Underfitting in machine learning occurs when your model isn’t complex enough to capture the underlying patterns in your data, leading to poor performance. At LEARNS.EDU.VN, we help you understand this crucial concept, learn to identify it, and implement effective strategies to avoid it. Master underfitting and enhance your model performance with our expert insights and actionable solutions, focusing on model complexity, feature engineering, and data quality.
1. Understanding Underfitting in Machine Learning
Underfitting happens when a machine learning model is too simplistic to effectively learn the underlying patterns present in the training data. This results in the model performing poorly not only on the training data itself but also on unseen or new data. In essence, an underfit model fails to capture the complexity inherent in the data, leading to inaccurate predictions and flawed decision-making.
1.1. Defining Underfitting
Underfitting can be visualized as trying to fit a straight line through a dataset that clearly follows a curved path. The model is too simple to represent the true relationships within the data. This is especially common when dealing with non-linear data or complex interactions between features. As a result, the model’s predictive accuracy is significantly compromised, and it cannot generalize well to new, unseen instances. LEARNS.EDU.VN provides resources to help you identify and address underfitting.
1.2. Key Indicators of Underfitting
Identifying underfitting early can save time and resources in the model development process. Key indicators of underfitting include:
- High Bias: The model makes strong assumptions about the data that are not accurate.
- Poor Performance on Training Data: The model fails to achieve a satisfactory level of accuracy on the data it was trained on.
- Similar Performance on Training and Test Data: The model performs equally poorly on both training and test datasets, indicating it hasn’t learned the underlying patterns.
- Simple Model Architecture: The model is too basic to capture the complexities of the data.
1.3. The Consequences of Underfitting
Underfitting leads to several detrimental consequences, affecting the reliability and utility of the machine learning model:
- Inaccurate Predictions: The primary outcome of underfitting is the model’s inability to make precise and dependable predictions.
- Poor Generalization: The model cannot generalize well to new, unseen data, limiting its practical application in real-world scenarios.
- Wasted Resources: Time and resources spent on developing an underfit model are effectively wasted since the model does not provide meaningful insights or results.
- Suboptimal Decision-Making: In business or critical applications, decisions based on an underfit model can lead to flawed strategies and adverse outcomes.
2. Causes of Underfitting
Several factors can contribute to underfitting in machine learning models. Understanding these causes is essential for developing models that accurately represent the underlying data.
2.1. Overly Simplified Models
The most common cause of underfitting is using a model that is too simple for the complexity of the data. Linear models applied to non-linear datasets often exhibit underfitting, as they cannot capture the curves and interactions present in the data.
- Linear Regression: Applying linear regression to data with non-linear relationships.
- Shallow Decision Trees: Using decision trees with limited depth, which cannot capture complex decision boundaries.
- Simple Neural Networks: Employing neural networks with too few layers or nodes, which lack the capacity to learn intricate patterns.
2.2. Insufficient Training Data
The amount of training data available significantly impacts a model’s ability to learn. If the dataset is too small or does not adequately represent the population, the model will likely underfit.
- Small Sample Size: A limited number of data points may not cover all possible scenarios or variations, leading to an incomplete understanding of the problem.
- Biased Sampling: If the training data is not representative of the real-world data, the model will learn skewed patterns that do not generalize well.
- Lack of Diversity: If the dataset lacks diversity, the model may fail to capture important nuances and variations in the data.
2.3. Poor Feature Selection
The features used to train a model are crucial in determining its performance. If the selected features are irrelevant, redundant, or do not capture the underlying patterns, the model is likely to underfit.
- Irrelevant Features: Including features that have no meaningful relationship with the target variable.
- Redundant Features: Using features that provide the same information, without adding new insights.
- Missing Important Features: Failing to include key variables that significantly influence the target variable.
2.4. Inadequate Model Training
Even with a suitable model architecture and sufficient data, underfitting can occur if the model is not trained adequately. This includes insufficient training iterations and inappropriate optimization techniques.
- Premature Stopping: Halting the training process too early, before the model has converged to an optimal solution.
- Suboptimal Learning Rate: Using a learning rate that is too high or too low, preventing the model from effectively learning the patterns in the data.
- Lack of Regularization: Failing to use regularization techniques to prevent overfitting can also indirectly lead to underfitting if the model is overly constrained.
3. Techniques to Prevent and Address Underfitting
Addressing underfitting involves increasing the complexity of the model, providing more relevant data, and optimizing the training process. Here are several effective techniques to prevent and address underfitting:
3.1. Increasing Model Complexity
One of the primary strategies to combat underfitting is to increase the complexity of the model. This allows the model to capture more intricate patterns in the data.
- Using More Complex Algorithms: Switching from simpler algorithms like linear regression to more complex ones such as polynomial regression, decision trees, or neural networks.
- Adding More Layers and Nodes in Neural Networks: For neural networks, increasing the number of layers and nodes allows the model to learn more complex representations.
- Increasing Depth of Decision Trees: Allowing decision trees to grow deeper, capturing more complex decision boundaries.
3.2. Enhancing Feature Engineering
Feature engineering involves selecting, transforming, and creating features that improve the model’s performance. Proper feature engineering can provide the model with more relevant information, reducing underfitting.
- Feature Selection: Carefully selecting the most relevant features for the model, excluding irrelevant or redundant ones.
- Feature Transformation: Applying transformations such as scaling, normalization, and encoding to make features more suitable for the model.
- Creating New Features: Deriving new features from existing ones that capture important relationships or patterns.
3.3. Augmenting Training Data
Increasing the amount of training data can significantly improve the model’s ability to generalize and reduce underfitting.
- Collecting More Data: Gathering additional data points to provide a more comprehensive representation of the problem.
- Data Augmentation: Creating new data points by applying transformations to existing data, such as rotations, translations, and scaling for images.
- Synthetic Data Generation: Generating synthetic data points using techniques like SMOTE (Synthetic Minority Over-sampling Technique) to balance class distributions.
3.4. Optimizing Model Training
Ensuring the model is trained adequately involves optimizing the training process, including adjusting the learning rate, increasing the number of iterations, and applying regularization techniques.
- Adjusting Learning Rate: Experimenting with different learning rates to find the optimal value that allows the model to converge effectively.
- Increasing Training Iterations: Training the model for a sufficient number of iterations to allow it to learn the underlying patterns in the data.
- Applying Regularization Techniques: Using techniques like L1 or L2 regularization to prevent overfitting, which can indirectly improve the model’s ability to capture relevant patterns.
3.5. Model Ensembling
Ensembling techniques involve combining multiple models to improve overall performance. Ensembling can reduce underfitting by leveraging the strengths of different models.
- Bagging: Training multiple instances of the same model on different subsets of the training data and averaging their predictions.
- Boosting: Training a sequence of models, where each model focuses on correcting the errors of the previous ones.
- Stacking: Combining multiple different models by training a meta-learner on their predictions.
4. Real-World Examples of Underfitting
To better understand the impact of underfitting, let’s explore real-world examples across various domains where models fail to capture the complexity of the data, leading to inaccurate predictions.
4.1. Healthcare: Predicting Disease Risk
In healthcare, machine learning models are used to predict the risk of various diseases based on patient data. If a model is underfit, it may fail to capture important risk factors, leading to inaccurate predictions.
- Scenario: A hospital develops a model to predict the risk of heart disease based on patient data, including age, gender, blood pressure, and cholesterol levels.
- Underfitting: If the model is too simple (e.g., a linear model), it may not capture the complex interactions between these factors, such as the non-linear relationship between age and heart disease risk.
- Consequences: The model may underestimate the risk for certain patients, leading to delayed or inadequate treatment.
4.2. Finance: Credit Risk Assessment
Financial institutions use machine learning models to assess the credit risk of loan applicants. An underfit model can lead to inaccurate risk assessments, resulting in financial losses.
- Scenario: A bank uses a model to predict the likelihood of loan default based on applicant data, including income, credit score, employment history, and debt-to-income ratio.
- Underfitting: If the model is too simple, it may not capture the complex relationships between these factors, such as the impact of employment history on loan repayment.
- Consequences: The model may approve loans for high-risk applicants, leading to increased default rates and financial losses for the bank.
4.3. Marketing: Customer Churn Prediction
In marketing, machine learning models are used to predict which customers are likely to churn (stop using a service). An underfit model can lead to missed opportunities to retain valuable customers.
- Scenario: A telecommunications company uses a model to predict customer churn based on usage data, customer demographics, and customer service interactions.
- Underfitting: If the model is too simple, it may not capture the complex factors influencing churn, such as the impact of service quality and pricing plans.
- Consequences: The company may fail to identify and proactively address the needs of at-risk customers, leading to increased churn rates and revenue loss.
4.4. Manufacturing: Predictive Maintenance
In manufacturing, machine learning models are used to predict when equipment is likely to fail, allowing for proactive maintenance. An underfit model can lead to missed maintenance opportunities, resulting in equipment downtime and production losses.
- Scenario: A manufacturing plant uses a model to predict equipment failure based on sensor data, maintenance history, and operating conditions.
- Underfitting: If the model is too simple, it may not capture the complex factors influencing equipment failure, such as the impact of temperature, vibration, and usage patterns.
- Consequences: The plant may fail to schedule maintenance proactively, leading to unexpected equipment failures and production downtime.
5. Underfitting vs. Overfitting
In machine learning, underfitting and overfitting are two common issues that can negatively affect a model’s ability to make accurate predictions. Understanding the difference between the two is crucial for building models that generalize well to new data.
5.1. Defining Overfitting
Overfitting occurs when a model learns the training data too well, capturing not only the underlying patterns but also the noise and irrelevant details. As a result, the model performs exceptionally well on the training data but poorly on new, unseen data. Overfitting leads to a model that is too complex and does not generalize well.
5.2. Key Differences
Here’s a table summarizing the key differences between underfitting and overfitting:
| Feature | Underfitting | Overfitting |
|---|---|---|
| Model Complexity | Too Simple | Too Complex |
| Training Performance | Poor | Excellent |
| Test Performance | Poor | Poor |
| Generalization | Poor | Poor |
| Cause | Lack of Model Complexity, Insufficient Data | Excessive Model Complexity, Noise in Data |
| Solution | Increase Complexity, Add Features, More Data | Reduce Complexity, Regularization, More Data |

5.3. Striking the Right Balance
The goal in machine learning is to strike the right balance between underfitting and overfitting, creating a model that generalizes well to new data. This is achieved through careful model selection, feature engineering, data augmentation, and regularization techniques. LEARNS.EDU.VN offers guidance on finding this balance.
- Model Selection: Choosing an algorithm and architecture that is appropriate for the complexity of the data.
- Feature Engineering: Selecting and transforming features that provide relevant information without introducing noise.
- Data Augmentation: Increasing the amount of training data to improve generalization.
- Regularization: Applying techniques to prevent the model from learning the noise in the training data.
6. Practical Steps to Detect Underfitting
Detecting underfitting early in the model development process can save time and resources. Here are practical steps to identify underfitting:
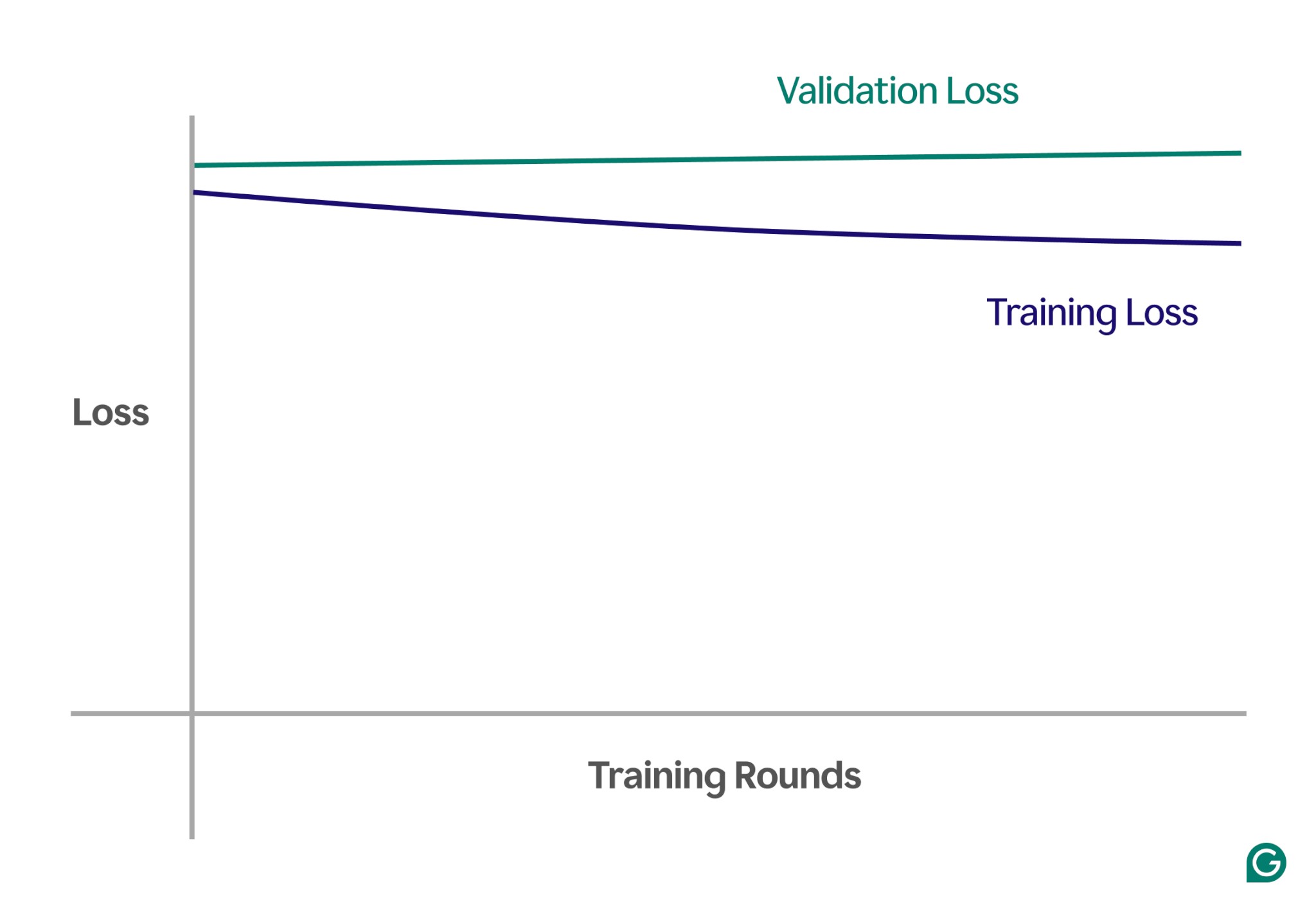
6.1. Analyze Learning Curves
Learning curves plot the model’s performance (typically loss or error) against the number of training iterations. Analyzing these curves can reveal whether the model is underfitting.
- High Training Loss: If the training loss remains high and plateaus early in the training process, it suggests the model is not learning from the data.
- High Validation Loss: If the validation loss is also high and similar to the training loss, it confirms the model is underfitting and not generalizing well.
- Small Gap Between Training and Validation Loss: A small gap indicates the model is not overfitting, but the high loss values suggest underfitting.
6.2. Evaluate Model Performance Metrics
Evaluate the model’s performance using appropriate metrics for the task, such as accuracy, precision, recall, and F1-score for classification, and mean squared error (MSE) and R-squared for regression.
- Low Accuracy: For classification tasks, low accuracy indicates the model is not correctly classifying instances.
- Low Precision and Recall: Low precision and recall suggest the model is not effectively identifying positive instances.
- High MSE: For regression tasks, high MSE indicates the model’s predictions are far from the actual values.
- Low R-Squared: Low R-squared suggests the model is not capturing the variance in the data.
6.3. Visualize Model Predictions
Visualizing the model’s predictions can provide insights into whether the model is underfitting.
- Regression: Plotting the predicted values against the actual values can reveal if the model is systematically under- or over-predicting.
- Classification: Visualizing decision boundaries can show if the model is failing to capture the complexity of the data.
6.4. Compare with Baseline Models
Compare the performance of the model with simple baseline models, such as a model that always predicts the mean or median value. If the model performs only slightly better than the baseline, it suggests the model is underfitting.
7. Advanced Techniques for Addressing Underfitting
Beyond the basic techniques, there are advanced methods that can be employed to address underfitting in machine learning models.
7.1. Complex Model Architectures
Utilizing more complex model architectures can help capture intricate patterns in the data.
- Deep Neural Networks: Using deep neural networks with multiple layers can learn complex hierarchical features.
- Convolutional Neural Networks (CNNs): Applying CNNs for image-related tasks can automatically learn relevant features from raw pixel data.
- Recurrent Neural Networks (RNNs): Using RNNs for sequence data can capture temporal dependencies and patterns.
7.2. Ensemble Learning with Diverse Models
Combining diverse models can leverage their individual strengths and reduce underfitting.
- Random Forests: Using random forests, which are an ensemble of decision trees, can provide robust and accurate predictions.
- Gradient Boosting Machines (GBMs): Applying GBMs, which combine weak learners sequentially, can improve model performance.
- Stacking with Heterogeneous Models: Stacking different types of models, such as neural networks and decision trees, can capture different aspects of the data.
7.3. Advanced Feature Engineering
Employing advanced feature engineering techniques can provide the model with more informative features.
- Polynomial Features: Creating polynomial features can capture non-linear relationships between variables.
- Interaction Features: Generating interaction features can capture the combined effect of multiple variables.
- Domain-Specific Features: Incorporating features based on domain knowledge can provide the model with relevant insights.
7.4. Transfer Learning
Leveraging pre-trained models through transfer learning can improve performance with limited data.
- Pre-trained Neural Networks: Using pre-trained neural networks on large datasets can provide a good starting point for learning complex patterns.
- Fine-Tuning: Fine-tuning the pre-trained models on specific tasks can adapt them to the data and reduce underfitting.
8. Case Studies
Examining case studies where underfitting was addressed can provide valuable insights into effective strategies.
8.1. Case Study 1: Predicting Customer Satisfaction
A company aimed to predict customer satisfaction using a simple linear regression model based on customer demographics and purchase history. The model performed poorly, indicating underfitting.
- Problem: The linear model was too simple to capture the complex factors influencing customer satisfaction.
- Solution: The company switched to a more complex model, a random forest, and incorporated additional features, such as customer service interactions and product reviews.
- Results: The random forest model significantly improved prediction accuracy, allowing the company to identify and address the needs of dissatisfied customers.
8.2. Case Study 2: Predicting Stock Prices
A financial firm attempted to predict stock prices using a simple time series model based on historical prices. The model failed to capture the volatility and trends in the market, resulting in underfitting.
- Problem: The simple time series model was inadequate to capture the complex dynamics of stock prices.
- Solution: The firm switched to a more advanced model, a recurrent neural network (RNN), and incorporated additional features, such as economic indicators and news sentiment.
- Results: The RNN model significantly improved prediction accuracy, enabling the firm to make more informed trading decisions.
9. Best Practices
Implementing best practices in machine learning model development can help prevent underfitting and ensure optimal performance.
9.1. Thorough Data Exploration
Conduct a thorough exploration of the data to understand its characteristics, patterns, and relationships.
- Data Visualization: Use visualizations, such as histograms, scatter plots, and box plots, to gain insights into the data.
- Statistical Analysis: Perform statistical analysis to identify correlations, distributions, and outliers.
9.2. Iterative Model Development
Follow an iterative model development process, continuously evaluating and refining the model based on performance metrics.
- Start Simple: Begin with a simple model and gradually increase complexity as needed.
- Regular Evaluation: Regularly evaluate the model’s performance on validation data and adjust the model accordingly.
9.3. Continuous Monitoring
Continuously monitor the model’s performance in production to detect and address any issues, including underfitting.
- Performance Tracking: Track key performance metrics over time to identify any degradation in performance.
- Retraining: Retrain the model periodically with new data to ensure it remains accurate and relevant.
10. Conclusion: Mastering Model Performance
Underfitting is a common challenge in machine learning that can significantly impact model performance. By understanding the causes of underfitting, implementing effective techniques to prevent and address it, and following best practices in model development, you can build models that accurately represent the underlying data and generalize well to new, unseen instances. LEARNS.EDU.VN is your partner in mastering these techniques.
10.1. Key Takeaways
- Underfitting occurs when a model is too simple to capture the underlying patterns in the data.
- Common causes of underfitting include overly simplified models, insufficient training data, poor feature selection, and inadequate model training.
- Techniques to prevent and address underfitting include increasing model complexity, enhancing feature engineering, augmenting training data, and optimizing model training.
- Real-world examples of underfitting highlight the impact of inaccurate predictions in various domains.
- Detecting underfitting involves analyzing learning curves, evaluating model performance metrics, visualizing model predictions, and comparing with baseline models.
10.2. Embrace Lifelong Learning
As the field of machine learning continues to evolve, it’s essential to embrace lifelong learning and stay updated with the latest techniques and best practices. LEARNS.EDU.VN provides the resources and support you need to excel in this dynamic field.
10.3. Call to Action
Ready to take your machine learning skills to the next level? Visit LEARNS.EDU.VN today to explore our comprehensive courses, tutorials, and resources. Whether you’re a beginner or an experienced practitioner, we have something to help you master the art of machine learning and build high-performing models.
Discover the power of effective learning with LEARNS.EDU.VN. Your journey to becoming a machine learning expert starts here.
Contact us:
- Address: 123 Education Way, Learnville, CA 90210, United States
- WhatsApp: +1 555-555-1212
- Website: learns.edu.vn
FAQ: Addressing Your Questions About Underfitting
Q1: What is underfitting in machine learning?
Underfitting occurs when a machine learning model is too simple to capture the underlying patterns in the training data, leading to poor performance on both the training and test data.
Q2: What are the main causes of underfitting?
The main causes of underfitting include overly simplified models, insufficient training data, poor feature selection, and inadequate model training.
Q3: How can I detect underfitting in my model?
You can detect underfitting by analyzing learning curves, evaluating model performance metrics, visualizing model predictions, and comparing with baseline models.
Q4: What are some techniques to prevent underfitting?
Techniques to prevent underfitting include increasing model complexity, enhancing feature engineering, augmenting training data, and optimizing model training.
Q5: How does increasing model complexity help prevent underfitting?
Increasing model complexity allows the model to capture more intricate patterns in the data, reducing the likelihood of underfitting.
Q6: What is the role of feature engineering in addressing underfitting?
Feature engineering involves selecting, transforming, and creating features that improve the model’s performance, providing the model with more relevant information and reducing underfitting.
Q7: How does data augmentation help in preventing underfitting?
Data augmentation involves creating new data points by applying transformations to existing data, providing the model with a more comprehensive representation of the problem and reducing underfitting.
Q8: What is model ensembling, and how does it help with underfitting?
Model ensembling involves combining multiple models to improve overall performance. It can reduce underfitting by leveraging the strengths of different models.
Q9: Can transfer learning help in addressing underfitting?
Yes, transfer learning, which involves leveraging pre-trained models, can improve performance with limited data and help in addressing underfitting.
Q10: What are some best practices to prevent underfitting in machine learning model development?
Best practices include thorough data exploration, iterative model development, and continuous monitoring to ensure optimal model performance and prevent underfitting.