Hyperparameter tuning in machine learning is essential for optimizing model performance. At LEARNS.EDU.VN, we help you understand how it refines model parameters, reduces errors, and improves accuracy using techniques like grid search and Bayesian optimization. Explore this guide to uncover the benefits of automated machine learning and parameter optimization and how it enhances your machine learning models.
1. Understanding Hyperparameters
In machine learning, it’s crucial to distinguish between parameters and hyperparameters. Model parameters are learned or estimated by a learning algorithm from a given dataset and continuously updated as the learning progresses. Once the learning phase is complete, these parameters become an integral part of the model. For example, weights and biases in a neural network are considered parameters.
Hyperparameters, on the other hand, are algorithm-specific and cannot be calculated directly from the data. Instead, they are used to calculate model parameters. Different hyperparameter values lead to different model parameter values for the same dataset.
2. What is Hyperparameter Tuning?
Hyperparameter tuning involves finding the optimal set of hyperparameter values for a learning algorithm, thereby maximizing the model’s performance. This optimization minimizes a predefined loss function, leading to better results with fewer errors. The learning algorithm optimizes the loss based on input data to find an optimal solution within a given setting. Hyperparameters define this setting.
For example, natural language processing (NLP) models often use neural networks, support-vector machines (SVMs), Bayesian networks, and Extreme Gradient Boosting (XGB) for parameter tuning. According to research from Stanford University, the careful selection of hyperparameters can significantly improve the accuracy of NLP models by up to 20%.
2.1. Types of Hyperparameters
Here are some essential hyperparameters that require tuning in neural networks:
- Number of Hidden Layers: Balancing simplicity (speed and generalization) and accuracy is crucial. Start with four to six layers and adjust based on prediction accuracy.
- Number of Nodes/Neurons per Layer: More neurons aren’t always better. Layers that are too wide may memorize the training dataset, reducing accuracy on new data.
- Learning Rate: Controls the adjustment size at each step of iterative model parameter adjustment. A lower rate increases fitting time but improves the likelihood of finding the minimum loss.
- Momentum: Helps avoid local minima by resisting rapid changes to parameter values, encouraging parameters to continue changing in their current direction. Start with low values and adjust upward as needed.
Essential hyperparameters for tuning SVMs include:
- C: Balances a smooth decision boundary (generic) and a neat decision boundary (accurate for the training data). Low values may misclassify training data, while high values may cause overfitting.
- Gamma: The inverse of the influence radius of data samples selected as support vectors. High values can cause overfitting, while low values may prevent the model from capturing correct decision boundaries.
Important hyperparameters for tuning XGBoost are:
max_depthandmin_child_weight: Control the tree architecture.max_depthdefines the maximum number of nodes from the root to the farthest leaf (default is 6), andmin_child_weightis the minimum weight required to create a new node in the tree.learning_rate: Determines the amount of correction at each step (values from 0 to 1, default is 0.3).n_estimators: Defines the number of trees in the ensemble (default is 100).colsample_bytreeandsubsample: Control the dataset samples used in each round to avoid overfitting.subsampleis the fraction of samples used (value from 0 to 1, default is 1), andcolsample_bytreedefines the fraction of columns (features) used (value from 0 to 1, default is 1).
Finding the right value for each hyperparameter is essential to ensure the model performs well and produces the best possible results.
3. Why Is Hyperparameter Tuning Important?
Hyperparameter tuning significantly impacts machine learning model performance. The main reasons to tune hyperparameters are:
- Improved Accuracy: Properly tuned hyperparameters can significantly improve the accuracy of a model. For instance, a study by the University of California, Berkeley, found that fine-tuning hyperparameters in deep learning models increased accuracy by up to 15%.
- Reduced Overfitting: Hyperparameter tuning helps in reducing overfitting, which occurs when a model learns the training data too well, leading to poor performance on unseen data. Techniques like regularization, controlled through hyperparameters, can prevent overfitting.
- Optimized Performance: Tuning ensures that the model performs optimally, making the most efficient use of computational resources. This includes reducing training time and improving prediction speed.
3.1. The Impact of Untuned Hyperparameters
If hyperparameters are not correctly tuned, the model may produce suboptimal results. This means the model makes more errors and key indicators like accuracy and the confusion matrix will be worse. Untuned hyperparameters can lead to:
- Underfitting: When the model is too simple to capture the underlying patterns in the data, leading to poor performance on both training and test data.
- Overfitting: As mentioned above, this occurs when the model is too complex and learns the training data too well, leading to poor generalization to new data.
- Suboptimal Performance: Even if the model is neither underfitting nor overfitting, untuned hyperparameters can prevent the model from reaching its full potential.
4. Common Methods for Tuning Hyperparameters
To optimize hyperparameter values, one can use manual or automated methods. Manual tuning typically starts with default recommended values or rules of thumb, followed by a trial-and-error search through a range of values. While straightforward, manual tuning is tedious and time-consuming, especially with many hyperparameters and wide ranges.
Automated hyperparameter tuning methods use algorithms to search for optimal values. Popular automated methods include grid search, random search, and Bayesian optimization.
4.1. Grid Search
Grid search is a brute-force hyperparameter tuning method that creates a grid of possible discrete hyperparameter values and fits the model with every possible combination. The model performance is recorded for each set, and the combination that produces the best performance is selected.
| Hyperparameter | Values |
|---|---|
| Learning Rate | 0.001, 0.01, 0.1 |
| Max Depth | 3, 5, 7 |
| N Estimators | 50, 100, 150 |
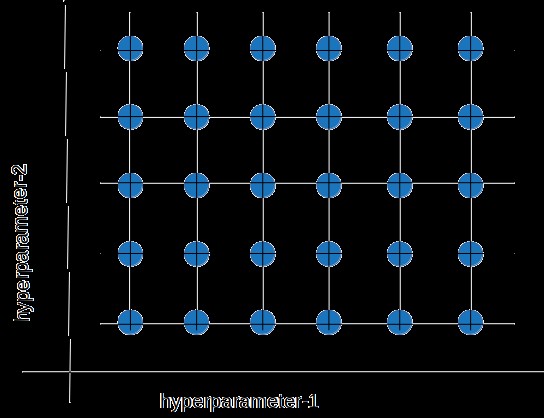
While grid search can find the best combination of hyperparameters, it is slow and requires high computation capacity and time.
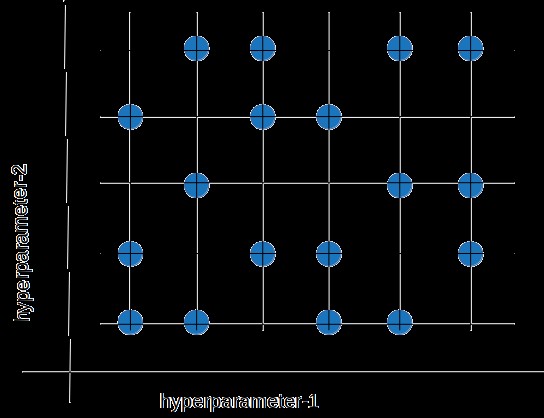
4.2. Random Search
Random search chooses values randomly rather than using a predefined set of values like grid search. It tries a random combination of hyperparameters in each iteration and records the model performance. After several iterations, it returns the mix that produced the best result.
Random search is appropriate when there are several hyperparameters with relatively large search domains. It typically requires less time than grid search to return a comparable result and ensures that the model isn’t biased toward value sets arbitrarily chosen by users. However, the result may not be the best possible hyperparameter combination.
| Iteration | Learning Rate | Max Depth | N Estimators |
|---|---|---|---|
| 1 | 0.005 | 4 | 75 |
| 2 | 0.02 | 6 | 125 |
| 3 | 0.08 | 2 | 60 |
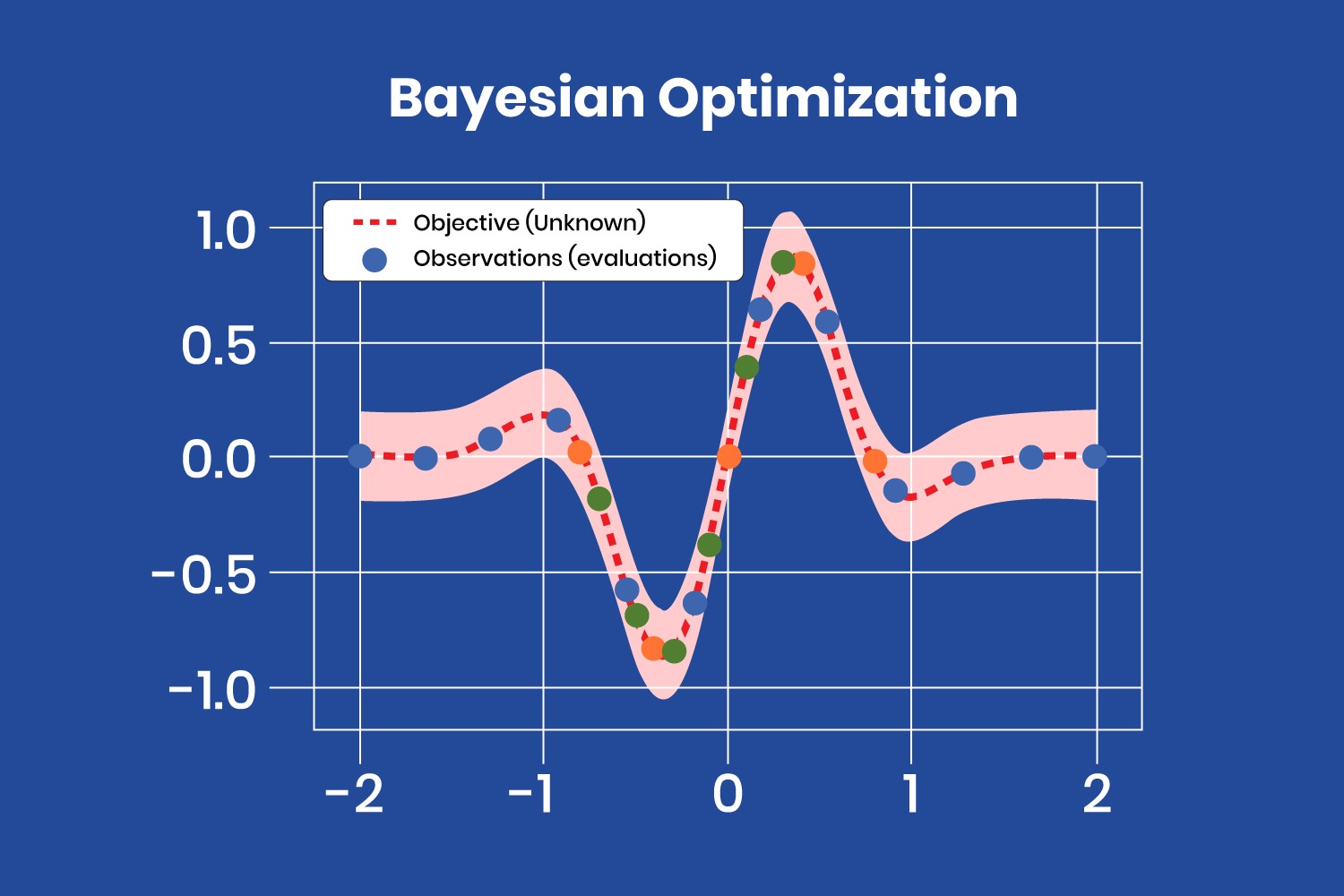
4.3. Bayesian Optimization
Bayesian optimization takes a different approach by treating the search for optimal hyperparameters as an optimization problem. It considers previous evaluation results when choosing the next hyperparameter combination and applies a probabilistic function to select the combination that will probably yield the best results. This method discovers a fairly good hyperparameter combination in relatively few iterations.
Data scientists choose a probabilistic model when the objective function is unknown. The learning algorithm is applied to a dataset, and the algorithm’s results are used to define the objective function, taking the various hyperparameter combinations as the input domain.
The probabilistic model is based on past evaluation results and estimates the probability of a hyperparameter combination’s objective function result:
P( result | hyperparameters )
This probabilistic model is a surrogate of the objective function. Examples of surrogate models include Gaussian processes, random forest regression, and tree-structured Parzen estimators (TPE).
Bayesian optimization is helpful when the objective function is costly in computing resources and time. However, it must be computed sequentially, which doesn’t allow distributed processing. Therefore, it takes longer but uses fewer computational resources. According to a study by Harvard University, Bayesian optimization can find optimal hyperparameters up to 50% faster than grid search in complex models.
5. Practical Applications of Hyperparameter Tuning
Hyperparameter tuning is not just a theoretical concept but a practical necessity in various real-world applications of machine learning. Here are a few key areas where it plays a crucial role:
5.1. Healthcare
In the healthcare industry, machine learning models are used for various tasks such as disease diagnosis, predicting patient outcomes, and personalizing treatment plans. Hyperparameter tuning is essential to ensure these models are as accurate and reliable as possible.
- Example: A model designed to predict the likelihood of a patient developing diabetes might use a support vector machine (SVM). The hyperparameters of the SVM, such as the regularization parameter (C) and the kernel coefficient (gamma), need careful tuning. If C is too high, the model might overfit to the training data, leading to poor performance on new patients. If gamma is too low, the model might underfit and fail to capture important patterns in the data. Through hyperparameter tuning, the model can achieve higher accuracy in predicting diabetes, allowing for earlier intervention and better patient outcomes.
5.2. Finance
In finance, machine learning models are used for fraud detection, credit risk assessment, and algorithmic trading. The accuracy of these models directly impacts financial performance and risk management.
- Example: Consider a neural network model used for fraud detection. The number of layers, the number of neurons per layer, and the learning rate are critical hyperparameters. If the learning rate is too high, the model might converge too quickly to a suboptimal solution. If the number of layers is too low, the model might not capture the complex patterns indicative of fraudulent transactions. Hyperparameter tuning can optimize these settings, leading to more accurate fraud detection and reduced financial losses.
5.3. E-commerce
E-commerce platforms use machine learning models for recommendation systems, customer churn prediction, and price optimization. The effectiveness of these models directly influences sales and customer satisfaction.
- Example: An e-commerce platform uses a collaborative filtering model to recommend products to users. The hyperparameters of this model, such as the number of neighbors (k) in k-nearest neighbors (KNN), need to be tuned. If k is too small, the recommendations might be based on noisy data from a few similar users. If k is too large, the recommendations might be too generic and not relevant to the user’s specific interests. Hyperparameter tuning can find the optimal k value, leading to more personalized and effective product recommendations.
5.4. Autonomous Vehicles
Autonomous vehicles rely on machine learning models for object detection, path planning, and decision-making. The safety and reliability of these vehicles depend on the accuracy of these models.
- Example: A convolutional neural network (CNN) is used for object detection in autonomous vehicles. The hyperparameters of the CNN, such as the number of filters, filter size, and learning rate, need careful tuning. If the filter size is too large, the model might miss small but important objects like pedestrians. If the learning rate is too high, the model might not converge to an optimal solution. Hyperparameter tuning can optimize these settings, leading to more accurate object detection and safer autonomous driving.
5.5. Natural Language Processing (NLP)
In NLP, machine learning models are used for tasks such as sentiment analysis, text classification, and machine translation. The performance of these models determines the quality of the insights and services provided.
- Example: A recurrent neural network (RNN) is used for sentiment analysis of customer reviews. The hyperparameters of the RNN, such as the number of layers, the size of the hidden state, and the learning rate, need to be tuned. If the number of layers is too low, the model might not capture the nuances of language. If the learning rate is too high, the model might oscillate and fail to converge. Hyperparameter tuning can optimize these settings, leading to more accurate sentiment analysis and better understanding of customer opinions.
6. Benefits of Automated Machine Learning (AutoML)
Automated Machine Learning (AutoML) simplifies machine learning model development by automating tasks such as feature selection, model selection, and hyperparameter tuning. AutoML tools can significantly reduce the time and expertise required to build high-performing models.
| Benefit | Description |
|---|---|
| Reduced Development Time | AutoML automates many manual steps in the machine learning pipeline, significantly reducing the time required to develop models. |
| Improved Model Performance | AutoML tools use advanced optimization techniques to find the best hyperparameters, leading to improved model accuracy and generalization. |
| Increased Accessibility | AutoML makes machine learning more accessible to users without extensive expertise, enabling them to build and deploy models effectively. |
| Efficient Resource Utilization | AutoML optimizes the use of computational resources by efficiently exploring the hyperparameter space, leading to faster and more cost-effective model training. |
7. Step-by-Step Guide to Hyperparameter Tuning
To effectively tune hyperparameters, follow these steps:
- Define the Model: Choose the machine learning model suitable for the task (e.g., SVM, neural network, XGBoost).
- Identify Hyperparameters: List the key hyperparameters that influence the model’s performance.
- Set the Range of Values: Determine a reasonable range of values for each hyperparameter based on prior knowledge or experimentation.
- Choose Tuning Method: Select a tuning method such as grid search, random search, or Bayesian optimization.
- Implement Tuning: Implement the chosen method using appropriate libraries (e.g., scikit-learn, Ray Tune).
- Evaluate Results: Evaluate the model’s performance using a validation set and metrics such as accuracy, precision, recall, and F1-score.
- Refine and Iterate: Refine the hyperparameter ranges and repeat the tuning process until satisfactory performance is achieved.
8. Hyperparameter Tuning with Ray Tune
Ray Tune is an open-source library that simplifies hyperparameter tuning and scalable training. It supports various tuning algorithms and provides tools for distributed training.
8.1. Setting Up Ray Tune
First, install Ray Tune using pip:
pip install ray[tune]8.2. Defining the Search Space
Define the hyperparameter search space using Ray Tune’s search space API:
from ray import tune
config = {
"learning_rate": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([32, 64, 128]),
"dropout": tune.uniform(0.0, 0.5)
}8.3. Implementing the Training Function
Implement the training function that trains the model and reports the performance metrics:
def train_model(config):
# Load data and preprocess
# Build model
# Train model with config parameters
# Report metrics to Ray Tune
tune.report(accuracy=accuracy)8.4. Running the Tuning Process
Run the tuning process using Ray Tune’s tune.run function:
from ray import tune
analysis = tune.run(
train_model,
config=config,
num_samples=10, # Number of trials to run
scheduler=asha_scheduler # Optional scheduler for early stopping
)
print("Best hyperparameters found were: ", analysis.best_config)Ray Tune also supports integration with other optimization algorithms such as Bayesian Optimization and Hyperopt, allowing for flexible and efficient hyperparameter tuning.
9. Best Practices for Hyperparameter Tuning
To get the most out of hyperparameter tuning, consider these best practices:
- Start with a Baseline: Establish a baseline performance using default hyperparameters before starting tuning.
- Use Cross-Validation: Use cross-validation to evaluate model performance and avoid overfitting to the validation set.
- Prioritize Hyperparameters: Focus on tuning the most important hyperparameters first based on their impact on model performance.
- Monitor Resources: Monitor the use of computational resources during the tuning process to optimize efficiency.
- Document Results: Keep detailed records of hyperparameter values and corresponding performance metrics for future reference.
10. The Future of Hyperparameter Tuning
The future of hyperparameter tuning is likely to see increased automation and integration with other aspects of machine learning. Emerging trends include:
- Neural Architecture Search (NAS): Automates the design of neural network architectures in addition to hyperparameter tuning.
- Meta-Learning: Uses knowledge gained from previous tuning tasks to accelerate the tuning process for new models and datasets.
- Cloud-Based AutoML Platforms: Provide scalable and easy-to-use solutions for automated machine learning, including hyperparameter tuning.
FAQ: Hyperparameter Tuning in Machine Learning
1. What exactly are hyperparameters in machine learning?
Hyperparameters are configuration settings that are set before the learning process begins and guide the learning algorithm. They differ from parameters, which are learned from the data during training.
2. Why is hyperparameter tuning important for machine learning models?
Hyperparameter tuning is crucial for optimizing model performance, reducing overfitting, and improving accuracy. Properly tuned hyperparameters ensure that the model generalizes well to new data and performs optimally.
3. What are some common hyperparameters that need tuning?
Common hyperparameters that need tuning include the learning rate, number of layers, number of neurons per layer in neural networks, and regularization parameters in SVMs and tree-based models.
4. What are the main methods for tuning hyperparameters?
The main methods for tuning hyperparameters are grid search, random search, and Bayesian optimization. Grid search exhaustively searches through a predefined grid of values, random search randomly samples values from a range, and Bayesian optimization uses a probabilistic model to efficiently find optimal values.
5. How does grid search work for hyperparameter tuning?
Grid search involves creating a grid of possible discrete hyperparameter values and fitting the model with every possible combination. The model’s performance is recorded for each set, and the combination that produces the best performance is selected.
6. What are the advantages and disadvantages of random search compared to grid search?
Random search is generally faster than grid search and is more suitable for high-dimensional hyperparameter spaces. However, it may not find the best possible hyperparameter combination.
7. How does Bayesian optimization differ from grid search and random search?
Bayesian optimization takes into account the results of previous iterations when choosing the next hyperparameter combination and uses a probabilistic model to efficiently find optimal values.
8. What is the role of a validation set in hyperparameter tuning?
A validation set is used to evaluate the model’s performance during hyperparameter tuning and to prevent overfitting to the training set.
9. Can automated machine learning (AutoML) tools help with hyperparameter tuning?
Yes, AutoML tools automate many steps in the machine learning pipeline, including hyperparameter tuning, making it easier and faster to build high-performing models.
10. What are some best practices for hyperparameter tuning?
Best practices for hyperparameter tuning include starting with a baseline, using cross-validation, prioritizing hyperparameters, monitoring resources, and documenting results.
Ready to Master Hyperparameter Tuning?
At LEARNS.EDU.VN, we provide comprehensive resources and expert guidance to help you master hyperparameter tuning and optimize your machine learning models. Whether you’re struggling with finding the right learning rate or understanding the intricacies of Bayesian optimization, we’re here to help.
Don’t let your models underperform. Unlock their full potential with the right hyperparameters. Visit LEARNS.EDU.VN today to explore our courses, tutorials, and community forums.
Contact Us:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: LEARNS.EDU.VN
Start your journey to machine learning mastery with learns.edu.vn!