Machine learning, a dynamic branch of computer science, empowers computers to learn from data without explicit programming. Within this field, supervised learning and unsupervised learning stand out as the two primary approaches. Both are powerful, but they tackle different types of problems and use different methods. This article provides a comprehensive comparison of supervised and unsupervised learning, exploring their methodologies, applications, advantages, and disadvantages to help you understand which approach is best suited for your needs.
What is Supervised Learning?
Supervised learning is a type of machine learning where algorithms learn from a labeled dataset. Think of it as learning with a teacher. In this context, “labeled” means that each piece of data is tagged with the correct answer or classification. The algorithm’s task is to learn a mapping function that can predict the output label for new, unseen input data based on the patterns it identifies in the labeled training data.
Imagine teaching a child to identify different types of fruits. You show them an apple and say, “This is an apple,” then a banana and say, “This is a banana,” and so on. Supervised learning works similarly. You feed the algorithm examples of inputs (like images of fruits) paired with their corresponding outputs (the fruit names). The algorithm learns the relationship between the fruit’s features (shape, color, texture) and its label.
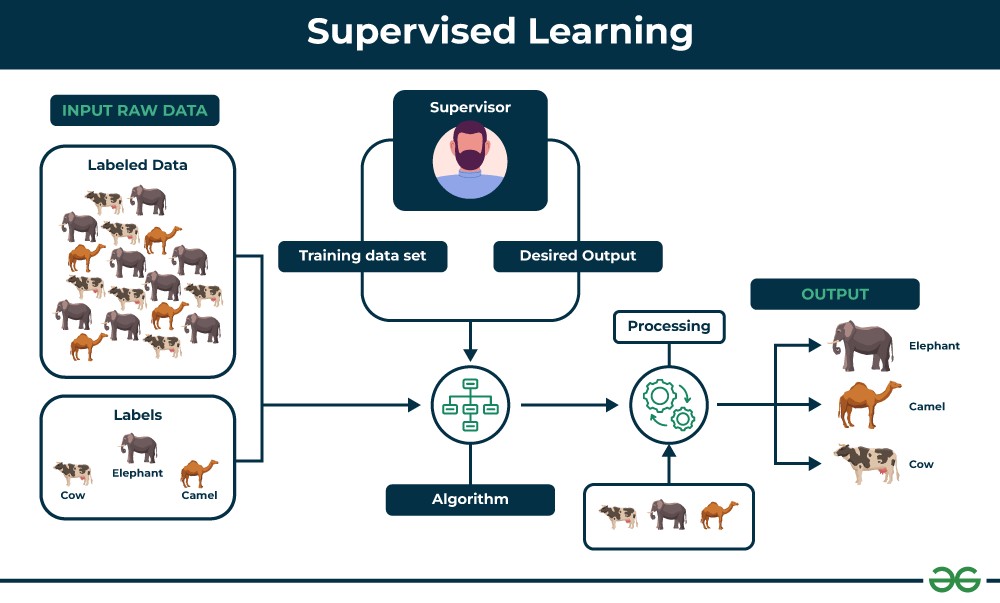 Supervised learning process illustrating training with labeled data and prediction on new data
Supervised learning process illustrating training with labeled data and prediction on new data
Key Characteristics of Supervised Learning:
- Labeled Data: Requires a dataset where inputs are paired with desired outputs.
- Training Phase: The algorithm learns from the labeled data to identify patterns and relationships.
- Prediction: The trained model is used to predict outputs for new, unlabeled data.
- Goal-Oriented: Aims to predict a specific outcome based on input features.
Example in Detail:
Consider the fruit basket example again. To train a supervised learning model to identify fruits:
- Data Collection: Gather a dataset of fruit images.
- Labeling: Manually label each image with the correct fruit name (e.g., “apple,” “banana,” “orange”).
- Training: Feed this labeled dataset to a supervised learning algorithm. The algorithm analyzes the images and their labels, learning to associate specific features with each fruit type. For instance, it might learn that round, red fruits are likely apples, while long, yellow fruits are bananas.
- Testing: Present the trained model with new, unlabeled fruit images. The model will use its learned knowledge to predict the fruit name for each new image.
Types of Supervised Learning Algorithms
Supervised learning tasks are broadly categorized into two main types: regression and classification.
1. Regression
Regression algorithms are used when the desired output is a continuous numerical value. The goal is to predict a value within a range, such as predicting house prices, stock market trends, or temperature forecasts.
Common Regression Algorithms:
- Linear Regression: Models the relationship between variables with a straight line.
- Polynomial Regression: Uses polynomial equations to model non-linear relationships.
- Support Vector Regression (SVR): Applies Support Vector Machines to regression problems.
- Decision Tree Regression: Uses decision trees to predict continuous values.
- Random Forest Regression: An ensemble method that combines multiple decision trees for improved accuracy.
2. Classification
Classification algorithms are used when the desired output is a categorical value or class label. The goal is to assign data points to predefined categories, such as classifying emails as spam or not spam, identifying the species of a plant from its image, or diagnosing a disease based on patient data.
Common Classification Algorithms:
- Logistic Regression: Despite its name, it’s a classification algorithm used for binary classification problems.
- Support Vector Machines (SVM): Effective for both linear and non-linear classification.
- Decision Trees: Tree-like structures that classify data based on a series of decisions.
- Random Forests: An ensemble of decision trees, robust and accurate for classification.
- Naive Bayes: A probabilistic classifier based on Bayes’ theorem, often used in text classification.
- K-Nearest Neighbors (KNN): Classifies data points based on the majority class of their nearest neighbors.
Evaluating Supervised Learning Models
Evaluating the performance of supervised learning models is crucial to ensure they are accurate and reliable. Different metrics are used depending on whether the task is regression or classification.
Evaluation Metrics for Regression
- Mean Squared Error (MSE): Calculates the average squared difference between predicted and actual values. Lower MSE indicates better performance.
- Root Mean Squared Error (RMSE): The square root of MSE, provides an easily interpretable measure of prediction error in the original units. Lower RMSE is better.
- Mean Absolute Error (MAE): Measures the average absolute difference between predicted and actual values. Less sensitive to outliers than MSE and RMSE.
- R-squared (Coefficient of Determination): Represents the proportion of variance in the target variable explained by the model. Higher R-squared (closer to 1) indicates a better fit.
Evaluation Metrics for Classification
- Accuracy: The percentage of correctly classified instances. Calculated as (True Positives + True Negatives) / Total Predictions.
- Precision: The proportion of correctly predicted positive instances out of all instances predicted as positive. Calculated as True Positives / (True Positives + False Positives). Focuses on the accuracy of positive predictions.
- Recall (Sensitivity): The proportion of correctly predicted positive instances out of all actual positive instances. Calculated as True Positives / (True Positives + False Negatives). Focuses on the model’s ability to find all positive instances.
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure of a model’s performance, especially when classes are imbalanced.
- Confusion Matrix: A table summarizing the performance of a classification model by showing the counts of true positives, true negatives, false positives, and false negatives. Helps visualize model performance and identify areas of confusion between classes.
Applications of Supervised Learning
Supervised learning is widely applied across numerous domains to solve real-world problems:
- Spam Filtering: Classifying emails as spam or not spam based on email content and metadata.
- Image Classification: Identifying objects, scenes, or categories within images, used in image search, medical imaging analysis, and autonomous vehicles.
- Medical Diagnosis: Predicting diseases or conditions based on patient data like symptoms, test results, and medical history.
- Fraud Detection: Identifying fraudulent transactions by analyzing patterns in financial data.
- Natural Language Processing (NLP): Tasks like sentiment analysis (determining the emotion in text), language translation, and text summarization rely heavily on supervised learning.
- Customer Churn Prediction: Predicting which customers are likely to stop using a service, enabling businesses to take proactive retention measures.
- Risk Assessment: Evaluating the risk associated with loans or insurance applications based on applicant data.
Advantages of Supervised Learning
- Leverages Labeled Data: Effectively uses labeled data to learn precise mappings and make accurate predictions.
- Performance Optimization: Algorithms can be optimized for specific performance metrics, allowing for targeted improvements.
- Solves Real-World Problems: Applicable to a wide range of practical problems in various industries.
- Classification and Regression Tasks: Versatile for both categorical and continuous output predictions.
- Controlled Output Classes: Allows for defining and controlling the specific categories or outputs the model learns to predict.
Disadvantages of Supervised Learning
- Requires Labeled Data: The need for labeled data can be a significant limitation, as labeling large datasets can be time-consuming, expensive, and require expertise.
- Computationally Intensive: Training complex supervised learning models, especially on large datasets, can be computationally demanding and time-consuming.
- Not Suitable for All Problems: Not effective for discovering hidden patterns or structures in data when labels are unavailable or unknown.
- Complexity with Big Data: Classifying and labeling extremely large datasets can become increasingly challenging.
- Overfitting: Models can overfit to the training data, performing well on training data but poorly on new, unseen data.
What is Unsupervised Learning?
Unsupervised learning, in contrast to supervised learning, works with unlabeled data. There’s no “teacher” providing correct answers. Instead, the algorithm explores the data to find inherent structures, patterns, and relationships without any prior guidance. The goal is to understand the underlying organization of the data and extract meaningful insights from it.
Think of giving a child a box of assorted toys they’ve never seen before. Without instructions, they might start grouping the toys based on color, shape, size, or material. This self-discovery process is similar to unsupervised learning. The algorithm is left to its own devices to find meaningful groupings or representations in the data.
Key Characteristics of Unsupervised Learning:
- Unlabeled Data: Operates on datasets without predefined labels or categories.
- Pattern Discovery: Aims to identify hidden structures, patterns, and relationships in the data.
- No Supervision: Algorithms learn without explicit guidance or correct answers.
- Data Exploration: Used for exploratory data analysis and gaining insights from unlabeled data.
Example in Detail:
Imagine you have a collection of animal images (dogs, cats, birds, etc.) but without any labels indicating the animal type. Using unsupervised learning:
- Data Input: Feed the unlabeled animal images to an unsupervised learning algorithm.
- Pattern Identification: The algorithm analyzes the images, looking for similarities in features like shape, texture, color patterns, and edges.
- Clustering: Based on the identified patterns, the algorithm groups similar images together into clusters. One cluster might contain images with furry bodies, four legs, and pointed ears (dogs), another with smaller bodies, whiskers, and varied fur patterns (cats), and so on.
- Insight Generation: Even without prior labels, the algorithm can successfully separate the images into meaningful groups based on their inherent characteristics, revealing underlying structure in the data. You can then analyze these clusters to understand the characteristics of each group and potentially assign labels based on the discovered patterns.
Types of Unsupervised Learning Algorithms
Unsupervised learning algorithms are primarily categorized into clustering and association rule learning.
1. Clustering
Clustering algorithms aim to group similar data points together based on their intrinsic characteristics. The goal is to partition the data into clusters such that data points within a cluster are more similar to each other than to those in other clusters.
Types of Clustering:
- Partitioning Clustering (e.g., K-Means): Divides data into non-overlapping clusters, where each data point belongs to exactly one cluster.
- Hierarchical Clustering: Creates a hierarchy of clusters, represented as a tree-like structure (dendrogram). Can be agglomerative (bottom-up) or divisive (top-down).
- Density-Based Clustering (e.g., DBSCAN): Identifies clusters as dense regions in the data space, separated by sparser regions. Effective at finding clusters of arbitrary shapes and handling noise.
- Distribution-Based Clustering (e.g., Gaussian Mixture Models – GMMs): Assumes that data points are generated from a mixture of probability distributions (e.g., Gaussian distributions).
Common Clustering Algorithms:
- K-Means Clustering: Partitions data into k clusters by iteratively assigning data points to the nearest cluster centroid and updating centroids.
- Hierarchical Clustering (Agglomerative and Divisive): Builds a hierarchy of clusters by successively merging or splitting clusters.
- Principal Component Analysis (PCA): Primarily used for dimensionality reduction, but can also reveal clusters in lower-dimensional space.
- Singular Value Decomposition (SVD): Similar to PCA, used for dimensionality reduction and can aid in clustering.
- Independent Component Analysis (ICA): Separates multivariate signals into additive subcomponents that are statistically independent.
- Gaussian Mixture Models (GMMs): Models clusters as Gaussian distributions and uses expectation-maximization (EM) to find cluster parameters.
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN): Groups together data points that are closely packed together, marking as outliers points that lie alone in low-density regions.
2. Association Rule Learning
Association rule learning aims to discover interesting relationships or associations between variables in large datasets. It identifies rules that describe frequent co-occurrence patterns in data. A classic example is market basket analysis, where association rules can reveal products that are frequently purchased together.
Common Association Rule Learning Algorithms:
- Apriori Algorithm: A foundational algorithm for association rule mining, uses frequent itemsets to generate association rules.
- Eclat Algorithm: An efficient algorithm for frequent itemset mining using vertical data format.
- FP-Growth Algorithm: Mines frequent itemsets without candidate generation, improving efficiency compared to Apriori.
Evaluating Unsupervised Learning Models
Evaluating unsupervised learning models is more challenging than evaluating supervised models because there are no ground truth labels to compare against. Evaluation often relies on intrinsic metrics that assess the quality of the discovered structures or patterns.
Evaluation Metrics for Clustering:
- Silhouette Score: Measures how well each data point fits within its cluster and how separated it is from other clusters. Ranges from -1 to 1, with higher scores indicating better clustering.
- Calinski-Harabasz Score (Variance Ratio Criterion): Calculates the ratio of between-cluster variance to within-cluster variance. Higher scores indicate better-defined clusters.
- Davies-Bouldin Index: Measures the average similarity ratio of each cluster with its most similar cluster. Lower scores indicate better clustering (better separation and compactness).
- Adjusted Rand Index (ARI): Measures the similarity between two clusterings, considering all pairs of samples and counting pairs that are assigned in the same or different clusters in both clusterings. Adjusted for chance, ranges from -1 to 1 (though typically 0 to 1 in practice), higher is better.
Evaluation Metrics for Association Rule Learning:
Evaluation of association rules often focuses on metrics like:
- Support: The frequency of an itemset appearing in the dataset.
- Confidence: The probability of item Y being purchased given that item X is purchased (for a rule X -> Y).
- Lift: Measures how much more often X and Y occur together than expected if they were independent. Lift > 1 indicates a positive association.
Applications of Unsupervised Learning
Unsupervised learning is powerful for exploring data, uncovering hidden patterns, and gaining insights in various fields:
- Anomaly Detection: Identifying unusual data points or outliers that deviate significantly from the norm, used in fraud detection, network intrusion detection, and equipment failure prediction.
- Customer Segmentation: Grouping customers based on their purchasing behavior, demographics, or other characteristics to personalize marketing efforts and improve customer service.
- Recommendation Systems: Recommending products, movies, or music to users based on their past behavior and preferences, often by identifying clusters of users with similar tastes.
- Image Analysis and Computer Vision: Tasks like image segmentation (dividing an image into regions) and object recognition (without pre-defined labels) can utilize unsupervised learning techniques.
- Scientific Discovery: Analyzing large scientific datasets to uncover hidden relationships and patterns, leading to new hypotheses and insights in fields like biology, astronomy, and materials science.
- Dimensionality Reduction: Reducing the number of variables in a dataset while preserving essential information, simplifying data analysis and visualization.
Advantages of Unsupervised Learning
- Works with Unlabeled Data: Can extract valuable insights from datasets where labeling is impractical or impossible.
- Pattern Discovery: Excels at finding previously unknown patterns, structures, and relationships in data.
- Dimensionality Reduction: Effective for reducing the complexity of high-dimensional data.
- Exploratory Data Analysis: Ideal for exploring data and gaining initial understanding without predefined goals.
- Versatile Applications: Applicable to a wide range of problems, from anomaly detection to recommendation systems.
Disadvantages of Unsupervised Learning
- Difficult to Evaluate: Assessing the accuracy and effectiveness of unsupervised learning models can be challenging due to the lack of ground truth labels.
- Less Accurate Results: Results might be less precise compared to supervised learning when a clear target output is needed.
- Interpretation Required: Requires human expertise to interpret the discovered patterns and clusters and assign meaningful labels or significance.
- Sensitive to Data Quality: Performance can be affected by noisy data, outliers, and missing values.
- Computational Complexity for Some Algorithms: Some unsupervised algorithms, especially for large datasets, can be computationally expensive.
Supervised vs. Unsupervised Machine Learning: A Detailed Comparison
To summarize the key differences, here’s a comparative table:
| Feature | Supervised Machine Learning | Unsupervised Machine Learning |
|---|---|---|
| Input Data | Labeled data (input-output pairs) | Unlabeled data |
| Training | Explicitly trained with labeled examples | Learns patterns without explicit guidance |
| Goal | Predict output for new input data | Discover patterns, structures, groupings |
| Output | Desired output is known and provided | Desired output is not predefined |
| Complexity | Generally simpler algorithms | Can involve more complex algorithms |
| Accuracy | Potentially high accuracy when data is labeled | Accuracy can be harder to define and measure |
| Number of Classes | Number of classes is often known beforehand | Number of classes may be unknown or discovered |
| Data Analysis | Often offline analysis after training | Can be used for real-time data analysis |
| Example Algorithms | Linear Regression, Logistic Regression, SVM, Decision Trees, Random Forests, Neural Networks | K-Means Clustering, Hierarchical Clustering, DBSCAN, Apriori, PCA |
| Model Testing | Model performance can be directly tested against labeled data | Model evaluation is often intrinsic and qualitative |
| Synonyms | Classification, Regression | Clustering, Association |
| Illustrative Example | Image classification (identify cat vs. dog) | Customer segmentation (group similar customers) |
| Need for Supervision | Requires supervision (labeled data) | No supervision needed (unlabeled data) |
Conclusion
Supervised and unsupervised learning are indispensable tools in the machine learning landscape. Supervised learning excels when you have labeled data and a clear target variable to predict, making it suitable for tasks like classification and regression. Unsupervised learning, on the other hand, shines when dealing with unlabeled data and the goal is to explore data structure, discover hidden patterns, and gain insights. Choosing between them depends heavily on the nature of your data, the problem you are trying to solve, and the availability of labeled information. Understanding the strengths and limitations of each approach is key to effectively applying machine learning to real-world challenges.
Frequently Asked Questions (FAQs)
1. What is the primary difference between supervised and unsupervised machine learning?
The fundamental difference lies in the type of data they use for training. Supervised learning uses labeled data, where each data point has a known output or label. Unsupervised learning uses unlabeled data, where the algorithm must find patterns and structures without explicit guidance.
2. When should I use supervised learning?
Use supervised learning when you have a labeled dataset and you want to predict a specific outcome for new data based on what you’ve learned from the labeled examples. Common scenarios include classification (categorizing data) and regression (predicting continuous values).
3. What are some typical applications of supervised learning?
Supervised learning is widely used for:
- Spam detection
- Image recognition
- Medical diagnosis
- Fraud detection
- Sentiment analysis
4. When is unsupervised learning the more appropriate choice?
Unsupervised learning is ideal when you have unlabeled data and you want to explore the data’s structure, discover hidden patterns, or group similar data points together. It’s useful for tasks like clustering, dimensionality reduction, and anomaly detection.
5. What are some common use cases for unsupervised learning?
Unsupervised learning is often applied in:
- Customer segmentation
- Recommendation systems
- Anomaly detection
- Dimensionality reduction
- Scientific data analysis
6. Can I combine supervised and unsupervised learning?
Yes, combining these approaches is common and often beneficial. For example, you might use unsupervised learning for feature extraction or dimensionality reduction on unlabeled data, and then use supervised learning on these extracted features with a smaller labeled dataset for prediction or classification. This is sometimes referred to as semi-supervised learning when you have a small amount of labeled data and a large amount of unlabeled data.
