Machine learning (ML) inference is a crucial stage in the machine learning lifecycle. It represents the process of using a trained machine learning algorithm, often referred to as an “ML model,” to make predictions or decisions on new, unseen data. This process is fundamental to operationalizing machine learning, effectively putting models into action to derive value from data. When a machine learning model is actively used for predictions, it’s often considered a form of applied artificial intelligence (AI), mimicking human-like analytical capabilities. Machine learning inference involves deploying the ML model as a software application within a production environment. The model itself is essentially software code embodying a mathematical algorithm. This algorithm processes input data, characterized as “features,” to generate an output, typically a numerical score or a classification.
The machine learning lifecycle consists of two primary phases: training and inference. The training phase is where the ML model learns patterns from a dataset, enabling it to make future predictions. Machine learning inference is the subsequent phase where this trained model is deployed to process live data and generate actionable insights. The act of processing data through the model is often called “scoring,” and the resulting output is the “score” or prediction. DevOps engineers or data engineers are typically responsible for deploying ML inference systems. In some cases, data scientists who developed the models may also handle deployment, although this can present challenges as deployment requires a different skillset. Successful ML inference implementations often necessitate close collaboration between teams and the adoption of specialized software tools to streamline the process. The emerging field of MLOps (Machine Learning Operations) is dedicated to establishing structured practices and resources for deploying and maintaining ML models in production environments.
How Machine Learning Inference Works
Setting up a machine learning inference environment requires several key components in addition to the trained ML model itself:
- Data Sources: These are the origins of the real-time data that the ML model will process.
- ML Model Hosting System: This is the infrastructure that runs the ML model and processes the incoming data.
- Data Destinations: These are the systems or applications that receive the output or predictions generated by the ML model.
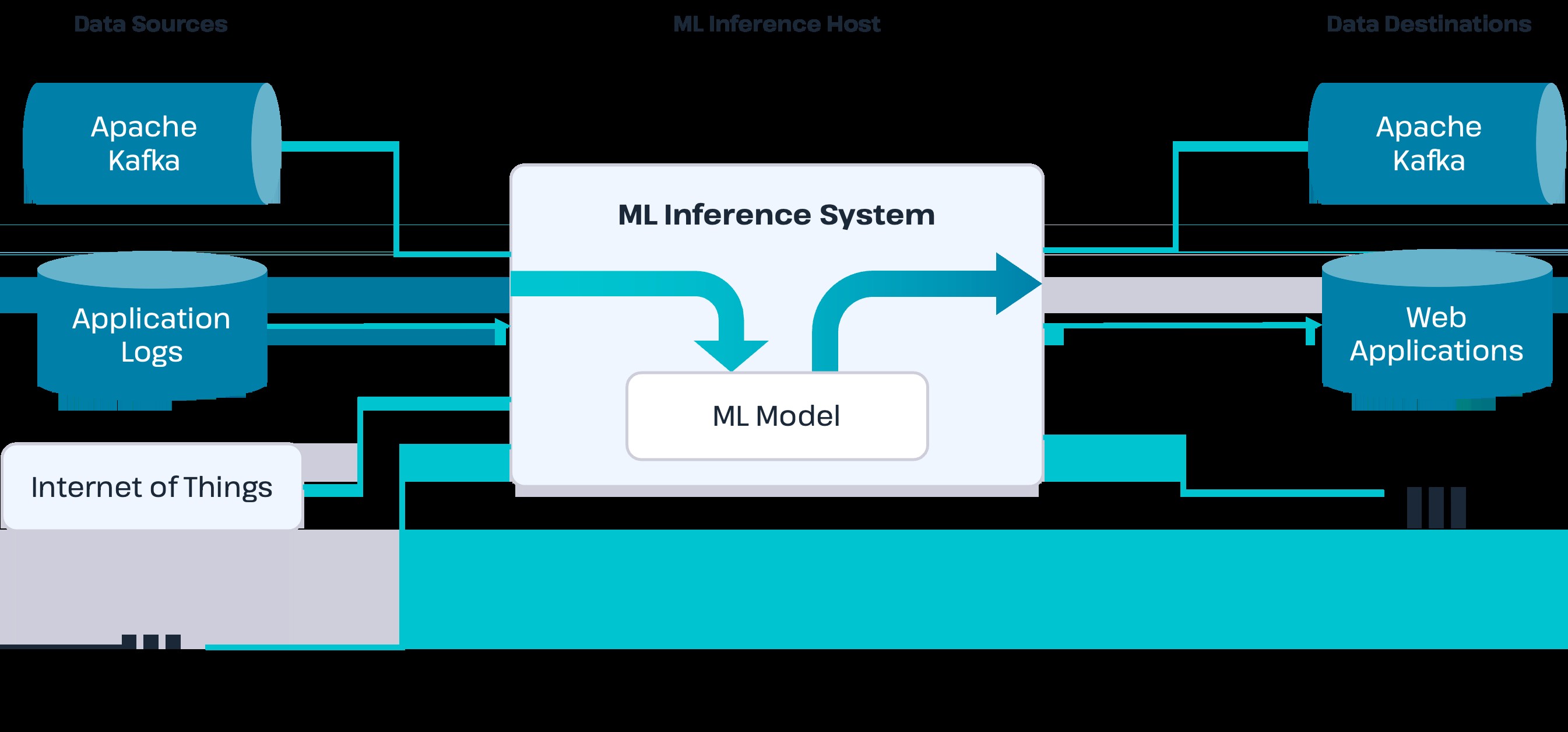 Diagram illustrating the machine learning inference process with data sources, ML model host system, and data destinations, highlighting the flow of data for real-time predictions.
Diagram illustrating the machine learning inference process with data sources, ML model host system, and data destinations, highlighting the flow of data for real-time predictions.
In a typical machine learning inference setup, data sources continuously feed live data into the system. These sources can vary widely depending on the application. For instance, a data source could be an Apache Kafka cluster collecting data from Internet of Things (IoT) devices, web server logs capturing user activity, or point-of-sale (POS) systems recording transaction data. Web applications that track user interactions can also serve as data sources, directly sending user click data to the ML model hosting system.
The ML model hosting system acts as the engine for inference. It receives data from the defined data sources and feeds it into the deployed ML model. This system provides the necessary infrastructure to transform the ML model’s code into a functioning application. The hosting system might be a web application exposing a REST API for data input or a stream processing application designed to handle high-velocity data streams from sources like Apache Kafka.
Once the ML model processes the input data and generates an output, the hosting system routes this output to the designated data destinations. Data destinations can be various data repositories, such as databases or message queues like Apache Kafka. From these destinations, downstream applications can utilize the model’s predictions for further actions. For example, in a fraud detection scenario, if the ML model calculates a high fraud score for a transaction, the applications connected to the data destination might automatically decline the transaction and notify relevant parties.
Challenges of Machine Learning Inference
As previously mentioned, a significant challenge in machine learning inference is the potential misplacement of responsibility onto data scientists. Data scientists, while experts in model development, may lack the specialized skills required for deploying and managing production systems. Providing them with only basic tools for ML inference can hinder successful deployment.
Furthermore, DevOps and data engineers, who possess the necessary deployment expertise, may face their own hurdles. Conflicting priorities, a lack of familiarity with machine learning workflows, or insufficient understanding of inference requirements can impede their ability to assist effectively. A common technical challenge arises from the programming languages often used in data science versus IT operations. ML models are frequently developed in Python, favored by data scientists, while IT teams often have stronger expertise in languages like Java. This discrepancy may necessitate translating Python-based models into Java to align with existing infrastructure, adding complexity and workload to the deployment process. Additionally, preparing input data to be compatible with the ML model’s expected format requires extra coding, further increasing the engineering effort.
The iterative nature of the ML lifecycle also presents challenges. Machine learning models typically require ongoing experimentation and periodic updates to maintain accuracy and relevance. If the initial deployment of a model is cumbersome, subsequent updates become equally difficult. Maintaining these models in production involves addressing critical aspects like business continuity and security, adding to the overall complexity.
Performance and scalability are additional key considerations. Inference systems relying on REST APIs can suffer from limitations in throughput and increased latency, which might be inadequate for applications dealing with high-volume data streams, such as IoT data or high-frequency online transactions. Modern inference deployments need to efficiently handle growing workloads and adapt to sudden spikes in demand while maintaining consistent responsiveness.
Choosing the right technology stack is crucial to effectively address these challenges in machine learning inference. Solutions like Hazelcast, offering in-memory and streaming technologies, are designed to optimize ML inference deployments by providing the necessary speed and scalability. Open-source options are available, enabling organizations to explore and test these technologies without initial investment.
Related Topics
- Machine Learning Model Deployment
- MLOps (Machine Learning Operations)
- Real-time Data Processing
- Stream Processing
- Artificial Intelligence (AI) Applications
Keep Reading
Webinar: Machine Learning Inference at Scale with Python and Stream Processing
Webinar: Tech Talk: Machine Learning at Scale Using Distributed Stream Processing
Webinar: Key Considerations for Optimal Machine Learning Deployments
Webinar: Operationalizing Machine Learning with Java Microservices and Stream Processing
White Paper: Fraud Detection with In-Memory Machine Learning
Level up with Hazelcast
Request a DemoTalk to an Expert