If you’re looking to understand the cutting edge of Artificial Intelligence, especially in fields like Natural Language Processing and beyond, then transformers are the key. These aren’t the transforming robots of fiction, but a revolutionary type of neural network model that’s reshaping the landscape of machine learning.
What Exactly is a Transformer Model in Machine Learning?
At its core, a transformer model is a neural network architecture designed to understand context and meaning by analyzing relationships within sequential data. Think of it like deciphering the nuances of human language – understanding not just individual words, but how those words relate to each other in a sentence to convey meaning. This capability is achieved through a sophisticated set of mathematical techniques known as attention or self-attention. These mechanisms allow the model to identify subtle dependencies, even between distant elements within a sequence of data, making them exceptionally powerful.
First introduced by Google researchers in a groundbreaking 2017 paper, transformers have rapidly become one of the most impactful classes of models in the AI domain. They are the driving force behind what many now refer to as the transformer AI revolution, pushing the boundaries of what’s possible with machine learning.
Researchers at Stanford University have even termed transformers “foundation models” in a significant August 2021 study. This designation highlights their belief that transformers are not just an incremental improvement, but rather a fundamental shift in the AI paradigm. As they stated, “the sheer scale and scope of foundation models over the last few years have stretched our imagination of what is possible,” underscoring the transformative potential of this technology.
The Diverse Capabilities of Transformer Models
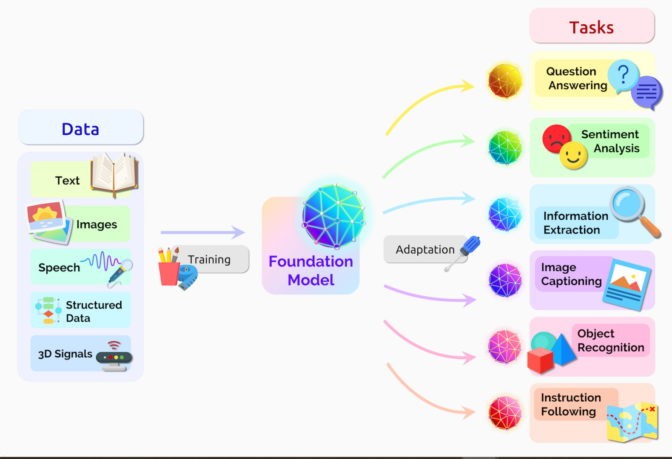
Transformer models are no longer confined to research labs; they are actively being deployed across a wide spectrum of real-world applications, demonstrating their versatility and effectiveness.
One of the most prominent applications is in real-time translation, bridging communication gaps in text and speech. This capability is invaluable in global meetings, diverse classrooms, and for accessibility for hearing-impaired individuals.
Beyond language, transformers are making significant strides in scientific research, particularly in bioinformatics. They are being used to analyze the complex sequences of genes in DNA and amino acids in proteins. This analysis is crucial for understanding biological processes and accelerating the pace of drug design and discovery.
Transformer models, often referred to as foundation models, are being applied across numerous data sources for a wide range of applications.
The ability of transformers to detect patterns and anomalies extends to various business applications as well. They are being used to prevent fraud, optimize manufacturing processes, personalize online recommendations, and enhance the efficiency and accuracy of healthcare systems.
Perhaps most ubiquitously, transformer models power the search engines we use daily, like Google Search and Microsoft Bing, ensuring relevant and contextually accurate search results.
The Self-Improving Cycle of Transformer AI
The power of transformer models is amplified by a virtuous cycle of learning and improvement. Their effectiveness stems from being trained on massive datasets. As transformers are deployed more widely due to their accuracy, they generate even more data. This influx of new data can then be used to refine and improve the models further, creating a continuous loop of enhancement. This self-improving nature is a key factor in the rapid advancement of transformer AI.
Stanford researchers emphasize that transformers represent the next major stage in AI evolution, ushering in the era of transformer AI. NVIDIA founder and CEO Jensen Huang highlighted this point in a recent keynote address, stating, “Transformers made self-supervised learning possible, and AI jumped to warp speed.” This encapsulates the dramatic acceleration of AI capabilities enabled by transformer architectures.
Transformers: Surpassing CNNs and RNNs in Many Domains
The rise of transformers marks a significant shift in the preferred architectures for deep learning. Just five years ago, Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) were the dominant models. However, transformers are increasingly replacing them in a wide array of tasks.
The sheer volume of research underscores this transition. A remarkable 70 percent of AI-related papers on arXiv in the past two years mention transformers. This is a stark contrast to a 2017 IEEE study which identified RNNs and CNNs as the most popular models for pattern recognition. This rapid adoption highlights the superior performance and versatility of transformer models.
Advantages of Transformers: Unlabeled Data and Enhanced Performance
Traditional neural networks often require large, labeled datasets for training. Creating these datasets is expensive, time-consuming, and limits the scalability of AI solutions. Transformers overcome this limitation by effectively finding patterns and relationships within data mathematically, eliminating the need for extensive labeled datasets. This unlocks the potential of using the vast amounts of unlabeled data available on the internet and in corporate databases, which includes trillions of images and petabytes of text.
Furthermore, the mathematical computations at the heart of transformers are inherently parallelizable. This means transformer models can leverage parallel processing architectures, like GPUs, to achieve significantly faster training and inference times compared to previous architectures.
This efficiency and performance are reflected in benchmark results. Transformers consistently dominate leaderboards like SuperGLUE, a recognized benchmark for evaluating language-processing systems since 2019.
Understanding the Attention Mechanism in Transformers
Like most neural networks, transformer models are built upon encoder/decoder blocks to process data. However, transformers incorporate strategic additions to these blocks, primarily the attention mechanism, which gives them their unique power.
An inside look at a transformer model, adapted from a presentation by Aidan Gomez, a key contributor to the original transformer paper.
Transformers utilize positional encoders to tag data elements as they enter and exit the network. Attention units then analyze these tags, effectively creating an algebraic map that represents the relationships between each data element within the sequence.
These attention queries are often executed in parallel using a technique called multi-headed attention, which involves calculating a matrix of equations. This sophisticated approach allows computers to discern patterns and relationships in data with a level of understanding that approaches human comprehension.
Self-Attention: Unlocking Meaning and Context
The power of self-attention is best illustrated through examples of language understanding. Consider these sentences:
- “She poured water from the pitcher to the cup until it was full.”
- “She poured water from the pitcher to the cup until it was empty.”
Humans intuitively understand that “it” refers to the cup in the first sentence and the pitcher in the second, based on context and relationships between words. Transformer models, leveraging self-attention, can achieve a similar level of contextual understanding.
Ashish Vaswani, a lead researcher on the seminal 2017 transformer paper from Google Brain, explains, “Meaning is a result of relationships between things, and self-attention is a general way of learning relationships.” He further noted that machine translation served as an ideal proving ground for self-attention, as it necessitates understanding both short and long-distance relationships between words within sentences. The success in machine translation demonstrated self-attention’s broader potential as a versatile tool for learning complex relationships in data.
The Naming of “Transformers”
The term “transformer” itself is a direct reflection of the central role of the attention mechanism. Google researchers considered naming their 2017 model “Attention Net” due to the significance of attention.
However, as Vaswani recounts, “Attention Net didn’t sound very exciting.” Jakob Uszkoreit, another key member of the team, proposed the name “Transformer.” While Vaswani jokingly argued for “transforming representations,” the name “Transformer” stuck, highlighting the architecture’s ability to transform input data representations through attention mechanisms.
The Genesis of Transformers: A Breakthrough at Google
The Google team’s paper presented at the 2017 NeurIPS conference marked a pivotal moment. They introduced the transformer architecture and demonstrated its record-breaking accuracy in machine translation tasks.
Through a combination of innovative techniques, they trained their model on NVIDIA GPUs in just 3.5 days, a fraction of the time and cost previously required for training comparable models. This efficiency was achieved while training on massive datasets containing up to a billion word pairs.
Aidan Gomez, an intern at Google in 2017 and a contributor to the groundbreaking work, described the intense period leading up to the paper submission: “It was an intense three-month sprint to the paper submission date.” He and Ashish Vaswani even worked through the night before submission. Despite the exhaustion, Vaswani’s conviction about the transformative potential of their work was strong, a conviction that has since been emphatically validated by the widespread impact of transformers. Gomez himself is now CEO of Cohere, a company providing language processing services powered by transformers.
A Turning Point for Machine Learning: The BERT Era
Vaswani recognized the significance of their results, noting the excitement of surpassing the performance of CNN-based models developed by a Facebook team. He understood that this was likely “an important moment in machine learning.”
The following year, another Google team further refined transformer technology by introducing Bidirectional Encoder Representations from Transformers, or BERT. BERT processes text sequences both forwards and backwards, enabling a more comprehensive understanding of word relationships and sentence meaning. BERT achieved 11 new performance records and became a core component of Google’s search algorithm.
The impact of BERT was immediate and global. Within weeks, researchers worldwide began adapting BERT for diverse use cases across languages and industries. Anders Arpteg, a veteran machine learning researcher, noted that text is “one of the most common data types companies have,” explaining the rapid and widespread adoption of BERT.
Transformers in Action: Expanding to Science and Healthcare
The versatility of transformer models quickly extended beyond language processing into scientific and healthcare domains.
DeepMind, based in London, made significant advancements in understanding proteins, the fundamental building blocks of life, using a transformer model called AlphaFold2. As described in a Nature article, AlphaFold2 processes amino acid chains, analogous to text strings, to predict protein folding with unprecedented accuracy. This breakthrough has the potential to significantly accelerate drug discovery processes.
AstraZeneca and NVIDIA collaborated to develop MegaMolBART, a specialized transformer model for drug discovery. MegaMolBART, derived from AstraZeneca’s MolBART transformer, is trained on a massive unlabeled database of chemical compounds using NVIDIA’s Megatron framework, designed for building large-scale transformer models.
Reading Molecules and Medical Records with AI
Ola Engkvist, Head of Molecular AI at AstraZeneca, explained the rationale behind MegaMolBART: “Just as AI language models can learn the relationships between words in a sentence, our aim is that neural networks trained on molecular structure data will be able to learn the relationships between atoms in real-world molecules.” This analogy highlights the power of transformers to extract meaningful relationships from complex data, regardless of its format.
Separately, the University of Florida and NVIDIA partnered to create GatorTron, a transformer model aimed at extracting valuable insights from vast amounts of clinical data to expedite medical research. This initiative underscores the growing role of transformers in transforming healthcare and medical research.
The Scaling Trend: Transformers Grow Larger and More Powerful
Research has consistently shown that larger transformer models generally exhibit better performance.
The Rostlab at the Technical University of Munich, pioneers in the intersection of AI and biology, transitioned from RNNs with 90 million parameters to transformer models boasting 567 million parameters within 18 months, demonstrating the trend towards larger models.
Researchers at Rostlab demonstrate language models trained without labeled data effectively identifying signals within protein sequences.
OpenAI’s Generative Pretrained Transformer (GPT) series exemplifies this scaling trend. The latest iteration, GPT-3, features a staggering 175 billion parameters, a massive increase from GPT-2’s 1.5 billion.
GPT-3’s immense size enables it to respond to user queries and perform tasks even without specific training for those tasks, showcasing emergent capabilities arising from scale. Companies like Cisco, IBM, and Salesforce are already leveraging GPT-3 for various applications.
The Era of Mega Transformers: MT-NLG
NVIDIA and Microsoft achieved a new milestone with the Megatron-Turing Natural Language Generation model (MT-NLG), a colossal transformer model with 530 billion parameters. MT-NLG was launched alongside the NVIDIA NeMo Megatron framework, designed to empower businesses to create their own massive transformer models for customized chatbots, personal assistants, and other language-based AI applications.
MT-NLG made its public debut as the “brain” behind TJ, the Toy Jensen avatar, during NVIDIA’s GTC 2021 keynote. Mostofa Patwary, who led the NVIDIA team that trained MT-NLG, described the excitement of seeing TJ effectively answer questions, demonstrating the power of their work.
TJ, the Toy Jensen avatar, jokingly attributes his intelligence to Megatron at GTC 2022.
Training such massive models is a significant undertaking, requiring vast computational resources and time. MT-NLG was trained using hundreds of billions of data elements, a process that involved thousands of GPUs running for weeks. Patwary emphasized the high stakes involved, noting that unsuccessful training attempts on such a scale could lead to project cancellation due to the immense cost and time investment.
The Future: Trillion-Parameter Transformers and Beyond
The field is rapidly moving towards even larger models. Many AI engineers are currently focused on developing trillion-parameter transformers and exploring their potential applications.
Patwary explains the ongoing research: “We’re constantly exploring how these big models can deliver better applications. We also investigate in what aspects they fail, so we can build even better and bigger ones.” This iterative process of development and refinement is driving continuous progress in transformer technology.
To support the computational demands of these massive models, NVIDIA’s latest accelerator, the NVIDIA H100 Tensor Core GPU, incorporates a dedicated Transformer Engine and supports the new FP8 format, significantly accelerating training while maintaining accuracy. Huang stated at GTC that these advancements can reduce transformer model training times from weeks to days, dramatically accelerating the development cycle.
Mixture of Experts (MoE): Enhancing Transformer Efficiency
Google researchers introduced the Switch Transformer, one of the first trillion-parameter models, which utilizes a mixture-of-experts (MoE) architecture and AI sparsity techniques to improve language processing performance and accelerate pre-training speeds by up to 7x.
The encoder architecture of the Switch Transformer, the first model to reach a trillion parameters.
Microsoft Azure collaborated with NVIDIA to implement an MoE transformer for its Translator service, further demonstrating the practical benefits of this approach in enhancing efficiency and scalability.
Addressing the Challenges of Transformer Models
While larger models offer performance gains, researchers are also actively exploring ways to develop simpler, more efficient transformers with fewer parameters that can achieve comparable performance.
Aidan Gomez of Cohere highlights the promise of retrieval-based models, citing DeepMind’s Retro model as an example. Retrieval-based models learn by querying a knowledge database, allowing for more selective and controlled knowledge integration. Gomez believes this approach could “bend the curve” in terms of model efficiency and performance.
The timeline shows the increasing size of transformer models as researchers pursue higher performance.
Ashish Vaswani, now co-founder of an AI startup, envisions future models that learn more like humans, drawing context from the real world with minimal data. He anticipates models that perform more upfront computation and incorporate better user feedback mechanisms. His goal is to develop models that are truly helpful in people’s daily lives.
Towards Safe and Responsible Transformer AI
Beyond efficiency, ensuring the safety and ethical implications of transformer models is a critical area of research. Researchers are actively working to mitigate bias and toxicity in models, addressing concerns about models amplifying harmful or incorrect language. Stanford University established the Center for Research on Foundation Models to specifically address these ethical challenges.
Shrimai Prabhumoye, a research scientist at NVIDIA, emphasizes the importance of context in addressing bias: “Today, most models look for certain words or phrases, but in real life these issues may come out subtly, so we have to consider the whole context.” This highlights the need for nuanced approaches to ensure responsible AI development.
Gomez echoes this concern, stating that safety is paramount for Cohere: “No one is going to use these models if they hurt people, so it’s table stakes to make the safest and most responsible models.”
The Future Horizon of Transformer Technology
Vaswani envisions a future where attention-powered, self-learning transformers approach the long-held aspiration of Artificial General Intelligence (AGI). He believes that transformers offer “a chance of achieving some of the goals people talked about when they coined the term ‘general artificial intelligence’ and I find that north star very inspiring.”
He concludes with optimism about the current state of AI: “We are in a time where simple methods like neural networks are giving us an explosion of new capabilities.”
The journey of transformer technology is just beginning. With ongoing research and development, coupled with powerful hardware like the NVIDIA H100 GPU, transformer training and inference will continue to accelerate, paving the way for even more groundbreaking applications and potentially bringing us closer to the elusive goal of general AI.
To delve deeper into the world of transformers, explore the NVIDIA Technical Blog.