Unsupervised learning, a core branch of machine learning, empowers systems to decipher patterns from unlabeled data. Unlike its supervised counterpart that relies on pre-categorized information, Unsupervised Learning Algorithms autonomously explore datasets to identify inherent structures and relationships without explicit guidance. These algorithms excel at extracting meaningful insights from raw data, operating without predefined outputs, and uncovering groupings or patterns independently.
The process of unsupervised learning can be visualized as follows: Raw, unlabeled data, like a collection of diverse animals, is fed into an algorithm. The algorithm, representing techniques such as clustering or dimensionality reduction, then processes this data. The crucial “Interpretation” stage highlights the algorithm’s task: to discern groupings and organization within the data based on its intrinsic patterns, without any prior labels. Finally, the output demonstrates the algorithm’s success, perhaps grouping the animals by species – elephants, camels, and cows – based purely on their features.
How Unsupervised Learning Functions
Unsupervised learning algorithms operate by meticulously analyzing unlabeled data to pinpoint underlying patterns and connections. Lacking pre-assigned labels or expected outcomes, these algorithms are challenged to autonomously discover the data’s inherent structure. This capability is invaluable, as it can reveal hidden insights and relationships within datasets that would remain obscure with traditional labeled approaches.
Consider a mall’s customer dataset, illustrated in Figure A. This data encompasses details of customers who have subscribed to the mall’s services and possess membership cards. By leveraging unsupervised learning techniques on this rich customer data, the mall can effectively segment its clientele based on various input parameters.
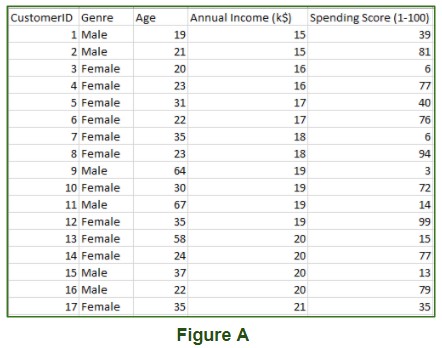 Visualization of customer data points clustered using unsupervised learning algorithms in a mall context.
Visualization of customer data points clustered using unsupervised learning algorithms in a mall context.
The input data for unsupervised learning models is characterized by:
- Unstructured Data: Often includes noisy, irrelevant data, missing entries, or unknown data points.
- Unlabeled Data: Consists solely of input parameter values, devoid of any target or output values. This type of data is more readily available and easier to collect compared to labeled data used in supervised learning.
Types of Unsupervised Learning Algorithms
Unsupervised learning employs several key algorithmic approaches, primarily categorized into three main types:
- Clustering
- Association Rule Learning
- Dimensionality Reduction
1. Clustering Algorithms
Clustering algorithms, a cornerstone of unsupervised machine learning, are designed to group unlabeled data into distinct clusters based on inherent similarities. The fundamental aim of clustering is to identify and reveal the hidden structure within data, grouping data points in meaningful ways without prior knowledge of categories or labels.
This technique is broadly applied to organize data based on discovered patterns, whether similarities or differences identified by the machine learning model. These algorithms are instrumental in processing raw, unclassified data, transforming it into organized groups. In the mall customer data example above, clustering would be used to segment customers into groups based on their purchasing behavior and demographic information, without predefined customer segments.
Common Clustering Algorithms:
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Mean-Shift Clustering
- Gaussian Mixture Models (GMMs)
2. Association Rule Learning
Association rule learning, also known as association rule mining, is a technique used in unsupervised machine learning to uncover relationships and associations within large datasets. This rule-based machine learning approach is particularly effective at finding interesting connections between different variables in a dataset. A prime application of association rule learning is market basket analysis, which aims to understand purchasing patterns and relationships between products.
For instance, retail stores utilize algorithms based on association rule learning to analyze customer purchase history and identify products frequently bought together. For example, if a customer purchases coffee, they might also be likely to buy milk or sugar. By effectively training these models, businesses can optimize sales strategies through targeted promotions and product placement.
Common Association Rule Learning Algorithms:
- Apriori Algorithm
- Eclat (Equivalence Class Clustering and bottom-up Lattice Traversal)
- FP-Growth (Frequent Pattern Growth)
3. Dimensionality Reduction
Dimensionality reduction is a technique focused on decreasing the number of variables or features in a dataset while preserving essential information. This reduction simplifies the dataset, making it more manageable and often improving the performance of machine learning algorithms, as well as facilitating data visualization.
Imagine a dataset containing 100 features describing students, such as height, weight, grades in various subjects, extracurricular activities, etc. Dimensionality reduction could be used to condense these features into a smaller, more manageable set, perhaps focusing on only two or three key features that capture most of the variance in the data, like ‘academic performance’ and ‘physical attributes’. This simplified representation makes it easier to analyze patterns, visualize data, and build more efficient models.
Popular Dimensionality Reduction Algorithms:
- Principal Component Analysis (PCA)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- Independent Component Analysis (ICA)
- Linear Discriminant Analysis (LDA) (While technically also used in supervised learning for feature extraction, variations exist for unsupervised contexts)
- UMAP (Uniform Manifold Approximation and Projection)
Challenges of Unsupervised Learning
Unsupervised learning, while powerful, presents several challenges:
- Noisy Data: The presence of outliers and noise in unlabeled data can significantly distort the patterns identified by algorithms, leading to inaccurate or misleading results.
- Assumption Dependence: Many unsupervised algorithms rely on underlying assumptions about the data structure, such as the shape of clusters. If these assumptions do not align with the actual data distribution, the algorithm’s effectiveness can be compromised.
- Overfitting Risk: Without labeled data to guide the learning process, unsupervised models are susceptible to overfitting. They may capture noise or irrelevant details in the data rather than generalizable patterns.
- Limited Guidance: The inherent lack of labels in unsupervised learning means there is no direct way to steer the algorithm towards specific outcomes or ensure that the discovered patterns are relevant to a particular goal.
- Cluster Interpretability: The results of clustering, such as identified clusters, can sometimes be difficult to interpret or assign meaningful labels to. Clusters might not always correspond to easily understandable real-world categories.
- Sensitivity to Parameters: Many unsupervised algorithms, like k-means, require careful tuning of hyperparameters, such as the number of clusters. The performance of these algorithms can be highly sensitive to these parameter settings.
- Lack of Ground Truth for Evaluation: Since unsupervised learning deals with unlabeled data, there is no readily available ‘ground truth’ to objectively evaluate the accuracy or quality of the results. Assessing the performance often relies on subjective measures or indirect metrics.
Applications of Unsupervised Learning
Unsupervised learning is applied across a wide spectrum of industries and domains, offering solutions to diverse problems. Key applications include:
- Customer Segmentation: Businesses use clustering algorithms to segment customers based on purchasing behavior, demographics, or preferences. This enables highly targeted marketing campaigns and personalized customer experiences.
- Anomaly Detection: Unsupervised learning is crucial for identifying unusual patterns or outliers in datasets. This is vital for fraud detection in finance, cybersecurity threat detection, and predictive maintenance by identifying equipment failures early.
- Recommendation Systems: By analyzing user behavior and preferences, unsupervised learning algorithms power recommendation systems that suggest products, movies, music, or content tailored to individual users.
- Image and Text Clustering: Clustering techniques are used to group similar images or documents. This is applied in image recognition, document organization, topic discovery in text corpora, and content recommendation.
- Social Network Analysis: Unsupervised learning helps in detecting communities, identifying influential users, and understanding trends in user interactions within social media platforms.
- Astronomy and Climate Science: In scientific research, unsupervised learning aids in classifying astronomical objects like galaxies or grouping weather patterns to support data analysis and discovery of new phenomena.
Unsupervised Learning Frequently Asked Questions (FAQs)
1. What is unsupervised learning?
Unsupervised learning is a type of machine learning where algorithms learn from unlabeled data to discover hidden patterns and structures, such as clusters or anomalies, without predefined categories or outcomes.
2. What are some common applications of unsupervised learning?
Unsupervised learning is widely used for:
- Clustering: Grouping similar data points together.
- Dimensionality Reduction: Simplifying data by reducing the number of variables.
- Anomaly Detection: Identifying unusual or outlier data points.
- Recommendation Systems: Providing personalized recommendations based on user patterns.
- Data Segmentation: Dividing datasets into meaningful segments.
3. What are the key challenges of unsupervised learning?
Major challenges include:
- Difficulty in evaluating model performance due to the lack of labeled data.
- Sensitivity to noisy or incomplete data.
- Potential for misinterpretation of results.
- The subjective nature of validating discovered patterns.
4. How is unsupervised learning utilized in Natural Language Processing (NLP)?
In NLP, unsupervised learning is used for tasks such as:
- Topic Modeling: Identifying thematic topics across large volumes of text.
- Document Clustering: Grouping documents based on content similarity.
- Word Embedding Learning: Discovering semantic relationships between words.
5. What are the primary differences between supervised and unsupervised learning?
The fundamental difference lies in the data used for training:
- Supervised learning uses labeled data to train models to predict outcomes based on input features.
- Unsupervised learning uses unlabeled data to find inherent structures and patterns within the data itself, without predicting a specific outcome variable.
Next Article Semi-Supervised Learning in ML
