Machine learning (ML) is a dynamic field within Artificial Intelligence, empowering computers to learn from data and refine their performance over time without explicit programming. Essentially, ML algorithms enable systems to mimic human-like thinking and understanding by identifying patterns and insights from data.
This article delves into the essential types of machine learning, crucial for anyone looking to understand or work with this transformative technology. Machine learning systems are trained to learn from past data, improving their accuracy and efficiency in predicting outcomes and uncovering valuable opportunities from vast datasets.
Exploring the Core Types of Machine Learning
Machine learning encompasses several distinct types, each designed with specific functionalities and applications. The primary categories of machine learning algorithms are:
- Supervised Machine Learning
- Unsupervised Machine Learning
- Reinforcement Learning
Furthermore, Semi-Supervised Learning emerges as a hybrid approach, blending elements from both supervised and unsupervised methodologies to address unique data scenarios.
Types of Machine Learning Algorithms
1. Supervised Machine Learning: Learning with Labeled Data
Supervised learning is characterized by training models on “Labeled Datasets.” These datasets are structured with both input features and corresponding output labels. In essence, supervised learning algorithms learn to map the relationship between input data and the correct outputs. This process involves using labeled training and validation datasets to guide the learning process.
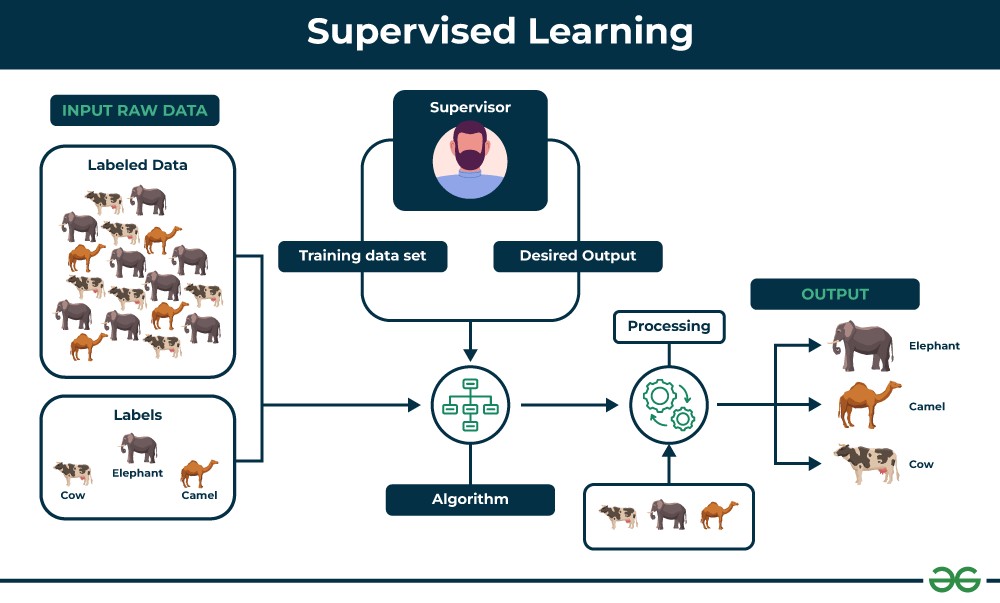 Supervised Learning Process
Supervised Learning Process
Alt text: Diagram illustrating the supervised learning process, showing labeled data input into a machine learning model, resulting in predictions and model training.
Let’s illustrate this with a practical example:
Example: Imagine you’re developing an image classifier to distinguish between images of cats and dogs. By feeding the algorithm a dataset of images where each image is labeled as either “cat” or “dog,” the machine learns to identify the distinguishing features of each animal. Subsequently, when presented with new, unseen images, the algorithm applies its learned knowledge to predict whether the image contains a cat or a dog. This is a classic example of supervised learning in action, specifically within image classification.
Supervised learning branches into two main categories:
Classification: Predicting Categories
Classification focuses on predicting categorical target variables, representing discrete classes or labels. Examples include classifying emails as “spam” or “not spam,” or diagnosing whether a patient has a high risk of heart disease (“yes” or “no”). Classification algorithms are designed to learn the boundaries that separate different classes based on input features.
Common Classification Algorithms:
- Logistic Regression
- Decision Trees
- Random Forests
- Support Vector Machines (SVM)
- Naive Bayes
- K-Nearest Neighbors (KNN)
Regression: Predicting Continuous Values
Regression, in contrast, deals with predicting continuous target variables, representing numerical values. Examples include predicting house prices based on size and location, or forecasting product sales figures. Regression algorithms aim to establish a relationship between input features and a continuous numerical output.
Common Regression Algorithms:
- Linear Regression
- Polynomial Regression
- Support Vector Regression (SVR)
- Decision Tree Regression
- Random Forest Regression
Advantages of Supervised Machine Learning
- High Accuracy: Supervised learning models often achieve high accuracy due to training on labeled data, which provides clear guidance during learning.
- Interpretability: The decision-making process in many supervised learning models is relatively interpretable, allowing users to understand how predictions are made.
- Pre-trained Models: The availability of pre-trained models can significantly reduce development time and resources for new applications.
Disadvantages of Supervised Machine Learning
- Limited Pattern Discovery: Supervised learning may struggle with identifying novel patterns not present in the training data.
- Labeled Data Dependency: It heavily relies on labeled data, which can be expensive, time-consuming, and sometimes difficult to obtain.
- Generalization Issues: Models may overfit the training data, leading to poor performance when generalizing to new, unseen data.
Applications of Supervised Learning
Supervised learning is widely applied across numerous domains:
- Image Classification: Identifying objects, faces, and scenes in images (e.g., medical image analysis, facial recognition).
- Natural Language Processing (NLP): Analyzing text for sentiment, entities, and relationships (e.g., sentiment analysis, text summarization).
- Speech Recognition: Converting spoken language to text (e.g., voice assistants, transcription services).
- Recommendation Systems: Providing personalized recommendations (e.g., product recommendations, movie suggestions).
- Predictive Analytics: Forecasting future outcomes (e.g., sales forecasting, demand prediction, risk assessment).
- Medical Diagnosis: Assisting in disease detection and diagnosis (e.g., cancer detection, disease risk prediction).
- Fraud Detection: Identifying fraudulent activities (e.g., credit card fraud detection, insurance fraud detection).
- Autonomous Vehicles: Enabling object recognition and decision-making in self-driving cars (e.g., pedestrian detection, lane keeping).
- Email Spam Detection: Filtering unwanted emails (e.g., spam filtering, phishing detection).
- Quality Control in Manufacturing: Inspecting products for defects (e.g., defect detection, anomaly detection).
- Credit Scoring: Assessing credit risk for loan applications (e.g., credit risk assessment, loan default prediction).
- Gaming: Developing intelligent game characters and analyzing player behavior (e.g., game AI, player behavior analysis).
- Customer Support: Automating customer service tasks (e.g., chatbots, virtual assistants).
- Weather Forecasting: Predicting weather conditions (e.g., temperature prediction, rainfall forecasting).
- Sports Analytics: Analyzing player performance and game strategies (e.g., player performance analysis, game outcome prediction).
2. Unsupervised Machine Learning: Discovering Patterns in Unlabeled Data
Unsupervised Learning is a machine learning approach where algorithms learn from unlabeled data to discover inherent patterns and relationships. Unlike supervised learning, there are no pre-defined output labels provided to guide the learning process. The primary objective of unsupervised learning is to uncover hidden structures, similarities, or groupings within the data, which can be leveraged for exploratory data analysis, visualization, dimensionality reduction, and more.
Alt text: Conceptual illustration of unsupervised learning, showing unlabeled data being processed by a machine learning model to discover hidden patterns and clusters.
Consider this example to understand unsupervised learning better:
Example: Imagine you have a dataset of customer purchase history at a retail store, without any pre-assigned customer segments. Using clustering algorithms, unsupervised learning can group customers with similar purchasing behaviors together. This can reveal distinct customer segments without prior labels, helping businesses target specific customer groups and identify outliers or anomalies in purchasing patterns.
Unsupervised learning primarily encompasses two major categories:
Clustering: Grouping Similar Data Points
Clustering involves grouping data points into clusters based on their similarity. This technique is valuable for identifying natural groupings and relationships within data without requiring labeled examples.
Common Clustering Algorithms:
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaussian Mixture Models (GMMs)
Association Rule Learning: Discovering Relationships
Association rule learning focuses on uncovering relationships between items in a dataset. It identifies rules indicating that the presence of certain items implies the presence of other items with a specific probability.
Common Association Rule Learning Algorithms:
- Apriori Algorithm
- Eclat Algorithm
- FP-Growth Algorithm
Advantages of Unsupervised Machine Learning
- Pattern Discovery: Unsupervised learning excels at discovering hidden patterns and complex relationships within data that might not be apparent through manual analysis.
- Versatile Applications: It’s well-suited for tasks like customer segmentation, anomaly detection, and exploratory data analysis, providing valuable insights from raw data.
- Reduced Data Labeling Effort: Eliminates the need for labeled data, significantly reducing the time and cost associated with data preparation.
Disadvantages of Unsupervised Machine Learning
- Output Quality Assessment: Without labels, it can be challenging to objectively assess the quality and accuracy of the model’s output.
- Cluster Interpretability: The resulting clusters may sometimes lack clear and meaningful interpretations, requiring domain expertise to derive actionable insights.
- Feature Extraction: While techniques like autoencoders and dimensionality reduction can extract meaningful features, they require careful tuning and may not always capture the most relevant information.
Applications of Unsupervised Learning
Unsupervised learning finds applications in various fields:
- Clustering: Customer segmentation, document clustering, image segmentation.
- Anomaly Detection: Fraud detection, network intrusion detection, equipment failure prediction.
- Dimensionality Reduction: Feature extraction, data compression, data visualization.
- Recommendation Systems: Content recommendation, personalized product suggestions, collaborative filtering.
- Topic Modeling: Document topic extraction, text summarization, understanding large text corpora.
- Density Estimation: Probability density estimation, outlier detection, data generation.
- Image and Video Compression: Reducing storage requirements for multimedia data.
- Data Preprocessing: Data cleaning, missing value imputation, data scaling and transformation.
- Market Basket Analysis: Product association analysis, cross-selling strategies, retail analytics.
- Genomic Data Analysis: Gene expression analysis, disease gene identification, bioinformatics research.
- Image Segmentation: Medical image analysis, object segmentation in images, autonomous driving.
- Community Detection in Social Networks: Social network analysis, identifying influential users, understanding social structures.
- Customer Behavior Analysis: Understanding customer preferences, personalized marketing, customer journey analysis.
- Content Recommendation: Tagging and classifying content, improving search relevance, content discovery platforms.
- Exploratory Data Analysis (EDA): Initial data exploration, hypothesis generation, gaining insights before specific task definition.
3. Reinforcement Machine Learning: Learning Through Interaction and Feedback
Reinforcement machine learning is a learning paradigm where an agent learns to interact with an environment by taking actions and receiving feedback in the form of rewards or penalties. Trial and error, coupled with delayed rewards, are defining characteristics of reinforcement learning. The model continuously improves its performance by learning optimal behaviors through reward feedback. These algorithms are often tailored to specific problems, such as training AI to play complex games (like AlphaGo) or developing self-driving car navigation systems.
.png)
Alt text: Diagram illustrating the reinforcement learning cycle, showing an agent interacting with an environment, taking actions, receiving rewards or penalties, and learning to optimize its behavior.
Let’s consider an example to understand reinforcement learning better:
Example: Imagine training an AI agent to play chess. The agent explores various moves within the game environment. For each move, it receives feedback: a positive reward for moves that lead to favorable positions or checkmate, and a negative reward (penalty) for moves that lead to disadvantage or loss. Through repeated trials and feedback, the agent learns to make strategic decisions that maximize its chances of winning. Reinforcement learning is particularly effective in scenarios where agents need to learn optimal strategies through interaction with their environment.
Reinforcement learning can be further categorized into:
Positive Reinforcement
- Provides rewards for desired actions, encouraging the agent to repeat those behaviors.
- Example: In training a dog, giving a treat when it sits on command reinforces the desired behavior. In a game, awarding points for correct answers encourages learning.
Negative Reinforcement
- Removes undesirable stimuli to encourage desired behaviors.
- Example: Turning off a loud buzzer when a lever is pressed correctly encourages the action of pressing the lever to stop the noise. Avoiding penalties by completing a task also falls under negative reinforcement.
Advantages of Reinforcement Machine Learning
- Autonomous Decision-Making: Reinforcement learning excels in tasks requiring sequences of decisions, such as robotics, game playing, and autonomous navigation.
- Long-Term Goal Achievement: It is particularly suitable for achieving long-term objectives that are difficult to define or achieve using conventional techniques.
- Complex Problem Solving: Reinforcement learning can tackle complex problems that are intractable with traditional programming approaches.
Disadvantages of Reinforcement Machine Learning
- Computational Cost: Training reinforcement learning agents can be computationally intensive and time-consuming, requiring significant resources.
- Overkill for Simple Problems: It’s often not the preferred approach for solving simple problems where simpler algorithms might suffice.
- Data and Computation Demands: Reinforcement learning typically requires vast amounts of data and computational power, making it potentially impractical and costly for some applications.
Applications of Reinforcement Machine Learning
Reinforcement learning is being applied across a growing range of applications:
- Game Playing: Mastering complex games like Go, Chess, and video games (e.g., AlphaGo, game AI development).
- Robotics: Robot control, navigation, manipulation tasks (e.g., autonomous robot navigation, robotic arm control).
- Autonomous Vehicles: Self-driving car navigation, decision-making in dynamic environments (e.g., lane keeping, traffic negotiation).
- Recommendation Systems: Optimizing recommendation algorithms based on user interaction and feedback (e.g., personalized recommendation engines).
- Healthcare: Optimizing treatment plans, drug discovery, personalized medicine (e.g., personalized treatment planning, drug dosage optimization).
- Natural Language Processing (NLP): Dialogue systems, chatbots, conversational AI (e.g., conversational agents, dialogue management).
- Finance and Trading: Algorithmic trading, portfolio optimization, risk management (e.g., automated trading systems, portfolio management).
- Supply Chain and Inventory Management: Optimizing supply chain operations, inventory control (e.g., supply chain optimization, inventory management).
- Energy Management: Optimizing energy consumption in buildings and grids (e.g., smart grid management, energy efficiency optimization).
- Game AI: Creating intelligent and adaptive non-player characters (NPCs) in video games (e.g., adaptive game AI, realistic NPC behavior).
- Adaptive Personal Assistants: Improving the responsiveness and personalization of personal assistants (e.g., personalized assistant behavior, context-aware assistance).
- Virtual Reality (VR) and Augmented Reality (AR): Creating immersive and interactive experiences (e.g., interactive VR environments, adaptive AR experiences).
- Industrial Control: Optimizing industrial processes and automation (e.g., process optimization, industrial automation).
- Education: Developing adaptive learning systems tailored to individual student needs (e.g., personalized learning platforms, adaptive tutoring systems).
- Agriculture: Optimizing agricultural operations, resource management in farming (e.g., precision agriculture, resource optimization in farming).
Semi-Supervised Learning: Bridging Supervised and Unsupervised Approaches
Semi-Supervised Learning represents a hybrid approach that falls between supervised and unsupervised learning. It leverages both labeled and unlabeled data for training. This technique is particularly valuable when labeled data is scarce, expensive to acquire, or time-consuming to annotate. Semi-supervised learning aims to improve model performance by utilizing the abundance of unlabeled data to enhance the learning process initiated by a smaller set of labeled examples.
Alt text: Diagram representing semi-supervised learning, showing the use of both labeled and unlabeled data to train a machine learning model, improving accuracy and efficiency.
Consider this example to understand the value of semi-supervised learning:
Example: In developing a language translation model, obtaining labeled translations for every sentence pair can be extremely resource-intensive. Semi-supervised learning allows models to learn from a combination of labeled translations (where available) and a larger pool of unlabeled sentence pairs in different languages. By leveraging the patterns in unlabeled text, the model can significantly improve translation accuracy and fluency, especially when labeled data is limited. This approach has been instrumental in advancing machine translation technologies.
Types of Semi-Supervised Learning Methods
Several semi-supervised learning methods exist, each with unique characteristics. Some common approaches include:
- Graph-based semi-supervised learning: Utilizes graph structures to represent relationships between data points, propagating labels from labeled to unlabeled points based on graph connectivity.
- Label propagation: Iteratively propagates labels from labeled data points to unlabeled points based on similarity metrics, effectively extending label information across the dataset.
- Co-training: Trains multiple machine learning models on different subsets of the data or features, with each model iteratively labeling data for the others, enhancing overall learning.
- Self-training: Trains a model initially on labeled data, then uses the model to predict labels for unlabeled data, iteratively retraining on the expanded dataset including its own predictions.
- Generative Adversarial Networks (GANs): Leverages GANs to generate synthetic data, which can be used in conjunction with labeled data to improve model generalization and performance, particularly in image and data augmentation tasks.
Advantages of Semi-Supervised Machine Learning
- Improved Generalization: Often leads to better model generalization compared to supervised learning alone, by leveraging the information present in unlabeled data.
- Broad Applicability: Can be applied to a wide range of data types and problem domains, particularly where labeled data is limited.
Disadvantages of Semi-Supervised Machine Learning
- Implementation Complexity: Semi-supervised methods can be more complex to implement and tune compared to purely supervised or unsupervised approaches.
- Labeled Data Requirement: Still requires some labeled data, which may not always be readily available or easy to obtain in certain scenarios.
- Unlabeled Data Impact: The quality and relevance of unlabeled data can significantly impact model performance, and noisy or irrelevant unlabeled data may degrade results.
Applications of Semi-Supervised Learning
Semi-supervised learning is effectively used in various applications:
- Image Classification and Object Recognition: Enhancing image recognition accuracy by combining limited labeled images with a larger pool of unlabeled images.
- Natural Language Processing (NLP): Improving language models and text classifiers by leveraging a small set of labeled text data with vast amounts of unlabeled text.
- Speech Recognition: Enhancing speech recognition accuracy by combining limited transcribed speech data with a larger set of unlabeled audio data.
- Recommendation Systems: Improving recommendation accuracy by supplementing sparse user-item interaction data with a wealth of unlabeled user behavior data.
- Healthcare and Medical Imaging: Enhancing medical image analysis by utilizing a small set of labeled medical images alongside a larger set of unlabeled images for tasks like disease detection and segmentation.
Explore further: Machine Learning Algorithms for a deeper dive into specific algorithms within these Machine Learning Types.
Conclusion
In conclusion, understanding the different types of machine learning is fundamental to harnessing the power of AI. Each type – supervised, unsupervised, reinforcement, and semi-supervised – offers unique capabilities and is suited to different problem domains. Machine learning continues to revolutionize industries, driving advancements in data prediction, automation, and intelligent systems across diverse sectors from healthcare to finance and beyond. As data continues to grow exponentially, the role of machine learning in extracting valuable insights and driving innovation will only become more critical.
Types of Machine Learning – FAQs
1. What are the challenges faced in supervised learning?
Key challenges in supervised learning include handling class imbalances, ensuring the quality and representativeness of labeled data, and mitigating overfitting to prevent poor performance on real-world, unseen data.
2. Where are common applications of supervised learning?
Supervised learning is widely applied in areas such as spam email analysis, image recognition systems, and sentiment analysis to understand public opinion and customer feedback.
3. What is the anticipated future outlook for machine learning?
The future of machine learning is projected to expand significantly, impacting fields like weather and climate analysis for improved forecasting, advancing healthcare systems for better diagnostics and treatments, and enabling more sophisticated autonomous systems across industries.
4. What are the primary classifications of machine learning?
The main types of machine learning are categorized into:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
5. What are some of the most frequently used machine learning algorithms?
Commonly used machine learning algorithms include:
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- K-Nearest Neighbors (KNN)
- Decision Trees
- Random Forests
- Artificial Neural Networks