Trees, in their natural elegance, represent growth and branching possibilities. This analogy extends beautifully into the realm of machine learning, where decision trees stand as powerful algorithms for both classification and regression tasks. Like an upside-down tree, a decision tree algorithm starts at a root and branches out, visualizing different decision paths and outcomes. This visual nature makes them incredibly valuable in understanding and refining machine learning models.
Let’s delve into the world of decision trees, exploring their significance in machine learning and examining the common types. This exploration will lay a solid foundation for your journey in this exciting field.
What is a Decision Tree in Machine Learning?
At its core, a decision tree is a supervised learning algorithm. This means it learns from labeled data to perform classification and regression tasks. Regression is a statistical method used for predictive modeling, and decision trees leverage this to either categorize data or forecast future trends.
Imagine a flowchart – that’s essentially what a decision tree looks like. It begins with a root node, posing an initial question about the data. This question leads to branches, each representing a potential answer or condition. These branches then connect to decision (internal) nodes, which introduce further questions, leading to more branches and outcomes. This process continues until the data reaches a terminal (or “leaf”) node, signifying a final decision or prediction.
In the landscape of machine learning, supervised learning is a key approach, alongside unsupervised, reinforcement, and semi-supervised learning. Decision trees are particularly useful for visualizing how supervised learning algorithms arrive at specific conclusions, making the learning process more transparent and interpretable.
To get a visual understanding of decision trees, check out this introductory video:
[Insert Video Placeholder Here – If video URL was provided, it would be here]
Expanding Your Knowledge: Supervised Learning
For those eager to deepen their understanding of supervised learning, the Introduction to Supervised Learning: Regression and Classification course, offered by DeepLearningAI and Stanford University, is an excellent resource. In approximately 33 hours, you’ll gain a comprehensive introduction to modern machine learning, covering supervised learning techniques and algorithms like decision trees, multiple linear regression, neural networks, and logistic regression.
Alt text: Abstract purple pattern representing decision tree concepts in machine learning.
The Importance of Decision Trees in Machine Learning
Decision trees are not just visually appealing; they are also practically significant in machine learning. Their strength lies in providing a clear and effective method for decision-making. By structuring a problem and mapping out all possible outcomes, decision trees empower developers to analyze the potential consequences of each decision. Furthermore, as the algorithm processes more data, it enhances its ability to predict outcomes for new, unseen data.
Consider this simple decision tree example, analyzing the everyday decision of whether to buy toilet paper at the supermarket:
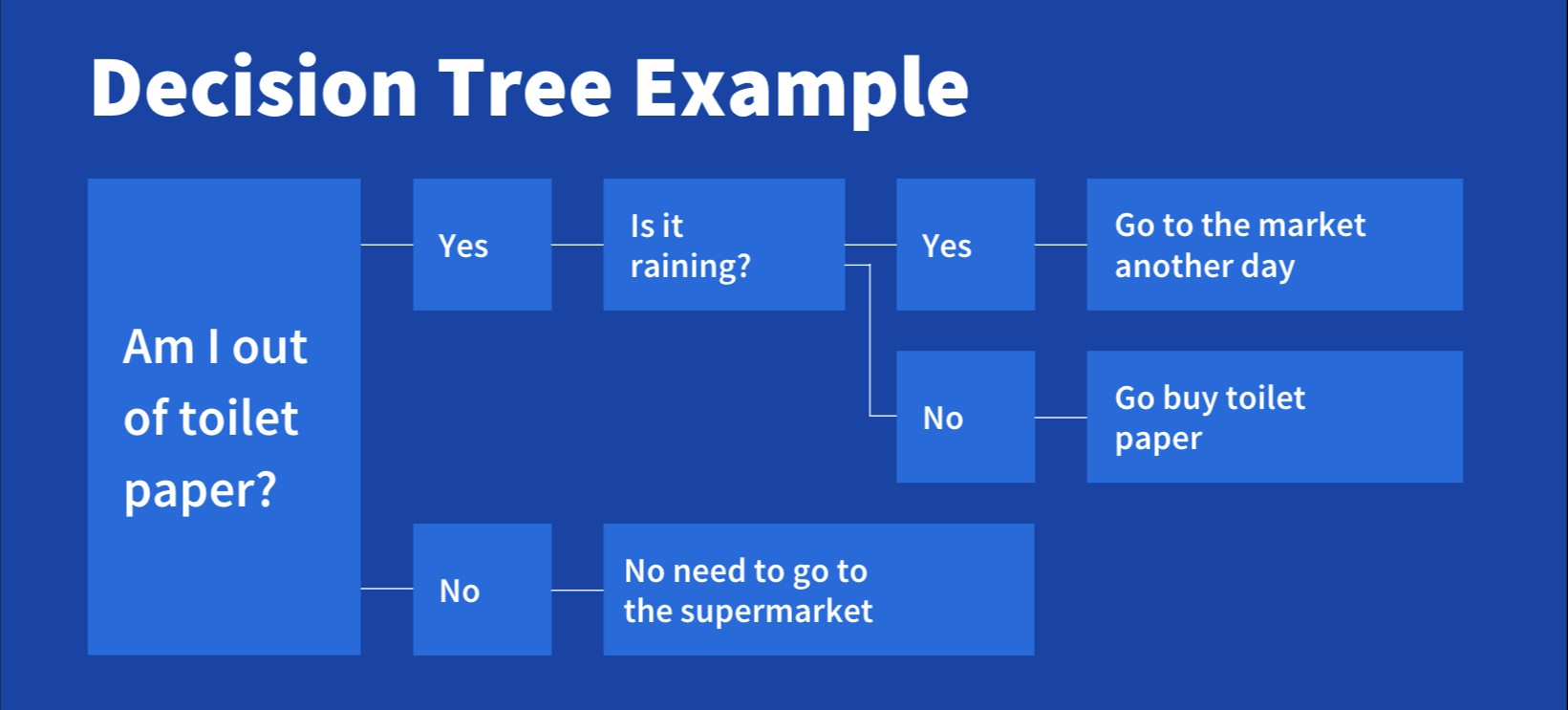 Decision tree for buying toilet paper
Decision tree for buying toilet paper
In machine learning, decision trees offer a blend of simplicity and visual clarity, making complex decision processes understandable. Let’s now explore the two primary types of learning ml tree models: classification and regression trees.
Types of Decision Tree Machine Learning Models
Decision trees in machine learning are broadly categorized into classification trees and regression trees. These two algorithms together are often referred to as “Classification and Regression Trees,” or CART. Their primary functions are to “classify” data into categories or to “predict” continuous values.
1. Classification Trees
Classification trees are designed to predict categorical outcomes. They answer questions that typically have binary (“yes” or “no”) or multiple categorical answers. Essentially, they determine whether an event belongs to a specific category or not.
This type of decision-making resonates with many real-world scenarios. Let’s look at a couple of examples to better understand how classification trees function:
Example 1: Deciding on After-Work Activities
Your choice of activity after work might depend on the weather. If it’s sunny, you might opt for a picnic with a friend, drinks with colleagues, or running errands. If it’s raining, staying in to watch a movie might be more appealing. This scenario clearly classifies the outcome into “go out” or “stay in,” based on the weather condition.
Example 2: Predicting Homeownership Based on Age and Income
In a classification tree, datasets are divided based on variables. Consider age and income as variables to predict homeownership. If training data reveals that 70% of people over 30 own homes, the data splits at this point, making age the initial node in the tree. This split increases data purity. Subsequent nodes might then consider income to refine the prediction further.
Get Practical Experience with Classification Trees
To gain hands-on experience with classification trees in machine learning, consider these guided projects that allow you to apply your skills to practical problems in just a couple of hours:
• Classification Trees in Python, From Start To Finish
• Decision Tree Classifier for Beginners in R
Alt text: Abstract purple pattern representing Python code and classification trees in machine learning.
2. Regression Trees
Regression trees, in contrast to classification trees, are used to predict continuous numerical values. They forecast values based on past data and trends. For instance, they can predict gasoline prices or estimate the quantity of eggs a customer might purchase, including the type and store preference.
This type of predictive modeling involves algorithms designed to anticipate likely outcomes based on historical patterns and behaviors.
Example 1: Predicting Housing Prices in Colorado
Regression analysis can be applied to predict housing prices in Colorado. By plotting historical housing prices, a regression model can forecast future prices. If housing prices show a consistent upward trend, linear regression is suitable for prediction. Machine learning refines this by predicting specific prices based on multiple historical variables.
Example 2: Forecasting Bachelor’s Degree Graduates in 2025
A university can use a regression tree to predict the number of bachelor’s degree graduates in 2025. By analyzing the trend of graduates from 2010 to 2022, if the number of graduates has increased linearly each year, regression analysis can create an algorithm to predict the graduate count for 2025.
Classification and Regression Trees (CART) algorithms are fundamental predictive tools in machine learning, forming the basis for more complex machine learning algorithms such as random forests, bagged decision trees, and boosted decision trees.
Enhance Your Skills with Regression Trees
To start exploring regression tree algorithms in predictive machine learning models, these guided projects offer real-world examples to elevate your skills in under two hours each:
• Supervised Machine Learning: Regression and Classification
• Regression Analysis: Simplify Complex Data Relationships
Alt text: Abstract purple pattern representing regression analysis and graphs in machine learning.
Key Decision Tree Terminology
As you advance in your machine learning journey, understanding these terms related to decision trees will be invaluable:
-
Root Node: The starting point of a decision tree, representing the entire dataset or decision problem.
-
Decision (or Internal) Node: A node within the tree where a branch splits into two or more sub-branches based on different variables or conditions.
-
Leaf (or Terminal) Node: The final node in a decision path, which does not branch further and represents the outcome or prediction.
-
Splitting: The process of dividing a node into sub-nodes, creating branches based on different variable values.
-
Pruning: The opposite of splitting, it involves simplifying the tree by removing less significant branches or nodes to prevent overfitting and improve generalization.
Embark on Your Machine Learning Journey with Coursera
Decision trees are a foundational concept in machine learning, offering a powerful tool for predicting outcomes and understanding complex behaviors. To begin your in-depth exploration of machine learning, consider Coursera’s highly-rated specialization, Supervised Machine Learning: Regression and Classification, presented by DeepLearning.AI and taught by AI pioneer Andrew Ng. This specialization will guide you in building machine learning models in Python using libraries like NumPy and scikit-learn, and in training supervised learning models, including decision trees, for effective prediction.