Natural Language Processing (NLP) is a dynamic field at the intersection of computer science, artificial intelligence, and linguistics. It’s dedicated to enabling computers to understand, interpret, and generate human language in a meaningful and contextually relevant way. In an era defined by an explosion of text data – from social media interactions to extensive research publications – NLP has emerged as a vital technology for extracting actionable insights and automating a wide range of tasks involving language.
In this article, we will delve into the core concepts and methodologies within Natural Language Processing, highlighting how it transforms unstructured text into valuable, structured information. From the foundational steps of tokenization and parsing to sophisticated applications like sentiment analysis and machine translation, NLP’s broad spectrum of techniques is revolutionizing industries and enhancing human-computer interactions. Whether you’re a seasoned expert or just beginning to explore this domain, this overview will provide a comprehensive understanding of NLP and its increasing importance in our digitally driven world, particularly in conjunction with machine learning.
What is Natural Language Processing?
Natural Language Processing (NLP) is a branch of computer science and a key component of artificial intelligence focused on enabling computers to understand and process human language. At its heart, NLP leverages computational linguistics – the scientific study of language from a computational perspective – and a variety of models built on statistical methods, machine learning algorithms, and advanced deep learning architectures. These powerful technologies equip computers to meticulously analyze and process both written text and spoken voice data, going beyond surface-level interpretation to grasp the nuanced meanings, underlying intentions, and even the emotional tones embedded within human communication.
NLP is the engine driving numerous applications we interact with daily. Consider the seamless text translation services that bridge language barriers, the accuracy of voice recognition systems that transcribe our speech, the efficiency of text summarization tools that condense lengthy documents, and the responsiveness of sophisticated chatbots that provide instant customer service. You’ve likely encountered NLP in action through voice-activated GPS navigation, intelligent digital assistants, speech-to-text software, and automated customer support bots. Beyond consumer applications, NLP is a transformative force for businesses, streamlining complex language-based tasks to boost efficiency, enhance productivity, and improve overall performance. The synergy between NLP and machine learning is particularly potent, allowing systems to learn from vast datasets and continuously improve their language processing capabilities.
NLP Techniques
NLP encompasses a diverse toolkit of techniques, each designed to equip computers with the ability to process and comprehend human language. These techniques can be categorized into several core areas, each addressing distinct facets of language processing. Here are some fundamental NLP techniques, many of which are significantly enhanced by machine learning methodologies:
1. Text Processing and Preprocessing in NLP
This initial stage is crucial for preparing raw text data for analysis. It involves cleaning and structuring the text to make it suitable for machine learning models. Common preprocessing steps include:
- Tokenization: Breaking down text into individual units, such as words, phrases, symbols, or sentences, known as tokens.
- Lowercasing: Converting all text to lowercase to ensure consistency and reduce data variability.
- Stop Word Removal: Eliminating common words like “the,” “a,” “is,” which often have little semantic value and can add noise to analysis.
- Punctuation Removal: Removing punctuation marks to focus on the essential textual content.
- Stemming: Reducing words to their root form by removing suffixes (e.g., “running” becomes “run”).
- Lemmatization: A more sophisticated approach than stemming, lemmatization reduces words to their dictionary base form (lemma), considering the word’s context and meaning (e.g., “better” becomes “good”).
2. Syntax and Parsing in NLP
Syntax and parsing focus on the grammatical structure of language, enabling machines to understand how words are arranged to form meaningful sentences. Machine learning models are often used to improve the accuracy of these techniques:
- Part-of-Speech (POS) Tagging: Identifying the grammatical role of each word in a sentence (e.g., noun, verb, adjective). Machine learning classifiers are trained on large datasets to accurately assign POS tags.
- Dependency Parsing: Analyzing the grammatical dependencies between words in a sentence, revealing relationships like subject-verb and object-verb. Machine learning helps build dependency parsers that can handle complex sentence structures.
- Constituency Parsing: Breaking down a sentence into its constituent parts or phrases, like noun phrases and verb phrases, to understand the hierarchical structure of sentences. Machine learning techniques, particularly deep learning, have significantly improved constituency parsing accuracy.
3. Semantic Analysis
Semantic analysis aims to understand the meaning of text, going beyond the literal words to grasp the intended message. Machine learning is central to many semantic analysis techniques:
- Named Entity Recognition (NER): Identifying and classifying named entities in text, such as names of people, organizations, locations, dates, and quantities. Machine learning models, especially deep learning models like recurrent neural networks (RNNs) and transformers, are highly effective in NER.
- Word Sense Disambiguation (WSD): Determining the correct meaning of a word in a given context when a word has multiple possible meanings. Machine learning methods use contextual information to choose the appropriate word sense.
- Coreference Resolution: Identifying instances where different words or phrases refer to the same entity within a text (e.g., resolving pronouns like “he” and “she” to their corresponding nouns). Machine learning models learn patterns of coreference from large text corpora.
4. Information Extraction
Information extraction focuses on automatically extracting structured information from unstructured text. Machine learning plays a crucial role in identifying patterns and relationships in text data:
- Entity Extraction: Identifying specific entities of interest and their attributes within a text, such as extracting product names and their features from customer reviews. Machine learning models can be trained to recognize and extract custom entities.
- Relation Extraction: Identifying and categorizing relationships between entities in a text, such as determining the relationship between a person and an organization (e.g., “employee of,” “founder of”). Machine learning classifiers are used to predict relationships between entities.
5. Text Classification in NLP
Text classification involves categorizing text into predefined classes or categories based on its content. Machine learning algorithms are fundamental to text classification tasks:
- Sentiment Analysis: Determining the emotional tone or sentiment expressed in a piece of text (e.g., positive, negative, neutral). Machine learning classifiers are trained on labeled datasets to classify sentiment.
- Topic Modeling: Discovering abstract topics or themes present in a collection of documents. Unsupervised machine learning techniques like Latent Dirichlet Allocation (LDA) are commonly used for topic modeling.
- Spam Detection: Classifying text messages or emails as spam or not spam. Machine learning models are trained to identify patterns and features indicative of spam.
6. Language Generation
Language generation focuses on enabling computers to produce human-like text. Machine learning, particularly deep learning, has revolutionized language generation capabilities:
- Machine Translation: Automatically translating text from one language to another. Neural machine translation models, based on deep learning, have achieved state-of-the-art results in translation quality.
- Text Summarization: Generating concise summaries of longer documents. Machine learning models can be trained to extract key information and generate coherent summaries.
- Text Generation: Automatically creating coherent and contextually relevant text for various purposes, such as creative writing, content creation, and dialogue systems. Generative models like GPT (Generative Pre-trained Transformer) leverage deep learning to generate highly realistic text.
7. Speech Processing
Speech processing deals with the analysis and synthesis of spoken language. Machine learning is integral to both speech recognition and text-to-speech systems:
- Speech Recognition: Converting spoken language into written text. Machine learning models, including deep learning models like convolutional neural networks (CNNs) and recurrent neural networks (RNNs), power modern speech recognition systems.
- Text-to-Speech (TTS) Synthesis: Converting written text into spoken language. Deep learning-based TTS systems can generate highly natural and expressive speech.
8. Question Answering
Question answering (QA) systems are designed to automatically answer questions posed in natural language. Machine learning is used extensively to build both retrieval-based and generative QA systems:
- Retrieval-Based QA: Retrieving and returning the most relevant text passage from a document collection in response to a question. Machine learning ranking models are used to identify the most relevant passages.
- Generative QA: Generating a direct answer to a question based on information extracted from a text corpus. Machine learning models can be trained to understand questions and generate answers.
9. Dialogue Systems
Dialogue systems enable computers to engage in conversations with humans. Machine learning is crucial for building sophisticated chatbots and virtual assistants:
- Chatbots and Virtual Assistants: Creating systems that can interact with users through natural language, providing information, answering questions, and performing tasks based on user input. Machine learning powers the natural language understanding, dialogue management, and response generation components of chatbots and virtual assistants.
10. Sentiment and Emotion Analysis in NLP
Going beyond basic sentiment, this area focuses on detecting and understanding the full spectrum of human emotions expressed in text. Machine learning enhances the accuracy and nuance of emotion analysis:
- Emotion Detection: Identifying and categorizing specific emotions expressed in text, such as joy, sadness, anger, fear, and surprise. Machine learning models are trained to recognize subtle emotional cues in text.
- Opinion Mining: Analyzing opinions, attitudes, and viewpoints expressed in text, often used to understand public sentiment towards products, services, or topics from reviews and social media data. Machine learning techniques can aggregate and analyze opinions from large datasets.
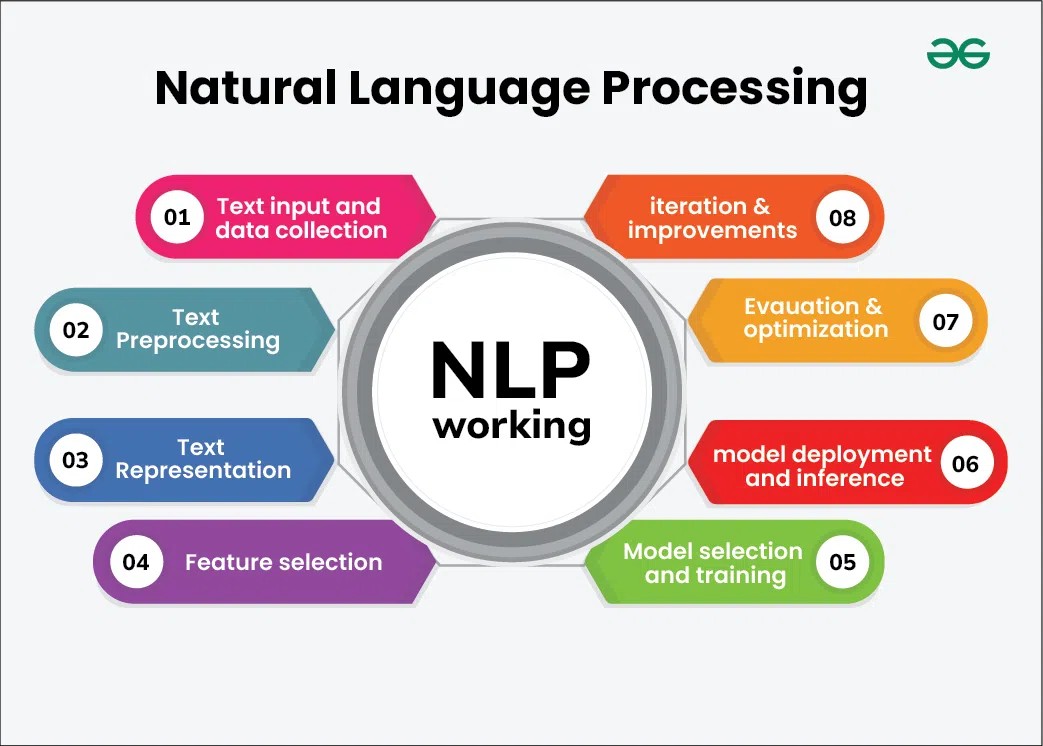 Diagram illustrating the workflow of Natural Language Processing (NLP) using machine learning techniques, showcasing stages from text input to model evaluation.
Diagram illustrating the workflow of Natural Language Processing (NLP) using machine learning techniques, showcasing stages from text input to model evaluation.
Working of Natural Language Processing (NLP) with Machine Learning
The effectiveness of modern Natural Language Processing heavily relies on machine learning. The workflow typically involves a series of steps where machine learning models are trained and deployed to analyze and understand human language. This process generally includes language understanding, language generation, and enabling seamless language interaction.
1. Text Input and Data Collection
- Data Collection: The initial step involves gathering text data from diverse sources. This could include scraping websites, digitizing books, collecting social media posts, or utilizing proprietary databases. The quality and quantity of data are crucial for training robust machine learning models.
- Data Storage: Collected text data needs to be stored in a structured and accessible format. Databases, cloud storage solutions, or collections of documents are commonly used to manage large volumes of text data effectively.
2. Text Preprocessing
Preprocessing is a critical phase in preparing raw text data for machine learning analysis. Clean and well-prepared data significantly improves the performance of NLP models. Common preprocessing steps, often implemented using scripting and automated tools, include:
- Tokenization: Splitting the text into individual tokens. This is a foundational step for most NLP tasks.
- Lowercasing: Converting all text to lowercase. This standardizes the text and reduces variations that machine learning models need to process.
- Stop Word Removal: Eliminating common words that don’t carry significant meaning. This reduces noise and focuses the analysis on more important terms for machine learning algorithms.
- Punctuation Removal: Removing punctuation marks. Similar to stop word removal, this cleans up the text and focuses on the core words for machine learning analysis.
- Stemming and Lemmatization: Reducing words to their base forms. This groups together different inflections of the same word, which is beneficial for many machine learning models. Lemmatization is often preferred as it provides linguistically correct base forms.
- Text Normalization: Standardizing text formats. This includes correcting spelling errors, expanding contractions (e.g., “can’t” to “cannot”), and handling special characters to ensure data consistency for machine learning.
3. Text Representation
To be processed by machine learning algorithms, text data needs to be converted into numerical representations. Several techniques are used to achieve this:
- Bag of Words (BoW): A simple representation where text is treated as a collection of words, disregarding grammar and word order. It focuses on word frequency, creating a vector representation of the text based on the count of each word.
- Term Frequency-Inverse Document Frequency (TF-IDF): A statistical measure that reflects the importance of a word in a document relative to a larger collection of documents (corpus). It weighs words based on their frequency in a document and their rarity across the corpus, highlighting words that are distinctive to specific documents.
- Word Embeddings: Dense vector representations of words where semantically similar words are positioned closer together in a vector space. Techniques like Word2Vec, GloVe, and FastText learn these embeddings from large text corpora, capturing semantic relationships between words. Word embeddings are crucial for deep learning models in NLP.
4. Feature Extraction
Extracting relevant features from the text data is essential for training effective machine learning models for NLP tasks. Features capture specific characteristics of the text that models can learn from:
- N-grams: Sequences of N consecutive words. N-grams capture some context and word order, which is lost in Bag of Words. Bigrams (2-grams) and trigrams (3-grams) are commonly used features.
- Syntactic Features: Features derived from the grammatical structure of sentences, such as Part-of-Speech tags, syntactic dependencies, and parse trees. These features provide machine learning models with insights into sentence structure.
- Semantic Features: Features that capture word meaning and context, often leveraging word embeddings and other semantic representations. These features allow models to understand the meaning conveyed by the text.
5. Model Selection and Training
Choosing and training an appropriate machine learning or deep learning model is a crucial step. The choice of model depends on the specific NLP task and the nature of the data:
- Supervised Learning: Using labeled data to train models. Common supervised learning algorithms include Support Vector Machines (SVM), Random Forests, and deep learning models like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). Labeled data provides the model with examples of correct outputs for given inputs.
- Unsupervised Learning: Applying techniques like clustering or topic modeling on unlabeled data. Latent Dirichlet Allocation (LDA) is a popular unsupervised technique for topic discovery. Unsupervised learning helps discover hidden patterns and structures in text data without explicit labels.
- Pre-trained Models: Utilizing pre-trained language models such as BERT, GPT, or transformer-based models. These models are trained on massive text corpora and can be fine-tuned for specific NLP tasks. Pre-trained models offer significant advantages by leveraging knowledge learned from vast amounts of data, reducing the need for extensive task-specific training data.
6. Model Deployment and Inference
Once a machine learning model is trained, it needs to be deployed to make predictions or extract insights from new, unseen text data. Deployment involves integrating the trained model into an application or system to perform NLP tasks:
- Text Classification: Categorizing new text into predefined classes (e.g., spam detection, sentiment analysis). The deployed model predicts the class label for new text inputs.
- Named Entity Recognition (NER): Identifying and classifying entities in new text. The deployed model extracts and categorizes entities from unseen text.
- Machine Translation: Translating text from one language to another. The deployed machine translation model translates input text into the target language.
- Question Answering: Providing answers to questions based on new text data. The QA system uses the deployed model to process questions and retrieve or generate answers from text data.
7. Evaluation and Optimization
Evaluating the performance of the NLP algorithm is crucial to ensure its effectiveness. Metrics like accuracy, precision, recall, F1-score, and BLEU (for machine translation) are used to assess model performance:
- Hyperparameter Tuning: Adjusting model parameters to optimize performance. Techniques like grid search and cross-validation are used to find the best hyperparameter settings.
- Error Analysis: Analyzing errors made by the model to understand its weaknesses and areas for improvement. Error analysis provides insights into model limitations and guides further development.
8. Iteration and Improvement
NLP model development is often an iterative process. Continuous improvement is achieved by:
- Incorporating new data: Expanding the training dataset to improve model generalization and robustness.
- Refining preprocessing techniques: Optimizing preprocessing steps to better clean and prepare text data.
- Experimenting with different models: Exploring different machine learning algorithms and architectures to find the most effective model for the task.
- Optimizing features: Engineering more informative features to enhance model performance.
This iterative cycle of development, evaluation, and refinement is essential for building high-performing NLP systems powered by machine learning.
Technologies Related to Natural Language Processing and Machine Learning
A range of technologies underpin and complement Natural Language Processing, particularly when combined with machine learning. These technologies provide tools, libraries, and platforms for building and deploying NLP solutions:
- Machine Learning Frameworks and Libraries: NLP heavily relies on machine learning frameworks such as TensorFlow, PyTorch, and scikit-learn. These provide the building blocks for developing and training NLP models.
- Natural Language Toolkits (NLTK) and Specialized Libraries: NLTK, spaCy, Stanford CoreNLP, and Gensim are popular Python libraries offering pre-built tools and functionalities for various NLP tasks, from tokenization and parsing to named entity recognition and topic modeling.
- Cloud-based NLP APIs: Cloud platforms like Google Cloud NLP API, Amazon Comprehend, and Microsoft Azure Text Analytics offer pre-trained NLP models and services accessible via APIs. These services provide ready-to-use NLP capabilities without requiring extensive model development.
- Vector Databases: Vector databases are optimized for storing and querying vector embeddings, which are crucial for semantic search and similarity tasks in NLP. Examples include Pinecone and Weaviate.
- GPUs and TPUs: Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) are specialized hardware accelerators that significantly speed up the training and inference of machine learning models, especially deep learning models used in NLP.
- Parsers: Syntactic parsers, like dependency parsers and constituency parsers, are essential for analyzing sentence structure. Libraries like spaCy and Stanford CoreNLP include high-performance parsers.
- Text-to-Speech (TTS) and Speech-to-Text (STT) Systems: These systems enable voice interaction and are often integrated with NLP applications. Examples include Google Cloud Text-to-Speech, Amazon Polly (TTS), and Google Cloud Speech-to-Text, AssemblyAI (STT).
- Named Entity Recognition (NER) Systems: Pre-trained NER systems are available in libraries like spaCy and cloud NLP APIs, allowing for quick and accurate entity extraction.
- Sentiment Analysis Tools: Libraries and cloud APIs provide sentiment analysis functionalities, enabling the automated detection of sentiment in text.
- Machine Translation Engines: Cloud-based machine translation services, such as Google Translate API and Amazon Translate, offer robust translation capabilities powered by machine learning.
- Chatbot Platforms: Platforms like Dialogflow, Rasa, and Amazon Lex provide frameworks and tools for building and deploying conversational chatbots, often incorporating sophisticated NLP and machine learning components.
- AI Software and Platforms: Broader AI software and platforms often integrate NLP capabilities, providing comprehensive solutions for AI development and deployment.
Applications of Natural Language Processing (NLP) and Machine Learning
The combination of NLP and machine learning has unlocked a vast array of applications across diverse industries. Here are some prominent examples:
- Spam Filters: Email spam filters are a ubiquitous application of NLP. They analyze email content to identify patterns and indicators of spam, leveraging machine learning classifiers to discern legitimate emails from unwanted spam.
- Algorithmic Trading: In finance, algorithmic trading systems utilize NLP to analyze news articles, financial reports, and social media sentiment to predict stock market trends. Machine learning models can learn to interpret the sentiment and meaning of textual data to inform trading decisions.
- Question Answering Systems: Search engines like Google Search and virtual assistants like Siri rely heavily on NLP for question answering. NLP enables these systems to understand the meaning of user queries and retrieve relevant information or generate natural language responses.
- Summarizing Information: With the explosion of online information, NLP-powered text summarization tools are invaluable. They can condense lengthy documents and articles into concise summaries, enabling users to quickly grasp the key information.
- Customer Service Chatbots: Businesses are increasingly deploying chatbots for customer service. These chatbots use NLP to understand customer inquiries, provide automated responses, and escalate complex issues to human agents when necessary, improving efficiency and customer satisfaction.
- Machine Translation Services: Online translation services powered by NLP and machine learning have revolutionized cross-language communication, enabling real-time translation of text and speech.
- Sentiment Analysis for Market Research: Businesses use sentiment analysis to monitor customer opinions and brand perception from social media, reviews, and surveys. Machine learning-based sentiment analysis provides valuable insights into customer attitudes and preferences.
- Content Recommendation Systems: Platforms like Netflix and YouTube use NLP to analyze content descriptions and user preferences to provide personalized content recommendations. NLP helps understand the semantic content of videos and articles to match them with user interests.
- Healthcare Applications: NLP is being applied in healthcare for tasks like analyzing patient records, extracting information from medical literature, and assisting with diagnosis and treatment planning. Machine learning models can identify patterns and insights from medical text data.
- Legal Document Review: In the legal field, NLP is used to analyze large volumes of legal documents for tasks like contract review, e-discovery, and legal research, significantly speeding up these processes.
Future Scope of NLP and Machine Learning
The future of NLP and machine learning is exceptionally promising, with ongoing research and development pushing the boundaries of language AI. Key areas of future growth include:
- Advanced Conversational AI (Bots): Chatbots will become even more sophisticated, capable of handling complex conversations, understanding nuanced language, and providing highly personalized and context-aware interactions. Advancements in machine learning will enable chatbots to learn and adapt continuously.
- Invisible User Interfaces (UI): The trend towards invisible or zero UIs, where interaction with technology is primarily through natural language, will accelerate. Voice assistants and language-based interfaces will become increasingly integrated into our daily lives, making technology more intuitive and accessible.
- Smarter Search Engines: Search engines will evolve to understand natural language queries even more effectively, moving beyond keyword-based search to semantic search that understands the user’s intent and context. NLP and machine learning will drive this evolution towards “search like you talk” functionality.
- Personalized Education: NLP can personalize learning experiences by analyzing student text and speech to understand their learning styles, knowledge gaps, and emotional states, allowing for tailored educational content and feedback.
- Enhanced Accessibility: NLP can make technology more accessible to people with disabilities, through improved speech recognition for voice control, text-to-speech for screen readers, and real-time captioning.
- Cross-lingual Communication: Machine translation will continue to improve, breaking down language barriers and facilitating seamless communication across languages and cultures.
Future Enhancements in NLP and Machine Learning
Further advancements in NLP and machine learning are expected to drive significant enhancements:
- Deep Neural Networks (DNNs): Continued research into and application of Deep Neural Networks will push the limits of NLP, enabling human-machine interactions to feel increasingly natural and human-like. DNNs will improve the ability of machines to understand context, nuance, and subtle aspects of language.
- Semantic Understanding: Moving beyond basic word recognition to deeper semantic understanding is a key area of focus. Developing algorithms that can truly grasp the meaning, intent, and implications of text will unlock more sophisticated NLP applications.
- Multilingual NLP: Expanding NLP capabilities to a wider range of languages, including low-resource languages and regional dialects, is crucial for global accessibility and inclusivity. Research into multilingual models and transfer learning techniques will be essential.
- Contextual Understanding and Reasoning: Improving the ability of NLP models to understand and reason with context is critical. Models will need to be able to track conversations, understand background knowledge, and make inferences based on context to achieve human-level language understanding.
- Explainable AI (XAI) in NLP: As NLP models become more complex, explainability and interpretability are increasingly important. Developing techniques to understand why NLP models make certain decisions will build trust and enable better debugging and improvement.
Conclusion
In conclusion, Natural Language Processing (NLP), especially when combined with machine learning, has revolutionized how humans interact with machines, paving the way for more intuitive and efficient communication. NLP’s diverse techniques and methodologies empower computers to understand, interpret, and generate human language with increasing sophistication. From foundational tasks to advanced applications, NLP’s impact is felt across numerous sectors. As technology progresses, fueled by breakthroughs in machine learning and artificial intelligence, NLP’s potential to enhance human-computer interaction and solve complex language-related challenges remains immense. Understanding the core principles and applications of NLP and machine learning is essential for anyone aiming to leverage the power of language AI in today’s digital landscape and shape the future of human-computer communication.
Natural Language Processing – FAQs
What are NLP models?
NLP models are computational systems designed to process natural language data, including text and speech, and perform various tasks such as translation, summarization, sentiment analysis, and question answering. These models are primarily based on machine learning and deep learning techniques, trained on extensive language datasets to learn patterns and relationships in language.
What are the types of NLP models?
NLP models can be broadly categorized into traditional machine learning models and deep learning models. Traditional models include statistical models, rule-based systems, and classical machine learning algorithms like Naive Bayes, SVM, and logistic regression. Deep learning models, such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformers (e.g., BERT, GPT), have become increasingly dominant due to their ability to learn complex language patterns and achieve state-of-the-art performance on many NLP tasks.
What are the challenges of NLP models?
NLP models face several challenges due to the inherent complexity and ambiguity of natural language. These challenges include:
- Ambiguity: Language is often ambiguous, with words and sentences having multiple possible interpretations.
- Context Dependence: Meaning is highly dependent on context, requiring models to understand the surrounding text and situation.
- Variability: Language exhibits significant variability in expression, style, and structure.
- Figurative Language: Metaphors, idioms, and sarcasm pose challenges for literal interpretation.
- Domain Specificity: Models trained on one domain may not generalize well to other domains.
- Data Scarcity: Labeled data for training supervised machine learning models can be limited for certain languages and tasks.
- Evolving Language: Language is constantly evolving, with new words and expressions emerging.
What are the applications of NLP models?
NLP models have a wide range of applications across numerous domains and industries, including:
- Search Engines: Improving search query understanding and relevance.
- Chatbots and Virtual Assistants: Enabling conversational interfaces for customer service and task automation.
- Voice Assistants: Powering voice-activated devices and applications.
- Social Media Analysis: Analyzing social media data for sentiment, trends, and insights.
- Text Mining and Information Extraction: Extracting structured information from unstructured text data.
- Natural Language Generation: Generating human-like text for various purposes.
- Machine Translation: Translating text between languages.
- Speech Recognition: Converting spoken language to text.
- Text Summarization: Condensing lengthy documents into summaries.
- Question Answering Systems: Answering questions posed in natural language.
- Sentiment Analysis: Determining the emotional tone of text.
- Content Recommendation: Recommending relevant content based on user preferences and content analysis.
- Healthcare Informatics: Analyzing medical records and literature for improved patient care and research.
Next Article Computer Vision Tutorial
