The remarkable ability of humans to learn new tasks from just a few examples is a cornerstone of human intelligence. This capability is something we strive to replicate in artificial intelligence. Large language models (LLMs) have shown exciting progress, particularly in performing complex reasoning tasks through in-context learning. However, these models are still overly sensitive to prompt variations, suggesting their reasoning isn’t as robust as we’d like. They often require extensive prompt engineering and can exhibit puzzling behaviors, such as being unaffected by incorrect labels in prompts. This highlights a gap in their ability to truly understand and generalize from limited examples.
In the quest to bridge this gap, the innovative approach of Learning Symbol tuning has emerged. This method, detailed in the research paper “Symbol tuning improves in-context learning in language models”, introduces a simple yet effective fine-tuning procedure. Symbol tuning enhances in-context learning by strategically emphasizing the crucial input–label mappings. Extensive experiments across various Flan-PaLM models demonstrate the broad benefits of this technique in diverse scenarios.
- Robustness and Generalization: Symbol tuning significantly improves performance on novel in-context learning tasks and makes models far more resilient to underspecified prompts. This includes prompts lacking explicit instructions or natural language labels, pushing the models to truly learn from examples.
- Algorithmic Reasoning Prowess: Models fine-tuned with symbol learning exhibit a marked improvement in algorithmic reasoning tasks, showcasing a deeper understanding of patterns and relationships.
- Overriding Prior Knowledge: Symbol-tuned models demonstrate a greater ability to adapt to new information presented in-context, even when it contradicts pre-existing knowledge. This is evident in their improved performance with flipped labels, indicating a more flexible and context-aware learning process.
| Overview of Symbol Tuning: Fine-tuning models using tasks where natural language labels are replaced with arbitrary symbols to enhance in-context learning. |
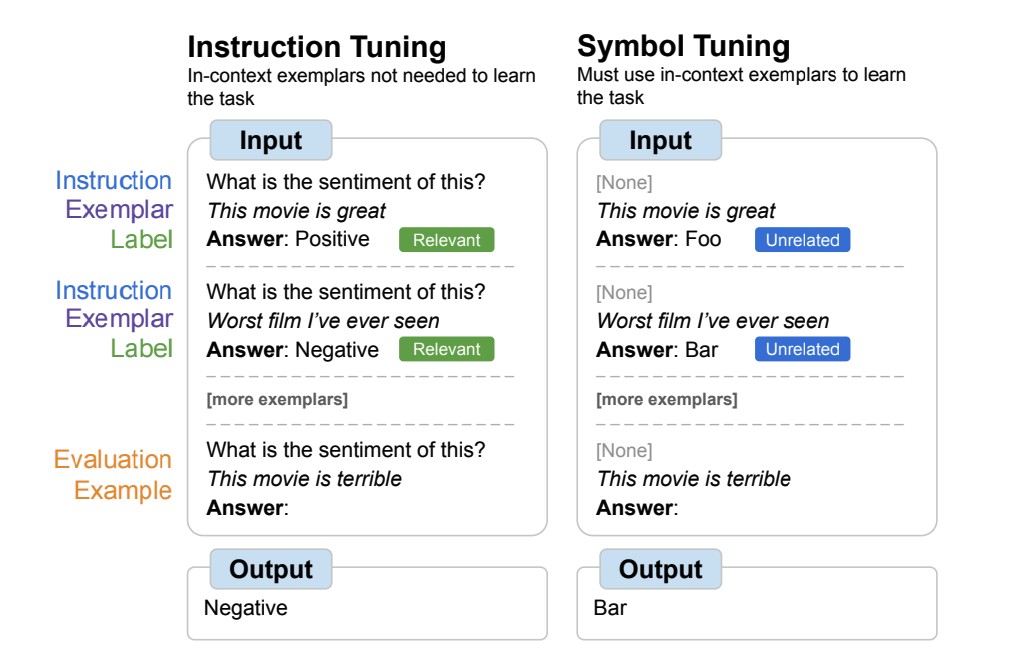



The Motivation Behind Symbol Learning
Instruction tuning has become a widely adopted fine-tuning technique, known for boosting model performance and improving their ability to follow in-context examples. However, a key limitation of traditional instruction tuning is that it doesn’t necessarily force models to deeply engage with the provided examples. This is because the task is often redundantly defined through both instructions and natural language labels within the evaluation prompt. Consider sentiment analysis, as illustrated in the figure below on the left. While examples can guide the model, they aren’t strictly essential; the model could potentially disregard them and simply rely on the instruction to determine the task.
Symbol tuning directly addresses this redundancy. It fine-tunes models on examples where explicit instructions are removed, and crucially, natural language labels are replaced with arbitrary, semantically unrelated symbols (like “Foo,” “Bar,” or even random characters). In this novel setup, the task becomes inherently ambiguous without careful examination of the in-context examples. Referring to the right side of the figure below, deciphering the task requires the model to process and learn from multiple in-context examples. By compelling the model to reason based on these examples, symbol learning cultivates enhanced performance in tasks that demand robust reasoning between in-context examples and their corresponding labels. This method truly emphasizes learning symbol representations to understand the task.
| Contrasting Instruction Tuning and Symbol Tuning: Symbol tuning removes instructions and replaces natural language labels with symbols, forcing models to learn from in-context examples. |
The Symbol-Tuning Procedure: A Deep Dive
To implement symbol tuning, researchers carefully selected 22 publicly available natural language processing (NLP) datasets. These datasets, widely used in prior research, were chosen to represent classification-type tasks, as the method necessitates discrete labels. The core of the procedure lies in remapping the original labels to a random selection from a large set of approximately 30,000 arbitrary symbols. These symbols were drawn from three distinct categories: integers, character combinations, and words, ensuring a diverse and semantically neutral set of labels.
The experiments focused on fine-tuning Flan-PaLM models, specifically the instruction-tuned variants of PaLM. Three different model sizes were utilized: Flan-PaLM-8B, Flan-PaLM-62B, and the largest Flan-PaLM-540B. Additionally, Flan-cont-PaLM-62B (denoted as 62B-c), a variant trained on 1.3 trillion tokens compared to the standard 780 billion tokens, was also included in the study. This comprehensive setup allowed for a thorough evaluation of symbol tuning across various model scales and training regimes. The use of these diverse symbols is key to forcing the models to focus on learning symbol relationships rather than relying on pre-existing semantic knowledge associated with natural language labels.
| Categories of Arbitrary Symbols: Integers, character combinations, and words, used for remapping labels in symbol tuning. |
Experimental Setup for Unseen Tasks
A crucial aspect of the experimental design was to rigorously evaluate the models’ generalization ability to unseen tasks. Therefore, the evaluation process deliberately excluded tasks used in either symbol tuning (the 22 datasets) or instruction tuning (1,800 tasks). To ensure a fair and unbiased assessment, 11 NLP datasets, completely independent of the fine-tuning datasets, were carefully selected for evaluation. This stringent approach guaranteed that the observed performance gains were not due to overfitting to the training data, but rather reflected a genuine improvement in the models’ ability to perform in-context learning on novel tasks.
In-Context Learning: Unveiling the Benefits of Symbol Tuning
The symbol-tuning procedure is fundamentally designed to force models to learn how to reason effectively with in-context examples. By removing instructions and replacing meaningful labels with arbitrary symbols, the prompts are intentionally crafted to make it impossible for models to rely on pre-existing knowledge or simple label associations. Success in these tasks hinges on the model’s ability to discern patterns and relationships directly from the provided in-context examples and their symbolic labels. Consequently, symbol-tuned models are expected to excel in scenarios where tasks are inherently ambiguous and require deep reasoning between in-context examples and their corresponding labels.
To thoroughly investigate these capabilities, four distinct in-context learning settings were defined. These settings systematically varied the level of reasoning required between inputs and labels, based on the presence or absence of instructions and relevant natural language labels. This nuanced approach allowed researchers to pinpoint exactly how symbol tuning impacts model performance across a spectrum of task complexities, particularly in situations where learning symbol relationships is paramount.
| In-Context Learning Settings: Varying availability of instructions and natural language labels to assess reasoning requirements. |
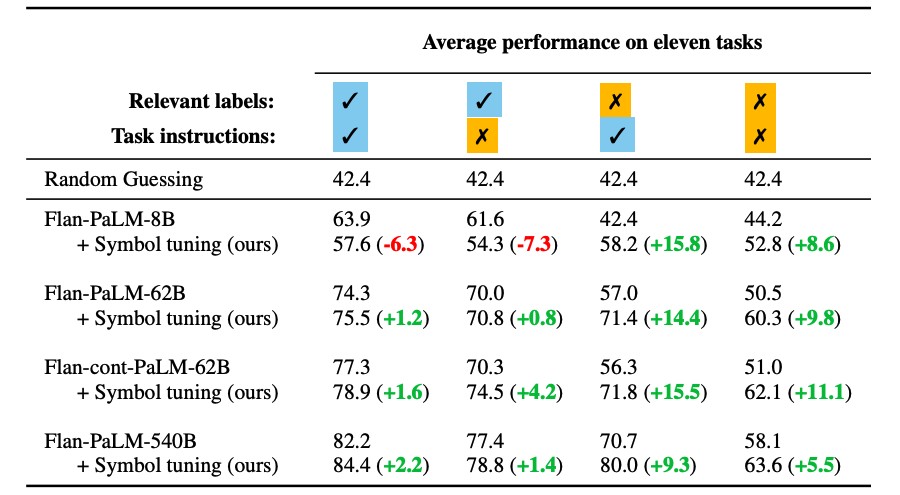
The results were striking. Symbol tuning consistently improved performance across all settings for larger models (62B and above). While modest improvements were observed in settings with relevant natural language labels (+0.8% to +4.2%), the gains were substantial in settings where these labels were absent (+5.5% to +15.5%). Most notably, when relevant labels were unavailable, the symbol-tuned Flan-PaLM-8B surprisingly outperformed the significantly larger Flan-PaLM-62B. Furthermore, the symbol-tuned Flan-PaLM-62B surpassed the even larger Flan-PaLM-540B in performance. This remarkable finding suggests that symbol tuning empowers smaller models to achieve performance levels comparable to much larger models in these challenging tasks, potentially leading to a significant reduction in computational resources required for inference (up to 10x).
| In-Context Learning Performance Comparison: Symbol-tuned models show significant improvements, especially when relevant labels are unavailable. |
Algorithmic Reasoning: Unlocking Deeper Understanding
The investigation extended to algorithmic reasoning tasks drawn from the BIG-Bench benchmark. These tasks fall into two main categories:
- List functions: Identifying the transformation function (e.g., removing the last element) applied between input and output lists of non-negative integers.
- Simple Turing concepts: Reasoning with binary strings to deduce the underlying concept mapping inputs to outputs (e.g., swapping 0s and 1s within a string).
Across both list function and simple Turing concept tasks, symbol tuning yielded impressive average performance improvements of 18.2% and 15.3%, respectively. Notably, the symbol-tuned Flan-cont-PaLM-62B outperformed the Flan-PaLM-540B on list function tasks, again demonstrating a potential 10x reduction in inference compute. These substantial improvements underscore symbol tuning’s effectiveness in enhancing a model’s capacity for in-context learning in unseen task types, particularly considering that the symbol-tuning procedure itself did not incorporate any numerical or algorithmic data. The focus on learning symbol mappings generalized to improved algorithmic understanding.
| Algorithmic Reasoning Task Performance: Symbol-tuned models outperform baselines on list function and simple Turing concept tasks. |
Flipped Labels: Enhancing Adaptability and Overriding Bias
In the flipped-label experiment, the labels of both in-context and evaluation examples were intentionally reversed. This creates a conflict between the model’s prior knowledge and the input-label mappings presented in the prompt (e.g., sentences with positive sentiment are labeled as “negative sentiment”). This setup provides a valuable way to assess whether models can effectively override their pre-existing biases and adapt to new, conflicting information provided in-context. Previous research has indicated that while pre-trained models (without instruction tuning) exhibit some ability to follow flipped labels, instruction tuning tends to diminish this capability.
The findings revealed a consistent trend across all model sizes: symbol-tuned models demonstrated a significantly enhanced ability to follow flipped labels compared to their instruction-tuned counterparts. After symbol tuning, Flan-PaLM-8B showed an average improvement of 26.5% across datasets, Flan-PaLM-62B improved by 33.7%, and Flan-PaLM-540B by 34.0%. Furthermore, symbol-tuned models achieved average performance levels that were comparable to or even better than pre-training-only models in this challenging scenario. This highlights the crucial role of learning symbol associations in enabling models to adapt to novel and potentially contradictory information.
| Flipped Label Experiment Results: Symbol-tuned models demonstrate superior ability to follow flipped labels compared to instruction-tuned models. |
Conclusion: The Power of Symbol Learning for In-Context Understanding
Symbol tuning presents a compelling new paradigm for fine-tuning language models. By training models on tasks where natural language labels are systematically replaced with arbitrary symbols, we encourage them to move beyond superficial pattern matching and delve deeper into understanding input–label mappings. The underlying principle is that when models are deprived of reliance on instructions or pre-defined label semantics, they are compelled to learn directly from the in-context examples themselves. Through extensive experiments on four language models using a diverse set of 22 datasets and approximately 30,000 arbitrary symbols, the effectiveness of symbol tuning has been clearly demonstrated.
The results unequivocally show that symbol tuning enhances performance on unseen in-context learning tasks, particularly in scenarios where prompts lack explicit instructions or relevant labels. Furthermore, symbol-tuned models exhibit remarkable improvements in algorithmic reasoning capabilities, despite the absence of algorithmic data in the tuning process. Finally, symbol tuning effectively restores the ability to follow flipped labels in in-context learning settings, a capability that is often diminished by traditional instruction tuning. This underscores the importance of learning symbol relationships for robust and adaptable language models.
Future Directions: Expanding the Horizons of Symbol Learning
The success of symbol tuning in enhancing in-context learning opens up exciting avenues for future research. The primary goal of symbol tuning is to amplify the extent to which models can meticulously examine and learn from input–label mappings during in-context learning. It is hoped that these findings will inspire further exploration into refining language models’ ability to reason over symbols presented in context, pushing the boundaries of AI’s reasoning capabilities and bringing us closer to truly human-like learning.
Acknowledgements
The authors of this post are now part of Google DeepMind. This work was conducted by Jerry Wei, Le Hou, Andrew Lampinen, Xiangning Chen, Da Huang, Yi Tay, Xinyun Chen, Yifeng Lu, Denny Zhou, Tengyu Ma, and Quoc V. Le. We would like to thank our colleagues at Google Research and Google DeepMind for their advice and helpful discussions.
