Transformers in machine learning are neural networks that learn context and meaning by tracking relationships in sequential data. At LEARNS.EDU.VN, we unravel the complexities of transformer models, providing you with a clear understanding of their architecture, applications, and impact on the field of artificial intelligence. Explore how these models are revolutionizing natural language processing and beyond, and discover how you can leverage them for your own projects through transformer networks and self-attention mechanisms.
1. What Is a Transformer Model in Machine Learning?
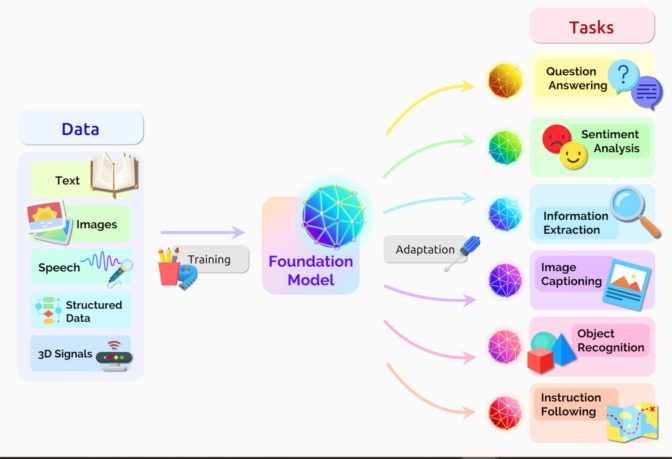
A transformer model in machine learning is a type of neural network architecture that excels at processing sequential data by understanding context and relationships between elements in the sequence. Unlike recurrent neural networks (RNNs) that process data sequentially, transformers use a mechanism called “attention” (or self-attention) to weigh the importance of different parts of the input data. This allows them to capture long-range dependencies more effectively and process data in parallel, leading to significant performance improvements, especially in tasks like natural language processing.
- Key Features:
- Attention Mechanism: Focuses on relevant parts of the input sequence.
- Parallel Processing: Processes data elements simultaneously.
- Contextual Understanding: Captures long-range dependencies.
1.1 The Essence of Transformer Models: Understanding Context and Meaning
Transformer models operate on the principle of understanding context and meaning within sequential data. This is achieved by tracking relationships between different elements, such as words in a sentence. The model discerns how these elements influence each other, enabling it to grasp the overall meaning. According to a 2017 paper from Google, transformer models represent one of the most powerful classes of models invented, driving advancements in machine learning and giving rise to what some call transformer AI.
1.2 The Role of Attention Mechanisms in Transformers
Attention mechanisms are central to the functionality of transformer models. These mechanisms employ mathematical techniques that evolve to detect subtle ways distant data elements influence and depend on one another. This is especially critical in understanding complex relationships within data, such as the dependencies between words in a sentence, or the relationships between different data points in a time series.
1.3 Transformers as Foundation Models: A Paradigm Shift in AI
Stanford researchers have identified transformers as “foundation models,” highlighting their role in driving a paradigm shift in AI. Their August 2021 paper emphasizes the transformative impact of these models, noting that their scale and scope have expanded the boundaries of what is possible in AI. This shift has been enabled by the ability of transformers to handle large datasets and complex relationships, making them a cornerstone of modern AI development.
2. What Can Transformer Models Do?
Transformer models possess a wide array of capabilities, revolutionizing various fields by enabling more accurate and efficient data processing. These models excel in tasks that require understanding context, relationships, and dependencies within sequential data.
- Key Applications:
- Natural Language Processing (NLP): Translation, text generation, sentiment analysis.
- Computer Vision: Image recognition, object detection.
- Time Series Analysis: Predicting future values based on past data.
- Drug Discovery: Analyzing genetic and protein sequences.
2.1 Revolutionizing Natural Language Processing with Transformers
Transformers have significantly advanced the field of natural language processing (NLP) by enabling near real-time text and speech translation. This has had a profound impact on accessibility, making meetings and classrooms more inclusive for diverse and hearing-impaired attendees. By understanding the nuances of language, transformers facilitate clearer and more accurate communication across different languages and contexts.
2.2 Enhancing Scientific Research: Transformers in Genomics and Proteomics
In scientific research, transformers are instrumental in understanding complex biological sequences, such as genes in DNA and amino acids in proteins. This understanding accelerates drug design by predicting how different molecules will interact, thus reducing the time and resources needed to develop new treatments. AstraZeneca and NVIDIA, for example, developed MegaMolBART, a transformer tailored for drug discovery.
2.3 Detecting Anomalies and Trends: The Versatility of Transformers
Transformers are capable of detecting trends and anomalies in data, which is crucial for preventing fraud, streamlining manufacturing processes, and improving healthcare outcomes. These models can analyze large datasets to identify unusual patterns, enabling proactive interventions and more efficient operations. People use transformers every time they search on Google or Microsoft Bing.
3. How Do Transformers Work?
Transformer models use a unique architecture that differs significantly from traditional sequential models like RNNs. The core innovation is the “attention mechanism,” which allows the model to focus on different parts of the input data when processing it.
- Key Components:
- Input Embedding: Converts input data into numerical vectors.
- Positional Encoding: Adds information about the position of each element in the sequence.
- Attention Mechanism: Weighs the importance of different parts of the input.
- Encoder and Decoder: Processes the input and generates the output.
- Feed Forward Network: Applies non-linear transformations to the data.
3.1 The Architecture of Transformer Models: Encoder and Decoder Blocks
Transformer models consist of encoder and decoder blocks, which process data in distinct ways. The encoder processes the input sequence to create a representation of the data, while the decoder uses this representation to generate the output sequence. Small but strategic additions to these blocks make transformers uniquely powerful.
3.2 The Power of Self-Attention: Finding Meaning in Relationships
Self-attention is a mechanism that allows the model to understand the relationships between different parts of the input sequence. For example, in the sentence: “She poured water from the pitcher to the cup until it was full,” the model can determine that “it” refers to the cup. Similarly, in the sentence: “She poured water from the pitcher to the cup until it was empty,” the model understands that “it” refers to the pitcher.
3.3 Positional Encoding: Preserving Order in Parallel Processing
Since transformers process data in parallel, they need a way to preserve the order of the input sequence. Positional encoding is used to add information about the position of each element in the sequence, ensuring that the model can understand the relationships between elements based on their order. Transformers use positional encoders to tag data elements coming in and out of the network.
4. Why Are Transformers Important?
Transformers have become essential in machine learning due to their superior performance, ability to handle large datasets, and versatility across various applications. Their ability to capture long-range dependencies and process data in parallel makes them ideal for complex tasks.
- Key Advantages:
- Superior Performance: Outperforms traditional models in many tasks.
- Parallel Processing: Enables faster training and inference.
- Long-Range Dependencies: Captures relationships between distant elements in the sequence.
- Versatility: Applicable to various types of data and tasks.
4.1 Replacing CNNs and RNNs: The Dominance of Transformers
Transformers are increasingly replacing convolutional neural networks (CNNs) and recurrent neural networks (RNNs) in many applications. A study of arXiv papers on AI revealed that 70% of papers posted in the last two years mention transformers, indicating a significant shift away from traditional models.
4.2 Eliminating the Need for Labeled Data: Self-Supervised Learning
One of the key advantages of transformers is their ability to learn from unlabeled data. Before transformers, users had to train neural networks with large, labeled datasets that were costly and time-consuming to produce. By finding patterns between elements mathematically, transformers eliminate that need, making available the trillions of images and petabytes of text data on the web and in corporate databases.
4.3 Dominating Performance Leaderboards: The Rise of Transformer AI
Transformers now dominate popular performance leaderboards like SuperGLUE, a benchmark for language-processing systems. This dominance underscores their effectiveness and efficiency in handling complex language-related tasks, making them a go-to choice for researchers and practitioners alike.
5. The Virtuous Cycle of Transformer AI
The use of transformer models creates a “virtuous cycle,” where the accuracy of predictions leads to wider adoption, generating more data that can be used to create even better models. This cycle drives continuous improvement and expands the capabilities of transformer AI.
- Key Components:
- Large Datasets: Trained on massive amounts of data.
- Accurate Predictions: Provides high-quality results.
- Wider Use: Drives adoption across various applications.
- Continuous Improvement: Generates more data for better models.
5.1 Enabling Self-Supervised Learning: A Leap in AI Development
Transformers have made self-supervised learning possible, leading to a significant leap in AI development. NVIDIA founder and CEO Jensen Huang noted that transformers have enabled AI to jump to warp speed. This is because transformers can learn from unlabeled data, which is far more abundant than labeled data, allowing for more comprehensive and efficient training.
5.2 Applications Across Sequential Data: Text, Image, and Video
Any application using sequential text, image, or video data is a candidate for transformer models. This versatility makes transformers applicable to a wide range of tasks, from natural language processing and computer vision to time series analysis and bioinformatics.
5.3 A Virtuous Cycle of Improvement: Data-Driven Advancement
The virtuous cycle of transformer AI is driven by the continuous feedback loop of data generation and model improvement. As transformers are used more widely, they generate more data, which can then be used to train even better models. This cycle ensures that transformer AI continues to advance, becoming more accurate and efficient over time.
6. Key Concepts in Transformer Models
Understanding transformer models requires familiarity with several key concepts. These concepts form the foundation of how transformers process data and achieve their remarkable performance.
- Key Concepts:
- Attention: Weighs the importance of different parts of the input.
- Self-Attention: Focuses on relationships within the input sequence.
- Positional Encoding: Preserves order in parallel processing.
- Encoder-Decoder Architecture: Processes input and generates output.
- Multi-Head Attention: Performs attention calculations in parallel.
6.1 Attention and Self-Attention: The Core of Transformer Functionality
Attention is a mechanism that allows the model to focus on relevant parts of the input sequence. Self-attention, a specific type of attention, focuses on the relationships within the input sequence, enabling the model to understand how different parts of the sequence relate to each other.
6.2 Multi-Headed Attention: Parallel Processing for Enhanced Understanding
Attention queries are typically executed in parallel by calculating a matrix of equations in what’s called multi-headed attention. With these tools, computers can see the same patterns humans see.
6.3 Positional Encoders: Tagging Data Elements for Context
Transformers use positional encoders to tag data elements coming in and out of the network. Attention units follow these tags, calculating a kind of algebraic map of how each element relates to the others.
7. The History of Transformers
The development of transformer models has been a journey of innovation, driven by the need for more efficient and accurate processing of sequential data. Understanding this history provides context for the current state of transformer AI.
- Key Milestones:
- 2017: Google publishes the seminal paper on transformers.
- 2018: Google introduces BERT, setting new records in NLP.
- 2020: OpenAI releases GPT-3, a massive transformer model.
- Present: Continued development of larger and more efficient transformers.
7.1 The Birth of Transformers: Google’s Seminal Paper in 2017
The journey of transformer models began with a 2017 paper from Google, which described their transformer and the accuracy records it set for machine translation. Thanks to a basket of techniques, they trained their model in just 3.5 days on eight NVIDIA GPUs, a small fraction of the time and cost of training prior models. They trained it on datasets with up to a billion pairs of words.
7.2 BERT: Revolutionizing Search Algorithms
A year later, another Google team tried processing text sequences both forward and backward with a transformer. That helped capture more relationships among words, improving the model’s ability to understand the meaning of a sentence. Their Bidirectional Encoder Representations from Transformers (BERT) model set 11 new records and became part of the algorithm behind Google search.
7.3 Global Adaptation: Transformers Across Languages and Industries
Within weeks, researchers around the world were adapting BERT for use cases across many languages and industries “because text is one of the most common data types companies have,” said Anders Arpteg, a 20-year veteran of machine learning research.
8. Putting Transformers to Work: Real-World Applications
Transformer models are being applied in various industries, transforming how businesses operate and solve complex problems. Their ability to process and understand data efficiently makes them invaluable in numerous applications.
- Key Industries:
- Healthcare: Drug discovery, medical research.
- Finance: Fraud detection, risk management.
- Manufacturing: Streamlining processes, quality control.
- Technology: Search engines, chatbots.
8.1 Transformers in Healthcare: Drug Discovery and Medical Research
Soon transformer models were being adapted for science and healthcare. DeepMind, in London, advanced the understanding of proteins, the building blocks of life, using a transformer called AlphaFold2, described in a recent Nature article. It processed amino acid chains like text strings to set a new watermark for describing how proteins fold, work that could speed drug discovery.
8.2 Reading Molecules: The AstraZeneca and NVIDIA Collaboration
AstraZeneca and NVIDIA developed MegaMolBART, a transformer tailored for drug discovery. It’s a version of the pharmaceutical company’s MolBART transformer, trained on a large, unlabeled database of chemical compounds using the NVIDIA Megatron framework for building large-scale transformer models.
8.3 Extracting Insights from Medical Records: The University of Florida’s GatorTron
Separately, the University of Florida’s academic health center collaborated with NVIDIA researchers to create GatorTron. The transformer model aims to extract insights from massive volumes of clinical data to accelerate medical research.
9. The Growth of Transformers: Bigger and Better Models
Transformer models have grown significantly in size and complexity over the years. Researchers have found that larger transformers generally perform better, leading to the development of models with trillions of parameters.
- Key Trends:
- Increasing Model Size: Models with billions or trillions of parameters.
- Improved Performance: Enhanced accuracy and efficiency.
- New Architectures: Innovations like Mixture-of-Experts (MoE).
9.1 The Rostlab’s Pioneering Work: AI and Biology
Researchers from the Rostlab at the Technical University of Munich, which helped pioneer work at the intersection of AI and biology, used natural-language processing to understand proteins. In 18 months, they graduated from using RNNs with 90 million parameters to transformer models with 567 million parameters.
9.2 GPT-3: Responding to Queries Without Specific Training
The OpenAI lab showed bigger is better with its Generative Pretrained Transformer (GPT). The latest version, GPT-3, has 175 billion parameters, up from 1.5 billion for GPT-2. With the extra heft, GPT-3 can respond to a user’s query even on tasks it was not specifically trained to handle. It’s already being used by companies including Cisco, IBM and Salesforce.
9.3 MT-NLG: The Megatron-Turing Natural Language Generation Model
NVIDIA and Microsoft hit a high watermark in November, announcing the Megatron-Turing Natural Language Generation model (MT-NLG) with 530 billion parameters. It debuted along with a new framework, NVIDIA NeMo Megatron, that aims to let any business create its own billion- or trillion-parameter transformers to power custom chatbots, personal assistants and other AI applications that understand language.
10. Challenges and Future Directions
Despite their many advantages, transformer models face several challenges. Researchers are actively working to address these challenges and explore new directions for transformer AI.
- Key Challenges:
- Computational Cost: Training large models is expensive.
- Bias and Toxicity: Models may amplify harmful language.
- Interpretability: Understanding how models make decisions.
10.1 Training Large Transformer Models: Overcoming Computational Costs
Training large transformer models is expensive and time-consuming, requiring significant computational resources. To provide the computing muscle those models need, our latest accelerator — the NVIDIA H100 Tensor Core GPU — packs a Transformer Engine and supports a new FP8 format. That speeds training while preserving accuracy. With those and other advances, “transformer model training can be reduced from weeks to days” said Huang at GTC.
10.2 Addressing Bias and Toxicity: Creating Safe and Responsible Models
Other researchers are studying ways to eliminate bias or toxicity if models amplify wrong or harmful language. For example, Stanford created the Center for Research on Foundation Models to explore these issues.
10.3 Developing Simpler Transformers: Retrieval-Based Models
Now some researchers aim to develop simpler transformers with fewer parameters that deliver performance similar to the largest models. I see promise in retrieval-based models that I’m super excited about because they could bend the curve,” said Gomez, of Cohere, noting the Retro model from DeepMind as an example. Retrieval-based models learn by submitting queries to a database. “It’s cool because you can be choosy about what you put in that knowledge base,” he said.
11. The Future of Transformers
The future of transformer models looks promising, with ongoing research and development aimed at creating more efficient, accurate, and responsible AI systems. These advancements are expected to further expand the capabilities and applications of transformer AI.
- Key Trends:
- More Efficient Models: Simpler architectures and training methods.
- Responsible AI: Addressing bias and toxicity.
- General AI: Approaching human-level intelligence.
11.1 The Goal of General AI: Learning from Context
The ultimate goal is to “make these models learn like humans do from context in the real world with very little data,” said Vaswani, now co-founder of a stealth AI startup. He imagines future models that do more computation upfront so they need less data and sport better ways users can give them feedback.
11.2 Addressing Societal Concerns: Safe and Responsible AI Deployment
“These are important problems that need to be solved for safe deployment of models,” said Shrimai Prabhumoye, a research scientist at NVIDIA who’s among many across the industry working in the area. No one is going to use these models if they hurt people, so it’s table stakes to make the safest and most responsible models.”
11.3 Transformer Training and Inference Acceleration: The NVIDIA H100 GPU
Transformer training and inference will get significantly accelerated with the NVIDIA H100 GPU.
12. FAQs About Transformers in Machine Learning
Q1: What Are Transformers In Machine Learning?
Transformers are a type of neural network architecture that excels at processing sequential data by understanding context and relationships between elements in the sequence.
Q2: How do transformers differ from RNNs?
Unlike recurrent neural networks (RNNs) that process data sequentially, transformers use an attention mechanism to weigh the importance of different parts of the input data, allowing them to capture long-range dependencies more effectively.
Q3: What is the attention mechanism in transformers?
The attention mechanism allows the model to focus on relevant parts of the input sequence by weighing the importance of different elements, enabling it to capture long-range dependencies.
Q4: What is self-attention?
Self-attention is a specific type of attention that focuses on the relationships within the input sequence, allowing the model to understand how different parts of the sequence relate to each other.
Q5: What is positional encoding, and why is it important?
Positional encoding adds information about the position of each element in the sequence, preserving order in parallel processing, which is crucial since transformers process data simultaneously.
Q6: What are some applications of transformer models?
Transformer models are used in various applications, including natural language processing (NLP), computer vision, time series analysis, and drug discovery.
Q7: What is BERT, and how did it impact the field?
BERT (Bidirectional Encoder Representations from Transformers) is a transformer model developed by Google that set new records in NLP and became part of the algorithm behind Google search, revolutionizing how search engines understand and process language.
Q8: What are the challenges of training large transformer models?
Training large transformer models is computationally expensive and time-consuming, requiring significant resources and specialized hardware.
Q9: How are researchers addressing the challenges of bias and toxicity in transformer models?
Researchers are studying ways to eliminate bias and toxicity by developing methods to detect and mitigate harmful language amplified by these models.
Q10: What is the future of transformer models in AI?
The future of transformer models involves developing more efficient, accurate, and responsible AI systems, with ongoing research focused on addressing challenges and exploring new directions for transformer AI.
Ready to dive deeper into the world of transformers? Visit LEARNS.EDU.VN today to explore our comprehensive articles, courses, and resources designed to help you master this transformative technology. Whether you’re a student, researcher, or industry professional, learns.edu.vn provides the expertise and guidance you need to succeed. Contact us at 123 Education Way, Learnville, CA 90210, United States, or reach out via WhatsApp at +1 555-555-1212.
