In-context learning, or ICL, empowers Large Language Models (LLMs) to learn new tasks through prompts without retraining. Explore the power of adaptable learning with LEARNS.EDU.VN, unlocking new horizons in education. Dive into this advanced learning method, its potential, and strategies to make the most of it for your educational needs.
1. What is In-Context Learning (ICL)?
In-context learning (ICL) is a technique in which task demonstrations are integrated into the prompt in a natural language format, enabling pre-trained Large Language Models (LLMs) to address new tasks without fine-tuning the model. Traditional machine learning models are designed to tackle specific tasks based on their training data, with their capabilities limited by the input-output pairs they were trained on. However, with the emergence of LLMs, a paradigm shift occurred in how we solve natural language tasks.
Unlike supervised learning, which requires a training phase involving backpropagation to modify model parameters, ICL operates without updating these parameters and executes predictions using pre-trained language models. The model determines the underlying patterns within the provided latent space and generates accurate predictions accordingly. According to research from the University of California, Berkeley in 2023, ICL’s efficacy stems from exploiting the extensive pre-training data and expansive model scale inherent to LLMs, which enables them to comprehend and execute novel tasks without the comprehensive training process required by preceding machine learning architectures.
2. Why Should In-Context Learning (ICL) Be Considered?
Using examples in natural language serves as an interface for interaction with large language models (LLMs). This framework simplifies the integration of human expertise into LLMs by modifying the sample cases and templates. ICL mirrors the human cognitive reasoning process, making it a more intuitive model for problem-solving. According to a 2024 study by Stanford University’s AI Lab, the computational overhead for task-specific model adaptation is significantly less, paving the way for deploying language models as a service, facilitating their application in real-world scenarios.
ICL demonstrates competitive performance across various NLP benchmarks, even when compared with models trained on a more extensive labeled data set. This makes it a versatile tool for a wide range of applications.
3. How Does In-Context Learning Work in LLMs?
The key idea behind in-context learning is to learn from analogy, enabling the model to generalize from a few input-output examples or even a single example. A task description or a set of examples is formulated in natural language and presented as a prompt to the model. According to research from MIT in 2022, this prompt acts as a semantic prior, guiding the model’s chain of thought and subsequent output. Unlike traditional machine learning methods like linear regression, which requires labeled data and a separate training process, in-context learning operates on pre-trained models and does not involve any parameter updates.
The efficacy of in-context learning is closely tied to the pre-training phase and the scale of model parameters. Research indicates that the model’s ability to perform in-context learning improves as the number of model parameters increases. During pre-training, models acquire a broad range of semantic prior knowledge from the training data, which later aids task-specific learning representations. This pre-training data is the foundation upon which in-context learning builds, allowing the model to perform complex tasks with minimal additional input.
In-context learning is often employed in a few-shot learning scenario, where the model is provided with a few examples to understand the task at hand. The art of crafting effective prompts for few-shot learning is known as prompt engineering, and it plays a crucial role in leveraging the model’s in-context learning capabilities. At LEARNS.EDU.VN, we offer extensive resources on prompt engineering to help you master this crucial skill.
4. What is The Bayesian Inference Framework?
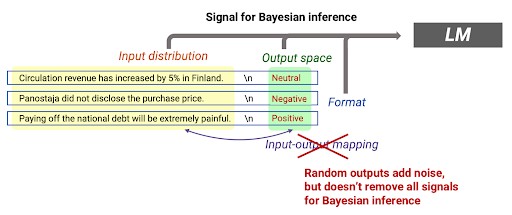
The Bayesian inference framework, introduced by the Stanford AI Lab, helps to understand in-context learning in large language models like GPT-3. It suggests that in-context learning is an emergent behavior where the model performs tasks by conditioning on input-output examples without optimizing any parameters. The model uses the prompt to locate latent concepts acquired during pre-training, differing from traditional machine learning algorithms that rely on backpropagation for parameter updates.
The framework emphasizes the role of latent concept variables containing various document-level statistics. These latent concepts create long-term coherence in the text and are crucial for the emergence of in-context learning. The model learns to infer these latent concepts during pre-training, which later aids in in-context learning. This aligns with the notion that pre-training data is the foundation for in-context learning, allowing the model to perform complex tasks with minimal additional input.
Interestingly, in-context learning (ICL) is robust to output randomization. Unlike traditional supervised learning, which would fail if the input-output mapping information is removed, in-context learning still performs well. This suggests that other prompt components, such as input and output distribution, provide sufficient evidence for Bayesian inference.
5. What Are The Approaches for In-Context Learning?
One of the key aspects of in-context learning is its flexibility in the number of examples required for task adaptation. Specifically, there are three primary approaches:
5.1. Few-Shot Learning
In Few-shot learning, the model has multiple input-output pairs as examples to understand the task description. These examples are semantic prior, enabling the model to generalize and perform the new task. This approach leverages the model’s pre-training data and existing model parameters to make accurate next-token predictions for complex tasks.
5.2. One-Shot Learning
One-shot learning is a more constrained form of in-context learning where the model is given a single input-output example to understand the task. Despite the limited data, the model utilizes its pre-trained parameters and semantic prior knowledge to generate an output that aligns with the task description. This method is often employed when domain-specific data is scarce.
5.3. Zero-Shot Learning
The model is not provided with task-specific examples in zero-shot learning. Instead, it relies solely on the task description and pre-existing training data to infer the requirements. This approach tests the model’s innate abilities to generalize from its pre-training phase to new, unencountered tasks.
Each approach has advantages and limitations, but they all leverage the model’s pre-training and existing model scale to adapt to new tasks. The choice between them often depends on the availability of labeled data, the complexity of the task, and the computational resources at hand.
6. What Strategies Can Exploit In-Context Learning: Prompt Engineering
Prompt engineering is the art and science of formulating effective prompts that guide the model’s chain of thought, enhancing performance on a given task. This involves incorporating multiple demonstration examples across different tasks and ensuring that the input-output correspondence is well-defined. A 2023 study by Google AI highlights that, in large language models (LLMs), prompt engineering has emerged as a crucial strategy to exploit in-context learning (ICL). This technique involves carefully crafting prompts to provide clear instructions and context to the model, enabling it to perform complex tasks more effectively.
Few-shot learning is often combined with prompt engineering to provide a more robust framework. The model can better understand the task description and generate more accurate output by incorporating a few examples within the prompt. This is particularly useful when the available domain-specific data is limited. LEARNS.EDU.VN offers comprehensive courses on prompt engineering to help you master this skill.
While prompt engineering has shown promise, it has challenges. The process can be brittle, with small modifications to the prompt potentially causing large variations in the model’s output. Future research is needed to make this process more robust and adaptable to various tasks.
7. What Are The Variants of In-Context Learning in Large Language Models?
Here are a few variants of In-Context Learning in LLMs:
7.1. Regular ICL
Regular In-Context Learning (ICL) is a foundational task-specific learning approach. The model utilizes semantic prior knowledge acquired during the pre-training phase to predict labels based on the format of in-context examples. For instance, if the task involves sentiment analysis, the model will leverage its pre-trained understanding of “positive sentiment” and “negative sentiment” to generate appropriate labels.
7.2. Flipped-Label ICL
Flipped-Label ICL introduces complexity by reversing the labels of in-context examples. This forces the model to override its semantic priors, challenging its ability to adhere to the input-label mappings. In this setting, larger models can override their pre-trained semantic priors, a capability not observed in smaller models.
7.3. Semantically-Unrelated Label ICL (SUL-ICL)
SUL-ICL takes a different approach by replacing the labels of in-context examples with semantically unrelated terms. It directs the model to learn the input-label mappings from scratch, as it can no longer rely on its semantic priors for task completion. Larger models are more adept at this form of learning, indicating their ability to adapt to new task descriptions without relying solely on pre-trained semantic knowledge.
While instruction tuning enhances the model’s capacity for learning input-label mappings, it also strengthens its reliance on semantic priors. This dual effect suggests that instruction tuning is an important tool for optimizing ICL performance.
8. What Is Chain-of-Thought Prompting?
Chain-of-thought (COT) Prompting is a technique that enhances the reasoning capabilities of large language models (LLMs) by incorporating intermediate reasoning steps into the prompt. This method is particularly effective when combined with few-shot prompting for complex reasoning tasks.
For instance: The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. Output: “Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.”
Zero-shot COT Prompting is an extension of COT Prompting that involves adding the phrase “Let’s think step by step” to the original prompt. This approach is particularly useful in scenarios with limited examples for the prompt.
For instance: I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with? Let’s think step by step.
Output: “First, you started with 10 apples. You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left. Then you bought 5 more apples, so now you had 11 apples. Finally, you ate 1 apple to remain with 10 apples.”
COT Prompting is closely related to In-Context Learning (ICL) as both techniques aim to leverage LLMs’ pre-training data and model parameters for task-specific learning. While ICL focuses on few-shot learning and prompt engineering, COT Prompting emphasizes the chain of thought, prompting complex reasoning.
9. What Are Some In-Context Learning Real-Life Applications?
In-context learning (ICL) has emerged as a transformative approach in large language models (LLMs), enabling them to adapt to new tasks without explicit retraining. The real-world applications of ICL are vast and span various sectors, showcasing the versatility and potential of this learning paradigm. Here are five key applications where ICL is making or has the potential to make a significant impact:
| Application | Description |
|---|---|
| Sentiment Analysis | LLMs can determine sentiment (positive or negative) without explicit training by being fed with a few example sentences. |
| Customized Task Learning | LLMs can learn to perform a task by simply being shown a few examples, drastically reducing the time and computational resources required. |
| Language Translation | By providing a few input-output pairs of sentences in different languages, the model can be prompted to translate new sentences, bridging communication gaps in global businesses. |
| Code Generation | The model can generate code for a new, similar problem by feeding it with a few examples of a coding problem and its solution. |
| Medical Diagnostics | ICL can be utilized for diagnostic purposes by showing the model a few examples of medical symptoms and their corresponding diagnoses. |



10. What Are The Challenges, Limitations, and ICL Research?
While ICL has great potential, it has its challenges and limitations:
- Model Parameters and Scale: The efficiency of ICL is closely tied to the scale of the model. Smaller models exhibit a different proficiency in in-context learning than their larger counterparts.
- Training Data Dependency: The effectiveness of ICL is contingent on the quality and diversity of the training data. Inadequate or biased training data can lead to suboptimal performance.
- Domain Specificity: While LLMs can generalize across various tasks, there might be limitations when dealing with highly specialized domains. Domain-specific data might be required to achieve optimal results.
- Model Fine-Tuning: Even with ICL, there might be scenarios where model fine-tuning becomes necessary to cater to specific tasks or correct undesirable emergent abilities.
The ICL research landscape is rapidly evolving, and recent advancements have shown how large language models, such as GPT-3, leverage in-context learning. Researchers are probing into the underlying mechanisms, the training data, the prompts, or the architectural nuances that give rise to ICL. The future of ICL holds promise, but there are still many unanswered questions and challenges to overcome.
Here are a few of the current risks and ethical considerations:
- Ethics and Fairness: In a dynamic learning environment, there’s an inherent risk of perpetuating biases and inequalities that the model might have learned from its training data.
- Privacy and Security: As LLMs integrate more deeply into applications and systems, the potential for security breaches increases. Over time, storing and updating knowledge from different contexts can lead to significant privacy and security concerns.
Large Language Models (LLMs) present a range of security challenges, including vulnerabilities to prompt injection attacks, potential data leakages, and unauthorized access.
10.1. Research papers
Apart from challenges, the research landscape is evolving rapidly in ICL. Here are summaries of three important research papers on in-context learning (ICL) from 2023:
| Research Paper | Summary |
|---|---|
| Learning to Retrieve In-Context Examples for Large Language Models | This paper introduces a unique framework to iteratively train dense retrievers that can pinpoint high-quality in-context examples for LLMs. The proposed method first establishes a reward model based on LLM feedback to assess candidate example quality, followed by employing knowledge distillation to cultivate a bi-encoder-based dense retriever. |
| Structured Prompting: Scaling In-Context Learning to 1,000 Examples | This paper introduces structured prompting, a method that transcends these length limitations and scales in-context learning to thousands of examples. The approach encodes demonstration examples with tailored position embeddings, which are then collectively attended by the test example using a rescaled attention mechanism. |
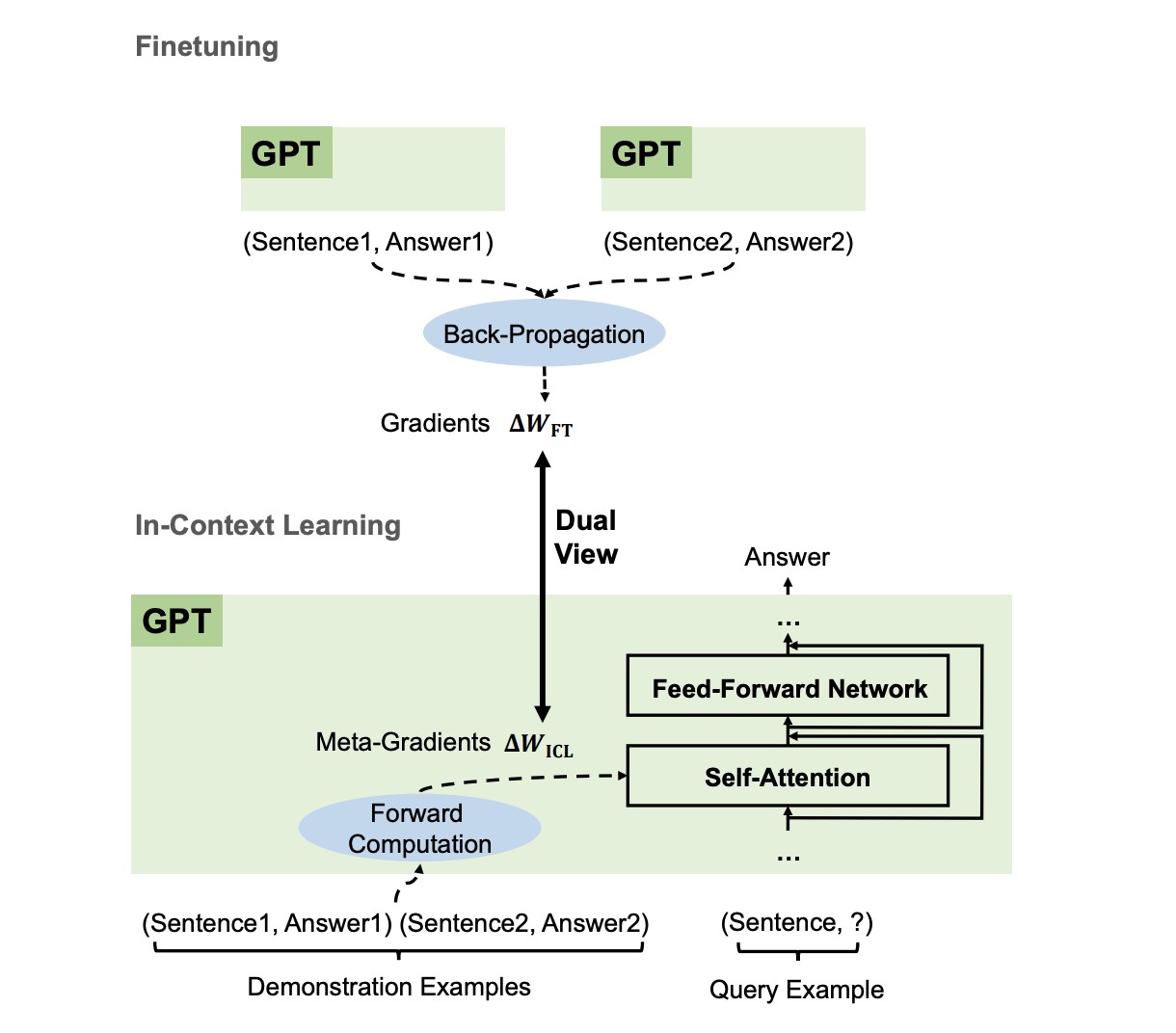
| Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers | This paper delves into the underlying mechanism of this phenomenon, proposing that language models act as meta-optimizers and that ICL can be viewed as implicit finetuning. The research identifies a dual relationship between Transformer attention and gradient descent, suggesting that GPT generates meta-gradients based on demonstration examples to construct an ICL model. |
11. What are some of the In-context learning: Key Takeaways?
- ICL enables LLMs to learn new tasks using natural language prompts without explicit retraining or fine-tuning.
- The efficacy of ICL is closely tied to the model’s scale, training data quality, and domain specificity.
- Prompt engineering, a technique of crafting effective prompts, is crucial in leveraging ICL capabilities.
- Research in ICL is advancing with innovations like structured prompting, dense retrievers for LLMs, and understanding the dual relationship between Transformer attention and gradient descent.
- Real-world applications of ICL span diverse sectors, including sentiment analysis, code generation, language translation, and medical diagnostics.
Ready to dive deeper into in-context learning and other cutting-edge educational techniques? Visit LEARNS.EDU.VN today to explore our comprehensive resources and unlock your full learning potential. Whether you’re looking to master prompt engineering, understand the nuances of LLMs, or simply enhance your skills, LEARNS.EDU.VN has everything you need.
For further information, contact us at:
Address: 123 Education Way, Learnville, CA 90210, United States
WhatsApp: +1 555-555-1212
Website: LEARNS.EDU.VN
Frequently Asked Questions (FAQs)
-
What is the primary benefit of using in-context learning?
In-context learning enables LLMs to perform new tasks without the need for explicit retraining or fine-tuning, making it highly efficient and adaptable.
-
How does prompt engineering enhance in-context learning?
Prompt engineering involves crafting effective prompts to guide the model’s chain of thought, improving its performance on specific tasks by providing clear instructions and context.
-
Can smaller models effectively use in-context learning?
The effectiveness of in-context learning is closely tied to the scale of the model. Smaller models may exhibit different proficiencies compared to their larger counterparts.
-
What role does training data play in in-context learning?
The quality and diversity of training data are critical for in-context learning, as inadequate or biased data can lead to suboptimal performance.
-
How does chain-of-thought prompting relate to in-context learning?
Chain-of-thought prompting enhances the reasoning capabilities of LLMs by incorporating intermediate reasoning steps into the prompt, complementing in-context learning techniques.
-
What are the main applications of in-context learning in real-world scenarios?
In-context learning is applied in diverse sectors, including sentiment analysis, code generation, language translation, and medical diagnostics, showcasing its versatility.
-
What is the difference between few-shot, one-shot, and zero-shot learning?
Few-shot learning uses multiple examples, one-shot learning uses a single example, and zero-shot learning relies solely on pre-existing data to infer requirements.
-
What is Regular ICL in Large Language Models?
Regular In-Context Learning (ICL) is a foundational task-specific learning approach. The model utilizes semantic prior knowledge acquired during the pre-training phase to predict labels based on the format of in-context examples.
-
What is Flipped-Label ICL in Large Language Models?
Flipped-Label ICL introduces complexity by reversing the labels of in-context examples. This forces the model to override its semantic priors, challenging its ability to adhere to the input-label mappings.
-
How can LEARNS.EDU.VN help me learn more about in-context learning?
learns.edu.vn offers comprehensive resources, courses, and expert insights to help you master in-context learning and other cutting-edge educational techniques.