Machine learning, a subset of artificial intelligence, empowers computers to learn from data without explicit programming. This powerful technology enables businesses to predict outcomes, analyze trends, and automate complex tasks. But what are the different types of machine learning? This article will delve into the four main categories: supervised, unsupervised, semi-supervised, and reinforcement learning.
A diagram illustrating the relationships between different types of machine learning.
Supervised Learning: Learning by Example
Supervised learning operates much like a teacher-student relationship. The algorithm is trained on a labeled dataset, meaning the input data is paired with corresponding correct outputs. The algorithm learns to map inputs to outputs by identifying patterns and relationships within the data. This process allows the algorithm to make predictions on new, unseen data. Supervised learning encompasses tasks like:
- Classification: Assigning data points to specific categories. Think of spam email filtering, where the algorithm learns to classify emails as spam or not spam based on previous examples.
- Regression: Predicting a continuous value based on input variables. For example, predicting house prices based on factors like size, location, and age.
- Forecasting: Predicting future trends based on historical data. This is commonly used in financial markets and sales projections.
Unsupervised Learning: Discovering Hidden Structures
Unsupervised learning involves algorithms learning from unlabeled data, meaning there are no predefined outputs. The algorithm’s task is to identify patterns, relationships, and structures within the data without explicit guidance. Common unsupervised learning tasks include:
- Clustering: Grouping similar data points together based on their inherent characteristics. This is used in customer segmentation, anomaly detection, and image recognition.
- Dimensionality Reduction: Reducing the number of variables in a dataset while preserving essential information. This simplifies data analysis and visualization.
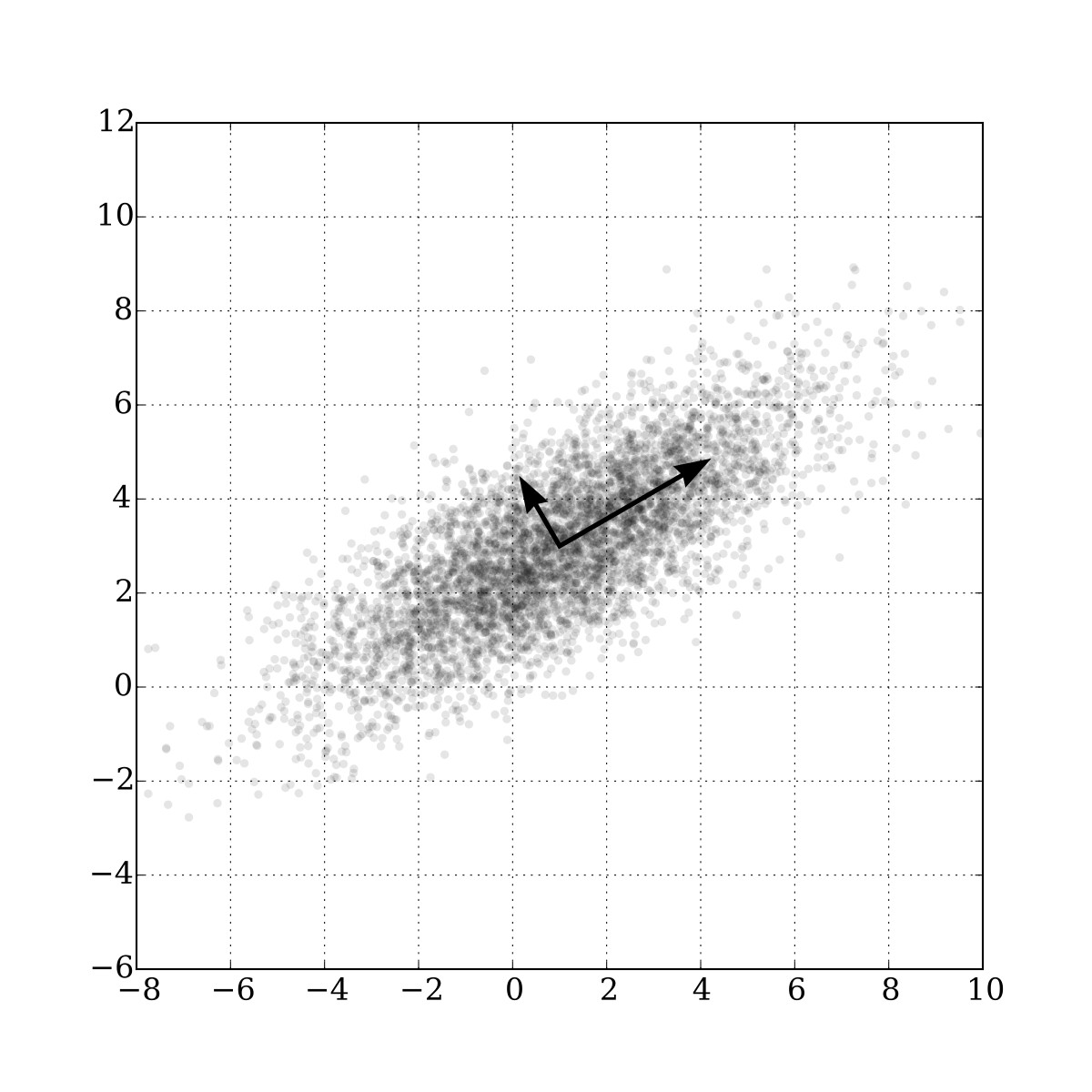 Dimensionality reduction with PCA
Dimensionality reduction with PCA
Semi-Supervised Learning: Bridging the Gap
Semi-supervised learning combines aspects of both supervised and unsupervised learning. It utilizes a small amount of labeled data along with a larger amount of unlabeled data. This approach leverages the benefits of both techniques, allowing for improved accuracy and efficiency in scenarios where labeled data is scarce or expensive to obtain.
Reinforcement Learning: Learning through Trial and Error
Reinforcement learning draws inspiration from how humans learn through trial and error. The algorithm, or agent, interacts with an environment and learns to take actions that maximize rewards and minimize penalties. This type of learning is commonly used in robotics, game playing, and control systems.
Choosing the Right Algorithm
Selecting the appropriate machine learning algorithm depends on several factors, including the type of data, the desired outcome, and the available resources. Factors to consider include data size, quality, diversity, desired accuracy, training time, and computational complexity. Experimentation and evaluation are crucial for determining the best algorithm for a specific task. Popular algorithms include Naive Bayes, K-Means Clustering, Support Vector Machines, Linear Regression, Logistic Regression, Artificial Neural Networks, Decision Trees, and Random Forests.
Conclusion
The four types of machine learning – supervised, unsupervised, semi-supervised, and reinforcement learning – each offer unique approaches to extracting knowledge and insights from data. Understanding these fundamental categories is crucial for leveraging the power of machine learning to solve complex problems and drive innovation across various industries. By selecting the right algorithm and applying it effectively, businesses can unlock valuable insights, automate processes, and gain a competitive edge.