Multi-Task Learning (MTL) is a powerful approach in machine learning, and by extension, education, where models learn multiple tasks simultaneously. This article, brought to you by LEARNS.EDU.VN, explores the depths of MTL, its benefits, and how it can revolutionize your approach to acquiring new skills and knowledge. Unlock your potential and discover the synergistic power of learning multiple tasks with representation sharing.
1. Understanding Multi-Task Learning (MTL)
Multi-Task Learning (MTL) is an approach to machine learning where multiple learning tasks are solved at the same time, while exploiting commonalities and differences across tasks. This can result in improved learning efficiency and prediction accuracy for the task-specific models, when compared to training models separately.
Imagine trying to learn several related subjects at once, such as physics and calculus. Instead of studying each subject in isolation, you might find that understanding the underlying mathematical principles enhances your grasp of physics concepts, and vice versa. This synergistic effect is at the heart of multi-task learning. The practice of concurrent task management enhances the primary task, leading to performance improvements and a deeper understanding.
1.1. Key Benefits of Multi-Task Learning
- Improved Generalization: By learning multiple tasks simultaneously, models are exposed to a wider range of data and learn more robust representations that generalize better to unseen examples.
- Increased Efficiency: Sharing representations between tasks reduces the number of parameters that need to be learned, leading to faster training times and lower memory requirements.
- Enhanced Feature Learning: MTL can help models discover and leverage features that are relevant to multiple tasks, leading to more informative and discriminative representations.
- Reduced Overfitting: By sharing information between tasks, MTL can help prevent overfitting, especially in scenarios where data is limited.
1.2. Multi-Task Learning vs. Single-Task Learning
| Feature | Multi-Task Learning | Single-Task Learning |
|---|---|---|
| Tasks | Multiple tasks learned simultaneously | One task learned at a time |
| Data | Leverages data from multiple related tasks | Uses data from only one task |
| Generalization | Improved generalization due to shared representations | Limited generalization; prone to overfitting |
| Efficiency | Increased efficiency due to parameter sharing | Lower efficiency; requires separate models for each task |
| Feature Learning | Enhanced feature learning; discovers common features | Limited feature learning; focuses only on features relevant to the specific task |
| Overfitting | Reduced overfitting due to shared information | Higher risk of overfitting, especially with limited data |
1.3. Origins and Evolution of Multi-Task Learning
The concept of Multi-Task Learning isn’t new. It has roots in psychological studies of human learning and skill acquisition. The idea that learning multiple related tasks can improve overall performance has been around for decades.
In the field of machine learning, Multi-Task Learning gained prominence in the 1990s, with early applications in areas like speech recognition and computer vision. However, the rise of deep learning has led to a resurgence of interest in Multi-Task Learning, as deep neural networks provide a powerful framework for sharing representations between tasks. As technology advances, new and improved techniques in Multi-Task Learning, representation learning, and knowledge sharing are constantly being developed.
2. How Multi-Task Learning Works
The core idea behind MTL is to train a single model to perform multiple tasks simultaneously. This is typically achieved by sharing some or all of the model’s parameters between tasks. By sharing parameters, the model can learn representations that are useful for multiple tasks, leading to improved generalization and efficiency.
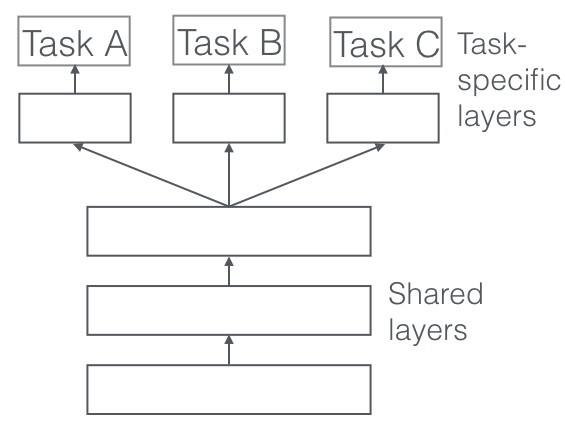
2.1. Hard Parameter Sharing
In hard parameter sharing, the hidden layers are shared across all tasks, while each task has its own task-specific output layer.
This approach is most effective when the tasks are closely related and share a significant amount of underlying structure.
Advantages:
- Reduces the risk of overfitting, especially when data is limited.
- Encourages the model to learn more general and robust representations.
- Increases efficiency by reducing the number of parameters that need to be learned.
Disadvantages:
- May not be suitable for tasks that are very different or have conflicting objectives.
- Can be difficult to optimize when tasks have different scales or distributions.
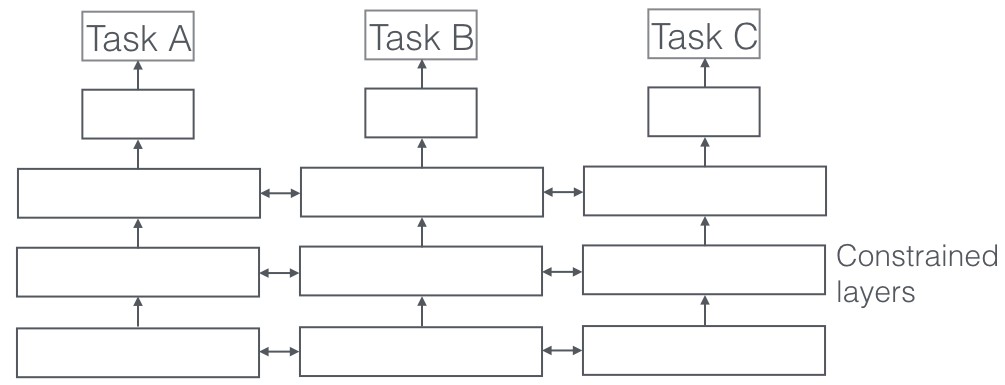
2.2. Soft Parameter Sharing
In soft parameter sharing, each task has its own model with its own parameters. However, the models are encouraged to be similar by adding a regularization term to the loss function that penalizes differences between the parameters.
This approach is more flexible than hard parameter sharing and can be used for tasks that are less closely related.
Advantages:
- More flexible than hard parameter sharing; can be used for a wider range of tasks.
- Allows each task to have its own specialized model, while still benefiting from knowledge transfer.
- Easier to optimize than hard parameter sharing, as each task has its own set of parameters.
Disadvantages:
- Less efficient than hard parameter sharing, as each task has its own model.
- Requires careful tuning of the regularization term to balance knowledge transfer and task-specific performance.
- May not be as effective as hard parameter sharing when tasks are very closely related.
2.3. Task Relationships and Weighting
One of the critical aspects of effective Multi-Task Learning is understanding the relationships between the tasks and appropriately weighting their contributions to the overall learning process.
- Positive Transfer: When learning one task improves the performance on another task.
- Negative Transfer: When learning one task hurts the performance on another task.
- Task Weighting: Assigning different weights to different tasks to balance their influence on the shared representations.
- Adaptive Weighting: Dynamically adjusting task weights during training based on task performance or uncertainty.
3. Why Multi-Task Learning Works: Underlying Mechanisms
The effectiveness of MTL can be attributed to several underlying mechanisms that contribute to improved generalization and efficiency.
3.1. Implicit Data Augmentation
MTL effectively increases the sample size that we are using for training our model. As all tasks are at least somewhat noisy, when training a model on some task (A), our aim is to learn a good representation for task (A) that ideally ignores the data-dependent noise and generalizes well. As different tasks have different noise patterns, a model that learns two tasks simultaneously is able to learn a more general representation. Learning just task (A) bears the risk of overfitting to task (A), while learning (A) and (B) jointly enables the model to obtain a better representation (F) through averaging the noise patterns. By training on multiple tasks, the model is exposed to a wider range of data and learns more robust representations that are less likely to overfit to the training data.
3.2. Attention Focusing
If a task is very noisy or data is limited and high-dimensional, it can be difficult for a model to differentiate between relevant and irrelevant features. MTL can help the model focus its attention on those features that actually matter as other tasks will provide additional evidence for the relevance or irrelevance of those features. MTL can help the model focus its attention on the most important features by providing additional context and guidance from related tasks.
3.3. Eavesdropping
Some features (G) are easy to learn for some task (B), while being difficult to learn for another task (A). This might either be because (A) interacts with the features in a more complex way or because other features are impeding the model’s ability to learn (G). Through MTL, we can allow the model to eavesdrop, i.e. learn (G) through task (B). The easiest way to do this is through hints [10], i.e. directly training the model to predict the most important features. MTL can allow the model to “eavesdrop” on easier tasks to learn features that are difficult to learn directly from the main task.
3.4. Representation Bias
MTL biases the model to prefer representations that other tasks also prefer. This will also help the model to generalize to new tasks in the future as a hypothesis space that performs well for a sufficiently large number of training tasks will also perform well for learning novel tasks as long as they are from the same environment [11]. MTL biases the model towards representations that are useful for multiple tasks, leading to more general and transferable knowledge.
3.5. Regularization
Finally, MTL acts as a regularizer by introducing an inductive bias. As such, it reduces the risk of overfitting as well as the Rademacher complexity of the model, i.e. its ability to fit random noise. MTL acts as a regularizer by introducing an inductive bias, which encourages the model to learn simpler and more general representations.
4. Applying Multi-Task Learning in Education
Multi-Task Learning principles can be applied to various educational contexts, improving learning outcomes and skill development.
4.1. Curriculum Design
- Integrated Curriculum: Designing curricula that integrate multiple related subjects, highlighting the connections and dependencies between them.
- Project-Based Learning: Engaging students in projects that require them to apply knowledge and skills from multiple domains.
- Interdisciplinary Studies: Encouraging students to explore topics from multiple perspectives, fostering a more holistic understanding.
4.2. Skill Development
- Cross-Training: Incorporating cross-training exercises that target multiple skills simultaneously, such as combining physical and cognitive tasks.
- Contextual Learning: Providing students with opportunities to apply their skills in real-world contexts that require them to draw on multiple areas of knowledge.
- Adaptive Learning: Tailoring the learning experience to each student’s individual needs and learning style, dynamically adjusting the tasks and challenges based on their progress.
4.3. Technology-Enhanced Learning
- Educational Games: Developing educational games that integrate multiple learning objectives, providing students with an engaging and interactive way to learn.
- Virtual Reality: Using virtual reality to create immersive learning environments that simulate real-world scenarios, allowing students to practice their skills in a safe and controlled setting.
- AI-Powered Tutors: Developing AI-powered tutors that can provide personalized feedback and guidance to students, adapting to their individual learning needs and pace.
4.4. Real-World Examples and Case Studies
Several real-world examples and case studies demonstrate the effectiveness of Multi-Task Learning in educational settings.
- Medical Training: Medical students often learn anatomy, physiology, and pharmacology concurrently to understand how drugs affect the human body.
- Language Learning: Language learners often study grammar, vocabulary, and pronunciation simultaneously to develop comprehensive language skills.
- Coding Bootcamps: Coding bootcamps often teach web development, data science, and machine learning concurrently to prepare students for various tech roles.
5. Deep Dive into Advanced Multi-Task Learning Techniques
As Multi-Task Learning evolves, researchers are developing more sophisticated techniques to optimize task sharing and knowledge transfer.
5.1. Deep Relationship Networks
In MTL for computer vision, approaches often share the convolutional layers, while learning task-specific fully-connected layers. [38] improve upon these models by proposing Deep Relationship Networks. In addition to the structure of shared and task-specific layers, which can be seen in Figure 3, they place matrix priors on the fully connected layers, which allow the model to learn the relationship between tasks, similar to some of the Bayesian models we have looked at before. This approach, however, still relies on a pre-defined structure for sharing, which may be adequate for well-studied computer vision problems, but prove error-prone for novel tasks.
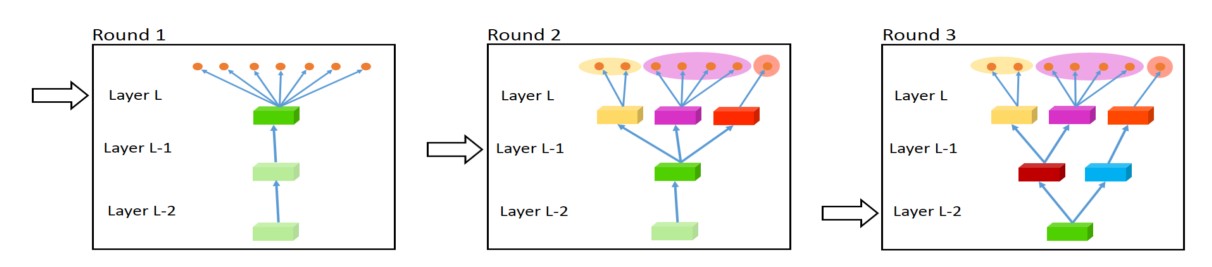
5.2. Fully-Adaptive Feature Sharing
Starting at the other extreme, [39] propose a bottom-up approach that starts with a thin network and dynamically widens it greedily during training using a criterion that promotes grouping of similar tasks. The widening procedure, which dynamically creates branches can be seen in Figure 4. However, the greedy method might not be able to discover a model that is globally optimal, while assigning each branch to exactly one task does not allow the model to learn more complex interactions between tasks.
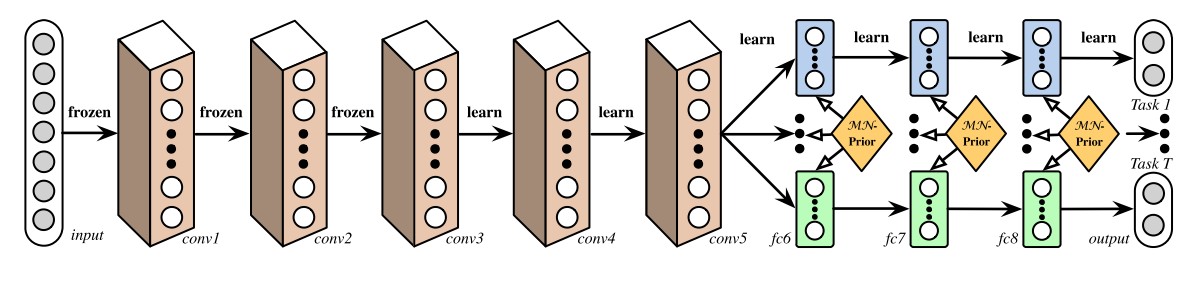
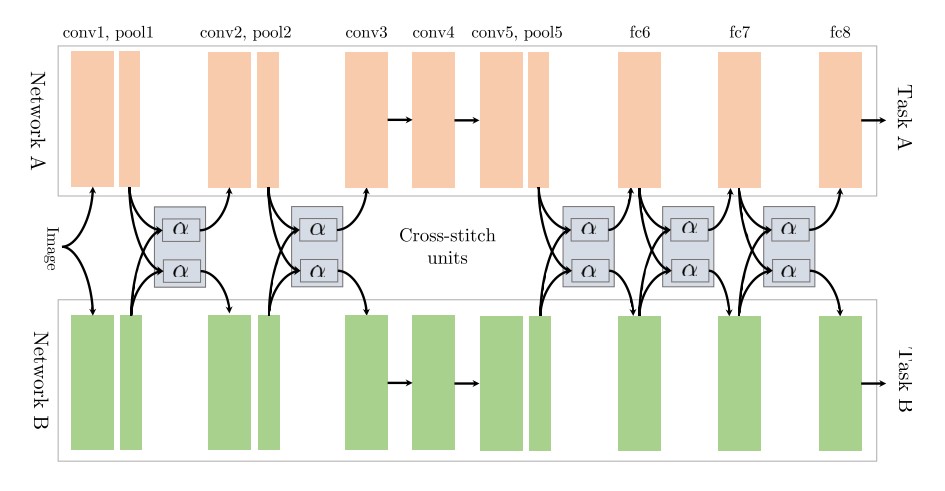
5.3. Cross-stitch Networks
[40] start out with two separate model architectures just as in soft parameter sharing. They then use what they refer to as cross-stitch units to allow the model to determine in what way the task-specific networks leverage the knowledge of the other task by learning a linear combination of the output of the previous layers. Their architecture can be seen in Figure 5, in which they only place cross-stitch units after pooling and fully-connected layers.
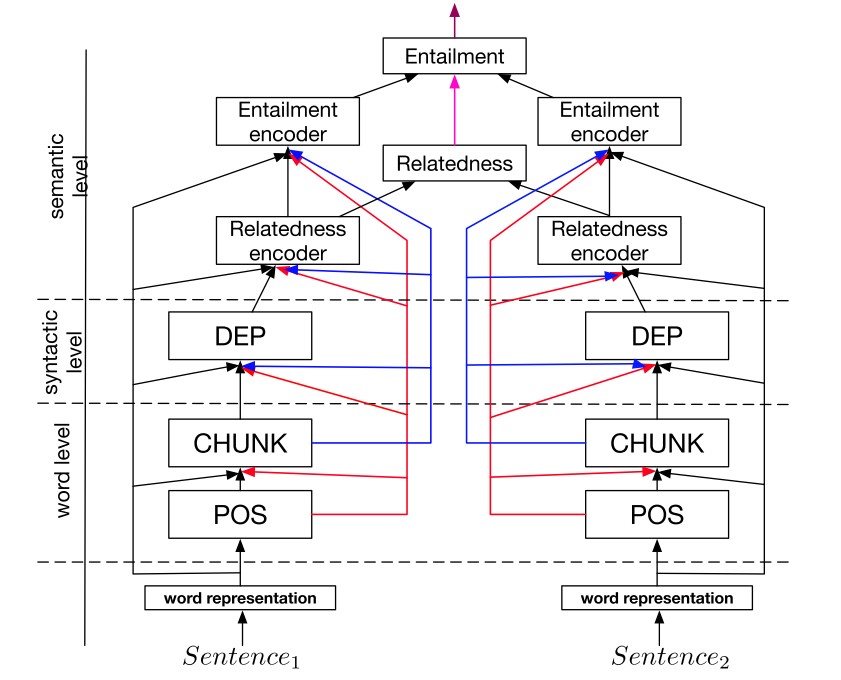
5.4. A Joint Many-Task Model
Building on this finding, [42] pre-define a hierarchical architecture consisting of several NLP tasks, which can be seen in Figure 6, as a joint model for multi-task learning.
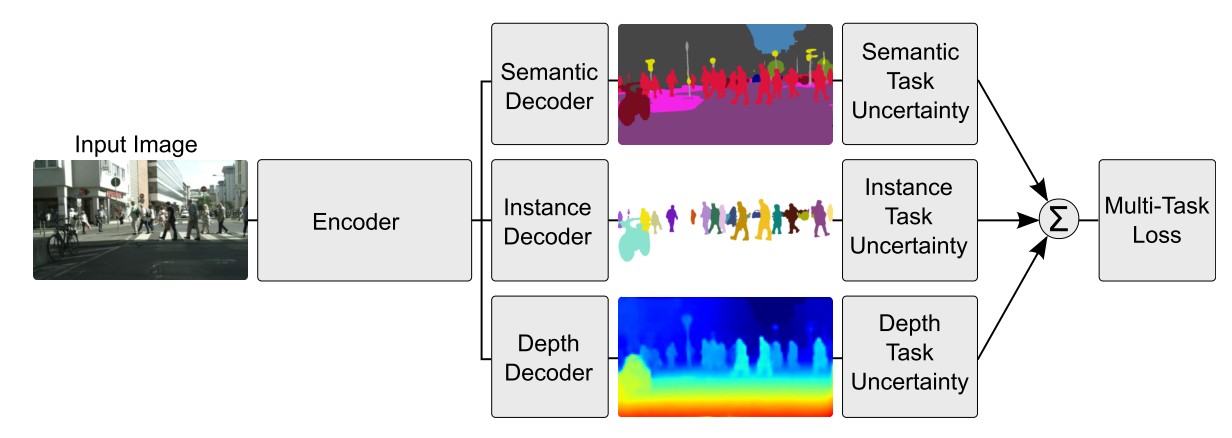
5.5. Weighting Losses with Uncertainty
Instead of learning the structure of sharing, [43] take a orthogonal approach by considering the uncertainty of each task. They then adjust each task’s relative weight in the cost function by deriving a multi-task loss function based on maximizing the Gaussian likelihood with task-dependant uncertainty. Their architecture for per-pixel depth regression, semantic and instance segmentation can be seen in Figure 7.
6. Selecting the Right Auxiliary Tasks
The choice of auxiliary tasks can significantly impact the effectiveness of MTL. Choosing tasks that are relevant and complementary to the main task can lead to improved generalization and efficiency.
6.1. Related Tasks
Using a related task as an auxiliary task for MTL is the classical choice. To get an idea what a related task can be, we will present some prominent examples. Caruana (1998) uses tasks that predict different characteristics of the road as auxiliary tasks for predicting the steering direction in a self-driving car; [46] use head pose estimation and facial attribute inference as auxiliary tasks for facial landmark detection; [47] jointly learn query classification and web search; Girshick (2015) jointly predicts the class and the coordinates of an object in an image; finally, [48] jointly predict the phoneme duration and frequency profile for text-to-speech. Selecting auxiliary tasks that are closely related to the main task can facilitate knowledge transfer and improve performance.
6.2. Adversarial Tasks
Often, labeled data for a related task is unavailable. In some circumstances, however, we have access to a task that is opposite of what we want to achieve. This data can be leveraged using an adversarial loss, which does not seek to minimize but maximize the training error using a gradient reversal layer. This setup has found recent success in domain adaptation [49]. The adversarial task in this case is predicting the domain of the input; by reversing the gradient of the adversarial task, the adversarial task loss is maximized, which is beneficial for the main task as it forces the model to learn representations that cannot distinguish between domains. Using adversarial tasks can encourage the model to learn more robust and invariant representations.
6.3. Hints
As mentioned before, MTL can be used to learn features that might not be easy to learn just using the original task. An effective way to achieve this is to use hints, i.e. predicting the features as an auxiliary task. Recent examples of this strategy in the context of natural language processing are [50] who predict whether an input sentence contains a positive or negative sentiment word as auxiliary tasks for sentiment analysis and [51] who predict whether a name is present in a sentence as auxiliary task for name error detection. Providing the model with hints through auxiliary tasks can guide the learning process and improve performance.
6.4. Focusing Attention
Similarly, the auxiliary task can be used to focus attention on parts of the image that a network might normally ignore. For instance, for learning to steer (Caruana, 1998) a single-task model might typically ignore lane markings as these make up only a small part of the image and are not always present. Predicting lane markings as auxiliary task, however, forces the model to learn to represent them; this knowledge can then also be used for the main task. Analogously, for facial recognition, one might learn to predict the location of facial landmarks as auxiliary tasks, since these are often distinctive. Using auxiliary tasks to focus attention on specific aspects of the input can improve the model’s ability to extract relevant features.
6.5. Representation Learning
The goal of an auxiliary task in MTL is to enable the model to learn representations that are shared or helpful for the main task. All auxiliary tasks discussed so far do this implicitly: They are closely related to the main task, so that learning them likely allows the model to learn beneficial representations. A more explicit modelling is possible, for instance by employing a task that is known to enable a model to learn transferable representations. The language modelling objective as employed by Cheng et al. (2015) and [53] fulfils this role. In a similar vein, an autoencoder objective can also be used as an auxiliary task. Selecting auxiliary tasks that promote representation learning can lead to more general and transferable knowledge.
7. Challenges and Considerations in Multi-Task Learning
While MTL offers many benefits, it also presents several challenges that need to be addressed to ensure successful implementation.
7.1. Negative Transfer
When sharing information with an unrelated task might actually hurt performance, a phenomenon known as negative transfer. If tasks are too dissimilar, sharing information between them can lead to negative transfer, where learning one task degrades performance on another.
Mitigation Strategies:
- Careful task selection to ensure relatedness and complementarity.
- Task weighting to balance the influence of different tasks.
- Adaptive sharing mechanisms to dynamically adjust the amount of shared information.
7.2. Task Interference
When tasks compete for resources or have conflicting objectives, it can lead to task interference. If tasks compete for resources or have conflicting objectives, it can lead to suboptimal performance.
Mitigation Strategies:
- Careful architecture design to allocate resources effectively.
- Task-specific layers to allow each task to learn its own specialized representations.
- Loss function engineering to balance the objectives of different tasks.
7.3. Scalability
As the number of tasks increases, MTL models can become more complex and difficult to train. As the number of tasks increases, MTL models can become more complex and difficult to train, requiring more computational resources.
Mitigation Strategies:
- Modular architecture design to facilitate scalability.
- Distributed training techniques to parallelize the learning process.
- Dimensionality reduction techniques to reduce the number of parameters.
8. Future Trends and Research Directions
The field of Multi-Task Learning is rapidly evolving, with new research directions emerging to address existing challenges and explore new opportunities.
8.1. Meta-Learning for Multi-Task Learning
Meta-learning, or “learning to learn,” can be used to automatically discover effective MTL strategies, such as task weighting and architecture design.
8.2. Lifelong Learning
Integrating MTL with lifelong learning approaches can enable models to continuously learn and adapt to new tasks over time, without forgetting previously learned knowledge.
8.3. Multi-Modal Multi-Task Learning
Extending MTL to multi-modal settings, where models learn from multiple types of data (e.g., images, text, audio), can lead to more comprehensive and robust representations.
9. Conclusion: The Power of Multi-Task Learning
Multi-Task Learning is a powerful approach that can significantly enhance learning outcomes and skill development in various educational contexts. By leveraging the connections between related tasks, MTL can improve generalization, increase efficiency, and promote deeper understanding. As the field continues to evolve, new techniques and applications will emerge, further unlocking the potential of MTL to transform education and training.
Embrace the power of Multi-Task Learning and unlock your full potential with LEARNS.EDU.VN. Explore our resources and discover how to integrate MTL principles into your learning journey.
Ready to explore the power of Multi-Task Learning? Visit LEARNS.EDU.VN today and discover a world of knowledge and skill-building opportunities.
10. Frequently Asked Questions (FAQ) About Multi-Task Learning
Q1: What is Multi-Task Learning (MTL)?
A1: Multi-Task Learning is a machine learning approach where multiple learning tasks are solved simultaneously, leveraging commonalities and differences across tasks to improve learning efficiency and prediction accuracy.
Q2: What are the key benefits of using Multi-Task Learning?
A2: Key benefits include improved generalization, increased efficiency, enhanced feature learning, and reduced overfitting.
Q3: How does Multi-Task Learning differ from Single-Task Learning?
A3: Multi-Task Learning involves learning multiple tasks at the same time, while Single-Task Learning focuses on learning one task at a time. MTL leverages data from multiple related tasks, leading to improved generalization and efficiency.
Q4: What is hard parameter sharing in Multi-Task Learning?
A4: Hard parameter sharing is an approach where the hidden layers are shared across all tasks, while each task has its own task-specific output layer. This approach is most effective when the tasks are closely related.
Q5: What is soft parameter sharing in Multi-Task Learning?
A5: Soft parameter sharing is an approach where each task has its own model with its own parameters. However, the models are encouraged to be similar by adding a regularization term to the loss function that penalizes differences between the parameters.
Q6: What are some challenges associated with Multi-Task Learning?
A6: Challenges include negative transfer, task interference, and scalability. Negative transfer occurs when sharing information with an unrelated task hurts performance, while task interference arises when tasks compete for resources or have conflicting objectives.
Q7: How can negative transfer be mitigated in Multi-Task Learning?
A7: Negative transfer can be mitigated through careful task selection, task weighting, and adaptive sharing mechanisms.
Q8: What are auxiliary tasks in Multi-Task Learning?
A8: Auxiliary tasks are additional tasks that are learned alongside the main task to improve its performance. These tasks should be related to the main task and provide complementary information.
Q9: How do I select the right auxiliary tasks for Multi-Task Learning?
A9: Select auxiliary tasks that are related to the main task and provide complementary information. Consider using related tasks, adversarial tasks, hints, or tasks that focus attention on specific aspects of the input.
Q10: What are some future trends in Multi-Task Learning research?
A10: Future trends include meta-learning for Multi-Task Learning, lifelong learning, and multi-modal Multi-Task Learning.
For more information on Multi-Task Learning and other educational topics, please contact us:
Address: 123 Education Way, Learnville, CA 90210, United States
WhatsApp: +1 555-555-1212
Website: learns.edu.vn
We hope this article has provided you with a comprehensive understanding of Multi-Task Learning and its potential to transform education and training.
