Bias in machine learning leads to inaccurate predictions and unfair outcomes, but LEARNS.EDU.VN can help you understand and mitigate it. Discover how to identify and address bias with our comprehensive guide, ensuring your models are accurate, fair, and reliable. Explore advanced techniques and strategies to create ethical and effective AI solutions while mastering machine learning fundamentals, data preprocessing, and model evaluation.
1. Understanding Bias in Machine Learning
What exactly is bias in machine learning, and why is it so critical to address? Bias in machine learning refers to systematic errors that occur in a model due to incorrect assumptions in the machine learning process, leading to inaccurate predictions and unfair outcomes. Let’s explore the depths of this issue, including its sources, types, and the importance of mitigating it.
1.1. Defining Bias in Machine Learning
Bias in machine learning is a systematic error that occurs in a model due to flawed assumptions in the learning algorithm or the training data. According to a study by researchers at Stanford University, algorithms trained on biased data can perpetuate and even amplify existing societal biases, leading to discriminatory outcomes. It’s crucial to understand that bias is not always intentional; it can creep into models subtly through various stages of the machine learning pipeline.
To technically define it:
- Bias is the error between the average model prediction and the ground truth.
- A model with high bias won’t match the dataset closely.
- A low bias model closely matches the training dataset.
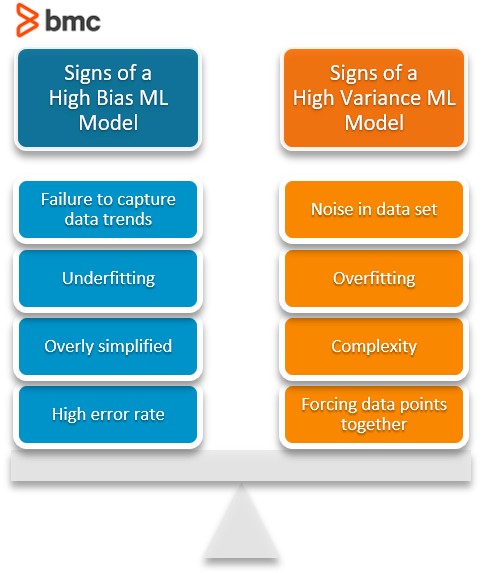
Characteristics of a high bias model include:
- Failure to capture proper data trends.
- Potential toward underfitting.
- More generalized or overly simplified models.
- High error rate.
1.2. Sources of Bias in Machine Learning
Bias can infiltrate machine learning models from various sources, making it a multifaceted challenge. These sources often interact, compounding the problem. Understanding these sources is the first step toward mitigating bias effectively.
| Source of Bias | Description | Example |
|---|---|---|
| Data Collection Bias | Occurs when the data used to train the model does not accurately represent the population it is intended to serve. | Using only data from urban areas to train a model intended to serve both urban and rural populations. |
| Sampling Bias | Arises when certain members of a population are systematically more or less likely to be selected than others. | Conducting a survey only during business hours, excluding individuals who work during those hours. |
| Pre-existing Bias | Societal biases present in the real world are reflected in the data, perpetuating and amplifying them. | Training a hiring algorithm on historical data where certain demographic groups were underrepresented in leadership positions. |
| Measurement Bias | Occurs when the data collected is systematically inaccurate or inconsistent. | Using a faulty sensor that consistently underestimates temperature readings. |
| Algorithmic Bias | Arises from the design and implementation of the machine learning algorithm itself. | An algorithm that penalizes complexity, leading to simpler models that underfit the data and ignore important patterns. |
| Evaluation Bias | Occurs when the evaluation metrics used to assess the model’s performance are not appropriate or do not reflect the real-world impact. | Evaluating a medical diagnostic model solely on accuracy without considering its sensitivity and specificity. |
| Labeling Bias | Arises when labels assigned to the data are biased, reflecting the prejudices or stereotypes of the labelers. | Labeling images for a facial recognition system using predominantly lighter-skinned faces, leading to poorer performance on darker-skinned faces. |
| Exclusion Bias | Occurs when important features or variables are excluded from the model, leading to incomplete or misleading representations. | Building a credit risk model that does not consider factors such as rental history or utility payments, disadvantaging individuals with limited credit history. |
| Interpretation Bias | Arises from the subjective interpretation of the model’s outputs, leading to biased decisions. | Interpreting a risk score generated by a criminal justice algorithm as a definitive measure of guilt rather than a probabilistic assessment. |
| Deployment Bias | Occurs when the model is deployed in a context that differs significantly from the environment in which it was trained, leading to unexpected performance issues. | Deploying a self-driving car model trained in sunny conditions to a region with frequent snowstorms. |
1.3. Types of Bias in Machine Learning
Understanding the different types of bias is essential for identifying and addressing them effectively. Each type manifests differently and requires specific mitigation strategies.
- Selection Bias: Occurs when the data used for training is not representative of the population the model is intended to serve.
- Measurement Bias: Arises from inaccuracies or inconsistencies in the data collection process.
- Algorithmic Bias: Results from the design or assumptions inherent in the machine learning algorithm itself.
1.4. The Importance of Addressing Bias
Addressing bias in machine learning is not just an ethical imperative but also a practical necessity. Biased models can lead to discriminatory outcomes, damage reputations, and undermine trust in AI systems. As Cathy O’Neil explains in her book Weapons of Math Destruction, biased algorithms can perpetuate and amplify inequality, creating feedback loops that disproportionately harm marginalized groups.
Mitigating bias ensures:
- Fairness
- Accuracy
- Reliability
- Ethical AI Development
- Trust
2. Identifying Bias in Machine Learning Models
How can you pinpoint bias in machine learning models before it leads to unfair or inaccurate outcomes? Identifying bias requires a combination of careful data analysis, model evaluation, and awareness of potential pitfalls. Let’s explore the methods and metrics for detecting bias in your models.
2.1. Data Analysis Techniques
The first step in identifying bias is to thoroughly analyze your data. Understanding the characteristics and potential biases in your data can help you anticipate and address issues early in the modeling process.
| Technique | Description | Benefit |
|---|---|---|
| Exploratory Data Analysis (EDA) | Using visual and statistical methods to summarize and understand the dataset’s main characteristics. | Helps uncover patterns, anomalies, and relationships between variables, highlighting potential biases. |
| Demographic Analysis | Examining the distribution of demographic variables (e.g., gender, race, age) within the dataset. | Reveals whether certain groups are over- or underrepresented, indicating selection bias. |
| Missing Value Analysis | Identifying patterns in missing data, which can indicate systematic biases in data collection. | Helps understand whether missing data is random or related to specific attributes, which could introduce bias. |
| Outlier Detection | Detecting and analyzing outliers, which may represent errors, anomalies, or underrepresented groups. | Identifies unusual data points that may skew the model’s performance and disproportionately affect certain groups. |
| Data Visualization | Creating visual representations of the data to identify patterns, trends, and disparities. | Provides a clear and intuitive way to understand the data’s distribution and identify potential biases. |
2.2. Model Evaluation Metrics
Traditional accuracy metrics can be misleading when dealing with biased datasets. It’s essential to use a range of metrics that provide a more nuanced view of the model’s performance across different subgroups.
| Metric | Description | Benefit |
|---|---|---|
| Precision | The proportion of positive identifications that were actually correct. | Measures the accuracy of positive predictions, useful when the cost of false positives is high. |
| Recall | The proportion of actual positives that were correctly identified. | Measures the ability of the model to find all relevant cases, important when the cost of false negatives is high. |
| F1-Score | The harmonic mean of precision and recall, providing a balanced measure of the model’s accuracy. | Offers a single metric that balances precision and recall, useful for comparing models with different trade-offs. |
| False Positive Rate (FPR) | The proportion of negative instances that were incorrectly classified as positive. | Measures the rate at which the model incorrectly flags negative instances as positive, important for identifying disparities in false alarms across groups. |
| False Negative Rate (FNR) | The proportion of positive instances that were incorrectly classified as negative. | Measures the rate at which the model fails to identify positive instances, important for identifying disparities in missed opportunities across groups. |
| Disparate Impact Ratio | Compares the proportion of positive outcomes for different groups. A ratio significantly different from 1 indicates disparate impact. | Quantifies the degree to which a model’s outcomes differ across groups, helping to identify potential discrimination. |
| Equalized Odds | Ensures that the false positive rate and false negative rate are approximately equal across different groups. | Aims to balance the types of errors the model makes across groups, promoting fairness in decision-making. |
| Statistical Parity | Aims to achieve equal representation of positive outcomes across different groups. | Ensures that the model’s predictions do not disproportionately favor or disfavor certain groups, promoting fairness in resource allocation and opportunity. |
| Calibration | Assesses whether the model’s predicted probabilities accurately reflect the true likelihood of the outcome. A well-calibrated model should have predictions that align with the observed frequencies. | Helps ensure that the model’s risk assessments are reliable and trustworthy, reducing the potential for biased decisions based on over- or underconfidence. |
2.3. Visualization Techniques
Visualizing model performance can provide insights into how the model behaves across different subgroups and identify potential biases.
- Confusion Matrices: Visual representation of the model’s classification performance, showing true positives, true negatives, false positives, and false negatives.
- ROC Curves: Plot the true positive rate against the false positive rate at various threshold settings.
- Calibration Curves: Plot the predicted probabilities against the observed frequencies to assess the model’s calibration.
2.4. Bias Auditing Tools
Several tools and libraries can help automate the process of bias detection and mitigation.
- AI Fairness 360: An open-source toolkit developed by IBM that provides a comprehensive set of metrics and algorithms for detecting and mitigating bias.
- Fairlearn: A Python package that provides tools for assessing and improving the fairness of machine learning models.
- What-If Tool: A visual interface developed by Google that allows users to explore the behavior of machine learning models and identify potential biases.
3. Mitigating Bias in Machine Learning
What strategies can you employ to reduce bias and ensure fairness in your machine learning models? Mitigating bias requires a holistic approach that addresses issues at every stage of the machine learning pipeline, from data collection to model deployment. Let’s explore the techniques and best practices for creating fairer and more equitable AI systems.
3.1. Data Preprocessing Techniques
Data preprocessing is a crucial step in mitigating bias. By transforming the data, you can reduce the impact of biased samples and features on the model’s performance.
| Technique | Description | Benefit |
|---|---|---|
| Resampling | Adjusting the class distribution in the training data by oversampling minority classes or undersampling majority classes. | Helps balance the representation of different groups, reducing bias caused by imbalanced datasets. |
| Reweighing | Assigning different weights to different data points based on their group membership and outcome, giving more importance to underrepresented groups or misclassified instances. | Corrects for biases in the training data by giving more influence to instances that are more likely to be misclassified or belong to disadvantaged groups. |
| Feature Engineering | Creating new features or transforming existing ones to reduce the correlation between sensitive attributes (e.g., race, gender) and the outcome. | Minimizes the influence of sensitive attributes on the model’s predictions, reducing the potential for discriminatory outcomes. |
| Data Augmentation | Generating synthetic data points to increase the diversity of the training data, particularly for underrepresented groups. | Expands the training data to include more diverse examples, improving the model’s ability to generalize and reducing bias. |
| Adversarial Debasing | Training a separate model to predict sensitive attributes from the data, and then using the predictions to remove the correlation between sensitive attributes and the outcome. | Removes the influence of sensitive attributes from the data, making it more difficult for the model to discriminate based on protected characteristics. |
| Data Anonymization | Removing or masking sensitive attributes from the data to protect privacy and reduce the risk of discrimination. | Prevents the model from directly using sensitive attributes in its predictions, reducing the potential for bias. |
| Data Smoothing | Applying techniques such as binning or kernel density estimation to smooth out the data and reduce the impact of outliers. | Reduces the influence of individual data points that may disproportionately affect the model’s performance and introduce bias. |
| Causal Intervention | Identifying and intervening on causal pathways that lead to bias, based on causal inference techniques. | Addresses the root causes of bias by disrupting the causal mechanisms that generate unfair outcomes. |
3.2. Algorithmic Bias Mitigation Techniques
In addition to preprocessing the data, you can also modify the machine learning algorithm itself to reduce bias.
- Fairness-Aware Algorithms: Algorithms designed to optimize for both accuracy and fairness, taking into account potential biases in the data.
- Adversarial Training: Training a model to be both accurate and resistant to adversarial attacks that aim to exploit biases.
- Regularization Techniques: Adding penalties to the model’s objective function to discourage the use of biased features.
3.3. Post-Processing Techniques
Post-processing involves adjusting the model’s predictions after training to improve fairness.
- Threshold Adjustment: Modifying the decision threshold for different groups to achieve equalized odds or statistical parity.
- Calibration: Adjusting the predicted probabilities to better reflect the true likelihood of the outcome for different groups.
- Reject Option Classification: Introducing a “reject option” for borderline cases where the model is uncertain, allowing for human review and intervention.
3.4. The Importance of Transparency and Explainability
Transparency and explainability are essential for building trust in machine learning models. By understanding how the model makes decisions, you can identify potential biases and ensure that the model is used responsibly.
- Explainable AI (XAI): Techniques for making machine learning models more transparent and interpretable, such as feature importance analysis, decision trees, and rule-based systems.
- Model Cards: Standardized documentation that provides information about the model’s purpose, performance, and potential biases.
- Bias Reporting: Regularly auditing and reporting on the model’s performance across different subgroups to identify and address potential biases.
4. Case Studies: Real-World Examples of Bias Mitigation
How have organizations successfully tackled bias in their machine learning models? Examining real-world case studies provides valuable insights into the challenges and best practices of bias mitigation. Let’s explore examples from various industries and applications.
4.1. Bias Mitigation in Healthcare
In healthcare, biased algorithms can lead to disparities in treatment and outcomes. For instance, a study published in Science found that an algorithm used to predict healthcare costs was biased against Black patients, leading to them being systematically undertreated.
| Challenge | Mitigation Strategy | Outcome |
|---|---|---|
| Algorithmic Bias in Cost Prediction | Redesigning the algorithm to predict health outcomes rather than costs, and incorporating additional variables to better capture patients’ health needs. | Reduced bias in treatment recommendations and improved health outcomes for Black patients. |
| Data Imbalance in Medical Imaging | Using data augmentation techniques to increase the representation of rare diseases in the training data. | Improved the accuracy of diagnostic models for rare diseases and reduced disparities in diagnosis rates. |
| Lack of Transparency in Clinical Trials | Implementing XAI techniques to understand the factors influencing the model’s predictions and ensure that they align with clinical knowledge. | Increased trust in AI-driven clinical decision support systems and facilitated the identification of potential biases. |
4.2. Bias Mitigation in Finance
In finance, biased algorithms can lead to discriminatory lending practices and unequal access to financial services.
| Challenge | Mitigation Strategy | Outcome |
|---|---|---|
| Discriminatory Lending Practices | Implementing fairness-aware algorithms that explicitly consider protected characteristics and aim to achieve equal opportunity. | Reduced disparities in loan approval rates across different demographic groups and ensured compliance with fair lending laws. |
| Lack of Explainability in Credit Scoring | Using rule-based systems and decision trees to provide clear and interpretable explanations for credit decisions. | Increased transparency in credit scoring and enabled applicants to understand and address the factors affecting their creditworthiness. |
| Data Bias in Fraud Detection | Employing resampling techniques to balance the representation of fraudulent and non-fraudulent transactions in the training data. | Improved the accuracy of fraud detection models and reduced the risk of false positives for legitimate transactions. |
4.3. Bias Mitigation in Criminal Justice
In criminal justice, biased algorithms can perpetuate and amplify racial disparities in policing, sentencing, and parole decisions.
| Challenge | Mitigation Strategy | Outcome |
|---|---|---|
| Racial Disparities in Risk Assessment | Redesigning risk assessment algorithms to remove reliance on biased predictors and incorporate community-based factors. | Reduced racial disparities in risk scores and improved the accuracy of predictions for recidivism. |
| Lack of Accountability in Policing | Implementing algorithmic auditing tools to monitor the performance of predictive policing systems and ensure that they are not disproportionately targeting minority communities. | Increased accountability and transparency in policing practices and reduced the risk of biased enforcement. |
| Data Bias in Sentencing Guidelines | Employing causal inference techniques to identify and correct for biases in sentencing guidelines, based on historical data. | Reduced disparities in sentencing outcomes across different demographic groups and ensured that sentences are proportionate to the severity of the crime. |
5. Best Practices for Building Fair and Ethical AI Systems
How can you ensure that your AI systems are fair, ethical, and aligned with societal values? Building fair and ethical AI systems requires a proactive and comprehensive approach that considers the potential impact of AI on individuals and communities. Let’s explore the best practices for developing AI systems that are trustworthy, responsible, and beneficial for all.
5.1. Develop a Fairness Framework
A fairness framework provides a structured approach to identifying, assessing, and mitigating bias in AI systems. The framework should include clear goals, principles, and procedures for ensuring fairness at every stage of the AI lifecycle.
- Define Fairness Metrics: Specify the metrics that will be used to measure fairness, such as equal opportunity, statistical parity, or equalized odds.
- Establish Accountability: Assign responsibility for ensuring fairness to specific individuals or teams within the organization.
- Implement Auditing Procedures: Regularly audit the AI system to identify and address potential biases.
5.2. Engage Diverse Stakeholders
Engaging diverse stakeholders, including domain experts, ethicists, and community members, is essential for identifying potential biases and ensuring that the AI system is aligned with societal values.
- Form an Advisory Board: Establish an advisory board comprising individuals with diverse backgrounds and perspectives to provide guidance on ethical and fairness issues.
- Conduct Community Consultations: Engage with community members to understand their concerns and incorporate their feedback into the AI system’s design.
- Promote Diversity in AI Teams: Foster diversity within AI teams to ensure that different perspectives are represented in the development process.
5.3. Prioritize Transparency and Explainability
Transparency and explainability are essential for building trust in AI systems. By understanding how the AI system makes decisions, users can identify potential biases and ensure that the system is used responsibly.
- Use Explainable AI (XAI) Techniques: Implement XAI techniques to make the AI system’s decision-making process more transparent and interpretable.
- Document the AI System: Create detailed documentation that explains the AI system’s purpose, design, and performance.
- Communicate with Users: Provide clear and accessible information to users about how the AI system works and how it may affect them.
5.4. Continuously Monitor and Evaluate
Bias can emerge or evolve over time, so it’s essential to continuously monitor and evaluate the AI system’s performance and fairness.
- Establish Monitoring Procedures: Implement procedures for continuously monitoring the AI system’s performance and fairness metrics.
- Conduct Regular Audits: Conduct regular audits to identify and address potential biases.
- Update the AI System: Update the AI system to address any biases that are identified.
6. The Future of Bias Mitigation in Machine Learning
What are the emerging trends and future directions in bias mitigation for machine learning? The field of bias mitigation is rapidly evolving, with new techniques and approaches emerging all the time. Let’s explore the cutting-edge research and future directions that promise to make AI systems fairer, more equitable, and more aligned with societal values.
6.1. Causal Inference Techniques
Causal inference techniques offer a powerful approach to understanding and mitigating bias by identifying and addressing the root causes of unfairness.
- Causal Modeling: Building causal models to understand the relationships between different variables and identify the causal pathways that lead to bias.
- Intervention Analysis: Using causal models to design interventions that disrupt the causal pathways that lead to bias.
- Counterfactual Reasoning: Using causal models to estimate the impact of different interventions on fairness metrics.
6.2. Federated Learning
Federated learning enables machine learning models to be trained on decentralized data sources without directly accessing the data, preserving privacy and reducing the risk of bias.
- Decentralized Training: Training models on multiple devices or servers without transferring the data to a central location.
- Privacy-Preserving Techniques: Using techniques such as differential privacy to protect the privacy of individual data points.
- Fairness-Aware Federated Learning: Developing federated learning algorithms that explicitly consider fairness metrics and aim to reduce bias across different data sources.
6.3. Human-in-the-Loop AI
Human-in-the-loop AI combines the strengths of machine learning with human judgment and oversight, enabling AI systems to be more accurate, reliable, and fair.
- Active Learning: Selecting the most informative data points for human labeling to improve the model’s accuracy and reduce bias.
- Human Oversight: Implementing procedures for human review and intervention in cases where the AI system is uncertain or makes a high-stakes decision.
- Collaborative AI: Designing AI systems that work collaboratively with humans, leveraging their complementary strengths to achieve better outcomes.
6.4. Ethical AI Frameworks and Regulations
Increasingly, organizations and governments are developing ethical AI frameworks and regulations to ensure that AI systems are developed and used responsibly.
- Ethical Guidelines: Developing ethical guidelines for AI development and deployment, based on principles such as fairness, transparency, and accountability.
- AI Auditing Standards: Establishing standards for auditing AI systems to ensure that they comply with ethical guidelines and regulations.
- AI Governance Structures: Creating governance structures to oversee the development and use of AI systems and ensure that they are aligned with societal values.
7. Conclusion: Embracing Fairness in Machine Learning
Why is fairness in machine learning essential, and how can you contribute to creating more equitable AI systems? Bias in machine learning is a complex and multifaceted challenge that requires a holistic and proactive approach. By understanding the sources and types of bias, implementing mitigation techniques, and adopting best practices for building fair and ethical AI systems, you can contribute to creating AI solutions that are trustworthy, responsible, and beneficial for all.
At LEARNS.EDU.VN, we are committed to providing you with the knowledge and resources you need to navigate the complexities of bias mitigation and build AI systems that are aligned with your values. Explore our comprehensive courses, workshops, and resources to deepen your understanding of machine learning fairness and develop the skills to create more equitable AI solutions.
Ready to take the next step in your AI journey? Visit LEARNS.EDU.VN today to discover how you can learn more and become a leader in ethical and responsible AI development.
Address: 123 Education Way, Learnville, CA 90210, United States
WhatsApp: +1 555-555-1212
Website: LEARNS.EDU.VN
 Bias and Variance Model
Bias and Variance Model
8. FAQ: Addressing Your Questions About Bias in Machine Learning
8.1. What is the primary reason for bias in machine learning models?
The primary reason for bias in machine learning models is flawed assumptions during the learning process, often stemming from biased training data that does not accurately represent the population. This results in skewed predictions and unfair outcomes.
8.2. How does selection bias affect machine learning outcomes?
Selection bias occurs when the training data isn’t representative of the population, leading the model to perform poorly on unseen data, especially for underrepresented groups. It skews the model’s understanding, causing inaccurate predictions.
8.3. Can algorithmic bias be completely eliminated?
No, algorithmic bias cannot be completely eliminated, but it can be significantly mitigated. Continuous monitoring, diverse datasets, fairness-aware algorithms, and ethical oversight can help reduce bias and promote fairer outcomes.
8.4. What role does data preprocessing play in mitigating bias?
Data preprocessing techniques, like resampling, reweighing, and feature engineering, adjust the data to reduce correlations between sensitive attributes and outcomes. This helps balance the representation of different groups and minimize discriminatory results.
8.5. How can transparency in AI systems help in identifying and addressing bias?
Transparency in AI systems allows for better understanding of how decisions are made, enabling the identification of potential biases in algorithms. Tools like Explainable AI (XAI) help monitor performance, ensure responsible use, and build trust.
8.6. Why is it important to engage diverse stakeholders in AI development?
Engaging diverse stakeholders ensures different perspectives are considered during AI development, helping to identify and mitigate biases that might otherwise be overlooked. It also aligns AI systems with societal values for fairness and ethical outcomes.
8.7. What are some effective methods for detecting bias in machine learning models?
Effective methods include data analysis techniques, like exploratory data analysis (EDA) and demographic analysis; model evaluation metrics, such as precision, recall, and the disparate impact ratio; and visualization techniques, like confusion matrices and ROC curves.
8.8. How do fairness-aware algorithms differ from traditional machine learning algorithms?
Fairness-aware algorithms are designed to optimize both accuracy and fairness, explicitly considering potential biases in the data. They aim to achieve equal opportunity and statistical parity, promoting equitable outcomes across different groups.
8.9. What steps should be taken to ensure continuous monitoring and evaluation of AI systems?
Steps include establishing monitoring procedures, conducting regular audits, and updating the AI system to address any biases that are identified. Continuous vigilance helps ensure that AI systems remain fair, ethical, and aligned with societal values over time.
8.10. How does LEARNS.EDU.VN support individuals in understanding and mitigating bias in machine learning?
learns.edu.vn provides comprehensive courses, workshops, and resources to deepen understanding of machine learning fairness. By exploring these offerings, individuals can develop skills to create more equitable AI solutions, navigate complexities, and build trustworthy systems.