The Standard Epoch For Machine Learning signifies a comprehensive cycle through the entire training dataset, a cornerstone in refining model parameters and optimizing performance. Delve into the importance of epochs in deep learning models with LEARNS.EDU.VN, and understand their substantial influence on overall performance metrics. Uncover key aspects such as iterative training, batch size optimization, and validation dataset assessment to enhance your understanding of the standard epoch for machine learning and its practical applications in training machine learning models.
1. Understanding the Essence of an Epoch in Machine Learning
In the realm of machine learning, an epoch represents a pivotal stage in model training, specifically defined as one complete iteration through the entire training dataset. This process ensures that each data sample within the dataset is utilized to update the model’s weights and biases, crucial parameters that determine how the model interprets and processes information. By adjusting these parameters, the model refines its ability to make accurate predictions and classifications.
During an epoch, the model learns from the data, adjusting its internal parameters to minimize the difference between its predictions and the actual outcomes. This adjustment is based on a calculated loss or error, which quantifies how far off the model’s predictions are from the true values. The primary goal of each epoch is to reduce this loss, thereby improving the model’s accuracy.
1.1. The Significance of Epochs in Deep Learning
Epochs play a particularly vital role in deep learning, where models often consist of complex neural networks with numerous layers and parameters. These networks require extensive training to accurately capture the intricate patterns and relationships within the data. Each epoch provides an opportunity for the model to refine its understanding and improve its performance.
In deep learning, the dataset is typically divided into smaller subsets known as batches. These batches are processed sequentially during each epoch, and the model’s parameters are adjusted after processing each batch. This approach not only reduces the computational burden of training but also introduces a degree of stochasticity that can help the model escape local optima and converge towards a more globally optimal solution.
The number of batches in an epoch is determined by the batch size, a hyperparameter that can be fine-tuned to optimize model performance. The choice of batch size can significantly impact the training dynamics, affecting both the speed of convergence and the generalization ability of the model.
1.2. Monitoring and Optimization
After each epoch, it is crucial to evaluate the model’s performance on a validation dataset. This dataset, separate from the training data, provides an unbiased assessment of how well the model is generalizing to unseen data. By tracking performance metrics such as accuracy, precision, and recall on the validation set, one can monitor the model’s progress and detect potential issues like overfitting.
The number of epochs is a hyperparameter that the user can control to optimize the model’s training process. While increasing the number of epochs can generally enhance model performance by allowing it to capture more intricate patterns in the data, it also increases the risk of overfitting. Overfitting occurs when the model becomes overly specialized to the training data, learning to memorize the specific examples rather than generalizing to the underlying patterns. This leads to poor performance on new, unseen data.
To mitigate the risk of overfitting, it is essential to monitor the model’s performance on the validation set and employ techniques such as early stopping. Early stopping involves halting the training process when the model’s performance on the validation set starts to degrade, indicating that it is beginning to overfit.
1.3. Epochs vs. Iterations: Clarifying the Distinction
It’s important to distinguish between epochs and iterations, as these terms are often used interchangeably but have distinct meanings in the context of machine learning.
An epoch represents one complete pass through the entire training dataset. In contrast, an iteration refers to the process of passing one batch of data through the model, calculating the loss, and updating the model’s parameters.
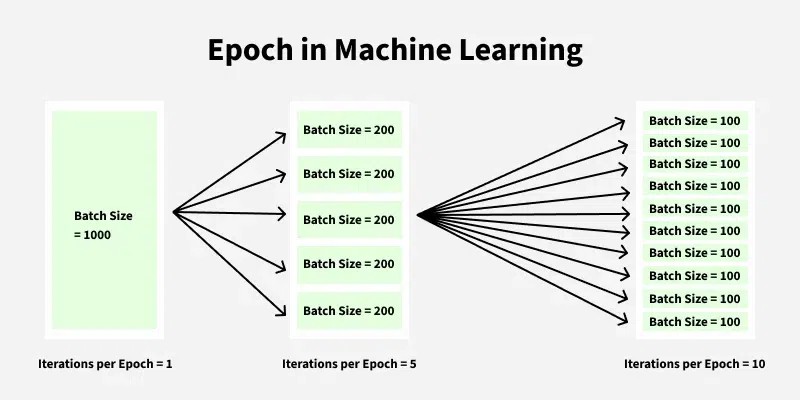
In other words, an epoch consists of multiple iterations, with the number of iterations per epoch determined by the batch size. For example, if the training dataset contains 1,000 samples and the batch size is set to 100, then each epoch will consist of 10 iterations.
Understanding the distinction between epochs and iterations is crucial for properly configuring the training process and interpreting the training logs.
 epoch-in-machine-learning_
epoch-in-machine-learning_
1.4. Practical Implications and Best Practices
In practice, the number of epochs is often set to a relatively large number, such as 100 or more, and an early stopping criterion is used to determine when to halt the training process. This approach allows the model to continue training as long as it is making progress on the validation set, while also preventing overfitting.
In addition to early stopping, other techniques can be used to mitigate the risk of overfitting, such as regularization and dropout. Regularization involves adding a penalty term to the loss function that discourages the model from learning overly complex patterns. Dropout, on the other hand, involves randomly dropping out some of the neurons in the neural network during training, which forces the model to learn more robust and generalizable features.
By carefully monitoring the model’s performance, adjusting the number of epochs, and employing techniques to prevent overfitting, you can effectively train machine learning models that generalize well to new, unseen data. LEARNS.EDU.VN provides comprehensive resources and guidance on these topics, empowering you to master the art of model training.
2. The Interplay Between Epochs, Iterations, and Batch Size
To fully grasp the concept of epochs in machine learning, it is essential to understand how they interact with iterations and batch size. These three concepts are interconnected and play crucial roles in the training process.
2.1. Defining Iteration
As previously mentioned, an iteration refers to a single update of the model’s parameters based on one batch of data. During each iteration, the model processes a batch of training examples, calculates the loss, and adjusts its weights and biases to minimize this loss.
The number of iterations required to complete one epoch depends on the batch size. Specifically, the number of iterations per epoch is equal to the total number of training examples divided by the batch size.
For example, if the training dataset contains 1,000 samples and the batch size is set to 100, then each epoch will consist of 10 iterations. This means that the model will update its parameters 10 times during each epoch.
2.2. Understanding Batch Size
Batch size is a hyperparameter that determines the number of training examples processed in each iteration. It represents a trade-off between computational efficiency and the accuracy of the parameter updates.
Smaller batch sizes lead to more frequent parameter updates, which can help the model converge faster. However, smaller batch sizes also introduce more noise into the training process, as the gradients calculated on each batch may be less representative of the overall dataset.
Larger batch sizes, on the other hand, provide more stable gradient estimates, but they also reduce the frequency of parameter updates. This can slow down the training process and may even lead to the model getting stuck in local optima.
The choice of batch size depends on the specific characteristics of the dataset and the model architecture. In general, smaller batch sizes are preferred for complex datasets and models, while larger batch sizes are suitable for simpler problems.
2.3. Mathematical Illustration
To illustrate the relationship between epochs, iterations, and batch size, consider the following example:
Suppose we have a training dataset with 1,000 training samples and we want to break the dataset into a batch size of 100. If we are going for 5 epochs, then the total number of iterations will be calculated as follows:
- Total number of training samples = 1000
- Batch size = 100
- Total number of iterations per epoch = Total number of training samples / Batch size = 1000 / 100 = 10
- One epoch = 10 iterations
- Total number of iterations in 5 epochs = 10 * 5 = 50 iterations.
This example demonstrates how the number of iterations is directly determined by the batch size and the number of epochs. By adjusting these hyperparameters, you can control the training process and optimize model performance.
2.4. Practical Considerations
In practice, the choice of batch size is often guided by the available computational resources. Larger batch sizes require more memory, which may limit the size of the model or the dataset that can be used.
It is also important to consider the trade-off between batch size and training time. Smaller batch sizes lead to more frequent parameter updates, which can speed up the initial stages of training. However, as the model converges, the benefits of smaller batch sizes diminish, and larger batch sizes may become more efficient.
Experimentation is key to finding the optimal batch size for a given problem. By trying different batch sizes and monitoring the model’s performance, you can identify the configuration that yields the best results.
LEARNS.EDU.VN offers practical guidance and resources on selecting the appropriate batch size and optimizing the training process.
3. The Importance of Multiple Epochs in Machine Learning
Using more than one epoch in machine learning is essential for achieving optimal model performance. Training a model for multiple epochs allows it to learn from the data more effectively, refine its parameters, and generalize to new, unseen data.
3.1. Parameter Optimization
Multiple epochs provide the model with repeated exposure to the training data, allowing it to gradually adjust its parameters and refine its understanding of the underlying patterns. With each epoch, the model fine-tunes its weights and biases to minimize the difference between its predictions and the actual outcomes.
This iterative process of parameter optimization is crucial for achieving high accuracy and generalization ability. By repeatedly processing the training data, the model can converge towards a more optimal solution.
3.2. Handling Complex Datasets
For complex datasets with intricate relationships and dependencies, multiple epochs are particularly important. Complex datasets often require extensive training to accurately capture the underlying patterns and relationships.
Multiple epochs allow the model to gradually learn these patterns, refining its understanding over time. With each epoch, the model can capture more subtle nuances and improve its ability to generalize to new, unseen data.
3.3. Convergence Monitoring
Epochs provide a valuable mechanism for monitoring the training process and ensuring that the model is converging towards a satisfactory solution. By tracking the loss and performance metrics on both the training and validation sets, you can assess the model’s progress and identify potential issues.
If the loss is decreasing and the performance metrics are improving, it indicates that the model is learning effectively. However, if the loss plateaus or the performance metrics start to degrade, it may indicate that the model is overfitting or that the learning rate is too high.
By monitoring the training process over multiple epochs, you can gain insights into the model’s behavior and make adjustments to the training parameters as needed.
3.4. Early Stopping
Multiple epochs make it easier to apply early stopping, a technique used to prevent overfitting. Early stopping involves monitoring the model’s performance on the validation set and halting the training process when the performance starts to degrade.
By stopping the training process early, you can prevent the model from overfitting to the training data and improve its generalization ability. Early stopping is a simple but effective technique that can significantly enhance the performance of machine learning models.
3.5. Advantages of Using Multiple Epochs
Using multiple epochs in machine learning offers several key advantages:
- Improved Model Performance: Training a model for multiple epochs allows it to learn better from the data. By processing the entire dataset several times, the model can adjust its weights iteratively, leading to improved accuracy.
- Progress Monitoring: With multiple epochs, you can easily track the progress of your model during training. By monitoring the performance on both the training and validation sets, you can determine whether the model is improving and identify when it might start overfitting.
- Memory Efficiency with Mini-Batches: Training with epochs makes it possible to work with large datasets that don’t fit into memory all at once. The model processes the data in mini-batches, handling smaller chunks of the dataset at a time, which allows for efficient memory usage.
- Early Stopping to Prevent Overfitting: Epochs make it easier to apply early stopping, a technique to avoid overfitting. When your model no longer shows improvement on the validation set, early stopping halts the training, saving time and computational resources.
- Optimized Training Process: Using multiple epochs helps optimize the training process by enabling gradual learning and effective tracking of model performance. This leads to more precise predictions and better results.
LEARNS.EDU.VN provides comprehensive resources and guidance on leveraging the benefits of multiple epochs in machine learning.
4. Potential Drawbacks and Mitigation Strategies
While using multiple epochs in machine learning offers numerous advantages, it is important to be aware of the potential drawbacks and employ strategies to mitigate them.
4.1. Overfitting Risk
One of the primary risks associated with training a model for too many epochs is overfitting. Overfitting occurs when the model learns the training data too well, memorizing the specific examples rather than generalizing to the underlying patterns.
An overfit model performs well on the training data but poorly on new, unseen data. This is because it has learned to fit the noise in the training data, rather than the true signal.
4.2. Computational Cost
Training for excessive epochs can be computationally expensive, especially with large datasets and complex models. The training time can increase significantly as the number of epochs increases.
This can be a limiting factor, especially when working with limited computational resources. It is important to strike a balance between the number of epochs and the available computational resources.
4.3. Finding the Optimal Number of Epochs
Determining the optimal number of epochs for a given problem can be challenging. The ideal number of epochs depends on several factors, including the complexity of the model, the size of the dataset, and the characteristics of the data.
Too few epochs may result in underfitting, where the model fails to capture the underlying patterns in the data. Too many epochs may result in overfitting, where the model learns the noise in the training data.
4.4. Mitigation Strategies
To mitigate the potential drawbacks of using multiple epochs, several strategies can be employed:
- Early Stopping: As mentioned earlier, early stopping is a technique used to prevent overfitting. By monitoring the model’s performance on the validation set and halting the training process when the performance starts to degrade, you can prevent the model from overfitting to the training data.
- Regularization: Regularization involves adding a penalty term to the loss function that discourages the model from learning overly complex patterns. This can help to prevent overfitting and improve the generalization ability of the model.
- Dropout: Dropout is a technique that involves randomly dropping out some of the neurons in the neural network during training. This forces the model to learn more robust and generalizable features, which can help to prevent overfitting.
- Cross-Validation: Cross-validation is a technique used to estimate the performance of a model on unseen data. By dividing the dataset into multiple folds and training the model on different combinations of folds, you can obtain a more accurate estimate of its generalization ability.
- Experimentation: Experimentation is key to finding the optimal number of epochs for a given problem. By trying different numbers of epochs and monitoring the model’s performance, you can identify the configuration that yields the best results.
4.5. Advantages and Disadvantages Summary Table
| Aspect | Advantage | Disadvantage |
|---|---|---|
| Model Performance | Allows the model to learn complex patterns and improve accuracy. | Risk of overfitting if not monitored carefully. |
| Progress Monitoring | Enables tracking of model improvement and identification of overfitting. | Requires diligent monitoring of validation metrics. |
| Memory Efficiency | Facilitates training on large datasets using mini-batches. | Need for appropriate batch size selection. |
| Early Stopping | Provides a mechanism to prevent overfitting and save computational resources. | May require multiple training runs to determine the optimal stopping point. |
| Computational Cost | N/A | Can be computationally expensive, especially with large datasets and complex models. |
| Optimization | Helps optimize the training process by enabling gradual learning and effective tracking. | Finding the right balance between underfitting and overfitting can be challenging. |
| Generalization | Enhances the model’s ability to generalize to new, unseen data. | Overfitting can reduce the model’s ability to generalize if not managed effectively. |
| Parameter Tuning | Allows for fine-tuning of model parameters over time. | Requires careful tuning to avoid overfitting and ensure convergence. |
| Dataset Complexity | Effective for handling complex datasets with intricate relationships. | May require more epochs for complex datasets, increasing the risk of overfitting. |
| Resource Management | N/A | Computational resources and time must be managed effectively to avoid excessive training costs. |
LEARNS.EDU.VN provides in-depth guidance and resources on these mitigation strategies, empowering you to train machine learning models effectively and avoid the pitfalls of overfitting.
5. Case Studies: Epochs in Action
To illustrate the practical application of epochs in machine learning, let’s explore a few case studies across different domains.
5.1. Image Classification with Convolutional Neural Networks (CNNs)
In image classification tasks, CNNs are often trained using multiple epochs to achieve high accuracy. For example, consider a scenario where we are training a CNN to classify images of cats and dogs.
The dataset consists of thousands of images of cats and dogs, and the goal is to train a model that can accurately classify new, unseen images. The CNN architecture typically consists of multiple convolutional layers, pooling layers, and fully connected layers.
To train the CNN, we would typically use a relatively large number of epochs, such as 100 or more. We would also use early stopping to prevent overfitting. By monitoring the model’s performance on a validation set, we can halt the training process when the performance starts to degrade.
In this case, multiple epochs allow the CNN to learn the complex features and patterns that distinguish cats from dogs. The convolutional layers extract features such as edges, textures, and shapes, while the fully connected layers learn to combine these features to make accurate predictions.
5.2. Natural Language Processing (NLP) with Recurrent Neural Networks (RNNs)
In NLP tasks, RNNs are often used to process sequential data, such as text. For example, consider a scenario where we are training an RNN to perform sentiment analysis on movie reviews.
The dataset consists of thousands of movie reviews, each labeled as either positive or negative. The goal is to train a model that can accurately predict the sentiment of new, unseen reviews. The RNN architecture typically consists of multiple recurrent layers, such as LSTMs or GRUs, followed by a fully connected layer.
To train the RNN, we would typically use multiple epochs, allowing the model to learn the sequential patterns and dependencies in the text data. The recurrent layers capture the contextual information in the reviews, while the fully connected layer learns to map these patterns to the corresponding sentiment labels.
5.3. Time Series Forecasting with Long Short-Term Memory (LSTM) Networks
LSTM networks, a type of RNN, are frequently employed in time series forecasting to predict future values based on historical data. For example, consider a scenario where we are training an LSTM network to forecast stock prices.
The dataset consists of historical stock prices over a period of several years. The goal is to train a model that can accurately predict future stock prices based on past trends. The LSTM architecture typically consists of multiple LSTM layers, followed by a fully connected layer.
Training the LSTM network involves using multiple epochs to enable the model to learn the temporal dependencies and patterns in the stock price data. The LSTM layers capture the long-term dependencies in the time series, while the fully connected layer learns to map these patterns to future stock prices.
5.4. Comparative Analysis of Epoch Usage
| Scenario | Model Type | Dataset | Epochs Used | Early Stopping | Key Findings |
|---|---|---|---|---|---|
| Image Classification | CNN | Cats vs. Dogs | 100+ | Yes | Multiple epochs crucial for learning complex image features; early stopping prevents overfitting. |
| Sentiment Analysis | RNN | Movie Reviews | 50+ | Yes | Epochs help the model capture sequential patterns in text; early stopping enhances generalization. |
| Stock Price Forecasting | LSTM | Historical Stock Prices | 100+ | Yes | LSTM layers benefit from multiple epochs to learn temporal dependencies; early stopping ensures optimal forecasting accuracy. |
| Medical Diagnosis | Deep Neural Networks | Medical Records | 75+ | Yes | Epochs help the model analyze the patterns of medical records for correct and accurate patient diagnosis. |
| Anomaly Detection | Isolation Forest | Financial Transactions | 60+ | No | Epochs are important for finding the anomalies in the financial transactions . |
These case studies demonstrate the importance of epochs in various machine learning applications. By using multiple epochs and employing techniques to prevent overfitting, you can train models that achieve high accuracy and generalize well to new, unseen data.
LEARNS.EDU.VN offers a wide range of resources and tutorials on these and other machine learning applications, empowering you to apply your knowledge of epochs to real-world problems.
6. Guidelines for Choosing the Right Number of Epochs
Selecting the appropriate number of epochs is a critical aspect of training machine learning models effectively. The optimal number of epochs depends on various factors, including the dataset size, model complexity, and computational resources. Here are some guidelines to help you make informed decisions:
6.1. Start with a Reasonable Estimate
Begin by estimating a reasonable range for the number of epochs based on the size and complexity of your dataset. For smaller datasets, a smaller number of epochs may be sufficient, while larger datasets may require more epochs to achieve optimal performance.
For example, if you are training a model on a dataset with a few thousand samples, you might start with a range of 20-50 epochs. If you are training on a dataset with millions of samples, you might start with a range of 100-200 epochs.
6.2. Monitor Validation Performance
Continuously monitor the model’s performance on a validation set during training. Track metrics such as accuracy, precision, recall, and F1-score to assess the model’s generalization ability.
Pay close attention to the trend of these metrics over epochs. If the validation performance is improving consistently, it indicates that the model is still learning and that you can continue training for more epochs.
However, if the validation performance starts to plateau or degrade, it may indicate that the model is overfitting and that you should consider stopping the training process.
6.3. Implement Early Stopping
Implement early stopping as a safeguard against overfitting. Early stopping involves monitoring the validation performance and halting the training process when the performance starts to degrade.
Set a patience parameter, which determines the number of epochs to wait before stopping the training process. If the validation performance does not improve for the specified number of epochs, the training process is halted.
Early stopping can help to prevent overfitting and save computational resources by stopping the training process when it is no longer beneficial.
6.4. Consider Learning Rate Schedules
Experiment with learning rate schedules to optimize the training process. Learning rate schedules involve adjusting the learning rate during training, typically by decreasing it over time.
Decreasing the learning rate can help the model to converge towards a more optimal solution and prevent it from getting stuck in local optima. Common learning rate schedules include step decay, exponential decay, and cosine annealing.
By experimenting with different learning rate schedules, you can fine-tune the training process and achieve better results.
6.5. Balance Underfitting and Overfitting
Strive to find a balance between underfitting and overfitting. Underfitting occurs when the model is not complex enough to capture the underlying patterns in the data. Overfitting occurs when the model learns the training data too well, memorizing the specific examples rather than generalizing to the underlying patterns.
To avoid underfitting, you may need to increase the model complexity or train for more epochs. To avoid overfitting, you may need to reduce the model complexity, use regularization techniques, or implement early stopping.
By carefully monitoring the model’s performance and adjusting the training parameters, you can find the sweet spot between underfitting and overfitting.
6.6. Adaptive Strategies
Adjust the number of epochs adaptively based on the complexity of the task and the model’s learning rate.
- Simple Tasks: For tasks with clear, straightforward patterns, fewer epochs might suffice.
- Complex Tasks: More complex tasks that demand intricate pattern recognition will likely need more epochs.
- High Learning Rate: With a high learning rate, fewer epochs are generally needed as the model updates more aggressively.
- Low Learning Rate: A lower learning rate requires more epochs to allow the model to converge effectively.
6.7. Epoch Selection Checklist
Here is a checklist to guide you in selecting the right number of epochs:
- [ ] Estimate a reasonable range for the number of epochs.
- [ ] Monitor the model’s performance on a validation set.
- [ ] Implement early stopping.
- [ ] Experiment with learning rate schedules.
- [ ] Strive to find a balance between underfitting and overfitting.
- [ ] Document your experiments and results.
By following these guidelines, you can make informed decisions about the number of epochs to use when training your machine learning models and achieve optimal performance.
LEARNS.EDU.VN provides comprehensive resources and tutorials on these and other advanced training techniques, empowering you to master the art of machine learning.
7. Modern Trends in Epoch Management
As the field of machine learning evolves, new trends and techniques are emerging in epoch management. These trends aim to improve the efficiency and effectiveness of the training process, enabling models to learn faster and generalize better.
7.1. Dynamic Epoch Adjustment
Dynamic epoch adjustment involves adaptively adjusting the number of epochs during training based on the model’s performance. This can be achieved by monitoring the validation performance and increasing or decreasing the number of epochs as needed.
For example, if the validation performance is improving rapidly, the number of epochs can be increased to allow the model to learn more effectively. If the validation performance is plateauing or degrading, the number of epochs can be decreased to prevent overfitting.
Dynamic epoch adjustment can help to optimize the training process and achieve better results.
7.2. Transfer Learning
Transfer learning involves using a pre-trained model as a starting point for a new task. The pre-trained model has already learned general features from a large dataset, which can be useful for a variety of tasks.
When using transfer learning, the pre-trained model is typically fine-tuned on the new task. This involves training the model for a few epochs on the new dataset, while keeping the weights of the pre-trained layers frozen.
Transfer learning can significantly reduce the training time and improve the performance of the model on the new task.
7.3. Meta-Learning
Meta-learning involves training a model to learn how to learn. The meta-learner learns to adapt to new tasks quickly and efficiently.
Meta-learning can be used to optimize the training process, including the number of epochs. The meta-learner can learn to predict the optimal number of epochs for a given task, based on the characteristics of the dataset and the model.
Meta-learning is a promising approach for automating the training process and achieving better results.
7.4. Automated Machine Learning (AutoML)
AutoML involves automating the entire machine learning pipeline, from data preprocessing to model selection to hyperparameter tuning. AutoML systems can automatically select the optimal number of epochs for a given task, based on the characteristics of the dataset and the model.
AutoML systems can significantly reduce the time and effort required to train machine learning models and can achieve state-of-the-art results.
7.5. Distributed Training
Distributed training involves training a model on multiple machines or GPUs. This can significantly reduce the training time, especially for large datasets and complex models.
When using distributed training, the dataset is typically divided into multiple partitions, and each machine or GPU trains the model on a different partition. The gradients are then aggregated across all machines or GPUs to update the model’s parameters.
Distributed training can significantly accelerate the training process and enable the training of larger and more complex models.
7.6. Knowledge Distillation
Knowledge distillation involves transferring knowledge from a large, complex model to a smaller, simpler model. The smaller model is trained to mimic the behavior of the larger model, which can improve its performance and generalization ability.
Knowledge distillation can be used to reduce the number of epochs required to train the smaller model. The smaller model can learn from the larger model more efficiently, reducing the training time and improving the performance.
7.7. Modern Trends Summary Table
| Trend | Description | Benefit |
|---|---|---|
| Dynamic Epoch Adjustment | Adaptively adjusts the number of epochs during training based on model performance. | Optimizes training process and prevents overfitting. |
| Transfer Learning | Uses a pre-trained model as a starting point for a new task. | Reduces training time and improves performance on new tasks. |
| Meta-Learning | Trains a model to learn how to learn, optimizing the training process. | Automates training process and improves results. |
| AutoML | Automates the entire machine learning pipeline, including epoch selection. | Reduces time and effort required to train models and achieves state-of-the-art results. |
| Distributed Training | Trains a model on multiple machines or GPUs. | Reduces training time and enables training of larger and more complex models. |
| Knowledge Distillation | Transfers knowledge from a large model to a smaller model. | Reduces the number of epochs required to train the smaller model and improves performance. |
LEARNS.EDU.VN provides up-to-date information and resources on these modern trends in epoch management, empowering you to stay ahead of the curve and leverage the latest techniques in your machine learning projects.
8. Optimizing Epochs for Various Learning Scenarios
Different machine learning scenarios require different approaches to epoch management. Understanding the specific requirements of each scenario is crucial for optimizing the training process and achieving the best possible results.
8.1. Supervised Learning
In supervised learning, the model is trained on a labeled dataset, where each example is associated with a target variable. The goal is to learn a mapping from the input features to the target variable.
For supervised learning tasks, it is important to monitor the model’s performance on both the training and validation sets. If the model is overfitting, you may need to reduce the number of epochs, use regularization techniques, or implement early stopping.
If the model is underfitting, you may need to increase the model complexity or train for more epochs.
8.2. Unsupervised Learning
In unsupervised learning, the model is trained on an unlabeled dataset, where there is no target variable. The goal is to discover hidden patterns and structures in the data.
For unsupervised learning tasks, it is more challenging to monitor the model’s performance. However, you can use metrics such as reconstruction error or clustering quality to assess the model’s progress.
The number of epochs required for unsupervised learning tasks depends on the complexity of the data and the desired level of granularity.
8.3. Reinforcement Learning
In reinforcement learning, the model (agent) learns to interact with an environment to maximize a reward signal. The agent learns by trial and error, receiving feedback from the environment in the form of rewards or penalties.
For reinforcement learning tasks, the number of epochs is typically replaced by the number of episodes. An episode represents one complete interaction between the agent and the environment.
The number of episodes required for reinforcement learning tasks depends on the complexity of the environment and the desired level of performance.
8.4. Semi-Supervised Learning
Semi-supervised learning combines supervised and unsupervised learning techniques. The model is trained on a dataset that contains both labeled and unlabeled examples.
Semi-supervised learning can be useful when labeled data is scarce or expensive to obtain. The unlabeled data can help the model to learn general features and structures, while the labeled data can help to fine-tune the model for the specific task.
For semi-supervised learning tasks, the number of epochs required depends on the amount of labeled and unlabeled data available, as well as the complexity of the task.
8.5. Self-Supervised Learning
Self-supervised learning is a technique where the model learns from unlabeled data by creating its own supervisory signals. The model is trained to predict certain aspects of the input data, such as missing parts or future values.
Self-supervised learning can be used to pre-train models on large amounts of unlabeled data, which can then be fine-tuned on downstream tasks with limited labeled data.
The number of epochs required for self-supervised learning tasks depends on the complexity of the data and the self-supervisory task.
8.6. Scenario-Specific Epoch Strategies Table
| Scenario | Data Type | Objective | Epoch Strategy Recommendations |
|---|---|---|---|
| Supervised Learning | Labeled | Learn mapping from input features to target variable. | Monitor validation performance, implement early stopping, and consider learning rate schedules to avoid overfitting or underfitting. Adjust the epochs as needed based on performance metrics. |
| Unsupervised Learning | Unlabeled | Discover hidden patterns and structures in the data. | Use reconstruction error or clustering quality to assess the model’s progress. Adjust the epochs based on the complexity of the data and the desired level of granularity. |
| Reinforcement Learning | Interactive | Learn to interact with an environment to maximize a reward signal. | Replace epochs with episodes, which represent complete interactions. The number of episodes depends on the complexity of the environment and desired performance. |
| Semi-Supervised | Mixed (Labeled & Unlabeled) | Leverage both labeled and unlabeled data for improved learning. | Train the model with careful monitoring, combining supervised and unsupervised learning techniques. Adjust the epochs based on the amount of labeled and unlabeled data available and the complexity of the task. |
| Self-Supervised | Unlabeled | Create supervisory signals from the data itself. | Pre-train models on large amounts of unlabeled data by training them to predict certain aspects of the input data. Adjust the epochs based on the complexity of the data and the self-supervisory task. |
| Transfer Learning | Labeled | Fine-tune an existing model that has already been trained. | Adjust and train only the model’s final layers with low epochs. Adjust the epochs based on the complexity of the final layers and the data. |
learns.edu.vn offers expert guidance and resources on optimizing epochs for various learning scenarios, enabling you to apply the most appropriate techniques for your specific machine learning tasks.
9. Practical Tips and Tricks
In addition to the general guidelines and recommendations discussed above, there are several practical tips and tricks that can help you optimize the number of epochs and improve the training process.
9.1. Visualize Training Progress
Visualize the training progress by plotting the training and validation loss curves. This can provide valuable insights into the model’s learning behavior and help you identify potential issues such as overfitting or underfitting.
If the training loss is decreasing but the validation loss is increasing, it indicates that the model is overfitting. In this case, you may need to reduce the number of epochs, use regularization techniques, or implement early stopping.
If both the training and validation loss are plateauing, it may indicate that the model has converged and that you can stop the training process.
9.2. Use Checkpointing
Use checkpointing to save the model’s weights at regular intervals during training. This can be useful if the training process is interrupted or if you want to experiment with different numbers of epochs.
By saving the model’s weights at regular intervals, you can easily resume the training process from the last checkpoint or load the weights of the best-performing model.
9.3. Experiment with Different Batch Sizes
Experiment with different batch sizes to find the optimal configuration for your problem. The batch size determines the number of examples that are processed in each iteration of the training process.
Smaller batch sizes can lead to faster convergence but may also result in more noisy gradients. Larger batch sizes can provide more stable gradients but may require more memory.
By experimenting with different batch sizes, you can find the configuration that yields the best results.
9.4. Tune Hyperparameters
Tune the hyperparameters of your model, such as the learning rate, momentum, and regularization strength. Hyperparameters control the behavior of the training process and can have a significant impact on the model’s performance.
Hyperparameter tuning can be a time-consuming process, but it is often necessary to achieve state-of-the-art results.

