Introduction
Human learning is a complex process, underpinned by a symphony of cognitive systems working in harmony. Among these, reinforcement learning (RL) and working memory (WM) stand out as critical players, each contributing uniquely to how we acquire and retain knowledge. Everyday decisions, from choosing our breakfast to navigating a new route, rely on our ability to learn from feedback and remember relevant information. While RL incrementally builds knowledge through repeated experiences, WM offers a rapid, albeit capacity-limited, system for holding and manipulating information. This article delves into the fascinating interplay between these two systems, focusing on how the cognitive load imposed by working memory demands paradoxically impacts the robustness of long-term learning, specifically exploring Learning That A Stimulus Predicts Another Stimulus within the context of stimulus-response associations.
Traditional reinforcement learning models emphasize a gradual accumulation of value for stimulus-action pairs over time. This system excels in stable environments but can be slow to adapt to new contingencies. Working memory, on the other hand, allows for rapid learning of new, arbitrary associations by actively maintaining representations of relevant stimulus-action links. This is particularly beneficial in the initial stages of learning, as highlighted by research from Yoo and Collins (2021). WM provides a readily accessible space to store and process stimulus-action mappings, facilitating value-based learning and decision-making. However, WM is not without its limitations. Its capacity is finite, and when overloaded, it becomes susceptible to interference and information decay, as Oberauer et al. (2016) have shown. Collins and Frank’s (2012) work further emphasizes this capacity constraint, demonstrating that while WM aids early learning, its effectiveness is bounded by its limited resources. In contrast, the RL system, with its broader capacity and resilience to interference, becomes increasingly dominant as learning progresses and reward contingencies stabilize. Prior studies have indeed observed a shift in reliance from WM to RL as learning unfolds (Collins and Frank, 2012, 2018).
Furthermore, research increasingly points towards an interactive, rather than modular, relationship between WM and RL (Collins et al., 2017a, b; Collins, 2018; Collins and Frank, 2018). Functional MRI (fMRI) and electroencephalography (EEG) studies have provided compelling evidence for this cooperative interaction. When stimulus-reward information is actively held in WM, neural indices of reward prediction errors (RPEs) – the signals that drive RL – are diminished (Collins et al., 2017a; Collins and Frank, 2018). Conversely, and intriguingly, higher WM load conditions result in larger RPEs, leading to accelerated neural learning curves. This suggests that despite behavioral learning being slowed by WM limitations, the RL system might be strengthened under high WM load conditions, potentially leading to more robust long-term retention. This counterintuitive notion is supported by surprise memory tests where participants demonstrated better retention for stimulus-response contingencies and their associated reward values when learned under higher WM demands compared to lower ones (Collins et al., 2017b; Collins, 2018; Wimmer and Poldrack, 2022). However, previous investigations into this phenomenon had limitations.
Firstly, studies demonstrating enhanced retention of stimulus-response associations often compared only low and high WM load conditions (Collins, 2018), revealing subtle performance differences. To address this, we sought to parametrically manipulate WM demands, building on the methodology of Collins et al. (2017b), to rigorously test the hypothesis that retention of stimulus-response associations would improve monotonically with increasing WM load, even if initial learning was slower under these conditions. Secondly, while behavioral and neural findings have been documented separately, a direct link between cooperative neural interactions within WM/RL systems during learning and subsequent long-term retention remained to be established. Moreover, the nature of neural RL learning curves – whether they reflect learned reward expectations or learned policies – required further clarification in the context of different RL algorithms (Li and Daw, 2011; Jaskir and Frank, 2023). Therefore, we aimed to directly investigate these relationships by recording EEG activity during learning and subsequently administering two retention tests. Our goal was to determine if EEG measures of RL could predict participants’ ability to retrieve learned reward expectations and, crucially, the retention of stimulus-response contingencies.
As a secondary objective, we explored the influence of acute stress on RL and WM processes. Accumulating evidence across various learning domains indicates that acute stress can impair goal-directed decision-making and alter prefrontal cortex function (Arnsten, 2009), promoting a shift from flexible, cognitively demanding systems to more rigid, simpler systems (Kim et al., 2001; Schwabe and Wolf, 2009; Vogel et al., 2016; Wirz et al., 2018; Meier et al., 2022). We hypothesized that stress might diminish WM’s effectiveness in guiding learning, thereby amplifying the relative contribution of RL processing. By investigating these questions, we aim to provide a more nuanced understanding of the dynamic interaction between WM and RL and how cognitive load, and potentially stress, sculpts the balance between immediate learning and long-term retention of learned associations, particularly in the context of learning that a stimulus predicts another stimulus in guiding behavior.
Materials and Methods
Participants
Eighty-six healthy volunteers, comprising 43 women and 43 men, aged between 18 and 34 years (mean age = 24.56, SD = 3.84), participated in this study. All participants were right-handed, possessed normal or corrected-to-normal vision, and were screened to ensure they had no contraindications for EEG recording. Individuals with pre-existing medical conditions, current medication use, or a history of neurological or psychiatric disorders were excluded. Prior to participation, all volunteers provided written informed consent, and they received modest financial compensation for their time. The study protocol received ethical approval from the ethics committee of the Faculty of Psychology and Human Movement Sciences at the University of Hamburg.
Experimental Procedure
Learning Task
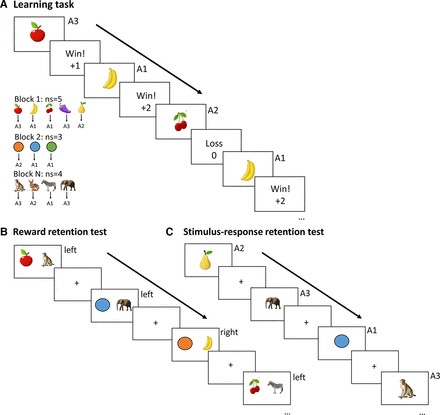
The interaction between RL and WM was assessed using the RLWM task, a paradigm previously established by Collins and Frank (2012, 2018) and Collins (2018). The task was programmed in MATLAB using the Psychophysics Toolbox. In this task (Fig. 1A), each trial began with a stimulus presentation centrally on a black screen. Participants were tasked with learning, through trial-and-error, which of three actions (key presses A1, A2, A3) to select in response to each stimulus, based on reward feedback. Stimulus presentation and response time were limited to 1.4 seconds. Incorrect choices resulted in zero reward feedback, while correct choices were rewarded with either 1 or 2 points, with fixed probabilities of 0.2, 0.5, or 0.8. Stimulus-probability assignments were counterbalanced across participants to ensure equal overall value across different set sizes (described below) and motor actions. Following the key press, audiovisual feedback was presented: “Win!” accompanied by an ascending tone for correct choices, or “Loss!” with a descending tone for incorrect choices. Participants who did not respond within 1.4 seconds received a “Too slow!” message. Feedback duration ranged from 0.4 to 0.8 seconds, followed by a fixation cross for 0.4 to 0.8 seconds before the onset of the next trial.
To manipulate WM load, the number of stimulus-action contingencies to be learned varied across blocks, ranging from one to five, denoted as ‘ns’ (not significant). A new set of stimuli (e.g., colors, fruits, or animals) was introduced in each block. The experiment comprised four blocks with a set size of 2, two blocks with a set size of 4, and three blocks each with set sizes of 1, 3, and 5, totaling 15 blocks and 645 trials. Within each block, each stimulus was presented 15 times. A total of 108 unique stimuli were used, with 43 stimuli presented to each participant. Stimulus category assignment to block set size was counterbalanced across participants. Block order was also counterbalanced, with the exception of set size 1 blocks, which served as control conditions and were fixed at block numbers 8 and 14.
Participants received the following instructions: “In this experiment, you will see an image on the screen. You need to respond to each image by pressing one of the three buttons on the Gamepad: 1, 2, or 3 with your right hand. Your goal is to figure out which button makes you win for each image. You will have a few seconds to respond. Please respond to every image as quickly and accurately as possible. If you do not respond, the trial will be counted as a loss. If you select the correct button, you will gain points. You can gain either 1 or 2 points designated as ‘$’ or ‘$$’. Some images will give you more points for correct answers on average than other images. You can only gain points when you select the correct button for each image. At the beginning of each block, you will be shown the set of images for that block. Take some time to identify them correctly. Note the following important rules: There is ONLY ONE correct response for each image. One response button MAY be correct for multiple images, or not be correct for any image. Within each block, the correct response for each image will not change.”
Test Phase
Following the learning phase, participants completed two surprise test phases (Fig. 1B, C). The first was a reward retention test, previously utilized in Collins et al. (2017b). This test assessed whether participants learned expected values by default, consistent with earlier findings showing that individuals can make choices based on relative expected values even when only required to identify the best option (Frank et al., 2007; Palminteri et al., 2015). In each trial of the reward retention test, participants were presented with a pair of stimuli, both encountered during the learning phase, and were asked to select the stimulus they perceived to be more rewarding. Stimulus pairs were pseudorandomly selected to sample across all combinations of set sizes, blocks, and reward probabilities. To prevent new learning during this phase, no feedback was provided. Importantly, this test required participants to use novel response mappings to indicate their choice, preventing them from relying on learned stimulus-response policies. Success in this task depended on the successful integration of probabilistic reward magnitude history for each stimulus acquired during the learning phase.
The second test was the stimulus-response retention test, designed to evaluate participants’ memory for the correct action associated with each learned stimulus. Each stimulus from the learning phase (excluding stimuli from blocks 1 and 15 to minimize primacy and recency effects) was presented individually four times. Participants were instructed to press the key they believed to be associated with the presented stimulus. Stimulus order was pseudorandomized to ensure even distribution across the test phase. No feedback was given to prevent new learning. Given that this test followed the reward retention test and multiple learning blocks, it is unlikely that participants could rely on WM for previously encountered stimuli. Therefore, performance on this test primarily reflected the retention of stimulus-action associations, representing the learned policy as formalized by the RL system (Collins, 2018; Jaskir and Frank, 2023).
Behavioral Data Analysis
Statistical analyses were conducted using R software (https://www.r-project.org/) and the lme4 package (version 1.1–26; Bates et al., 2015). Data were analyzed using generalized mixed-effect models (glmer) with a binomial family function. To balance Type I error control with statistical power, a parsimonious mixed-model approach was employed (Matuschek et al., 2017). The random-effects structure was determined by retaining only variance components supported by the data, using singular value decomposition (Bates et al., 2015; Matuschek et al., 2017).
Behavioral Analysis of Learning Task
To quantify the relative contributions of RL and WM to learning performance, trial-by-trial data from 86 participants were analyzed using generalized mixed-effect regression. The proportion of correct responses was modeled as a function of WM and RL variables and their interactions. WM variables included ‘setSize’ (number of stimulus-response associations to be learned) and ‘delay’ (number of intervening trials since the last presentation of a stimulus and a correct response, reflecting WM interference or maintenance time). The RL variable was ‘Pcor’ (total number of previous correct responses for a stimulus). Participants and all predictors were included as random variables.
Behavioral Analysis of the Reward Retention Test
To assess the impact of WM load on expected value learning, test performance (proportion of selecting the right stimulus in each pair) was analyzed using generalized mixed-effect regression. Predictor variables included: ‘delta_Q’ (value difference, positive when the right stimulus had higher value, negative otherwise); ‘mean value (Q)’ (mean Q value of the stimulus pair); ‘mean_setSize’ (mean set size of the stimulus pair); ‘delta_ setSize’ (set size difference, positive when the right stimulus was learned in a higher set size); ‘block’ (block number in which stimuli were learned, indicating recency); and ‘perseveration’ (binary coding of response repetitions). Participants, the effect of value difference (‘delta_Q’), and set size difference (‘delta_setSize’) were included as random variables.
Behavioral Analysis of the Reward Retention Test with EEG RL Index
A revised regression model for reward retention test data (including only the 77 participants with EEG data) incorporated the difference in EEG RL index between stimulus pairs. Since the neural RL index could be positive or negative, all difference score predictors were taken as absolute values, and the model predicted performance accuracy (proportion of choosing the higher value stimulus). Accuracy was analyzed as a function of ‘abs_delta_Q’ (absolute model-estimated value difference), ‘abs_delta_EEG_RL’ (absolute difference in EEG RL index), ‘mean Q value’, ‘mean set size’, ‘abs_delta_block’ (absolute block number difference), and ‘perseveration’. Participants, value difference (‘abs_delta_Q’), and EEG RL index difference (‘abs_delta_EEG_RL’) were random variables.
Behavioral Analysis of the Stimulus-Response Retention Test
Stimulus-response retention test accuracy (correctly recalling the response for a presented stimulus) was analyzed using generalized mixed-effect regression. Predictors included ‘set size’ (set size block of learning), ‘block’ (block number of learning, recency), ‘model Q’ (model-estimated Q value of each stimulus, average of final six learning iterations), and ‘perseveration’ (response repetition tendency). Interactions between ‘set size’ and ‘model Q’, ‘set size’ and ‘block’, and ‘set size’ and ‘perseveration’ were also included. Participants and the ‘model Q’ × ‘set size’ interaction were random variables.
Behavioral Analysis of the Stimulus-Response Retention Test with EEG RL Index
The stimulus-response retention test regression model was extended (for the 77 EEG participants) to include ‘average EEG RL index’ for each stimulus-response association and the interaction between ‘EEG RL index’ and ‘set size’. Participants, ‘model Q’ × ‘set size’ interaction, and ‘EEG RL index’ × ‘set size’ interaction were random variables.
EEG Recording and Processing
EEG data were acquired during the learning task using a 64-channel BioSemi ActiveTwo system with sintered Ag/AgCl electrodes arranged according to the 10–20 system. The sampling rate was 2048 Hz, and signals were digitized using a 24-bit A/D converter. Additional electrodes monitored eye movements and were placed on mastoids. EEG data were re-referenced offline to a common average, and electrode impedances were maintained below 30 kΩ. EEGs and EOGs were amplified with a low cutoff frequency of 0.53 Hz.
EEG data processing utilized EEGLAB (Delorme and Makeig, 2004) and ERPLAB (Lopez-Calderon and Luck, 2014) toolboxes. Continuous EEG was bandpass filtered (0.5–20 Hz), downsampled to 125 Hz, and segmented into epochs (-500 ms to +3000 ms relative to stimulus onset). Epochs with non-blink artifacts were manually removed. Independent components analysis (ICA) was performed on scalp electrodes using EEGLAB’s runica algorithm to remove blink and oculomotor artifacts (average 1.6 components removed per participant). Automated artifact detection (100 µV threshold, 200 ms window, 100 ms step) followed by manual verification was used to identify and interpolate bad electrodes and remove artifactual trials. Nine participants were excluded from EEG analyses due to high artifact rates (>40% in any condition), resulting in 77 participants for EEG analysis.
Data Processing for Behavior and EEG Regression Analysis
Omission trials, trials with reaction times (RTs) below 200 ms, and trials before the first correct response were excluded from all analyses. ‘Delay’ and ‘Pcor’ variables were set to a minimum of 1 for interpretable analysis (Collins and Frank, 2012). The ‘delay’ predictor was inverse transformed (-1/delay) to mitigate the disproportionate influence of rare, very long delays.
Modeling
RL and WM contributions to participant choices were estimated using the RLWM computational model, as described in Collins and Frank (2018). This model combines a standard RL module with a delta rule and a WM module with limited capacity and delay sensitivity. The RL module estimates expected values (Q) for stimulus-action associations and updates them incrementally based on reward history. The WM module rapidly updates stimulus-action-outcome associations within its capacity. Crucially, the model posits a cooperative interaction, where WM information influences RL prediction errors and learning (Fig. 2).
Basic RL Module
The model employs Q-learning for the model-free RL algorithm, consistent with prior studies. Reward values were coded as 0 or 1 (incorrect or correct). Q-values for stimulus ‘s’ and action ‘a’ associations were updated on each trial ‘t’ using the delta rule: Qt+1(s,a) = Qt(s,a) + α × δt.
The reward prediction error (δt) was calculated as the difference between observed reward ‘Rt’ and expected reward ‘Qt’: δt = Rt – Qt.
Choices were probabilistically determined using a softmax policy: p(a|s) = exp(βQ(s,a)) / Σ(exp(βQ(s,ai))).
‘α’ represents the learning rate, and ‘β’ is the inverse temperature parameter controlling choice determinism. Q-values were initialized to 1/nA (nA = 3, number of actions).
WM Module
This module updates stimulus-action-outcome associations in a single trial, assuming perfect retention within its capacity. When unconstrained by capacity and decay, it is represented by a Q-learning system with a learning rate of 1 (α = 1).
Decay
To account for potential forgetting due to delay or WM interference, a decay parameter ‘ϕ’ (0 < ϕ < 1) was introduced, pulling Q-value estimates towards their initial value (Q0 = 1/nA): Q ← Q + ϕ(Q0 – Q).
Only the WM module was subject to decay (parameter φWM) to reflect WM’s short-term stability compared to RL’s robustness.
WM Contribution to Choice
WM capacity is limited to ‘K’ stimulus-action associations. A constraint factor, ‘wWM’, represents the a priori probability of an item being in WM: wWM(0) = P0(WM) = K/ns (set size relative to capacity ‘K’). This probability is scaled by ‘ρ’ (0 < ρ < 1), reflecting participant’s WM vs. RL reliance: wWM(0) = ρ × min(1, K/ns).
Cooperative Model
The model assumes WM expectations influence RL updating. The RPE calculation is modified: δt = Rt – [wWM × QWM + (1 – wWM) × QRL].
This RPE updates RL Q-values: Qt+1 = Qt + α × δt. This interactive computation forms the basis for model predictions. However, for analysis, independent RL and WM modules were also fitted to assess deviations from independence, particularly in neural learning curves and retention.
Data Processing for Univariate EEG Analysis
To extract neural correlates of conditions of interest, a mass univariate approach was used (Collins and Frank, 2018). Multiple regression analysis was conducted for each participant, predicting EEG amplitude at each electrode and time point by ‘set size’, model-derived ‘Q value’, ‘delay’, and their interactions, controlling for reaction time (log-transformed) and trial number. EEG signal was windowed (-100 to +700 ms around stimulus onset), baseline corrected (-100 to 0 ms), and z-scored across trials. Predictors were also z-scored before robust multilinear regression (Collins and Frank, 2018).
Corrected ERPs
Corrected event-related potentials (ERPs) were generated by predicting voltage using the regression model, setting a single regressor to zero, and subtracting this predicted voltage from the true voltage. This isolates the variance explained by the regressor and residual noise. ERPs were averaged across trials within condition levels (Q-values divided into quartiles for plotting).
Trial-by-Trial Similarity Index of WM and RL
Spatiotemporal clusters (masks) for ‘set size’, ‘delay’, and ‘Q value’ predictors were identified using mass univariate regression and cluster-mass correction by permutation testing (threshold p < 0.001, 1000 permutations). Trial-level similarity measures were computed as the dot product between individual trial activity and these masks, yielding trial-wise indices of WM load, delay effects, and RL contributions. The EEG RL index used in retention test regressions was the average EEG RL index from the final six iterations of each stimulus.
Stress Manipulation
Testing occurred in the morning (8:00 AM to noon). Baseline blood pressure and salivary cortisol were measured. Participants completed the Multidimensional Mood State Questionnaire (Steyer et al., 1994) before and after treatment and after the learning task. Forty-two participants underwent the Socially Evaluated Cold Pressor Test (SECPT; Schwabe et al., 2008), a standardized stress protocol involving hand immersion in ice water (0–2°C) for 3 minutes with videotaping and experimenter evaluation. Forty-four participants served as a control group, immersing their hands in warm water (35–37°C) without videotaping or evaluation. Approximately 25 minutes post-treatment, participants received learning task instructions, completed a training session, and then performed the learning task and test phases 1 and 2. The total experiment duration was approximately 130 minutes.
Results
Consistent with prior research using this task (Collins et al., 2017b), our findings revealed distinct contributions of RL and WM systems to learning performance. The influence of incremental RL was evident in the increasing proportion of correct responses as blocks progressed (Fig. 3A) and with greater reward history [Pcor, β = 0.67, SE = 0.05, z(46926) = 13.17, p < 0.001]. WM’s role was highlighted by the significant impact of set size; lower set sizes yielded a higher proportion of correct responses compared to higher set sizes [set size, β = −0.28, SE = 0.05, z(46926) = −5.39, p < 0.001]. Learning curves were more gradual in higher set sizes (Fig. 3A) and learning was slower overall (Fig. 3B). Furthermore, performance declined with increased delay, particularly in larger set sizes [delay × ns, β = −0.09, SE = 0.05, z(46926) = −2.59, p = 0.009; Fig. 3C]. The relative contributions of WM diminished as learning advanced, as the detrimental effect of delay lessened with accumulated rewards [ns × Pcor, β = 0.13, SE = 0.04, z(46926) = 3.35, p < 0.001; delay × Pcor, β = 0.34, SE = 0.04, z(46926) = 9.17, p < 0.001; ns × delay × Pcor, β = 0.20, SE = 0.03, z(46 926) = 6.37, p < 0.001; Fig. 3D, E], indicating a transition from WM to RL dominance. These results collectively support the cooperative interaction model, where initial WM contributions decrease as RL becomes increasingly influential.
Behavioral Performance: Reward Retention Test
The reward retention test results mirrored previous findings (Collins et al., 2017b). Participants were more likely to select the stimulus associated with more frequent rewards during learning, as a function of reward difference [delta_Q, β = 0.41, SE = 0.04, z(19796) = 9.76, p < 0.001]. Replicating prior results, this value discrimination was enhanced for stimuli learned under higher set sizes [mean_setSize × delta_Q, β = 0.11, SE = 0.02, z(19796) = 6.04, p < 0.001]. Figure 4A illustrates this effect using a median split of absolute delta_Q scores. Conversely, participants were less likely to choose stimuli learned under higher set sizes [delta_setSize, β = −0.69, SE = 0.09, z(19796) = −7.61, p < 0.001], an effect previously attributed to a learned cost of mental effort in high WM load conditions (Collins et al., 2017b). Block number and its interaction with set size had no significant effect (p > 0.82). Response perseveration was also not significant (p > 0.69).
Behavioral Performance: Stimulus-Response Retention Test
Confirming the model’s key prediction, stimulus-response retention improved with increased WM load. Recall performance was significantly better for associations learned under high set sizes [set size, β = 0.84, SE = 0.05, z(11894) = 15.83, p < 0.001], and this effect was parametric across set size levels (Fig. 4B, C). This is particularly notable given the parametrically worse learning performance for higher set size items (compare Fig. 3A and Fig. 4C). As expected, recall accuracy was positively predicted by the estimated Q value of the stimulus-response association [model Q, β = 0.27, SE = 0.04, z(11 894) = 6.97, p < 0.001], indicating better retention for better-learned associations. Importantly, this effect was amplified in higher set sizes [model Q × set size, β = 0.15, SE = 0.04, z(11 894) = 3.64, p < 0.001; Fig. 4B]. Recency also influenced recall, with more recently learned associations recalled more accurately [block, β = 0.22, SE = 0.03, z(11894) = 8.61, p < 0.001], and this recency effect was stronger for higher set sizes [set size × block, β = 0.09, SE = 0.02, z(11894) = 4.13, p < 0.001]. No perseveration effect was observed (p > 0.11).
EEG Correlates of WM and RL During Learning
Model-based EEG analysis revealed significant effects for set size, delay, and RL. Replicating previous EEG findings (Collins and Frank, 2018), neural RL signals exhibited early frontal activity (~300 ms post-stimulus onset; Fig. 5) preceding parietal set size signals (peaking ~540 ms; Fig. 5), supporting early RL system engagement followed by cognitively demanding WM processing. RL signals also showed late temporal activity (~600 ms), overlapping with the set size effect. A significant frontal and parietal delay effect also emerged early at 300 ms.
To quantify WM modulation of neural RL, trial-by-trial EEG RL index was analyzed using linear regression. As expected, RL indices increased with reward history (Pcor, β = 0.17, t(38,377) = 34.77, p < 0.001). Crucially, and confirming model predictions, neural RL signals increased more with set size (Pcor × setSize, β = 0.04, t(38,377) = 7.53, p < 0.001; Fig. 4F), corroborating prior reports of enhanced RL computations under high set sizes due to reduced WM contributions and increased RPE accumulation (Collins et al., 2017b; Collins and Frank, 2018).
We then tested the core prediction that neural RL index relates to future retention. While no relationship was found for reward retention (abs_delta_EEG_RL, p = 0.65; mean_setSize × abs_delta_EEG_RL, p = 0.61; Fig. 4D), a clear relationship emerged for stimulus-response retention [EEG RL, β = 0.23, z(10613) = 4.51, p < 0.001; Fig. 4E]. Higher EEG RL index during learning predicted better stimulus-response recall, even after controlling for non-neural predictors. Figure 4E demonstrates that a high EEG RL index (median split) predicts better retention. The finding that neural RL index predicts policy retention but not reward retention is relevant to models differentiating between reward expectation and policy encoding in model-free RL. Behavioral reward retention analysis, controlling for neural predictors, replicated prior results: performance increased with absolute value differences [abs_delta_Q, β = 0.31, SE = 0.03, z(17743) = 8.82, p < 0.001], and improved with set size [mean_setSize, β = 0.07, SE = 0.02, z(17743) = 3.23, p = 0.001; Fig. 4D], although set size did not modulate the value difference effect (mean_setSize × abs_delta_Q, p = 0.63).
Acute Stress Modulation of RL and WM Interaction
Manipulation Check
Subjective, autonomic, and endocrine data confirmed successful stress induction by SECPT. SECPT was rated as significantly more unpleasant, stressful, painful, and difficult than the warm water control (all p < 0.001; Tables 1 and 2). Significant Treatment-by-Time interactions were observed for subjective stress ratings (negative mood, restlessness) and autonomic arousal (systolic and diastolic blood pressure, heart rate; all p < 0.001). Autonomic responses returned to baseline relatively quickly post-treatment (Fig. 6). Groups did not differ in pretreatment autonomic measures (all p > 0.07).
View this table:
Table 1.The mean and SD (in parentheses) of the ratings before and after the procedures are reported for the control group
View this table:
Table 2.The mean and SD (in parentheses) of the ratings before and after the procedures are reported for the stress group
ANOVA of salivary cortisol (sCORT) revealed a significant Time effect (F(3,234) = 28.53, p < 0.001) and a Treatment × Time interaction (F(3,234) = 6.97, p < 0.001), but no main Treatment effect (F(1,78) = 3.03, p = 0.08). The stress group showed higher sCORT levels immediately before learning (23 min post-treatment; t(78) = 2.80, p = 0.006), with marginal difference halfway through learning (50 min post-treatment; t(78) = 1.90, p = 0.06). No baseline or end-of-learning sCORT differences were observed (both p > 0.54), suggesting gradual stress-induced cortisol decline during learning (Fig. 6). Six participants were excluded from cortisol analysis due to insufficient saliva.
Learning Phase Performance by Stress Group
Regression analysis including stress group as a factor revealed a stress modulation of the Pcor × set size interaction [Pcor × set size × stress_group, β = −0.20, SE = 0.08, z(46926) = −2.60, p = 0.009] and Pcor × delay interaction [Pcor × delay × stress_group, β = 0.22, SE = 0.07, z(46 926) = 3.04, p = 0.002]. Follow-up analyses in control and stress groups separately showed that learning curves were additive to set size in the stress group (Pcor × set size, p = 0.74) but not in the control group [Pcor × set size, β = 0.22, SE = 0.05, z(24 031) = 4.30, p < 0.001], which exhibited a greater performance drop in high set sizes (Fig. 7A, B). Delay effect attenuation with learning was significant in both groups (both p < 0.001; Fig. 7C, D).
Reward Retention Test Performance by Stress Group
Reward retention test analysis including stress group revealed no stress effect (p > 0.15; Fig. 7E).
Stimulus-Response Retention Test Performance by Stress Group
Stimulus-response retention test analysis including stress group showed a set size × stress interaction [set size × stress_group, β = 0.22, SE = 0.10, z(11894) = 2.30, p = 0.02; Fig. 7F]. Follow-up analyses showed significant set size effects in both control [β = 0.72, SE = 0.07, z(6129)=10.72, p < 0.001] and stress groups [β = 0.95, SE = 0.08, z(5765) = 11.76, p < 0.001].
Discussion
Our findings provide significant insights into the intricate relationship between WM and RL during learning and their opposing effects on learning acquisition and retention of stimulus-response associations, specifically in the context of learning that a stimulus predicts another stimulus through reward feedback. Building upon a previously proposed cooperative WMRL model (Collins and Frank, 2018), which posits that RPEs are modulated by WM expectations, our results offer compelling evidence for the model’s key predictions. This model explained previous fMRI and EEG findings where neural RPEs were reduced under lower WM loads (Collins et al., 2017a; Collins and Frank, 2018) and predicted that larger WM expectation indices within a set size predicted subsequent RPEs (Collins and Frank, 2018). The model’s crucial prediction—enhanced RL processes under high WM load leading to more robust retention despite slower acquisition—is strongly supported by our data. Preliminary behavioral evidence existed (Collins, 2018), showing better retention in set size 6 compared to 3, but lacked neural validation. Our study provides multiple lines of evidence corroborating this claim.
Firstly, our behavioral and EEG results successfully replicated key findings from the RLWM task and subsequent memory tests. In the learning phase, we observed impaired acquisition with increasing set size and delay, yet the negative impact of delay diminished as learning progressed, supporting the model’s prediction of RL dominance over WM with accumulated reward experience. Secondly, at the neural level, we again observed that neural RL indices preceded WM-related processes during stimulus processing (Collins and Frank, 2018). Critically, we found robust evidence that EEG RL signals increased more rapidly across trials under high WM load (Fig. 4F), a core prediction of the cooperative model (Fig. 2), despite slower behavioral learning in these conditions.
Importantly, we demonstrated that associations learned under higher WM load exhibited parametrically improved recall accuracy in the stimulus-response retention test (Fig. 4C). This extends previous findings of retention benefits for high versus low set size learning (Collins, 2018), showing a parametric effect across five WM load levels. Notably, the most pronounced retention deficits occurred at the lowest set sizes, where participants could readily learn primarily through WM. Furthermore, we replicated reward retention test results (Collins et al., 2017b), showing differential sensitivity to reward proportions, which was enhanced by set size.
Finally, to elucidate the mechanisms underlying retention benefits, we utilized within-trial neural indexing of EEG dynamics. We showed that neural RL indices during acquisition predicted subsequent stimulus-response retention, even when controlling for set size. This strongly supports the model prediction that enhanced RL processing under high WM load drives improved policy retention when WM is no longer available. Conversely, neural RL indices did not predict reward retention test performance.
This dissociation aligns with theories and empirical studies suggesting that model-free learning in the brain directly learns stimulus-response policies using prediction errors from another system (actor-critic models; Collins and Frank, 2014; Klein et al., 2017; Jaskir and Frank, 2023). In this framework, the actor, responsible for policy selection, lacks direct access to reward values, only possessing response propensities for each stimulus. While participants could access critic values for stimulus comparison in the reward retention phase, they were not required to during learning. Indeed, participants showed above-chance performance in reward discrimination, albeit subtly (accuracy up to ~60%), whereas stimulus-response retention accuracy, directly assessing actor learning, was significantly higher (~80% for high set sizes), despite longer delays since learning.
For many simple RL tasks, distinguishing between value-learning and actor-critic algorithms is challenging, as both predict reward-maximizing action selection. However, theoretical and empirical evidence suggests that the human RL system aligns more closely with actor-critic predictions (Li and Daw, 2011; Gold et al., 2012; Collins and Frank, 2014; Klein et al., 2017; Geana et al., 2022; Jaskir and Frank, 2023). Our model fits also did not improve when allowing Q-learning to differentiate between 1-point and 2-point rewards, suggesting participants focused on maximizing task performance, effectively making Q-learning equivalent to an actor-critic at the task performance level. While Q-learners would minimally learn stimulus reward value in terms of correct response frequency, the EEG RL marker remained unrelated to reward retention performance, even when correct performance was defined as choosing the stimulus with a higher correct response proportion. Although our neural RL index cannot differentiate between EEG metrics of Q-values or actor weights, its predictive power for stimulus-response test performance, but not reward retention, provides initial support for the actor interpretation, where the neural RL index reflects policy rather than reward value.
While our primary focus was the RLWM mechanism’s impact on retention, we also investigated acute stress modulation of the WM/RL interaction. Stress is known to profoundly influence learning and decision-making (Starcke and Brand, 2012; Raio et al., 2017; Cremer et al., 2021). Stress-induced prefrontal cortex alterations can impair executive control (cognitive inhibition, task switching, WM maintenance; Schwabe et al., 2011; Schwabe and Wolf, 2011, 2012, 2012; Plessow et al., 2012; Hamilton and Brigman, 2015; Bogdanov and Schwabe, 2016; Vogel et al., 2016; Goldfarb et al., 2017; Brown et al., 2020). Conversely, stress can increase striatal dopamine activity (Vaessen et al., 2015), potentially enhancing WM updating (Goldfarb et al., 2017) and motor executive control (response inhibition; Schwabe and Wolf, 2012; Leong and Packard, 2014). We hypothesized that stress would shift the WM/RL trade-off, diminishing WM contribution and enhancing RL processing. However, our results showed only subtle differences between stress and control groups during learning and testing.
The 25-minute delay between stressor and learning task onset might have mitigated stress effects, as both noradrenaline and cortisol elevation may be necessary for stress-induced WM performance changes (Elzinga and Roelofs, 2005; Roozendaal, et al., 2006; Barsegyan et al., 2010). Alternatively, individuals with higher WM capacity might be more resilient to stress-induced cognitive impairments and less prone to habitual decision-making (Otto et al., 2013; Quaedflieg et al., 2019; Cremer et al., 2021). Future research should directly examine stress effects on WM/RL interactions, considering individual WM capacity.
In conclusion, our study enhances our understanding of the coupled WM/RL mechanism, which dynamically shifts between effortful WM and slower RL, each with distinct learning and retention characteristics. We provide trial-by-trial neural evidence for this trade-off during learning, demonstrating that greater RL reliance under WM degradation (high WM load) predicts superior long-term memory retention of stimulus-response associations. A compelling avenue for future research is exploring whether this system shift is strategic, modulated by individual preferences or abilities to prioritize immediate learning versus long-term retention. Furthermore, investigating how clinical populations with WM or RL impairments might exhibit altered flexibility in shifting between these systems, potentially leading to suboptimal reliance on one system over the other, even when disadvantageous, represents a crucial direction for future studies, particularly in understanding and addressing learning deficits in various conditions.
Footnotes
- This work was supported by Landesforschungsfoerdung Hamburg, Germany, Grant LFF FV 38 to L.S. and National Institutes of Health Grant R01 MH084840-08A1 to M.J.F.
- Correspondence should be addressed to Rachel Rac-Lubashevsky at rac.hunrachel{at}gmail.com
SfN exclusive license.