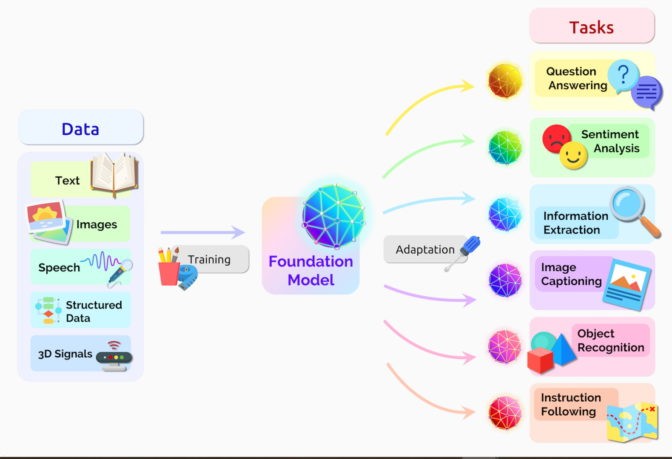
A transformer model is revolutionizing the field of Artificial Intelligence. But what exactly is it? This article delves into the core concepts of transformers, exploring their architecture, applications, and impact on machine learning.
Understanding the Transformer Architecture
At its heart, a transformer is a type of neural network designed to process sequential data, such as text or speech. Unlike traditional recurrent or convolutional networks, transformers leverage a mechanism called self-attention to weigh the importance of different parts of the input sequence when generating output. This allows the model to capture long-range dependencies and contextual information more effectively.
Self-attention works by comparing each element in the input sequence to every other element, calculating an “attention score” that reflects the relationship between them. These scores are then used to weight the contribution of each element to the final output. This process enables the transformer to understand the context and meaning of each word in relation to all other words in a sentence, paragraph, or even a larger document. For example, in the sentence “The cat sat on the mat,” the transformer can understand that “sat” refers to the action of the “cat” and relates to the location “mat.”
Applications of Transformer Models
The versatility of transformers has led to their widespread adoption across various domains.
- Natural Language Processing (NLP): Transformers have achieved state-of-the-art results in tasks like machine translation, text summarization, question answering, and sentiment analysis. Popular examples include Google Translate, BERT (used in Google Search), and GPT-3 (a powerful language model).
- Computer Vision: Transformers are increasingly being used for image recognition, object detection, and image generation, challenging the dominance of convolutional neural networks in this field.
- Drug Discovery: Transformers are helping researchers analyze protein sequences and molecular structures, accelerating the development of new drugs and treatments.
- Speech Recognition: Transformers are improving the accuracy and efficiency of speech-to-text systems, enabling better voice assistants and transcription services.
The Impact of Transformers on Machine Learning
Transformers have significantly impacted the field of machine learning by:
- Improving Performance: Transformers have consistently outperformed previous models in various tasks, setting new benchmarks for accuracy and efficiency.
- Enabling Self-Supervised Learning: The self-attention mechanism allows transformers to learn from unlabeled data, reducing the need for expensive and time-consuming manual annotation.
- Scaling to Massive Datasets: Transformers can be trained on massive datasets containing billions of data points, leading to more powerful and generalized models.
The Future of Transformers
The field of transformer research is rapidly evolving, with ongoing efforts to develop:
- More Efficient Transformers: Researchers are exploring techniques like model compression and pruning to reduce the computational cost of training and deploying transformers.
- Multimodal Transformers: These models can process and integrate information from multiple modalities, such as text, images, and audio.
- Explainable Transformers: Efforts are underway to make transformer models more transparent and interpretable, allowing us to understand how they arrive at their predictions.
Conclusion
Transformers represent a significant advancement in machine learning, enabling breakthroughs in various fields. Their ability to capture long-range dependencies and contextual information has led to unprecedented performance in tasks involving sequential data. As research continues, we can expect even more powerful and versatile transformer models to emerge, further revolutionizing the way we interact with and understand the world around us. The era of “Transformer AI” is upon us.
