Machine learning, a subset of artificial intelligence, involves computers learning from data without explicit programming. Discover the different types of machine learning and their applications at LEARNS.EDU.VN, where we provide comprehensive educational resources. Dive into the world of supervised learning, unsupervised learning, and reinforcement learning, and explore how each method empowers systems to evolve and improve. Learn about machine learning categories, machine learning methods, and machine learning techniques, ensuring a comprehensive understanding of this transformative field.
1. Understanding Machine Learning: An Overview
Machine learning (ML) is a revolutionary field within artificial intelligence (AI) that empowers computers to learn from data, identify patterns, and make decisions with minimal human intervention. Unlike traditional programming, where explicit instructions are given for every task, ML algorithms improve their performance through experience. This dynamic learning process has led to significant advancements across various industries, transforming how we interact with technology and solve complex problems.
1.1. What is Machine Learning?
Machine learning is the science of enabling computers to learn from data without being explicitly programmed. This is achieved by developing algorithms that can analyze datasets, identify patterns, and make predictions or decisions based on the insights gained. The core principle of ML involves creating models that can adapt and improve as they are exposed to more data, thus enhancing their accuracy and efficiency over time.
According to a study by Stanford University, machine learning algorithms have shown a 20-30% improvement in predictive accuracy compared to traditional statistical models across various applications. This highlights the power and potential of ML in data-driven decision-making.
1.2. Key Concepts in Machine Learning
To grasp the essence of machine learning, it’s essential to understand the fundamental concepts that underpin this field:
- Algorithms: The set of rules and statistical techniques used to learn patterns from data.
- Models: The output of a machine learning algorithm, representing the learned relationships and patterns within the data.
- Data: The raw material for machine learning, which can be structured (e.g., tables, databases) or unstructured (e.g., text, images, audio).
- Features: The specific attributes or characteristics of the data that are used by the algorithm to make predictions.
- Training: The process of feeding data into an algorithm to create a model.
- Prediction: The output generated by the model when presented with new, unseen data.
These concepts form the backbone of machine learning, enabling systems to learn, adapt, and make informed decisions based on the data they analyze.
1.3. The Importance of Machine Learning
Machine learning is rapidly transforming industries and sectors worldwide due to its ability to:
- Automate Tasks: ML algorithms can automate repetitive and time-consuming tasks, freeing up human resources for more strategic activities.
- Enhance Decision-Making: By analyzing vast amounts of data, ML models can provide insights that lead to better, more informed decisions.
- Improve Accuracy: ML algorithms can improve their accuracy over time as they are exposed to more data, resulting in more reliable predictions.
- Personalize Experiences: ML can be used to personalize products, services, and content based on individual preferences and behaviors.
- Solve Complex Problems: ML can tackle complex problems that are difficult or impossible to solve using traditional methods.
According to a report by McKinsey, companies that have fully integrated machine learning into their operations are 23% more likely to achieve above-average revenue growth. This underscores the significant competitive advantage that ML can provide.
1.4. Applications of Machine Learning in Various Industries
Machine learning is being applied across a wide range of industries, demonstrating its versatility and transformative potential:
| Industry | Application |
|---|---|
| Healthcare | Diagnosing diseases, personalizing treatment plans, predicting patient outcomes. |
| Finance | Detecting fraud, assessing credit risk, automating trading, providing personalized financial advice. |
| Retail | Recommending products, optimizing inventory, predicting customer behavior, enhancing customer service. |
| Manufacturing | Predicting equipment failures, optimizing production processes, improving quality control. |
| Transportation | Optimizing routes, predicting traffic patterns, enhancing safety, enabling autonomous vehicles. |
| Marketing | Personalizing marketing campaigns, predicting customer churn, optimizing ad spending. |
| Education | Personalizing learning experiences, identifying at-risk students, automating grading, enhancing educational resources. |
| Cybersecurity | Detecting cyber threats, preventing data breaches, automating security tasks. |
| Energy | Optimizing energy consumption, predicting energy demand, enhancing grid reliability. |
| Entertainment | Recommending movies and music, personalizing content, creating realistic special effects. |
| Natural Language Processing | Powering virtual assistants, chatbots, and improving language translation services. |
The applications of machine learning are vast and continue to expand as technology evolves, promising to revolutionize how businesses operate and how we interact with the world around us.
LEARNS.EDU.VN is committed to providing comprehensive educational resources to help you understand and leverage the power of machine learning. Whether you’re a student, a professional, or simply curious about this exciting field, we offer the knowledge and tools you need to succeed.
2. Supervised Learning: Learning from Labeled Data
Supervised learning is a fundamental type of machine learning where algorithms learn from labeled datasets. In this approach, each data point is paired with a correct output, enabling the model to learn the mapping between inputs and desired outcomes. Supervised learning is widely used for tasks such as classification and regression, making it a cornerstone of many real-world applications.
2.1. What is Supervised Learning?
Supervised learning involves training a model on a dataset that includes both input features and corresponding labels. The labels represent the correct answers or outcomes for each input. The algorithm learns to predict the labels for new, unseen data based on the patterns it identifies in the training data. This process is akin to a student learning under the guidance of a teacher, hence the term “supervised.”
For example, in image classification, a supervised learning algorithm might be trained on a dataset of images labeled as either “cat” or “dog.” The algorithm learns to distinguish between the features of cats and dogs, allowing it to classify new images accurately.
2.2. Key Components of Supervised Learning
To effectively implement supervised learning, it’s important to understand its key components:
- Labeled Dataset: The foundation of supervised learning, containing both input features and corresponding labels.
- Training Data: The portion of the labeled dataset used to train the model.
- Validation Data: A separate portion of the labeled dataset used to fine-tune the model’s parameters and prevent overfitting.
- Testing Data: A final portion of the labeled dataset used to evaluate the model’s performance on unseen data.
- Algorithm: The specific learning algorithm used to create the model, such as linear regression, logistic regression, or decision trees.
- Model: The output of the training process, representing the learned relationships between inputs and outputs.
- Prediction: The output generated by the model when presented with new, unseen data.
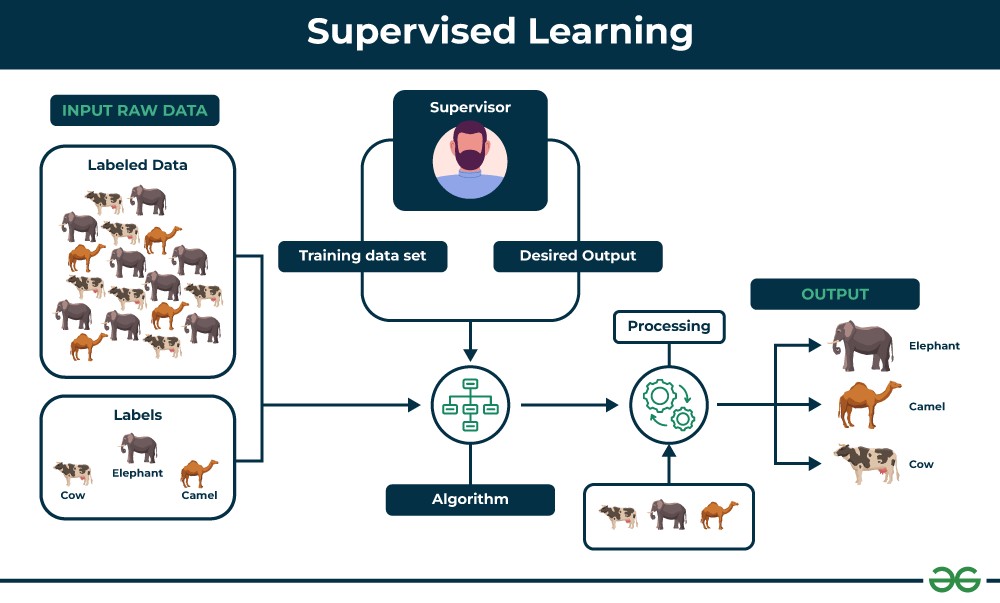 Supervised Learning
Supervised Learning
2.3. Types of Supervised Learning
Supervised learning can be broadly categorized into two main types:
- Classification: This type of supervised learning is used to predict categorical target variables, which represent discrete classes or labels.
- Regression: This type of supervised learning is used to predict continuous target variables, which represent numerical values.
2.3.1. Classification
Classification deals with predicting categorical target variables, which represent discrete classes or labels. The goal is to assign input data to one of the predefined classes. Examples of classification tasks include:
- Email Spam Detection: Classifying emails as either “spam” or “not spam.”
- Medical Diagnosis: Predicting whether a patient has a high risk of heart disease based on their medical history and test results.
- Image Recognition: Identifying objects, faces, or scenes in images.
- Credit Risk Assessment: Determining whether a loan applicant is likely to default on a loan.
Common Classification Algorithms:
- Logistic Regression: A linear model used for binary classification problems.
- Support Vector Machines (SVM): A powerful algorithm that finds the optimal hyperplane to separate data into different classes.
- Decision Trees: A tree-like model that makes decisions based on a series of rules.
- Random Forest: An ensemble method that combines multiple decision trees to improve accuracy and robustness.
- Naive Bayes: A probabilistic classifier based on Bayes’ theorem, assuming independence between features.
- K-Nearest Neighbors (KNN): A non-parametric algorithm that classifies data based on the majority class of its nearest neighbors.
2.3.2. Regression
Regression deals with predicting continuous target variables, which represent numerical values. The goal is to estimate the value of a target variable based on the input features. Examples of regression tasks include:
- House Price Prediction: Predicting the price of a house based on its size, location, and amenities.
- Sales Forecasting: Forecasting the sales of a product based on historical data and market trends.
- Stock Price Prediction: Predicting the price of a stock based on historical data and market indicators.
- Weather Forecasting: Predicting temperature, precipitation, and other meteorological parameters.
Common Regression Algorithms:
- Linear Regression: A linear model that finds the best-fitting line to describe the relationship between the input features and the target variable.
- Polynomial Regression: An extension of linear regression that allows for non-linear relationships between the input features and the target variable.
- Decision Tree Regression: A decision tree model used for regression tasks.
- Random Forest Regression: An ensemble method that combines multiple decision tree regressors to improve accuracy and robustness.
- Support Vector Regression (SVR): A support vector machine algorithm adapted for regression tasks.
- Neural Networks: Complex models that can learn non-linear relationships and handle large datasets.
2.4. Advantages of Supervised Learning
Supervised learning offers several advantages:
- High Accuracy: Supervised learning models can achieve high accuracy, especially when trained on large, well-labeled datasets.
- Interpretability: The decision-making process in supervised learning models is often interpretable, allowing users to understand how the model arrives at its predictions.
- Pre-trained Models: Supervised learning benefits from the availability of pre-trained models, which can save time and resources when developing new models from scratch.
- Clear Goals: The presence of labeled data provides a clear objective for the learning process, making it easier to evaluate and improve the model’s performance.
2.5. Disadvantages of Supervised Learning
Despite its advantages, supervised learning also has some limitations:
- Limited Pattern Recognition: Supervised learning models may struggle with unseen or unexpected patterns that are not present in the training data.
- Data Dependency: Supervised learning relies heavily on labeled data, which can be time-consuming and costly to obtain.
- Generalization Issues: Supervised learning models may lead to poor generalizations when applied to new data that differs significantly from the training data.
- Overfitting: Models can overfit the training data, leading to poor performance on unseen data.
2.6. Applications of Supervised Learning
Supervised learning is used in a wide variety of applications across various industries:
| Application | Description |
|---|---|
| Image Classification | Identifying objects, faces, and other features in images. |
| Natural Language Processing | Extracting information from text, such as sentiment, entities, and relationships. |
| Speech Recognition | Converting spoken language into text. |
| Recommendation Systems | Making personalized recommendations to users based on their preferences and behavior. |
| Predictive Analytics | Predicting outcomes such as sales, customer churn, and stock prices. |
| Medical Diagnosis | Detecting diseases and other medical conditions based on patient data. |
| Fraud Detection | Identifying fraudulent transactions. |
| Autonomous Vehicles | Recognizing and responding to objects in the environment to enable self-driving capabilities. |
| Email Spam Detection | Classifying emails as spam or not spam. |
| Quality Control in Manufacturing | Inspecting products for defects and ensuring quality standards are met. |
| Credit Scoring | Assessing the risk of a borrower defaulting on a loan. |
| Gaming | Recognizing characters, analyzing player behavior, and creating non-player characters (NPCs) that adapt to the player’s actions. |
Supervised learning is a powerful tool for solving a wide range of problems, and its applications continue to grow as technology advances and more data becomes available.
2.7. Real-World Examples of Supervised Learning
To further illustrate the power of supervised learning, here are a few real-world examples:
- Netflix Movie Recommendations: Netflix uses supervised learning algorithms to recommend movies and TV shows to its users based on their viewing history and preferences. By analyzing the movies a user has watched and rated, the algorithm can predict what other movies they might enjoy.
- Amazon Product Recommendations: Amazon employs supervised learning to recommend products to its customers based on their browsing history, purchase history, and demographic data. This helps customers discover new products and increases sales for Amazon.
- Spam Filters: Email providers use supervised learning algorithms to classify emails as spam or not spam. These algorithms learn from labeled data (emails that have been manually classified as spam or not spam) to identify patterns and features that are indicative of spam.
- Medical Diagnosis: Supervised learning is used in medical diagnosis to detect diseases and conditions based on patient data. For example, algorithms can be trained to identify cancerous tumors in medical images or predict a patient’s risk of developing a particular disease based on their medical history and lifestyle factors.
- Credit Scoring: Banks and financial institutions use supervised learning to assess the creditworthiness of loan applicants. These algorithms analyze data such as credit history, income, and employment status to predict the likelihood that an applicant will default on a loan.
These examples demonstrate the versatility and impact of supervised learning in various domains, highlighting its ability to solve complex problems and improve decision-making.
LEARNS.EDU.VN offers in-depth courses and resources on supervised learning, providing you with the knowledge and skills you need to implement these powerful algorithms in your own projects.
3. Unsupervised Learning: Discovering Hidden Patterns
Unsupervised learning is a type of machine learning that involves algorithms discovering patterns and relationships using unlabeled data. Unlike supervised learning, unsupervised learning doesn’t involve providing the algorithm with labeled target outputs. The primary goal of unsupervised learning is often to discover hidden patterns, similarities, or clusters within the data, which can then be used for various purposes, such as data exploration, visualization, dimensionality reduction, and more.
3.1. What is Unsupervised Learning?
In unsupervised learning, the algorithm is given a dataset without any predefined labels or target outputs. The algorithm’s task is to explore the data, identify patterns, and extract meaningful insights on its own. This is like giving a child a set of building blocks and asking them to create something interesting without providing any instructions. The algorithm must find its own way to structure and interpret the data.
For example, in customer segmentation, an unsupervised learning algorithm might be given a dataset of customer purchase histories without any information about customer demographics or preferences. The algorithm can then group customers into different segments based on their purchasing behavior, revealing valuable insights for marketing and product development.
3.2. Key Components of Unsupervised Learning
To effectively implement unsupervised learning, it’s important to understand its key components:
- Unlabeled Dataset: The foundation of unsupervised learning, containing input features without corresponding labels.
- Algorithm: The specific learning algorithm used to discover patterns in the data, such as clustering or dimensionality reduction.
- Model: The output of the training process, representing the discovered patterns and relationships within the data.
- Evaluation Metrics: Metrics used to assess the quality and usefulness of the discovered patterns.
- Data Preprocessing: Techniques used to clean and prepare the data for analysis, such as normalization, scaling, and handling missing values.
3.3. Types of Unsupervised Learning
Unsupervised learning can be broadly categorized into two main types:
- Clustering: This technique is used to group data points into clusters based on their similarity.
- Association: This technique is used to discover relationships between items in a dataset.
3.3.1. Clustering
Clustering is the process of grouping data points into clusters based on their similarity. The goal is to create clusters such that data points within the same cluster are more similar to each other than to data points in other clusters. This technique is useful for identifying patterns and relationships in data without the need for labeled examples.
Common Clustering Algorithms:
- K-Means: A centroid-based algorithm that partitions data into k clusters, where each data point belongs to the cluster with the nearest mean (centroid).
- Hierarchical Clustering: A method that builds a hierarchy of clusters, either by starting with each data point in its own cluster and merging clusters iteratively (agglomerative clustering) or by starting with all data points in one cluster and dividing clusters iteratively (divisive clustering).
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): A density-based algorithm that groups together data points that are closely packed together, marking as outliers data points that lie alone in low-density regions.
- Gaussian Mixture Models (GMM): A probabilistic model that assumes data points are generated from a mixture of Gaussian distributions.
3.3.2. Association
Association rule learning is a technique for discovering relationships between items in a dataset. It identifies rules that indicate the presence of one item implies the presence of another item with a specific probability.
Common Association Rule Learning Algorithms:
- Apriori: An algorithm that identifies frequent itemsets and generates association rules based on these itemsets.
- Eclat (Equivalence Class Clustering and bottom-up Lattice Traversal): A more efficient algorithm than Apriori, which uses a depth-first search to identify frequent itemsets.
- FP-Growth (Frequent Pattern Growth): An algorithm that constructs a frequent pattern tree (FP-tree) to efficiently identify frequent itemsets.
3.4. Advantages of Unsupervised Learning
Unsupervised learning offers several advantages:
- Pattern Discovery: It helps discover hidden patterns and various relationships between the data.
- Versatility: Used for tasks such as customer segmentation, anomaly detection, and data exploration.
- Reduced Effort: It does not require labeled data, reducing the effort of data labeling.
- Data Exploration: Helps in understanding the structure and characteristics of data without prior knowledge.
3.5. Disadvantages of Unsupervised Learning
Despite its advantages, unsupervised learning also has some limitations:
- Quality Prediction: Without using labels, it may be difficult to predict the quality of the model’s output.
- Interpretability: Cluster Interpretability may not be clear and may not have meaningful interpretations.
- Complexity: It has techniques such as autoencoders and dimensionality reduction that can be used to extract meaningful features from raw data, but these can be complex to implement.
- Subjectivity: The interpretation of results can be subjective and dependent on the domain knowledge of the analyst.
3.6. Applications of Unsupervised Learning
Unsupervised learning is used in a variety of applications across various industries:
| Application | Description |
|---|---|
| Clustering | Group similar data points into clusters to identify patterns and segments. |
| Anomaly Detection | Identify outliers or anomalies in data that deviate from the norm. |
| Dimensionality Reduction | Reduce the dimensionality of data while preserving its essential information. |
| Recommendation Systems | Suggest products, movies, or content to users based on their historical behavior or preferences. |
| Topic Modeling | Discover latent topics within a collection of documents. |
| Density Estimation | Estimate the probability density function of data. |
| Image and Video Compression | Reduce the amount of storage required for multimedia content. |
| Data Preprocessing | Help with data preprocessing tasks such as data cleaning, imputation of missing values, and data scaling. |
| Market Basket Analysis | Discover associations between products that are frequently purchased together. |
| Genomic Data Analysis | Identify patterns or group genes with similar expression profiles. |
| Image Segmentation | Segment images into meaningful regions. |
| Community Detection in Social Networks | Identify communities or groups of individuals with similar interests or connections. |
| Customer Behavior Analysis | Uncover patterns and insights for better marketing and product recommendations. |
| Content Recommendation | Classify and tag content to make it easier to recommend similar items to users. |
| Exploratory Data Analysis (EDA) | Explore data and gain insights before defining specific tasks. |
3.7. Real-World Examples of Unsupervised Learning
To further illustrate the power of unsupervised learning, here are a few real-world examples:
- Customer Segmentation: Businesses use unsupervised learning to segment their customers into different groups based on their purchasing behavior, demographics, or other characteristics. This allows them to tailor their marketing efforts and product offerings to better meet the needs of each segment.
- Anomaly Detection: Unsupervised learning is used to detect anomalies or outliers in data, such as fraudulent transactions, network intrusions, or equipment failures. By identifying patterns that deviate from the norm, businesses can take proactive steps to prevent problems and minimize losses.
- Recommendation Systems: Unsupervised learning is used to build recommendation systems that suggest products, movies, or content to users based on their historical behavior or preferences. By analyzing user data and identifying patterns, these systems can provide personalized recommendations that increase engagement and sales.
- Topic Modeling: News organizations and research firms use unsupervised learning to discover latent topics within large collections of documents. By analyzing the words and phrases that appear together in these documents, algorithms can identify the key themes and topics that are being discussed.
- Image Compression: Unsupervised learning is used to compress images and videos by reducing the amount of storage required for multimedia content. By identifying patterns and redundancies in the data, algorithms can compress the data without significantly affecting its quality.
These examples demonstrate the versatility and impact of unsupervised learning in various domains, highlighting its ability to uncover hidden patterns and insights from unlabeled data.
LEARNS.EDU.VN offers a variety of courses and resources on unsupervised learning, providing you with the knowledge and skills you need to implement these powerful algorithms in your own projects.
4. Reinforcement Learning: Learning Through Interaction
Reinforcement learning (RL) is a machine learning algorithm that interacts with the environment by producing actions and discovering errors. Trial, error, and delay are the most relevant characteristics of reinforcement learning. In this technique, the model keeps on increasing its performance using Reward Feedback to learn the behavior or pattern. These algorithms are specific to a particular problem e.g. Google Self Driving car, AlphaGo where a bot competes with humans and even itself to get better and better performers in Go Game. Each time we feed in data, they learn and add the data to their knowledge which is training data. So, the more it learns the better it gets trained and hence experienced.
4.1. What is Reinforcement Learning?
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives rewards or penalties for its actions, and it learns to maximize its cumulative reward over time. This process is similar to how humans learn by trial and error. The agent explores different actions and learns which actions lead to the best outcomes.
For example, in a game like chess, a reinforcement learning agent would learn to play by making different moves and receiving feedback based on the outcome of the game. If the agent wins, it receives a positive reward. If it loses, it receives a negative reward. Over time, the agent learns to make moves that maximize its chances of winning.
4.2. Key Components of Reinforcement Learning
To effectively implement reinforcement learning, it’s important to understand its key components:
- Agent: The learner that makes decisions and interacts with the environment.
- Environment: The world in which the agent operates and interacts.
- State: The current situation or context in the environment that the agent perceives.
- Action: The decision or move made by the agent in a given state.
- Reward: The feedback received by the agent after taking an action, indicating the desirability of that action.
- Policy: The strategy used by the agent to select actions based on the current state.
- Value Function: A function that estimates the expected cumulative reward that the agent will receive starting from a given state.
.png)
4.3. Types of Reinforcement Learning
There are two main types of reinforcement learning:
- Positive Reinforcement: Rewards the agent for taking a desired action, encouraging the agent to repeat the behavior.
- Negative Reinforcement: Removes an undesirable stimulus to encourage a desired behavior, discouraging the agent from repeating the behavior.
4.3.1. Positive Reinforcement
Positive reinforcement involves giving the agent a reward when it performs a desired action. This encourages the agent to repeat the behavior in the future.
Examples of Positive Reinforcement:
- Giving a treat to a dog for sitting.
- Providing a point in a game for a correct answer.
- Giving a bonus to an employee for achieving a sales target.
4.3.2. Negative Reinforcement
Negative reinforcement involves removing an undesirable stimulus when the agent performs a desired action. This also encourages the agent to repeat the behavior in the future.
Examples of Negative Reinforcement:
- Turning off a loud buzzer when a lever is pressed.
- Avoiding a penalty by completing a task.
- Removing a restriction when a student completes their homework.
4.4. Advantages of Reinforcement Learning
Reinforcement learning offers several advantages:
- Autonomous Decision-Making: It has autonomous decision-making that is well-suited for tasks and that can learn to make a sequence of decisions, like robotics and game-playing.
- Long-Term Results: This technique is preferred to achieve long-term results that are very difficult to achieve with other methods.
- Complex Problem Solving: It is used to solve complex problems that cannot be solved by conventional techniques.
- Adaptability: RL agents can adapt to changing environments and learn to optimize their behavior over time.
4.5. Disadvantages of Reinforcement Learning
Despite its advantages, reinforcement learning also has some limitations:
- Computational Expense: Training Reinforcement Learning agents can be computationally expensive and time-consuming.
- Complexity: Reinforcement learning is not preferable to solving simple problems.
- Data and Computation Requirements: It needs a lot of data and a lot of computation, which makes it impractical and costly in some cases.
- Reward Function Design: Designing an appropriate reward function can be challenging and may require domain expertise.
4.6. Applications of Reinforcement Learning
Reinforcement learning is used in a variety of applications across various industries:
| Application | Description |
|---|---|
| Game Playing | RL can teach agents to play games, even complex ones like chess and Go. |
| Robotics | RL can teach robots to perform tasks autonomously, such as grasping objects and navigating environments. |
| Autonomous Vehicles | RL can help self-driving cars navigate and make decisions in real-time traffic conditions. |
| Recommendation Systems | RL can enhance recommendation algorithms by learning user preferences and optimizing recommendations over time. |
| Healthcare | RL can be used to optimize treatment plans and drug discovery processes. |
| Natural Language Processing (NLP) | RL can be used in dialogue systems and chatbots to improve their ability to engage in natural conversations. |
| Finance and Trading | RL can be used for algorithmic trading and portfolio optimization. |
| Supply Chain and Inventory Management | RL can be used to optimize supply chain operations and inventory levels. |
| Energy Management | RL can be used to optimize energy consumption in buildings and smart grids. |
| Game AI | RL can be used to create more intelligent and adaptive non-player characters (NPCs) in video games. |
| Adaptive Personal Assistants | RL can be used to improve the performance of personal assistants and make them more responsive to user needs. |
| Virtual Reality (VR) and Augmented Reality (AR) | RL can be used to create immersive and interactive experiences in VR and AR environments. |
4.7. Real-World Examples of Reinforcement Learning
To further illustrate the power of reinforcement learning, here are a few real-world examples:
- AlphaGo: Developed by DeepMind, AlphaGo is a reinforcement learning agent that defeated the world’s best human players in the game of Go.
- Self-Driving Cars: Companies like Tesla and Waymo use reinforcement learning to train self-driving cars to navigate complex environments and make decisions in real-time.
- Robotics: Reinforcement learning is used to train robots to perform tasks such as assembly, welding, and inspection in manufacturing environments.
- Recommendation Systems: Companies like Netflix and Amazon use reinforcement learning to optimize their recommendation systems and provide personalized recommendations to users.
These examples demonstrate the versatility and impact of reinforcement learning in various domains, highlighting its ability to solve complex problems and improve decision-making.
learns.edu.vn offers comprehensive courses and resources on reinforcement learning, providing you with the knowledge and skills you need to implement these powerful algorithms in your own projects.
5. Semi-Supervised Learning: Combining Labeled and Unlabeled Data
Semi-Supervised learning is a machine learning algorithm that works between the supervised and unsupervised learning so it uses both labelled and unlabelled data. It’s particularly useful when obtaining labeled data is costly, time-consuming, or resource-intensive. This approach is useful when the dataset is expensive and time-consuming. Semi-supervised learning is chosen when labeled data requires skills and relevant resources in order to train or learn from it.
5.1. What is Semi-Supervised Learning?
Semi-supervised learning is a machine learning approach that combines labeled and unlabeled data to train a model. This technique is particularly useful when labeled data is scarce or expensive to obtain, as it leverages the abundance of unlabeled data to improve the model’s performance. By using both types of data, semi-supervised learning can achieve better results than either supervised or unsupervised learning alone.
For example, consider a medical image analysis task where you have a limited number of labeled images (e.g., images with tumors identified) but a large collection of unlabeled images. Semi-supervised learning can use the labeled images to guide the learning process while also leveraging the unlabeled images to discover additional patterns and improve the model’s generalization ability.
5.2. Key Components of Semi-Supervised Learning
To effectively implement semi-supervised learning, it’s important to understand its key components:
- Labeled Data: A small set of data points with corresponding labels.
- Unlabeled Data: A large set of data points without labels.
- Algorithm: The specific learning algorithm used to combine labeled and unlabeled data, such as label propagation or self-training.
- Model: The output of the training process, representing the learned relationships between inputs and outputs.
- Evaluation Metrics: Metrics used to assess the quality and accuracy of the model’s predictions.
5.3. Types of Semi-Supervised Learning Methods
There are a number of different semi-supervised learning methods each with its own characteristics. Some of the most common ones include:
- Graph-Based Semi-Supervised Learning: This approach uses a graph to represent the relationships between the data points. The graph is then used to propagate labels from the labeled data points to the unlabeled data points.
- Label Propagation: This approach iteratively propagates labels from the labeled data points to the unlabeled data points, based on the similarities between the data points.
- Co-Training: This approach trains two different machine learning models on different subsets of the unlabeled data. The two models are then used to label each other’s predictions.
- Self-Training: This approach trains a machine learning model on the labeled data and then uses the model to predict labels for the unlabeled data. The model is then retrained on the labeled data and the predicted labels for the unlabeled data.
- Generative Adversarial Networks (GANs): GANs are a type of deep learning algorithm that can be used to generate synthetic data. GANs can be used to generate unlabeled data for semi-supervised learning by training two neural networks, a generator and a discriminator.
5.4. Advantages of Semi-Supervised Learning
Semi-supervised learning offers several advantages:
- Improved Generalization: It leads to better generalization as compared to supervised learning, as it leverages both labeled and unlabeled data.
- Data Efficiency: It can achieve high accuracy with limited labeled data, reducing the cost and effort of data labeling.
- Versatility: Can be applied to a wide range of data types and applications.
- Enhanced Performance: By leveraging unlabeled data, it can improve the performance of machine learning models compared to supervised learning alone.
5.5. Disadvantages of Semi-Supervised Learning
Despite its advantages, semi-supervised learning also has some limitations:
- Complexity: Semi-supervised methods can be more complex to implement compared to other approaches.
- Labeled Data Requirement: It still requires some labeled data that might not always be available or easy to obtain.
- Data Sensitivity: The unlabeled data can impact the model performance accordingly, potentially introducing bias or noise.
- Algorithm Selection: Choosing the right semi-supervised learning algorithm can be challenging and may require experimentation.
5.6. Applications of Semi-Supervised Learning
Semi-supervised learning is used in a variety of applications across various industries:
| Application | Description |
|---|---|
| Image Classification and Object Recognition | Improve the accuracy of models by combining a small set of labeled images with a larger set of unlabeled images. |
| Natural Language Processing (NLP) | Enhance the performance of language models and classifiers by combining a small set of labeled text data with a vast amount of unlabeled text. |
| Speech Recognition | Improve the accuracy of speech recognition by leveraging a limited amount of transcribed speech data and a more extensive set of unlabeled audio. |
| Recommendation Systems | Improve the accuracy of personalized recommendations by supplementing a sparse set of user-item interactions (labeled data) with a wealth of unlabeled user behavior data. |
| Healthcare and Medical Imaging | Enhance medical image analysis by utilizing a small set of labeled medical images alongside a larger set of unlabeled images. |
| Document Classification | Classify documents using a mix of labeled and unlabeled examples to improve accuracy and reduce the need for extensive manual labeling. |
| Fraud Detection | Enhance fraud detection systems by leveraging a small set of labeled fraudulent transactions alongside a larger set of unlabeled transactions. |
5.7. Real-World Examples of Semi-Supervised Learning
To further illustrate the power of semi-supervised learning, here are a few real-world examples:
- Web Page Classification: Search engines use semi-supervised learning to classify web pages using a combination of labeled and unlabeled data. The labeled data consists of a small set of web pages that have been manually classified into different categories. The unlabeled data consists of a vast amount