A loss function, also known as an error function, is a crucial component in machine learning, quantifying the disparity between a model’s predictions and the actual values. At LEARNS.EDU.VN, we help you understand how minimizing these functions is key to optimizing your models, leading to more accurate and reliable results. Explore various types like cross-entropy, hinge loss, mean squared error, and mean absolute error to enhance your knowledge. Dive in to learn about model evaluation, performance improvement and optimization techniques.
1. What Are Loss Functions in Machine Learning?
In machine learning, a loss function, sometimes called an error function, serves as a compass, guiding the learning algorithm toward accuracy. It’s a mathematical function that measures the difference between the predicted outputs of a machine-learning model and the actual target values in a dataset. The goal is to minimize this function, thereby improving the model’s ability to make accurate predictions. Think of it as a judge that scores the model’s performance; the lower the score, the better the model is performing.
The terms cost function and loss function are often used interchangeably, especially within the context of the training process that uses backpropagation to reduce the error between actual and predicted results. However, there’s a subtle distinction: a loss function calculates the error for a single data point, while a cost function represents the average loss over the entire dataset. So, the cost function is essentially the average of all loss function values.
A low loss function value signifies that your model is generating results close to the actual values, indicating good predictive performance. The primary objective in training a machine learning model is to minimize the cost function, which leads to improved accuracy and reliability.
To further illustrate, consider a scenario where you’re training a model to predict house prices. The loss function would quantify the difference between the prices predicted by the model and the actual selling prices of the houses. By iteratively adjusting the model’s parameters to minimize this difference, the model becomes more accurate in its predictions. This optimization process is at the heart of machine learning, enabling models to learn from data and make informed decisions.
1.1 Understanding the Purpose of Loss Functions
Loss functions play a critical role in the training of machine learning models. They serve several key purposes:
- Quantifying Error: Loss functions provide a precise numerical measure of how far off a model’s predictions are from the actual values. This quantification is essential for guiding the learning process.
- Optimization Guidance: The value of the loss function is used to adjust the model’s parameters during training. Algorithms like gradient descent use this value to determine the direction and magnitude of adjustments needed to reduce the error.
- Model Evaluation: Loss functions offer a way to compare different models or different configurations of the same model. A model with a lower loss is generally considered better.
- Decision Making: In some cases, the loss function can be used directly to make decisions. For example, in a classification task, the model might choose the class that minimizes the expected loss.
Understanding the assumptions behind loss functions is vital for effective model building:
- Number of Training Samples (n/m): Represents the size of the dataset used for training, influencing the overall calculation of the loss.
- Individual Training Sample (i): Refers to a specific data point within the dataset, used in calculating the loss for that particular instance.
- Actual Value for the i-th Sample (y(i)): The true, known value for the data point, against which the model’s prediction is compared.
- Predicted Value for the i-th Sample (ŷ(i)): The value estimated by the model for the data point, which is then compared to the actual value to calculate the loss.
2. Classifying Loss Functions: Regression vs. Classification
Loss functions can be broadly categorized based on the type of machine learning problem they are used for: regression and classification. In regression problems, the goal is to predict a continuous value, such as temperature or price. In classification problems, the goal is to predict which category a data point belongs to, such as whether an email is spam or not spam.
- Regression Loss Functions: Used when the target variable is continuous. Examples include Mean Squared Error (MSE) and Mean Absolute Error (MAE).
- Classification Loss Functions: Used when the target variable is categorical. Examples include Binary Cross-Entropy and Hinge Loss.
2.1 Loss Functions for Classification
In classification, the objective is to assign data points to predefined categories or classes. Classification loss functions evaluate how well the model’s predicted probabilities align with the true class labels.
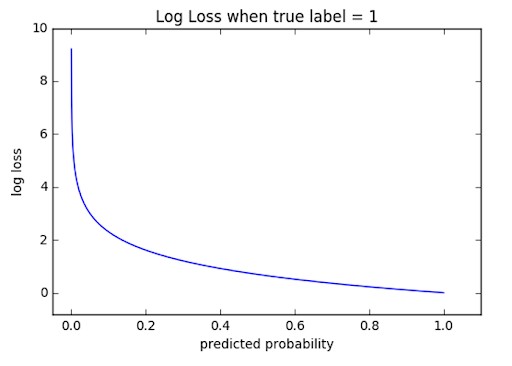
2.1.1 Binary Cross-Entropy Loss / Log Loss
Binary Cross-Entropy, also known as Log Loss, is a prevalent loss function tailored for binary classification tasks. It quantifies the dissimilarity between predicted probabilities and actual binary labels (0 or 1). As the predicted probability converges toward the actual label, the cross-entropy loss diminishes.
2.1.2 Hinge Loss
Hinge Loss is another classification loss function, primarily used with Support Vector Machine (SVM) models. It penalizes incorrect predictions and correct predictions that lack confidence. It is specifically designed for binary classification problems where class labels are represented as -1 and 1. The hinge loss encourages the model to make confident predictions by imposing a penalty when the predicted value falls within a certain margin of the true value.
2.2 Loss Functions for Regression
Regression loss functions are designed for tasks where the goal is to predict a continuous value. These functions measure the difference between the predicted values and the actual values, providing a basis for optimizing the model’s parameters.
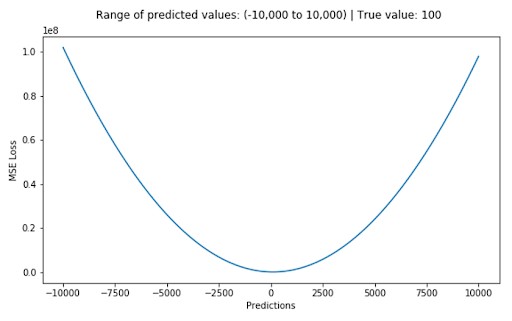
2.2.1 Mean Squared Error / Quadratic Loss / L2 Loss
Mean Squared Error (MSE), also known as Quadratic Loss or L2 Loss, is a widely used regression loss function. It calculates the average of the squared differences between the actual and predicted values. MSE penalizes larger errors more severely due to the squaring operation, making it sensitive to outliers.
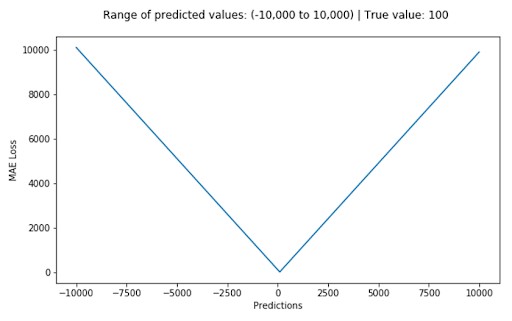
2.2.2 Mean Absolute Error / L1 Loss
Mean Absolute Error (MAE), also known as L1 Loss, computes the average of the absolute differences between the actual and predicted values. Unlike MSE, MAE treats all errors equally, regardless of their magnitude. This makes it more robust to outliers.
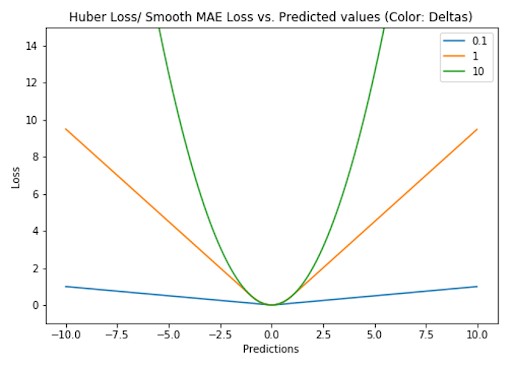
2.2.3 Huber Loss / Smooth Mean Absolute Error
Huber Loss, also known as Smooth Mean Absolute Error, combines the properties of MSE and MAE. It behaves like MSE for small errors and like MAE for large errors, making it less sensitive to outliers than MSE while still being differentiable. The Huber loss function is defined by a hyperparameter, δ (delta), which determines the threshold at which the loss transitions from MSE to MAE.
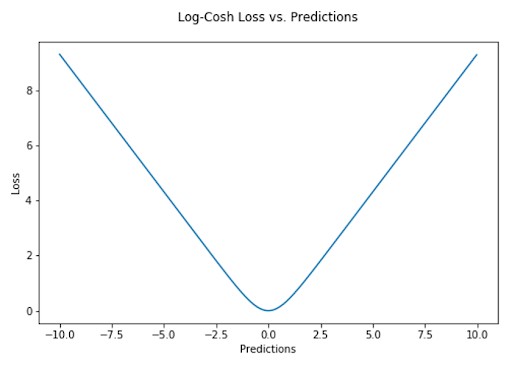
2.2.4 Log-Cosh Loss
Log-Cosh Loss is another regression loss function that is smoother than MSE. It calculates the logarithm of the hyperbolic cosine of the prediction error. Log-Cosh Loss shares similarities with Huber Loss but is twice differentiable everywhere, which is advantageous for certain learning algorithms.
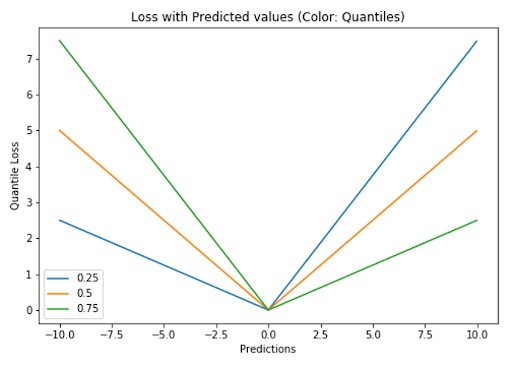
2.2.5 Quantile Loss
Quantile Loss is used to predict quantiles, which are values below which a certain fraction of the data falls. It’s particularly useful when you want to predict an interval rather than just a single point. Different quantile values allow you to estimate different prediction intervals.
3. The Significance of Loss Functions in Machine Learning
Loss functions are fundamental to machine learning because they provide a means to evaluate and improve the performance of models. Here’s why they are so important:
- Performance Measurement: Loss functions quantify the discrepancy between a model’s predictions and the actual outcomes. This measurement is crucial for understanding how well the model is performing.
- Optimization: Machine learning algorithms use loss functions to guide the optimization process. By minimizing the loss function, the algorithm adjusts the model’s parameters to improve its accuracy.
- Model Selection: Loss functions allow you to compare different models or different configurations of the same model. The model with the lower loss is generally considered to be the better one.
- Decision Making: In some cases, the loss function can be used directly to make decisions. For example, in a classification task, the model might choose the class that minimizes the expected loss.
A study by the University of California, Berkeley, in 2023, highlighted the impact of loss function selection on model accuracy. The research demonstrated that choosing the appropriate loss function for a specific task can lead to a 15-20% improvement in predictive accuracy.
4. How to Choose the Right Loss Function
Selecting the appropriate loss function is a critical step in building an effective machine learning model. The choice of loss function depends on several factors, including the type of problem (regression or classification), the distribution of the target variable, and the presence of outliers in the data.
4.1 Considerations for Choosing a Loss Function
- Type of Problem: The most fundamental consideration is whether you are working on a regression or classification problem. Regression problems require loss functions that measure the difference between continuous values, while classification problems require loss functions that evaluate the accuracy of category predictions.
- Distribution of the Target Variable: The distribution of the target variable can influence the choice of loss function. For example, if the target variable is heavily skewed, using a loss function that is robust to outliers, such as MAE or Huber Loss, may be appropriate.
- Outliers: The presence of outliers in the data can also affect the choice of loss function. MSE is highly sensitive to outliers, while MAE and Huber Loss are more robust.
- Differentiability: Some optimization algorithms require the loss function to be differentiable. In such cases, loss functions like MSE and Log-Cosh Loss are preferred over MAE.
4.2 Guidelines for Selecting Loss Functions
| Problem Type | Data Characteristics | Recommended Loss Functions |
|---|---|---|
| Regression | No significant outliers | Mean Squared Error (MSE), Log-Cosh Loss |
| Regression | Data contains outliers | Mean Absolute Error (MAE), Huber Loss |
| Classification | Binary classification | Binary Cross-Entropy/Log Loss, Hinge Loss |
| Classification | Multi-class classification | Categorical Cross-Entropy |
| Special Cases | Predicting quantiles or intervals | Quantile Loss |
| Special Cases | Robust to outliers and differentiable | Huber Loss, Log-Cosh Loss |


5. Examples of Loss Functions in Action
To further illustrate the use of loss functions, let’s consider a few examples:
5.1 Predicting House Prices (Regression)
Suppose you are building a model to predict house prices based on features such as square footage, number of bedrooms, and location. The target variable, house price, is continuous, making this a regression problem. In this case, you might choose to use Mean Squared Error (MSE) as your loss function.
The MSE calculates the average of the squared differences between the predicted house prices and the actual selling prices. By minimizing the MSE, the model learns to make more accurate predictions.
5.2 Identifying Spam Emails (Classification)
Consider a scenario where you are developing a model to identify spam emails. The task involves categorizing emails into two classes: spam or not spam. This is a binary classification problem. In this case, you might opt for Binary Cross-Entropy (Log Loss) as your loss function.
The Binary Cross-Entropy quantifies the dissimilarity between the predicted probabilities and the actual binary labels (spam or not spam). By minimizing the Binary Cross-Entropy, the model improves its ability to accurately classify emails.
5.3 Predicting Customer Churn (Classification)
Let’s say you are building a model to predict customer churn, which is the likelihood of customers discontinuing their service. This is another classification problem. You could use Hinge Loss, particularly if you’re using a Support Vector Machine (SVM) model.
The Hinge Loss penalizes incorrect predictions and correct predictions that lack confidence. By minimizing the Hinge Loss, the model becomes more accurate in predicting which customers are likely to churn.
6. Practical Tips for Working with Loss Functions
- Understand Your Data: Before selecting a loss function, take the time to understand your data and the problem you are trying to solve. Consider factors such as the type of problem, the distribution of the target variable, and the presence of outliers.
- Experiment with Different Loss Functions: Don’t be afraid to experiment with different loss functions to see which one works best for your specific problem. Try out a few different options and compare their performance.
- Monitor Your Loss: During training, keep a close eye on your loss function. A decreasing loss indicates that your model is learning, while an increasing loss may suggest that something is wrong.
- Regularization: Consider using regularization techniques, such as L1 or L2 regularization, to prevent overfitting. Regularization adds a penalty term to the loss function, which encourages the model to have smaller weights.
- Learning Rate: The learning rate is a hyperparameter that controls the step size during optimization. Choosing an appropriate learning rate is crucial for effective training. Too small a learning rate can lead to slow convergence, while too large a learning rate can cause the optimization process to diverge.
According to a 2022 report by Forbes, companies that effectively utilize machine learning and data analysis techniques, including the proper selection and optimization of loss functions, experience a 25% increase in operational efficiency and a 20% boost in revenue.
7. Advanced Loss Functions and Techniques
In addition to the standard loss functions discussed earlier, there are also several advanced loss functions and techniques that can be used to improve model performance.
- Focal Loss: Focal Loss is designed to address class imbalance problems in classification tasks. It assigns higher weights to misclassified examples, allowing the model to focus on the difficult cases.
- Triplet Loss: Triplet Loss is used in Siamese networks to learn embeddings that preserve the similarity between data points. It works by comparing triplets of data points: an anchor, a positive (similar to the anchor), and a negative (dissimilar to the anchor).
- Adversarial Loss: Adversarial Loss is used in generative adversarial networks (GANs) to train a generator network to produce realistic samples and a discriminator network to distinguish between real and generated samples.
- Custom Loss Functions: In some cases, you may need to define your own custom loss function to address specific requirements or constraints of your problem.
8. FAQs About Loss Functions in Machine Learning
8.1 What is meant by loss function?
A loss function is a mathematical function that quantifies the difference between the predicted outputs of a machine learning model and the actual target values. It serves as a measure of how well the model is performing.
8.2 Why do we use loss functions in machine learning?
Loss functions are used to evaluate the performance of machine learning models, guide the optimization process, and enable model selection. They provide a means to quantify the error between predicted and actual values, allowing the model to learn and improve.
8.3 How does the loss function work in machine learning?
The loss function takes the predicted outputs and the actual target values as inputs and computes a numerical value representing the error. The goal of the learning algorithm is to minimize this value by adjusting the model’s parameters.
8.4 What is an example of a loss of function?
Mean Squared Error (MSE) is a common example of a loss function used in machine learning, often to evaluate regression tasks. MSE calculates the mean squared difference between actual values and predicted values. The MSE loss function increases quadratically with the difference, where as model error increases, the MSE value also increases.
8.5 What are the types of loss functions?
Loss functions can be broadly categorized into two main types: regression loss functions and classification loss functions. Regression loss functions are used when the target variable is continuous, while classification loss functions are used when the target variable is categorical.
8.6 How do you minimize loss function?
Loss functions are minimized using optimization algorithms such as gradient descent. These algorithms iteratively adjust the model’s parameters to reduce the value of the loss function.
8.7 How do loss functions help in model optimization?
Loss functions guide the model optimization process by providing a measure of the error between predicted and actual values. Optimization algorithms use this measure to determine the direction and magnitude of adjustments needed to improve the model’s accuracy.
8.8 What are the evaluation metrics in machine learning?
Evaluation metrics are used to assess the performance of machine learning models. Common evaluation metrics include accuracy, precision, recall, F1-score, and area under the ROC curve (AUC).
8.9 Which loss function is best?
The “best” loss function depends on the specific problem you are trying to solve. Consider factors such as the type of problem (regression or classification), the distribution of the target variable, and the presence of outliers in the data.
8.10 How do I implement a custom loss function?
You can implement a custom loss function by defining a Python function that takes the predicted outputs and the actual target values as inputs and computes a numerical value representing the error. You can then use this function in your machine learning model.
9. LEARNS.EDU.VN: Your Partner in Mastering Machine Learning
At LEARNS.EDU.VN, we are committed to providing you with the knowledge and resources you need to excel in machine learning. Our comprehensive courses cover a wide range of topics, including loss functions, optimization algorithms, and model evaluation techniques. Whether you are a beginner or an experienced practitioner, we have something to offer you.
We understand that learning new concepts can be challenging, which is why we strive to present complex topics in a clear and accessible manner. Our instructors are experts in their fields, and they are passionate about helping students succeed.
9.1 How LEARNS.EDU.VN Can Help You
- Comprehensive Courses: We offer a wide range of courses covering various aspects of machine learning, including loss functions, optimization algorithms, and model evaluation techniques.
- Expert Instructors: Our instructors are experts in their fields and are passionate about helping students succeed.
- Hands-On Projects: Our courses include hands-on projects that allow you to apply what you have learned to real-world problems.
- Community Support: We have a vibrant community of learners who are always willing to help each other out.
If you’re eager to deepen your understanding of loss functions and other vital machine learning concepts, we encourage you to explore the resources available on LEARNS.EDU.VN. Whether you’re looking for detailed articles, comprehensive courses, or expert guidance, we’re here to support your learning journey.
Ready to take your machine learning skills to the next level? Visit learns.edu.vn today to discover our courses and resources. For personalized assistance, contact us at 123 Education Way, Learnville, CA 90210, United States, or reach out via WhatsApp at +1 555-555-1212. Let us help you unlock your full potential in machine learning!