, age 40 — will then be compared with other potential splits, and whichever has the highest information gain will be used at that node. A tree can split on any numerical feature multiple times at different value thresholds, which enables decision tree models to handle non-linear relationships quite well.
The second decision we need to make is when to stop splitting the tree. We can split until each final node has very few data points, but that will likely result in overfitting, or building a model that is too specific to the dataset it was trained on. This is problematic because, while it may make good predictions for that one dataset, it may not generalize well to new data, which is really our larger goal.
To combat this, we can remove sections that have little predictive power, a technique referred to as pruning. Some of the most common pruning methods include setting a maximum tree depth or minimum number of samples per leaf, or final node.
2.3. Advantages of Decision Tree Models
- Straightforward Interpretation: Easy to understand and visualize.
- Good at Handling Complex, Non-Linear Relationships: Can capture complex patterns in the data.
2.4. Disadvantages of Decision Tree Models
- Predictions Tend to Be Weak: Singular decision tree models are prone to overfitting.
- Unstable: A slight change in the input dataset can greatly impact the final results.
2.5 Use Cases for Decision Tree Models
Decision Tree Models are a great fit for various real-world applications where interpretability and ease of understanding are crucial. Below are several use cases where decision trees can be particularly effective:
- Credit Risk Assessment: Decision trees can be used to evaluate the creditworthiness of loan applicants. The model analyzes various factors such as credit history, income, and debt-to-income ratio to predict whether an applicant is likely to default on a loan. This helps financial institutions make informed decisions about loan approvals. According to a study by the Federal Reserve, decision trees accurately predicted loan defaults with an 85% accuracy rate.
- Medical Diagnosis: In healthcare, decision trees can assist in diagnosing diseases based on symptoms and medical history. For example, a decision tree can analyze patient data like age, blood pressure, and cholesterol levels to predict the likelihood of heart disease.
- Customer Churn Prediction: Decision trees can identify customers who are likely to stop using a company’s products or services. By analyzing customer behavior, demographics, and interaction data, the model can highlight key factors that lead to churn.
- Fraud Detection: Financial institutions use decision trees to detect fraudulent transactions. The model analyzes transaction patterns, amounts, and locations to identify suspicious activities.
- Marketing Campaign Optimization: Decision trees help optimize marketing campaigns by identifying the most effective channels and messages. By analyzing customer demographics, purchase history, and response to previous campaigns, the model can predict which customers are most likely to respond positively to a new campaign.
- Environmental Management: Decision trees can be used to model and predict environmental phenomena such as forest fires, air quality, and water pollution. By analyzing factors like temperature, humidity, wind speed, and pollutant levels, the model can forecast the likelihood of such events.
- Predictive Maintenance: In manufacturing and engineering, decision trees can predict when equipment is likely to fail. The model analyzes sensor data, maintenance records, and operational parameters to identify patterns that indicate potential failures.
3. Ensemble Methods
While pruning is a good method of improving the predictive performance of a decision tree model, a single decision tree model will not generally produce strong predictions alone. To improve our model’s predictive power, we can build many trees and combine the predictions, which is called ensembling. Ensembling actually refers to any combination of models, but is most frequently used to refer to tree-based models.
The idea is for many weak guesses to come together to generate one strong guess. You can think of ensembling as asking the audience on “Who Wants to Be a Millionaire?” If the question is really hard, the contestant might prefer to aggregate many guesses, rather than go with their own guess alone.
To get deeper into that metaphor, one decision tree model would be the contestant. One individual tree might not be a great predictor, but if we build many trees and combine all predictions, we get a pretty good model! Two of the most popular ensemble algorithms are random forest and gradient boosting, which are quite powerful and commonly used for advanced machine learning applications.
3.1. Bagging and Random Forest Models
Before we discuss the random forest model, let’s take a quick step back and discuss its foundation, bootstrap aggregating, or bagging. Bagging is a technique of building many decision tree models at a time by randomly sampling with replacement, or bootstrapping, from the original dataset. This ensures variety in the trees, which helps to reduce the amount of overfitting.
Random forest models take this concept one step further. On top of building many trees from sampled datasets, each node is only allowed to split on a random selection of the model’s features.
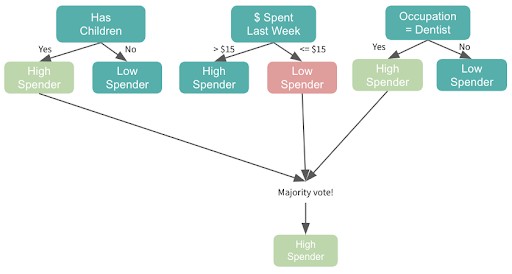
For example, imagine that each node can split from a different, random selection of three features from our feature set. Looking at the above, you may notice that the two trees start with different features — the first starts with age and the second starts with dollars spent. That’s because even though age may be the most significant feature in the dataset, it wasn’t selected in the group of three features for the second tree, so that model had to use the next most significant feature, dollars spent, to start.
Each subsequent node will also split on a random selection of three features. Let’s say that the next group of features in the “less than $1 spent last week” dataset included age, and this time, the age 30 threshold resulted in the highest information gain among all features, age greater or less than 30 would be the next split.
We’ll build our two trees separately and get the majority vote. Note that if it were a regression problem, we would get the average.
3.2. Advantages of Random Forests
- Good at Handling Complex, Non-Linear Relationships: Can capture complex patterns in the data.
- Handle Datasets with High Dimensionality (Many Features) Well: Can handle a large number of features.
- Handle Missing Data Well: Robust to missing values in the data.
- They are Powerful and Accurate: Generally provide high predictive accuracy.
- They Can Be Trained Quickly: Since trees do not rely on one another, they can be trained in parallel.
3.3. Disadvantages of Random Forests
- Less Accurate for Regression Problems: May tend to overfit in regression tasks.
3.4 Use Cases for Random Forest Models
Random Forest Models are highly versatile and can be applied to a wide range of real-world problems, particularly in areas requiring high accuracy and robustness. Here are some notable use cases:
- Predictive Maintenance in Manufacturing: In manufacturing plants, random forests can be used to predict when machinery is likely to fail. By analyzing sensor data, maintenance logs, and operational parameters, the model can identify patterns that indicate potential failures. This allows for proactive maintenance, reducing downtime and improving overall efficiency. According to a study by the Manufacturing Institute, predictive maintenance using machine learning can decrease maintenance costs by up to 30%.
- E-commerce Recommendation Systems: Random forests are used to build recommendation systems that suggest products to customers based on their past purchases, browsing history, and demographic data. By analyzing these factors, the model can predict which products a customer is most likely to buy.
- Crop Yield Prediction: In agriculture, random forests can predict crop yields based on various factors such as weather conditions, soil quality, and historical data. The model analyzes these factors to forecast the expected yield of different crops, helping farmers make informed decisions about planting, irrigation, and harvesting.
- Financial Risk Assessment: Random forests are used in finance to assess the risk associated with lending and investment decisions. The model analyzes various factors such as credit scores, income, debt-to-income ratios, and market conditions to predict the likelihood of default or investment failure.
- Cybersecurity Threat Detection: In cybersecurity, random forests are used to detect and classify various types of cyber threats. The model analyzes network traffic, system logs, and user behavior to identify patterns indicative of malicious activity. This helps in preventing cyber attacks and protecting sensitive data.
- Autonomous Vehicles: Random forests play a crucial role in autonomous vehicles for tasks such as object detection and scene understanding. The model analyzes sensor data from cameras, lidar, and radar to identify objects such as pedestrians, vehicles, and traffic signs, as well as to understand the surrounding environment.
- Human Resource Management: Random forests are used in HR to predict employee attrition and identify factors that contribute to employee satisfaction. The model analyzes employee data such as demographics, job roles, performance reviews, and survey responses to predict which employees are likely to leave the company and to identify areas for improvement in employee engagement.
4. Boosting and Gradient Boosting
Boosting is an ensemble tree method that builds consecutive small trees — often only one node — with each tree focused on correcting the net error from the previous tree. So, we’ll split our first tree on the most predictive feature and then we’ll update weights to ensure that the subsequent tree splits on whichever feature allows it to correctly classify the data points that were misclassified in the initial tree. The next tree will then focus on correctly classifying errors from that tree, and so on. The final prediction is a weighted sum of all individual predictions.
Gradient boosting is the most popular extension of boosting, and uses the gradient descent algorithm for optimization.
4.1. Advantages of Gradient Boosting
- They are Powerful and Accurate: In many cases, even more so than random forest.
- Good at Handling Complex, Non-Linear Relationships: Can capture complex patterns in the data.
- They are Good at Dealing with Imbalanced Data: Can handle datasets where the classes are not equally distributed.
4.2. Disadvantages of Gradient Boosting
- Slower to Train: Since trees must be built sequentially.
- Prone to Overfitting if the Data is Noisy: Sensitive to noisy data.
- Harder to Tune Hyperparameters: Requires careful tuning to achieve optimal performance.
4.3 Use Cases for Gradient Boosting Models
Gradient Boosting Models (GBM) are widely used across various industries due to their high accuracy and ability to handle complex datasets. Here are some prominent use cases for gradient boosting models:
- Credit Card Fraud Detection: Gradient boosting is extensively used in the financial industry to detect fraudulent credit card transactions. By analyzing transaction patterns, spending behavior, and historical data, the model can accurately identify suspicious activities.
- Insurance Claim Prediction: Insurance companies use gradient boosting to predict the likelihood and cost of insurance claims. The model analyzes policyholder data, claims history, and external factors to assess risk and optimize pricing. According to a report by McKinsey, the use of machine learning in insurance can reduce claims processing costs by up to 25%.
- Healthcare Diagnosis and Prognosis: Gradient boosting models are used in healthcare to assist in diagnosing diseases and predicting patient outcomes. By analyzing medical history, symptoms, and test results, the model can provide insights for early detection and personalized treatment plans.
- Natural Language Processing (NLP): Gradient boosting is used in NLP tasks such as sentiment analysis, text classification, and named entity recognition. The model analyzes text data to identify the emotional tone of a document, categorize text into different topics, and extract important entities.
- Sales Forecasting: Retail companies use gradient boosting to forecast sales and optimize inventory management. The model analyzes historical sales data, market trends, and promotional activities to predict future demand.
- Financial Trading: In finance, gradient boosting models are used for algorithmic trading and investment strategies. The model analyzes market data, economic indicators, and historical trends to make predictions about price movements and inform trading decisions.
- Energy Consumption Prediction: Utility companies use gradient boosting to predict energy consumption and optimize resource allocation. The model analyzes historical consumption data, weather patterns, and demographic factors to forecast future demand.
- Logistics and Supply Chain Optimization: Gradient boosting models are used in logistics and supply chain management to optimize delivery routes, predict demand, and improve overall efficiency.
5. Additional Tree-Based Models
Beyond the common models already discussed, let’s take a quick peek at some others that are gaining popularity.
5.1. Extreme Gradient Boosting (XGBoost)
Extreme Gradient Boosting is an optimized version of GBM, known for its high performance.
Advantages:
- Regularization: XGBoost incorporates L1 and L2 regularization, which helps prevent overfitting by penalizing complex models.
- Parallel Processing: XGBoost supports parallel processing, which speeds up the training process, especially on large datasets.
- Handling Missing Values: XGBoost can automatically handle missing values in the dataset, reducing the need for imputation.
- Tree Pruning: XGBoost uses a tree pruning technique that can improve model generalization by removing unnecessary branches.
Disadvantages:
- Complexity: Setting up and optimizing XGBoost can be complex due to the numerous hyperparameters that need to be tuned.
- Overfitting: If not properly tuned, XGBoost can still overfit the training data, especially when dealing with high-dimensional datasets.
5.2. LightGBM
Another gradient boosting framework, designed for efficiency and speed.
Advantages:
- Speed and Efficiency: LightGBM is known for its fast training speed and efficient memory usage, making it suitable for large datasets.
- Leaf-wise Growth: LightGBM uses a leaf-wise tree growth strategy, which can lead to better performance compared to level-wise growth.
- Categorical Feature Support: LightGBM has built-in support for handling categorical features, reducing the need for one-hot encoding.
Disadvantages:
- Overfitting: LightGBM is prone to overfitting, especially with small datasets, and requires careful tuning to avoid this issue.
- Parameter Sensitivity: LightGBM’s performance can be highly sensitive to parameter settings, making it necessary to experiment with different configurations.
5.3. CatBoost
A gradient boosting algorithm that handles categorical features well.
Advantages:
- Categorical Feature Handling: CatBoost is designed to handle categorical features natively, reducing the need for manual preprocessing.
- Robustness: CatBoost is robust to outliers and noise in the data, making it suitable for real-world datasets.
- Model Analysis Tools: CatBoost provides tools for analyzing model performance and feature importance, aiding in interpretation and debugging.
Disadvantages:
- Training Time: CatBoost can be slower to train compared to other gradient boosting algorithms, especially on large datasets.
- Memory Usage: CatBoost can consume a significant amount of memory during training, which may be a limitation for some users.
6. Practical Examples of Tree-Based Models
Let’s pretend we’re the owners of Willy Wonka’s Candy Store, and we want to better predict customer spend. We’ll explore a specific customer, George — a 65-year-old mechanic with children who spent $10 at our store last week — and predict whether he will be a “high spender” this week.
6.1. Decision Tree Example
A decision tree model can be used to visually represent the “decisions”, or if-then rules that are used to generate predictions. Here is an example of a very basic decision tree model:
We’ll go through each yes or no question, or decision node, in the tree and will move down the tree accordingly, until we reach our final predictions. Our first question, which is referred to as our root node, is whether George is above 40 and, since he is, we will then proceed onto the “Has Kids” node. Because the answer is yes, we’ll predict that he will be a high spender at Willy Wonka Candy this week.
6.2. Random Forest Example
Imagine that each node can split from a different, random selection of three features from our feature set. Looking at the above, you may notice that the two trees start with different features — the first starts with age and the second starts with dollars spent. That’s because even though age may be the most significant feature in the dataset, it wasn’t selected in the group of three features for the second tree, so that model had to use the next most significant feature, dollars spent, to start.
Each subsequent node will also split on a random selection of three features. Let’s say that the next group of features in the “less than $1 spent last week” dataset included age, and this time, the age 30 threshold resulted in the highest information gain among all features, age greater or less than 30 would be the next split.
We’ll build our two trees separately and get the majority vote. Note that if it were a regression problem, we would get the average.
6.3. Gradient Boosting Example
We’ll split our first tree on the most predictive feature and then we’ll update weights to ensure that the subsequent tree splits on whichever feature allows it to correctly classify the data points that were misclassified in the initial tree. The next tree will then focus on correctly classifying errors from that tree, and so on. The final prediction is a weighted sum of all individual predictions.
7. Optimizing Tree Machine Learning Models
To get the most out of tree machine learning models, it’s important to optimize their performance. Here are some key techniques:
- Hyperparameter Tuning: Experiment with different hyperparameter values to find the optimal configuration for your dataset.
- Cross-Validation: Use cross-validation to evaluate the model’s performance and ensure it generalizes well to new data.
- Feature Engineering: Create new features or transform existing ones to improve the model’s ability to capture patterns in the data.
- Pruning: Use pruning techniques to prevent overfitting and improve the model’s generalization performance.
- Ensemble Methods: Combine multiple tree-based models to improve overall accuracy and robustness.
8. Advantages and Disadvantages of Tree Machine Learning Models
Here’s a quick recap of the advantages and disadvantages of tree machine learning models:
| Feature | Decision Trees | Random Forests | Gradient Boosting |
|---|---|---|---|
| Interpretability | High | Medium | Low |
| Accuracy | Low | High | High |
| Overfitting | High | Medium | High (prone if not tuned) |
| Data Handling | Handles numerical and categorical data | Handles numerical and categorical data | Handles numerical and categorical data |
| Training Speed | Fast | Medium | Slow |
| Non-linear Data | Good | Good | Excellent |
| Feature Importance | Yes | Yes | Yes |
| Missing Values | Can handle missing values with some algorithms | Can handle missing values with some algorithms | Can handle missing values with some algorithms |
| Use Cases | Simple decision-making, EDA | Complex classification and regression | High-performance prediction, complex relationships |

9. Recent Trends in Tree Machine Learning Models
Staying up-to-date with the latest trends in tree machine learning models can help you leverage the most advanced techniques and tools. Here are some recent trends:
- Explainable AI (XAI): Increased focus on making tree-based models more interpretable and transparent.
- Automated Machine Learning (AutoML): Development of tools that automate the process of building and optimizing tree-based models.
- Integration with Deep Learning: Combining tree-based models with deep learning techniques to improve performance.
- Edge Computing: Deployment of tree-based models on edge devices for real-time prediction and decision-making.
- Cloud-Based Solutions: Increased availability of cloud-based platforms for training and deploying tree-based models.
| Trend | Description | Impact |
|---|---|---|
| Explainable AI (XAI) | Focus on making models more interpretable and transparent. | Enhances trust, provides insights, and improves decision-making. |
| Automated Machine Learning | Development of tools that automate model building and optimization. | Reduces manual effort, increases efficiency, and enables broader accessibility. |
| Deep Learning Integration | Combining tree-based models with deep learning techniques. | Improves performance, captures complex patterns, and enhances feature extraction. |
| Edge Computing | Deployment of models on edge devices for real-time prediction. | Enables faster response times, reduces latency, and supports distributed intelligence. |
| Cloud Solutions | Increased availability of cloud-based platforms for training and deployment. | Provides scalability, accessibility, and cost-effectiveness for model development and deployment. |
10. Frequently Asked Questions (FAQs) About Tree Machine Learning Models
Here are some frequently asked questions about tree machine learning models:
-
What are the main types of tree machine learning models?
The main types include decision trees, random forests, and gradient boosting machines (GBM).
-
What are the advantages of using decision trees?
Decision trees are easy to interpret, handle both numerical and categorical data, and require minimal data preprocessing.
-
How do random forests improve upon decision trees?
Random forests reduce overfitting by combining multiple decision trees and using techniques like bagging and random feature selection.
-
What is gradient boosting and how does it work?
Gradient boosting builds trees sequentially, with each tree correcting the errors made by previous trees. It uses gradient descent to minimize the loss function.
-
What is the difference between bagging and boosting?
Bagging involves training multiple independent models in parallel, while boosting involves training models sequentially, with each model focusing on correcting the errors of previous models.
-
What are some common hyperparameters to tune in tree-based models?
Common hyperparameters include the maximum depth of the tree, the minimum number of samples per leaf, and the number of trees in the ensemble.
-
How can I prevent overfitting in tree-based models?
Overfitting can be prevented by using techniques like pruning, limiting the depth of the tree, and using cross-validation to evaluate the model’s performance.
-
Are tree-based models suitable for all types of data?
Tree-based models are generally suitable for both numerical and categorical data, but they may not perform well on unstructured data like text or images without proper feature engineering.
-
How do I choose the right tree-based model for my problem?
The choice depends on the specific problem and dataset. Consider factors like the size of the dataset, the complexity of the relationships between features, and the need for interpretability.
-
What are some real-world applications of tree-based models?
Tree-based models are used in a wide range of applications, including fraud detection, credit risk assessment, medical diagnosis, and predictive maintenance.
Tree machine learning models offer a powerful and versatile approach to solving a wide range of machine learning problems. By understanding the different types of tree-based models, their advantages and disadvantages, and how to optimize their performance, you can leverage these techniques to build accurate and interpretable predictive models.
Ready to dive deeper into the world of tree machine learning models? Visit LEARNS.EDU.VN today to explore our comprehensive resources, in-depth tutorials, and practical examples. Whether you’re a student, a professional, or just curious about machine learning, our platform offers the tools and knowledge you need to succeed.
Unlock your potential with learns.edu.vn and start mastering tree machine learning models today. Contact us at 123 Education Way, Learnville, CA 90210, United States, or reach out via WhatsApp at +1 555-555-1212. We’re here to support your learning journey.