In the realm of machine learning, particularly when training neural networks, the learning rate stands out as a pivotal hyperparameter. This scalar value dictates the magnitude of adjustments an optimizer makes to the network’s weights during the iterative training process. Essentially, it governs how rapidly or cautiously a model refines its understanding from the training data.
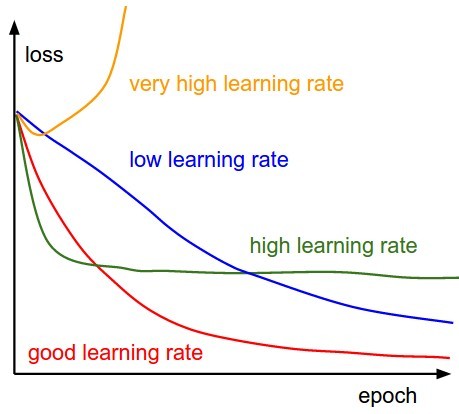
Generally speaking, a higher learning rate translates to more substantial alterations in the model’s weights with each update. Conversely, a lower learning rate results in more subtle, incremental changes. Think of it as the stride length of a learner: a larger stride (higher learning rate) covers more ground quickly, but risks overshooting the target.
 Learning Rate and Convergence in Gradient Descent
Learning Rate and Convergence in Gradient Descent
However, the implications of a higher learning rate are nuanced. While it promises faster initial learning, propelling the model towards a potential solution more swiftly, it also introduces the risk of instability. If the learning rate is excessively high, the optimizer might overshoot the optimal set of weights. Imagine trying to carefully descend into a valley (representing the minimum error); large steps might cause you to jump over the valley floor entirely, hindering convergence. The training process can become erratic, with the model’s performance oscillating or even diverging instead of settling into an optimal state.
On the other hand, a lower learning rate ensures a more stable but potentially slower learning process. It allows for fine-grained adjustments, meticulously navigating the complex landscape of possible weight configurations. However, the drawback is that it can be computationally expensive and time-consuming, especially for large datasets or intricate models. Furthermore, an excessively low learning rate might trap the optimizer in a suboptimal local minimum or a flat region (plateau), preventing it from reaching the globally optimal solution.
Therefore, selecting an appropriate learning rate is a critical balancing act. It often involves experimentation, where data scientists test different values and monitor the model’s performance. Sophisticated techniques like learning rate schedules, which dynamically adjust the learning rate during training, and adaptive learning rate methods, which tailor the learning rate for each parameter, have been developed to mitigate the challenges of choosing a fixed learning rate. Ultimately, a carefully chosen learning rate is paramount to ensure efficient training, stable convergence, and optimal performance of the machine learning model.
