Self supervised learning is a revolutionary approach in machine learning where models learn from unlabeled data by creating their own supervisory signals. Interested in mastering this technique? At LEARNS.EDU.VN, we offer comprehensive resources and courses to help you understand and implement self supervised learning effectively, unlocking new possibilities in AI. Explore our platform to discover more about self learning methods, pretext tasks, and downstream tasks, and enhance your skills in creating intelligent systems.
1. Understanding Self Supervised Learning (SSL)
Self-supervised learning (SSL) represents a groundbreaking shift in machine learning, designed to overcome the limitations of traditional supervised learning, which heavily relies on labeled data. For years, the development of intelligent systems has been significantly constrained by the need for extensive, high-quality labeled datasets. The cost and effort associated with creating these datasets have become major bottlenecks in the AI development process.
AI researchers are now prioritizing the creation of self-learning mechanisms that can utilize unstructured data. This approach aims to reduce the costs associated with data labeling and enable the development of more versatile AI systems. The challenge lies in the impracticality of collecting and labeling the vast amounts of diverse data needed for comprehensive AI training.
To address this challenge, researchers are actively developing self-supervised learning (SSL) techniques that can discern subtle patterns and insights from data without explicit labels.
1.1. Traditional Learning Methods: A Quick Review
Before diving into the specifics of self-supervised learning, let’s briefly recap the most common learning methods used in building intelligent systems:
1.1.1. Supervised Learning
Supervised learning involves training neural networks on labeled data for a specific task. Think of it as a student learning from a teacher who provides numerous examples. A classic example is object classification, where the model learns to identify objects based on labeled images.
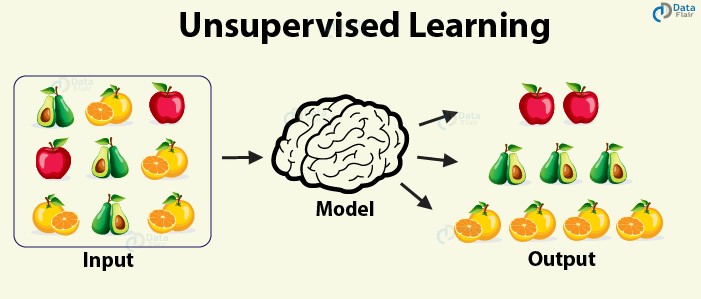
1.1.2. Unsupervised Learning
Unsupervised learning is a technique used to identify hidden patterns in data without explicit training on labeled data. Unlike supervised learning, it doesn’t require annotations or a feedback loop. Clustering, where data points are grouped based on similarities, is a common example.
1.1.3. Semi-Supervised Learning
Semi-supervised learning combines elements of both supervised and unsupervised learning. In this method, a portion of the input data is labeled, while the rest is not.
Semi-supervised learning is particularly useful when only a small amount of labeled data is available. The model can be trained on the labeled data and then use pseudo-labeling techniques to infer labels for the rest of the dataset.
1.1.4. Reinforcement Learning
Reinforcement learning involves training AI agents to learn optimal behavior within an environment by using a reward feedback policy. Imagine a child learning to win a game through trial and error.
1.2. The Essence of Self-Supervised Learning
Self-supervised learning is a machine learning process where a model trains itself to predict one part of the input from another. It is also known as predictive learning or pretext learning. The core idea is to convert an unsupervised problem into a supervised one by automatically generating labels from the data itself. Setting the right learning objectives is crucial for leveraging the vast amount of unlabeled data effectively.
Self-supervised learning involves identifying hidden or masked parts of the input using the unhidden parts.
For example, in natural language processing, SSL can be used to complete sentences. In video analysis, it can predict future frames based on available video data. This technique uses the inherent structure of the data to create supervisory signals across large datasets without needing manual labels.
1.3. Self-Supervised vs. Unsupervised Learning: Key Differences
Many people often confuse self-supervised and unsupervised learning, using the terms interchangeably. However, these techniques have distinct objectives.
Both self-supervised and unsupervised learning methods do not require labeled datasets, making them complementary. Unsupervised learning can be seen as a superset of self-supervised learning because it does not involve feedback loops. In contrast, self-supervised learning uses supervisory signals that act as feedback during the training process.
Unsupervised learning focuses more on the model itself, whereas self-supervised learning emphasizes the data. Unsupervised learning excels at tasks like clustering and dimensionality reduction, while self-supervised learning is used as a pretext method for regression and classification tasks.
1.4. The Need for Self-Supervised Learning
Self-supervised learning emerged to address several persistent issues in other learning procedures:
- High Cost: Most learning methods require labeled data, which is expensive to acquire in terms of both time and money.
- Lengthy Lifecycle: Preparing data for machine learning models is a time-consuming process, involving cleaning, filtering, annotating, reviewing, and restructuring the data to fit the training framework.
- Towards Generic AI: Self-supervised learning represents a step toward embedding human-like cognition in machines, enabling them to learn from their environment with minimal supervision.
2. Applications of Self-Supervised Learning
Let’s explore how self-supervised learning is used in various domains.
2.1. Computer Vision
For many years, computer vision research focused on improving model architectures, assuming the availability of high-quality labeled data. In reality, obtaining good-quality image data is costly and time-consuming, leading to suboptimal models. Recent research has shifted toward developing self-supervised methods in computer vision to overcome these challenges. Training models with unlabeled data speeds up the overall training process and allows the model to learn underlying semantic features without label bias.
Self-supervised learning in computer vision typically involves two main stages:
- Pretext Task: This task is used for pre-training the model to learn intermediate representations of data. It helps the model understand the underlying structure, which benefits downstream tasks.
- Downstream Tasks: This involves transferring the knowledge learned during the pretext task to specific tasks using a smaller amount of labeled data.
Generative models like GANs can be considered self-supervised models, but with different objectives. GANs generate realistic images, while self-supervised training aims to identify features that can be used for various tasks.
2.1.1. Patch Localization
Objective: To identify the relationship between different patches in an image using self-supervised learning.
Training Algorithm:
- Sample a random patch from the image.
- Sample a second patch from its neighboring locations (e.g., in a 3×3 grid).
- Introduce augmentations like gaps, chromatic aberration, and downsampling to prevent overfitting.
- Train the model to classify the position of the second patch relative to the first.
2.1.2. Context-Aware Pixel Prediction
Objective: To predict the pixel values of an unknown patch in an image based on the overall context.
Training Algorithm:
- Use a vanilla encoder-decoder architecture.
- The encoder generates a latent feature representation of the image with blacked-out regions.
- The decoder estimates the missing image region using the latent feature representation and reconstruction loss (MSE).
Loss Functions:
- Reconstruction Loss: Captures salient features relative to the context of the full image.
- Adversarial Loss: Makes the prediction look real and learns the latent space of the input data.
- Joint Loss: Combines reconstruction and adversarial losses, though experiments show that inpainting works best with only adversarial loss.
2.2. Natural Language Processing (NLP)
Self-supervised learning has significantly advanced natural language processing (NLP). From document processing to text suggestion and sentence completion, language models are widely used.
The evolution of these models can be traced back to the Word2Vec paper published in 2013, which revolutionized NLP. The idea of word embedding approaches was simple: instead of asking a model to predict the next word, we can ask it to predict the next word based on prior context.
This advancement has led to meaningful representations through the distribution of word embeddings, useful in scenarios like sentence completion and word prediction. Today, one of the most popular SSL methods in NLP is BERT.
2.2.1. Next Sentence Prediction (NSP)
In Next Sentence Prediction (NSP), the model predicts the relative position of two sentences. For example, given sentence A, the model determines whether sentence B follows A.
Example:
- After completing the school hours, Mike went home.
- After almost 50 years, the manned mission to Moon is finally underway.
- Once home, Mike watched Netflix to relax.
The model should predict that sentence 1 is followed by sentence 3.
BERT (Bidirectional Encoder Representations from Transformers), developed by Google AI, is a gold standard for NLP tasks. For downstream tasks, BERT captures the relationship between sentences in ways that other language modeling techniques cannot.
BERT handles NSP by:
- Representing a pair of sentences packed together in a single sequence.
- Starting every sequence with a special classification token ([CLS]).
- Separating sentences with a special token ([SEP]).
- Adding a learned embedding to each token indicating whether it belongs to sentence A or sentence B.
2.2.2. Auto-Regressive Language Modelling
While autoencoding models like BERT are used for sentence classification, auto-regressive models like GPT (Generative Pre-trained Transformer) are used for text generation.
Autoregressive models are pre-trained on the task of predicting the next word given the previous words. These models correspond to the decoder part of the transformer, and a mask is used to ensure that attention heads only see the text that comes before.
Training Framework of GPT:
- Unsupervised Pre-training: Learning a high-capacity language model on a large corpus of text. The model maximizes the likelihood of predicting the next word given the previous words.
- Supervised Fine-tuning: Using a labeled dataset to fine-tune the pre-trained model for specific tasks. This involves passing the inputs through the pre-trained model to obtain the final transformer block’s activation, which is then fed into a linear output layer to predict the label.
2.3. Industrial Case Studies
Let’s examine how self-supervised learning is being used to solve critical problems in industry.
2.3.1. Hate-Speech Detection at Facebook
Facebook uses self-supervised learning to build background knowledge and approximate common sense in AI systems.
One example is XLM, a method for training language systems across multiple languages to improve hate speech detection without relying on hand-labeled datasets.
XLM Model:
- Casual Language Modelling (CLM): Models the probability of a word given the previous words.
- Masked Language Modelling (MLM): Masks randomly chosen tokens and tries to predict them.
- Translation Language Modelling (TLM): Concatenates parallel sentences and masks words in both source and target sentences.
Performance Analysis of XLM:
- Cross-lingual classification: Achieves state-of-the-art performance by obtaining 71.5% accuracy through MLM.
- Machine Translation Systems: Improves supervised and unsupervised neural machine translation systems.
- Language models for low-resource languages: Improves language models for low-resource languages by leveraging data in similar, higher-resource languages.
- Unsupervised cross-lingual word embeddings: Outperforms previous works on cross-lingual word embeddings.
2.3.2. Google’s Medical Imaging Analysis Model
In the medical domain, training deep learning models is challenging due to limited labeled data. Google’s Research Team introduced a Multi-Instance Contrastive Learning (MICLe) method that uses multiple images of the underlying pathology per patient case to construct more informative positive pairs for self-supervised learning.
Steps Involved:
- Uses SimCLR, a framework for self-supervised representation learning on images.
- MICLe constructs positive pairs by drawing crops from distinct images of the same patient case.
- The model is fine-tuned using the weights of the pre-trained network as initialization for the downstream supervised task dataset.
SimCLR Framework:
SimCLR learns generic representations of images on an unlabeled dataset. It maximizes agreement between differently transformed views of the same image and minimizes agreement between transformed views of different images using contrastive learning.
MICLe:
Given multiple images of a patient, MICLe constructs positive pairs by drawing two crops from two distinct images from the same patient case.
Performance Analysis:
- Self-supervised learning significantly outperforms supervised ImageNet pre-training.
- Self-supervised pre-trained models generalize better to distribution shifts with MICLe pre-training leading to the most gains.
- Pre-training using self-supervised models can compensate for low label efficiency for medical image classification.
3. Challenges in Self-Supervised Learning
Despite its advancements, self-supervised learning has some drawbacks:
- Accuracy: The approach requires large amounts of data to generate accurate pseudo-labels or compromises on accuracy. Inaccurate labels can be counterproductive during initial training.
- Computational Efficiency: Due to multiple stages of training, the time taken to train a model is high compared to supervised learning. Current SSL approaches require a huge amount of data to achieve accuracy close to supervised learning counterparts.
- Pretext Task: Choosing the right pretext task is crucial. For instance, using an autoencoder as a pretext task may mimic noise in the original image, which can be harmful if the task is generating high-quality images.
4. Key Takeaways
Self-supervised learning is a powerful technique for addressing data-related challenges, such as low resources for dataset preparation and time-consuming annotation problems. It excels in downstream tasks like transfer learning, where models are pre-trained on unlabeled datasets and fine-tuned for specific use-cases. However, it’s essential to be aware of the limitations, including the need for large amounts of data and careful selection of pretext tasks.
5. FAQs about Self-Supervised Learning
-
What exactly is self-supervised learning?
Self-supervised learning is a machine learning approach where a model learns from unlabeled data by creating its own supervisory signals. The model is trained to predict one part of the input from another, allowing it to learn useful representations without manual labels.
-
How does self-supervised learning differ from supervised learning?
Supervised learning requires labeled data, where each input is paired with a correct output. Self-supervised learning, on the other hand, uses unlabeled data and generates its own labels by leveraging the inherent structure of the data.
-
What are the primary applications of self-supervised learning in computer vision?
In computer vision, self-supervised learning is used for tasks such as patch localization (identifying the relationship between different patches in an image) and context-aware pixel prediction (predicting pixel values based on the overall context of the image).
-
Can you explain the concept of pretext tasks in self-supervised learning?
A pretext task is a task used for pre-training a model to learn intermediate representations of data. The goal is to guide the model to understand the underlying structure of the data, which is then beneficial for practical downstream tasks.
-
What role does BERT play in self-supervised learning for natural language processing?
BERT (Bidirectional Encoder Representations from Transformers) is a popular self-supervised learning method used in NLP for tasks like next sentence prediction. It captures the relationship between sentences, enabling the model to predict the subsequent sentence given a context.
-
What are some real-world applications of self-supervised learning?
Self-supervised learning is used in various applications, including hate speech detection at Facebook (using XLM) and medical imaging analysis at Google (using MICLe) to improve model accuracy and efficiency.
-
What is SimCLR, and how is it used in medical imaging analysis?
SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) is a framework designed by Google for self-supervised representation learning on images. It is used in medical imaging analysis to learn generic representations of images on unlabeled datasets before fine-tuning with labeled data.
-
What are the key challenges associated with self-supervised learning?
Challenges include ensuring accuracy (requiring large amounts of data to generate accurate pseudo-labels), computational efficiency (due to multiple training stages), and the critical selection of an appropriate pretext task.
-
How does multi-instance contrastive learning (MICLe) enhance self-supervised learning in medical imaging?
MICLe (Multi-Instance Contrastive Learning) enhances self-supervised learning by using multiple images of the underlying pathology per patient case to construct more informative positive pairs, improving the model’s ability to learn robust representations.
-
Where can I learn more about self-supervised learning and its applications?
For more in-depth information and resources on self-supervised learning, visit LEARNS.EDU.VN. We offer comprehensive courses and materials to help you understand and implement self-supervised learning effectively.
Interested in exploring more about self-supervised learning and its vast potential? Visit LEARNS.EDU.VN, your go-to platform for mastering AI and machine learning. Our comprehensive resources and expert guidance will help you navigate the complexities of SSL and apply it to solve real-world problems. Contact us at 123 Education Way, Learnville, CA 90210, United States or via Whatsapp at +1 555-555-1212. Start your learning journey with learns.edu.vn today!